遗传算法解决TSP问题
一、TSP问题
TSP问题:给定一组n个城市和俩俩之间的直达距离,寻找一条闭合的旅程,使得每个城市刚好经过一次且总的旅行距离最短。TSP是一个具有广泛的应用背景和重要理论价值的组合优化问题。 近年来,有很多解决该问题的较为有效的算法不断被推出,例如Hopfield神经网络方法,模拟退火方法以及遗传算法方法等。TSP的搜索空间随着城市数量的增加而增大,在庞大的搜索空间里求最优解,是个很大的难题,本实验用遗传算法方法来解决TSP问题。
二、遗传算法原理
算法设计的基本概念:
- 种群:种群是指用遗传算法求解问题是,初始给定的多个解的集合。遗传算法的求解过程是从这个子集开始的。
- 个体:个体是指种群中的单个元素,它通常由一个用于描述其基本遗传结构的数据结构来表示。
- 染色体:染色体是指对个体进行编码后所得到的编码串。
- 适应度函数:适应度函数是一种用来对种群中各个个体的环境适应性进行度量的函数。其函数值是遗传算法实现优胜劣汰的主要依据
- 遗传操作:遗传操作是指作用于种群而产生新的种群的操作。标准的遗传操作有选择、杂交、变异。
算法步骤:
(1)对遗传算法的运行参数进行赋值。参数包括种群规模、变量个数、交叉概率、变异概
率以及遗传运算的终止进化代数。
(2)建立区域描述器。根据轨道交通与常规公交运营协调模型的求解变量的约束条件,设置变量的取值范围。
(3)在(2)的变量取值范围内,随机产生初始群体,代入适应度函数计算其适应度值。
(4)执行比例选择算子进行选择操作。
(5)按交叉概率对交叉算子执行交叉操作。
(6)按变异概率执行离散变异操作。
(7)计算(6)得到局部最优解中每个个体的适应值,并执行最优个体保存策略。
(8)判断是否满足遗传运算的终止进化代数,不满足则返回(4),满足则输出运算结果。
三、代码实现
main.m
主程序
%main
clear;
clc;
%%%%%%%%%%%%%%%输入参数%%%%%%%%
N=25; %%城市的个数
M=100; %%种群的个数
ITER=2000; %%迭代次数
%C_old=C;
m=2; %%适应值归一化淘汰加速指数
Pc=0.8; %%交叉概率
Pmutation=0.05; %%变异概率
%%生成城市的坐标
pos=randn(N,2);
%%生成城市之间距离矩阵
D=zeros(N,N);
for i=1:N
for j=i+1:N
dis=(pos(i,1)-pos(j,1)).^2+(pos(i,2)-pos(j,2)).^2;
D(i,j)=dis^(0.5);
D(j,i)=D(i,j);
end
end
%%生成初始群体
popm=zeros(M,N);
for i=1:M
popm(i,:)=randperm(N);%随机排列,比如[2 4 5 6 1 3]
end
%%随机选择一个种群
R=popm(1,:);
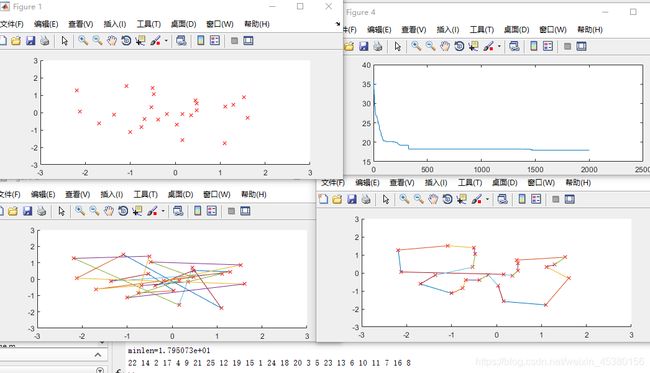
figure(1);
scatter(pos(:,1),pos(:,2),'rx');%画出所有城市坐标
axis([-3 3 -3 3]);
figure(2);
plot_route(pos,R); %%画出初始种群对应各城市之间的连线
axis([-3 3 -3 3]);
%%初始化种群及其适应函数
fitness=zeros(M,1);
len=zeros(M,1);
for i=1:M%计算每个染色体对应的总长度
len(i,1)=myLength(D,popm(i,:));
end
maxlen=max(len);%最大回路
minlen=min(len);%最小回路
fitness=fit(len,m,maxlen,minlen);
rr=find(len==minlen);%找到最小值的下标,赋值为rr
R=popm(rr(1,1),:);%提取该染色体,赋值为R
for i=1:N
fprintf('%d ',R(i));%把R顺序打印出来
end
fprintf('\n');
fitness=fitness/sum(fitness);
distance_min=zeros(ITER+1,1); %%各次迭代的最小的种群的路径总长
nn=M;
iter=0;
while iter<=ITER
fprintf('迭代第%d次\n',iter);
%%选择操作
p=fitness./sum(fitness);
q=cumsum(p);%累加
for i=1:(M-1)
len_1(i,1)=myLength(D,popm(i,:));
r=rand;
tmp=find(r<=q);
popm_sel(i,:)=popm(tmp(1),:);
end
[fmax,indmax]=max(fitness);%求当代最佳个体
popm_sel(M,:)=popm(indmax,:);
%%交叉操作
nnper=randperm(M);
% A=popm_sel(nnper(1),:);
% B=popm_sel(nnper(2),:);
%%
for i=1:M*Pc*0.5
A=popm_sel(nnper(i),:);
B=popm_sel(nnper(i+1),:);
[A,B]=cross(A,B);
% popm_sel(nnper(1),:)=A;
% popm_sel(nnper(2),:)=B;
popm_sel(nnper(i),:)=A;
popm_sel(nnper(i+1),:)=B;
end
%%变异操作
for i=1:M
pick=rand;
while pick==0
pick=rand;
end
if pick<=Pmutation
popm_sel(i,:)=Mutation(popm_sel(i,:));
end
end
%%求适应度函数
NN=size(popm_sel,1);
len=zeros(NN,1);
for i=1:NN
len(i,1)=myLength(D,popm_sel(i,:));
end
maxlen=max(len);
minlen=min(len);
distance_min(iter+1,1)=minlen;
fitness=fit(len,m,maxlen,minlen);
rr=find(len==minlen);
fprintf('minlen=%d\n',minlen);
R=popm_sel(rr(1,1),:);
for i=1:N
fprintf('%d ',R(i));
end
fprintf('\n');
popm=[];
popm=popm_sel;
iter=iter+1;
%pause(1);
end
%end of while
figure(3)
plot_route(pos,R);
axis([-3 3 -3 3]);
figure(4)
plot(distance_min);
cross.m
%交叉操作函数 cross.m
function [A,B]=cross(A,B)
L=length(A);
if L<10
W=L;
elseif ((L/10)-floor(L/10))>=rand&&L>10
W=ceil(L/10)+8;
else
W=floor(L/10)+8;
end
%%W为需要交叉的位数
p=unidrnd(L-W+1);%随机产生一个交叉位置
%fprintf('p=%d ',p);%交叉位置
for i=1:W
x=find(A==B(1,p+i-1));
y=find(B==A(1,p+i-1));
[A(1,p+i-1),B(1,p+i-1)]=exchange(A(1,p+i-1),B(1,p+i-1));
[A(1,x),B(1,y)]=exchange(A(1,x),B(1,y));
end
end
exchange.m
%对调函数 exchange.m
function [x,y]=exchange(x,y)
temp=x;
x=y;
y=temp;
end
fit.m
%适应度函数fit.m,每次迭代都要计算每个染色体在本种群内部的优先级别,类似归一化参数。越大约好!
function fitness=fit(len,m,maxlen,minlen)
fitness=len;
for i=1:length(len)
fitness(i,1)=(1-(len(i,1)-minlen)/(maxlen-minlen+0.0001)).^m;
end
Mutation.m
%变异函数 Mutation.m
function a=Mutation(A)
index1=0;index2=0;
nnper=randperm(size(A,2));
index1=nnper(1);
index2=nnper(2);
%fprintf('index1=%d ',index1);
%fprintf('index2=%d ',index2);
temp=0;
temp=A(index1);
A(index1)=A(index2);
A(index2)=temp;
a=A;
end
myLength.m
%染色体的路程代价函数 mylength.m
function len=myLength(D,p)%p是一个排列
[N,NN]=size(D);
len=D(p(1,N),p(1,1));
for i=1:(N-1)
len=len+D(p(1,i),p(1,i+1));
end
endplot_route.m
%连点画图函数 plot_route.m
function plot_route(a,R)
scatter(a(:,1),a(:,2),'rx');
hold on;
plot([a(R(1),1),a(R(length(R)),1)],[a(R(1),2),a(R(length(R)),2)]);
hold on;
for i=2:length(R)
x0=a(R(i-1),1);
y0=a(R(i-1),2);
x1=a(R(i),1);
y1=a(R(i),2);
xx=[x0,x1];
yy=[y0,y1];
plot(xx,yy);
hold on;
end
end
四、参数对比分析
基本可变参数如下:
N:城市个数(25)
M:种群个数(100)
Pc:交叉概率(0.8)
Pmutation:变异概率(0.05)
当四个参数都固定时,不同的城市序列对比:
| 序号 | 总时间 | minlen | 城市序列 |
| 1 | 16.676s | 1.836447e+01 | 15 21 10 3 22 25 24 6 1 7 18 5 19 2 12 4 23 13 9 16 17 8 14 11 20 |
| 2 | 16.335 s | 1.880064e+01 | 21 7 12 19 16 20 24 3 23 11 22 8 13 10 4 2 5 18 25 14 17 6 1 15 9 |
| 3 | 16.454 s | 1.754988e+01 | 4 14 23 24 22 7 10 12 6 19 2 13 5 17 8 15 20 21 25 11 9 1 18 16 3 |
| 4 | 15.261 s | 2.062626e+01 | 9 3 24 12 6 11 15 19 4 7 25 18 23 21 17 22 5 2 16 8 14 1 13 20 10 |
| 5 | 14.260 s | 1.643078e+01 | 17 9 12 21 25 13 6 16 15 14 3 24 10 5 20 8 2 18 23 22 19 11 1 4 7 |
| 6 | 14.314 s | 1.817458e+01 | 5 20 10 7 23 19 17 2 25 24 13 3 1 9 16 18 11 4 22 8 15 6 12 21 14 |
城市序列固定,四个参数变化对比
保存的城市序列:
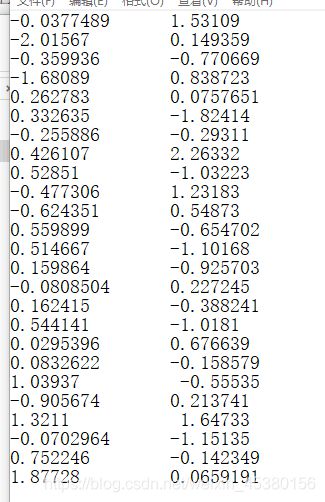
- N变化对比
当N=10时
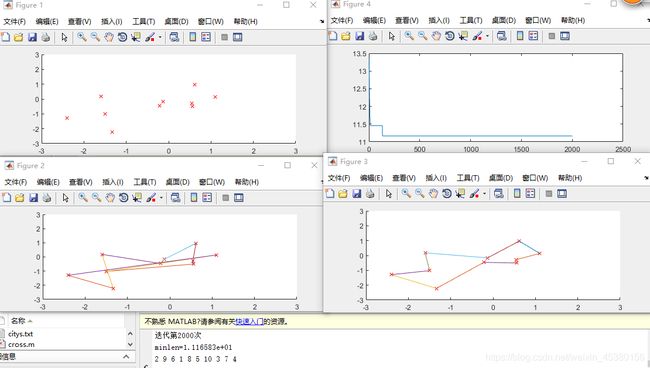
当N=25时
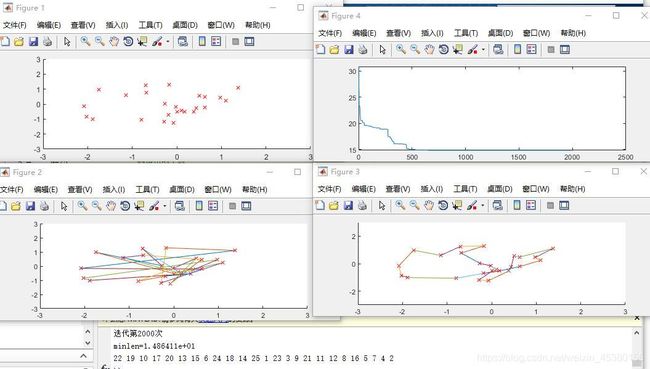
当N=50时
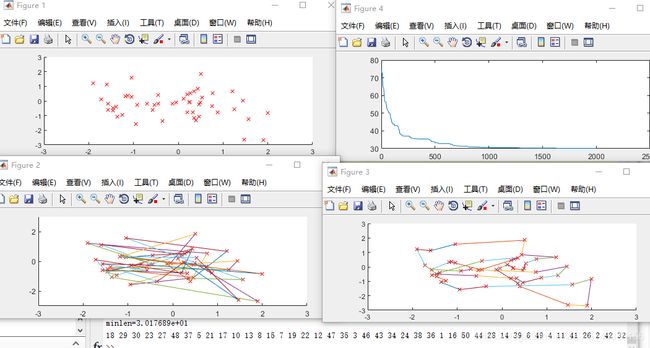
当N=80时
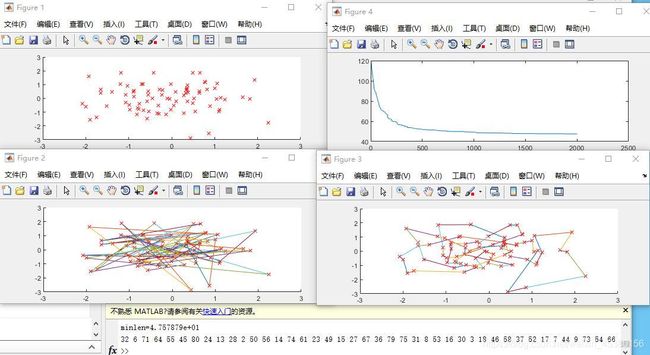
- M变化对比
当M=50
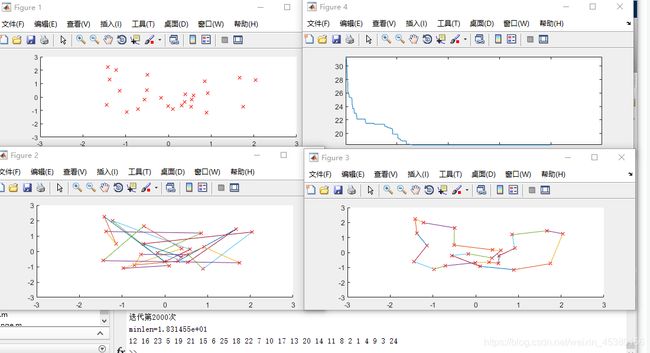
当M=80
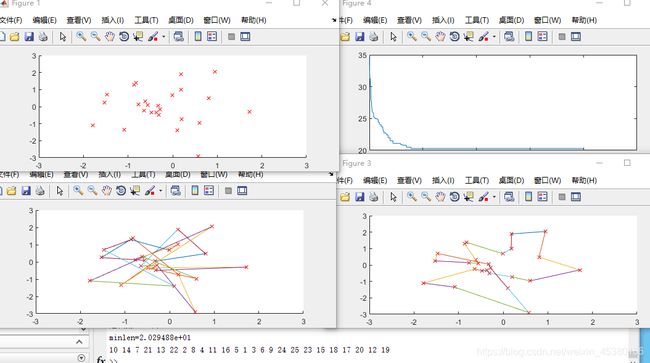
当M=100

当M=130

总结:M设置较大时可以提高算法的搜索能力,但是降低算法的运行效率。
- Pc变化对比
Pc=0.3
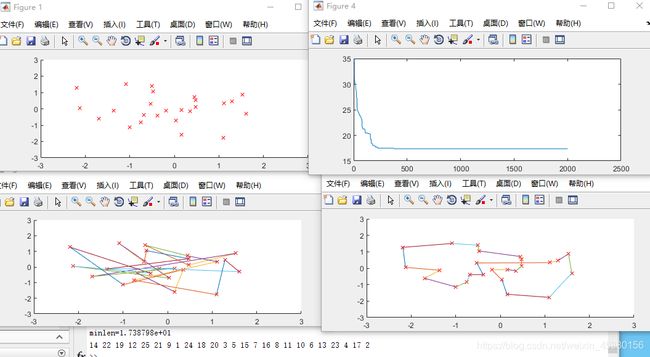
Pc=0.4
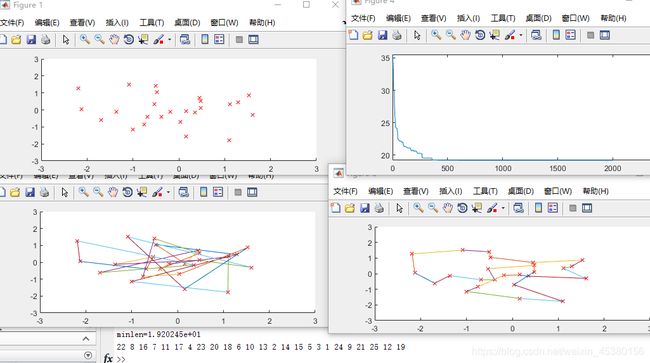
Pc=0.6
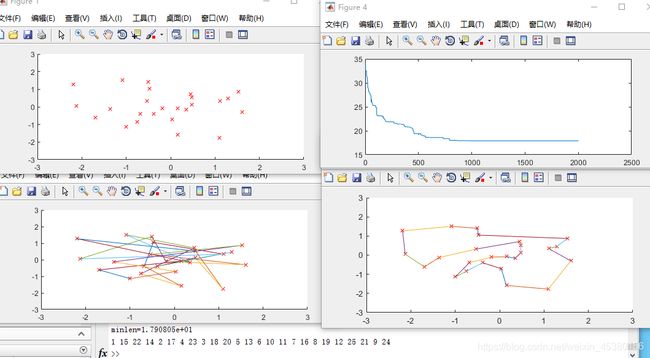
Pc=0.8
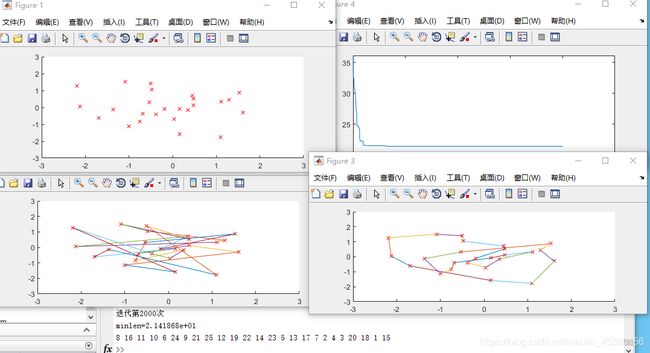
Pc=0.99

- Pmutation变化对比:
Pmutation=0.001

Pmutation=0.01
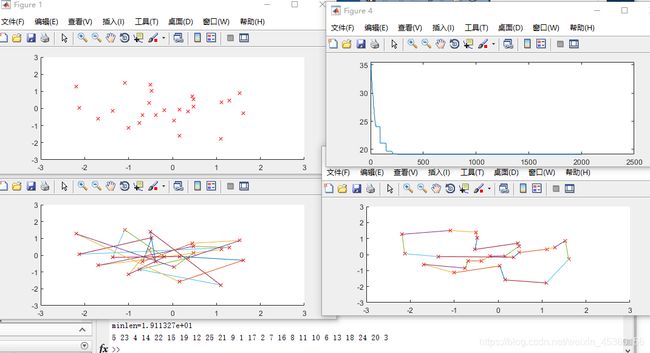
Pmutation=0.05

Pmutation=0.1
五、实验总结
实验中随机产生城市序列,对于不同的城市序列,种群数量的不同对最终的结果有一定的影响,还有相同的城市序列下,不同的种群数量影响算法的搜索能力及运行效率,不同的变异概率决定进行过程中发生变异的数量。
实验难点是交叉算法的设计,由于TSP问题和一般的NP问题不一样,每个个体的每个维度具有唯一性,因此在交叉的时候要注意不能有重复的值。