Residual Non-local Attention Networks for Image Restoration
一.论文
在本文中,我们提出了一种残留的非局部注意网络,用于高质量的图像恢复。 在不考虑损坏图像中信息不均匀分布的情况下,先前的方法受到局部卷积运算以及对空间和通道方向特征的同等对待的限制。 为了解决这个问题,我们设计了局部和非局部注意块,以提取可捕获像素之间长期依赖关系的特征,并更加注意具有挑战性的部分。 具体来说,我们在每个(非本地)注意力模块中设计主干分支和(非本地)掩码分支。 干线分支用于提取层次结构特征。 局部和非局部蒙版分支的目的是在混合注意力的情况下自适应地重新缩放这些分层功能。 局部遮罩分支集中在具有卷积运算的更多局部结构上,而非局部注意则更多地考虑了整个特征图中的远程依赖性。 此外,我们提出了剩余的局部和非局部注意力学习方法来训练非常深的网络,从而进一步增强了网络的表示能力。
我们提出的方法可以推广到各种图像恢复应用中,例如图像去噪,去马赛克,压缩伪像减少和超分辨率。 实验表明,与最新的领先方法相比,我们的方法在数量上和视觉上均达到了可比或更好的结果。
二.网络结构



感觉最值的学习的就是Non-local block, 性能提升感觉还是网络的加深起到的作用,(目前的感觉,不一定对).
去噪结果:
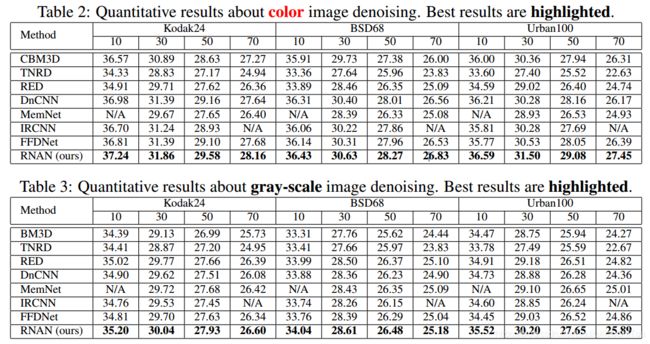
三.代码
主要学习这部分,当然完整代码也有.提供https://github.com/yulunzhang/RNAN/blob/master/DN_Gray
class NonLocalBlock2D(nn.Module):
def __init__(self, in_channels, inter_channels):
super(NonLocalBlock2D, self).__init__()
self.in_channels = in_channels
self.inter_channels = inter_channels
self.g = nn.Conv2d(in_channels=self.in_channels, out_channels=self.inter_channels, kernel_size=1, stride=1, padding=0)
self.W = nn.Conv2d(in_channels=self.inter_channels, out_channels=self.in_channels, kernel_size=1, stride=1, padding=0)
nn.init.constant(self.W.weight, 0)
nn.init.constant(self.W.bias, 0)
self.theta = nn.Conv2d(in_channels=self.in_channels, out_channels=self.inter_channels, kernel_size=1, stride=1, padding=0)
self.phi = nn.Conv2d(in_channels=self.in_channels, out_channels=self.inter_channels, kernel_size=1, stride=1, padding=0)
def forward(self, x):
batch_size = x.size(0)
g_x = self.g(x).view(batch_size, self.inter_channels, -1)
g_x = g_x.permute(0,2,1)
theta_x = self.theta(x).view(batch_size, self.inter_channels, -1)
theta_x = theta_x.permute(0,2,1)
phi_x = self.phi(x).view(batch_size, self.inter_channels, -1)
f = torch.matmul(theta_x, phi_x)
f_div_C = F.softmax(f, dim=1)
y = torch.matmul(f_div_C, g_x)
y = y.permute(0,2,1).contiguous()
y = y.view(batch_size, self.inter_channels, *x.size()[2:])
W_y = self.W(y)
z = W_y + x
return z