L2-Net 论文详解
L2-Net
本文提供了相应的代码,是基于 matconvnet,论文的思路相对来说比较简单,可以使用 pytorch 或者 tersorflow 等框架复现。
主要思路
之前有 SIFT 等手工设计的 patch 特征,这里提出的 L2-Net 的方法,利用 CNN 方法在 Euclidean 空间学习 patch 特征。本文主要的工作包括:
- 提出递进的采样策略,可以保证网络在很少的 epochs 就可以访问到数十亿的训练样本。
- 重点关注 patch 特征之间的相对距离,就是匹配上的 patch pair 距离比未匹配上的 patch pair 距离更近。
- 对学习过程中间的 feature maps 进行额外的监督。
- 同时会考虑特征的 compactness(紧凑程度)。
利用网络输出特征向量后,用 L 2 L_{2} L2 距离当做在 Euclidean 空间的相似程度。而且这个和传统特征是完全一致的,这样在很多方法里面可以直接用 L2-Net 的特征进行替换。
本文的主要目的是输出 patch 对应的 128d 的特征向量,而不去关注 metric 的学习,有了特征向量后直接利用 L 2 L_{2} L2 来度量相似度,简单来说就是在特征空间里面进行 nearest neighbor search (NNS) 查找最近的 patch 作为匹配结果。本文的关注的只要 matching pairs 都互为最近邻即可,而实际距离的大小和量级不需要太过关心,也就是只关注相对距离。这算是本文的核心思路吧,后面 training batch 构建以及网络结构和 loss 涉及都和这个思路相关。
基本流程
网络架构
本文 L2-Net 整体的网络架构如下图所示:
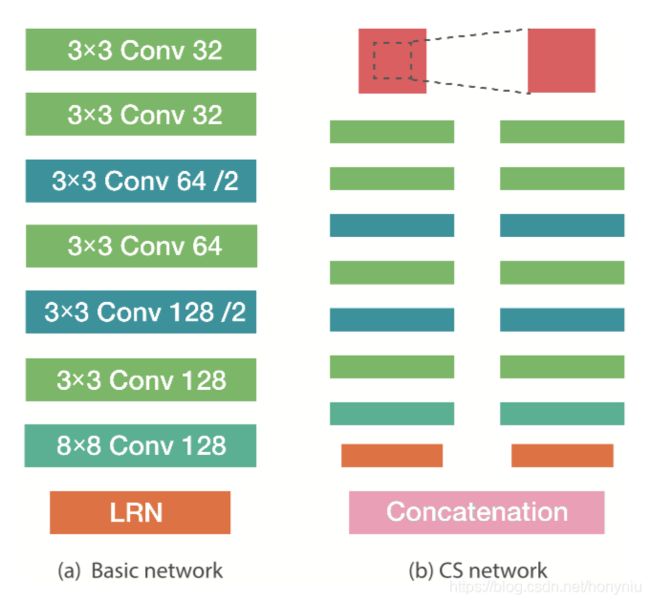
左图是基本架构,其中利用的是全卷积网络,同时 feature map 降维是利用卷积层的 stride 设置为 2 实现的。每个卷积后面都跟着一个 BN 层,但是该 BN 层的参数不会在训练过程中去更新(w和b固定为1和0)。网络最后使用 Local Response Normalization (LRN) 层输出一个单位特征向量。
其中输入是 32 × 32 32 \times 32 32×32 大小的 patch,输出是 128d 的特征向量。
同时参考 DeepPatchMatch 和 DeepCompare ,实现了 central-surround (CS) L2-Net,如上面右图,左边分支输入是原始的 patch,右边分支输入是在原始 patch 基础上中间 crop 然后 resize 到同样大小,然后经过同样的网络,把最后特征向量拼接在一起,得到最后的特征向量。
CS 这种操作的好处是为了处理特征 scale 不变性的问题,但是有个疑问就是 CNN 框架是也可以处理这种 scale 情况的,估计是效果不太好。
训练数据和预处理
本文训练数据使用的是 Brown 和 HPatches,是在不同的场景下采集的。但是组织方式一致,如下:
- 每个 patch 都有独一无二的 3D 点的 index 属性,如果 patches 的该属性一致,则认为具有匹配关系;
- 当然对于每个 3D 点,至少有两个相关的匹配的 patches;
其中 Brown 数据集包含 Yosemite, Notredame, and Liberty 三个子集,通常情况都是一个子集用来 train,其他两个用于 test。
其中 HPatches 数据集被分成 train-hard (easy) -viewpoint 和 train-hard (easy) -illum 四个子集,表示不同的 view 和 光线的变化程度。HPatches 只当做 train 数据集。
其中 Brown 数据包含 500K (1.5M) 个 3D 点,HPatches 包含 190K (1.2M)个 3D 点。
实际训练时每个 patch 直接 resize 到 32 × 32 32 \times 32 32×32,同时对每个 pixel 做 mean 和 scale 的 norm 操作。
递进采样策略
首先在 patch matching 的问题上,负样本数量要远远高于正样本,一对匹配的 patch pair,除了互相匹配之外,其中每个 patch 和数据库中的除这两个之外的 patch 都可以组成负样本,这就导致很难在训练过程中遍历所有的负样本,所以需要一个好的采样策略。
之前的工作都是采样相同数目的正负样本,本文的递进采样策略则会采样更多的负样本。具体采样过程如下:
在训练数据集中有个 P P P 个 3D 点,首先选择其中的 p 1 p_{1} p1 个点,按照顺序遍历所有的 3D 点,然后从余下的 P − p 1 P- p{1} P−p1 个 3D 点随机选取 p 2 p_{2} p2 个点, p 2 p_{2} p2 3D 点的选取增加了数据的 random, p 1 + p 2 p_{1} + p_{2} p1+p2 当做每个 training batch 选择的 3D 点。
然后为了得到最终的 training batch,对 p = p 1 + p 2 p = p_{1} + p_{2} p=p1+p2 中的每个点,随机选取一对 matching patches(每个 3D 点可能对应更多的 patches),所以最终的 training batch为:
X = { x 1 1 , x 1 2 , ⋯ , x i 1 , x i 2 , ⋯ , x p 1 , x p 2 } 32 × 32 × 2 p \mathbf { X } = \left\{ \mathbf { x } _ { 1 } ^ { 1 } , \mathbf { x } _ { 1 } ^ { 2 } , \cdots , \mathbf { x } _ { i } ^ { 1 } , \mathbf { x } _ { i } ^ { 2 } , \cdots , \mathbf { x } _ { p } ^ { 1 } , \mathbf { x } _ { p } ^ { 2 } \right\} _ { 32 \times 32 \times 2 p } X={x11,x12,⋯,xi1,xi2,⋯,xp1,xp2}32×32×2p
其中下标是 3D 点的 i n d e x index index,上标 2D patch 的 i n d e x index index, x i 1 \mathbf { x } _ { i } ^ { 1 } xi1 和 x i 2 \mathbf { x } _ { i } ^ { 2 } xi2 表示 3D 点的对应的一对匹配的 patch pair。这 X \mathbf { X } X 是 L2-Net 的输入,输出是:
Y = [ y 1 1 , y 1 2 , ⋯ , y i 1 , y i 2 , ⋯ , y p 1 , y p 2 ] q × 2 p \mathbf { Y } = \left[ \mathbf { y } _ { 1 } ^ { 1 } , \mathbf { y } _ { 1 } ^ { 2 } , \cdots , \mathbf { y } _ { i } ^ { 1 } , \mathbf { y } _ { i } ^ { 2 } , \cdots , \mathbf { y } _ { p } ^ { 1 } , \mathbf { y } _ { p } ^ { 2 } \right] _ { q \times 2 p } Y=[y11,y12,⋯,yi1,yi2,⋯,yp1,yp2]q×2p
其中 Y \mathbf { Y } Y 为网络经过 LRN 层得到的结果, q = 128 q=128 q=128 为输出的特征向量维度。
定义距离矩阵为:
D = [ d i j ] p × p 其 中 d i j = ∥ y i 2 − y j 1 ∥ 2 ( ∥ ∥ 2 is L 2 norm ) \mathbf { D } = \left[ d _ { i j } \right] _ { p \times p } \\ 其中 \; d _ { i j } = \left\| \mathbf { y } _ { i } ^ { 2 } - \mathbf { y } _ { j } ^ { 1 } \right\| _ { 2 } \left( \| \| _ { 2 } \text { is } L _ { 2 } \text { norm } \right) D=[dij]p×p其中dij=∥∥yi2−yj1∥∥2(∥∥2 is L2 norm )
这个 D \mathbf { D } D 可以直接用一个矩阵乘法计算:
D = 2 ( 1 − Y 1 T Y 2 ) 其 中 Y s = [ y 1 s , ⋯ , y i s , ⋯ , y p s ] q × p , ( s = 1 , 2 ) \mathbf { D } = \sqrt { \mathbf { 2 } \left( \mathbf { 1 } - \mathbf { Y } _ { \mathbf { 1 } } ^ { \mathbf { T } } \mathbf { Y } _ { \mathbf { 2 } } \right) } \\ 其中 \; \mathbf { Y } _ { \mathbf { s } } = \left[ \mathbf { y } _ { 1 } ^ { s } , \cdots , \mathbf { y } _ { i } ^ { s } , \cdots , \mathbf { y } _ { p } ^ { s } \right] _ { q \times p } , ( s = 1,2 ) D=2(1−Y1TY2)其中Ys=[y1s,⋯,yis,⋯,yps]q×p,(s=1,2)
其中 D \mathbf { D } D 包含 p 2 p ^ { 2 } p2 个 patch pairs 的距离,其中 p p p 个是正样本(矩阵对角线元素), p 2 − p p ^ { 2 } - p p2−p 个负样本(矩阵除对角线之外元素)。
根据上面的叙述,假设有 160 K 160K 160K 的 3D 点,设置 p = 128 p = 128 p=128,那么每个 training epoch 包含 2500 2500 2500 个上面的 traning batches,大概 40 M ( 12 8 2 × 2500 ) 40 \mathrm { M } \left( 128 ^ { 2 } \times 2500 \right) 40M(1282×2500) patch pair(这里虽然总共training batch只有 128 × 2 128 \times 2 128×2 个 patches,但是参入计算的 pairs 是 12 8 2 128^{2} 1282)。
而且总共需要训练 40 个 epoches,这样将近 16 亿个 pairs 需要计算,除了大量的负样本外,正样本数目大概为 12.8 M ( 128 × 2500 × 40 ) 12.8 \mathrm { M } ( 128 \times 2500 \times 40 ) 12.8M(128×2500×40)。
这里有个问题是每个 training batch 包含 128 × 2 128 \times 2 128×2 个patches,每个 patch 除了与自身和匹配的 patch 外,其实和其他所有的 patches 都能计算一个距离当做负样本的,但本文只选择了匹配 patch pair 中的一个来计算负样本。如果按照全部计算的话,那么 D \mathbf { D } D 公式 Y 1 T Y 2 \mathbf { Y } _ { 1 } ^ { \mathrm { T } } \mathbf { Y } _ { 2 } Y1TY2 就变成了 Y T Y \mathbf { Y } ^ { \mathbf { T } } \mathbf { Y } YTY,这样结果中对角线值都为 0,表示 patch 自身的距离,而其中正样本和负样本都在非对角线元素上,这样不仅仅是计算量增加,更多的是带来不好去计算梯度,增加了计算的复杂度。而且本文也测试过使用该方法,但是性能并没有太提高。
Loss 函数
根据上面的递进采用策略,loss 函数包含三个目标函数:
- 利用相对距离区分匹配上和未匹配上的 patch pairs;
- 考虑最后输出特征向量的 compactness,也就是特征向量的各个维度尽可能不相关;
- 学习过程中间的 feature maps 进行额外的监督,可以得到更好的性能;
描述符相似度的误差项
loss error 基于相对距离,nearest neighbor 是哪个匹配上的 patch pairs。在 D \mathbf { D } D 里面就是:
min ( i , j ) ∈ [ 1 , p ] { d i k , d k j } = d k k \min _ { ( i , j ) \in [ 1 , p ] } \left\{ d _ { i k } , d _ { k j } \right\} = d _ { k k } (i,j)∈[1,p]min{dik,dkj}=dkk
行列拆开来看就是:
{ min i ∈ [ 1 , p ] { d i k } = d k k min j ∈ [ 1 , p ] { d k j } = d k k \left\{ \begin{aligned} \min _ { i \in [ 1 , p ] } \left\{ d _ { i k } \right\} & = d _ { k k } \\ \min _ { j \in [ 1 , p ] } \left\{ d _ { k j } \right\} & = d _ { k k } \end{aligned} \right. ⎩⎪⎨⎪⎧i∈[1,p]min{dik}j∈[1,p]min{dkj}=dkk=dkk
这就很好理解了,也就是 k k k 行或者 k k k 列最小的那个 distance 都必须是对角线上元素 d k k d _ { k k } dkk,也就是匹配上的那个 patch pair 的 distance。
为了实现上的简单,行列分开计算,如下:
S c = [ s i j c ] p × p 列 相 似 度 矩 阵 其 中 s i j c = exp ( 2 − d i j ) / ∑ m exp ( 2 − d m j ) S r = [ s i j r ] p × p 行 相 似 度 矩 阵 其 中 s i j r = exp ( 2 − d i j ) / ∑ n exp ( 2 − d j n ) \mathbf { S } ^ { c } = \left[ s _ { i j } ^ { c } \right] _ { p \times p } \; 列相似度矩阵 \\ 其中 \; s _ { i j } ^ { c } = \exp \left( 2 - d _ { i j } \right) / \sum _ { m } \exp \left( 2 - d _ { m j } \right) \\ \mathbf { S } ^ { r } = \left[ s _ { i j } ^ { r } \right] _ { p \times p } \; 行相似度矩阵 \\ 其中 \; s _ { i j } ^ { r } = \exp \left( 2 - d _ { i j } \right) / \sum _ { n } \exp \left( 2 - d _ { j n } \right) Sc=[sijc]p×p列相似度矩阵其中sijc=exp(2−dij)/m∑exp(2−dmj)Sr=[sijr]p×p行相似度矩阵其中sijr=exp(2−dij)/n∑exp(2−djn)
其中 2 2 2 是两个单位向量的最大距离。
其中 S i j c \mathcal { S } _ { i j } ^ { c } Sijc 可以被认为 y i 2 y _ { i } ^ { 2 } yi2 匹配上 y j 2 y _ { j } ^ { 2 } yj2 的可能性,同理 S i j r \mathcal { S } _ { i j } ^ { r } Sijr 可以被认为 y i 1 y _ { i } ^ { 1 } yi1 匹配上 y j 2 y _ { j } ^ { 2 } yj2 的可能性。也就是对 D \mathbf { D } D 每一行和每一列当做一个分类任务,分别求 softmax 得到 S c \mathbf { S } ^ { c } Sc 和 S r \mathbf { S } ^ { r } Sr,最终 loss error 值为(类似 softmax loss, − l o g -log −log):
E 1 = − 1 2 ( ∑ i log s i i c + ∑ i log s i i r ) E _ { 1 } = - \frac { 1 } { 2 } \left( \sum _ { i } \log s _ { i i } ^ { c } + \sum _ { i } \log s _ { i i } ^ { r } \right) E1=−21(i∑logsiic+i∑logsiir)
描述符 compactness 的误差项
实验中发现 overfitting 的程度和特征描述符各维度之间的关联度是正相关的,本文提出一种计算描述符 compactness (即各个维度直接关联度)的误差项来防止过拟合。描述符 compactness 表示各个维度之间信息没有冗余,而每个维度可以表示ge那个可能多的信息,这样和冗余情况相比更少的维度可以达到相同的性能,另一角度看同样的维度下描述符 compactness 程度越高,就可以表示更多的信息,一定层度可以减少 overfitting。
compactness 在之前的一些二进制描述符工作中经常被使用,如 BOLD 和 RFD,通常是采用暴力的查找选择那些变化比较大的 bits,对于描述符的某个维度来说,在大量描述符数据上如果该维度变化越大,一般就是指方差越大,可以说明该维度信息有效性越高。
本文也采用了该思想,而且为了使该过程可进行反向传播,尝试使用相关系数矩阵(correlation matrix),具体公式为:
R s = [ r i j s ] q × q r i j s = ( b i s − b i s ‾ ) T ( b j s − b j s ‾ ) ( b i s − b i s ‾ ) T ( b i s − b i s ‾ ) ( b j s − b j s ‾ ) T ( b j − b j s ‾ ) Y s T as [ b 1 s , ⋯ , b i s , ⋯ , b q s ] 其 中 b i s 是 行 向 量 , 代 表 p 个 p a t c h 的 描 述 符 的 第 i 个 维 度 集 合 \mathbf { R } _ { s } = \left[ r _ { i j } ^ { s } \right] _ {q \times q} \\ r _ { i j } ^ { s } = \frac { \left( \mathbf { b } _ { i } ^ { s } - \overline { { b } _ { i } ^ { s } } \right) ^ { T } \left( \mathbf { b } _ { j } ^ { s } - \overline { { b } _ { j } ^ { s } } \right) } { \sqrt { \left( \mathbf { b } _ { i } ^ { s } - \overline { { b } _ { i } ^ { s } } \right) ^ { T } \left( \mathbf { b } _ { i } ^ { s } - \overline { { b } _ { i } ^ { s } } \right) } \sqrt { \left( \mathbf { b } _ { j } ^ { s } - \overline { { b } _ { j } ^ { s } } \right) ^ { T } \left( \mathbf { b } _ { j } - \overline { { b } _ { j } ^ { s } } \right) } } \\ \mathbf { Y } _ { \mathbf { s } } ^ { \mathbf { T } } \text { as } \left[ \mathbf { b } _ { 1 } ^ { s } , \cdots , \mathbf { b } _ { i } ^ { s } , \cdots , \mathbf { b } _ { q } ^ { s } \right] \; 其中 \mathbf { b } _ { i } ^ { s } 是行向量,代表 p 个 patch 的 描述符的第 i 个维度集合 Rs=[rijs]q×qrijs=(bis−bis)T(bis−bis)(bjs−bjs)T(bj−bjs)(bis−bis)T(bjs−bjs)YsT as [b1s,⋯,bis,⋯,bqs]其中bis是行向量,代表p个patch的描述符的第i个维度集合
其中 b j s ‾ \overline { { b } _ { j } ^ { s } } bjs 是 Y s \mathbf { Y } _ { \mathbf { s } } Ys 第 i i i 行的均值。
优化目标是希望该相关系数矩阵 R s \mathbf { R } _ { s } Rs 的非对角线元素之都为 0,简化得到误差项为:
E 2 = 1 2 ( ∑ i ≠ j ( r i j 1 ) 2 + ∑ i ≠ j ( r i j 2 ) 2 ) E _ { 2 } = \frac { 1 } { 2 } \left( \sum _ { i \neq j } \left( r _ { i j } ^ { 1 } \right) ^ { 2 } + \sum _ { i \neq j } \left( r _ { i j } ^ { 2 } \right) ^ { 2 } \right) E2=21⎝⎛i̸=j∑(rij1)2+i̸=j∑(rij2)2⎠⎞
实际中这个 s = 1 s =1 s=1 和 s = 2 s = 2 s=2 是同时输入,在计算时做了区分。
E 2 E _ { 2 } E2 是在 LRN 层之间计算的,主要是前面正好是 BN 层,做了 mean 和 scale 处理,所以最好简化为:
R s = Y s Y s T / q \mathbf { R } _ { s } = \mathbf { Y } _ { s } \mathbf { Y } _ { s } ^ { \mathbf { T } } / q Rs=YsYsT/q
中间 feature maps 误差项
本文对学习过程中间的 feature maps 进行额外的监督,进一步提供性能。该误差项思路和 E 1 E _ { 1 } E1 完全类似,就是匹配上 patch pairs 的中间 feature maps 尽可能相似,而非匹配的则是尽可能不同。
这里定义第 k k k 层输出的 feature maps 为:
F = [ f 1 1 , f 1 2 , ⋯ , f i 1 , f i 2 , ⋯ , f p 1 , f p 2 ] ( w h ) × 2 p 其 中 f i s 是 向 量 化 的 f e a t u r e m a p , 长 度 为 w h \mathbf { F } = \left[ \mathbf { f } _ { 1 } ^ { 1 } , \mathbf { f } _ { 1 } ^ { 2 } , \cdots , \mathbf { f } _ { i } ^ { 1 } , \mathbf { f } _ { i } ^ { 2 } , \cdots , \mathbf { f } _ { p } ^ { 1 } , \mathbf { f } _ { p } ^ { 2 } \right] _ { ( w h ) \times 2 p } \\ 其中 \; \mathbf { f } _ { i } ^ { s } 是向量化的feature \; map,长度为wh F=[f11,f12,⋯,fi1,fi2,⋯,fp1,fp2](wh)×2p其中fis是向量化的featuremap,长度为wh
和上面描述符 distance 计算很类似,中间 feature maps 的内积矩阵为:
G = [ g i j ] p × p G = ( F 1 ) T F 2 F s = [ f 1 s , ⋯ , f i s , ⋯ , f p s ] ( w h ) × p ( s = 1 , 2 ) \mathbf { G } = \left[ g _ { i j } \right] _ { p \times p } \\ \mathbf { G } = \left( \mathbf { F } _ { 1 } \right) ^ { \mathbf { T } } \mathbf { F } _ { 2 } \\ \mathbf { F } _ { s } = \left[ \mathbf { f } _ { 1 } ^ { s } , \cdots , \mathbf { f } _ { i } ^ { s } , \cdots , \mathbf { f } _ { p } ^ { s } \right] _ { ( w h ) \times p } ( s = 1,2 ) G=[gij]p×pG=(F1)TF2Fs=[f1s,⋯,fis,⋯,fps](wh)×p(s=1,2)
和上面描述符相似度的误差项计算也很类似,中间 feature maps 误差项为:
{ min i ∈ [ 1 , p ] { g i k } = g k k min i ∈ [ 1 , p ] { g k j } = g k k \left\{ \begin{aligned} \min _ { i \in [ 1 , p ] } \left\{ g _ { i k } \right\} & = g _ { k k } \\ \min _ { i \in [ 1 , p ] } \left\{ g _ { k j } \right\} & = g _ { k k } \end{aligned} \right. ⎩⎪⎨⎪⎧i∈[1,p]min{gik}i∈[1,p]min{gkj}=gkk=gkk
同样行列分开计同样如下:
V c = [ v i j c ] p × p 列 相 似 度 矩 阵 v i j c = exp ( g i j ) / ∑ m exp ( g m j ) V r = [ v i j r ] p × p 行 相 似 度 矩 阵 v i j r = exp ( g i j ) / ∑ n exp ( g j n ) \mathbf { V } ^ { c } = \left[ v _ { i j } ^ { c } \right] p \times p \; 列相似度矩阵 \\ v _ { i j } ^ { c } = \exp \left( g _ { i j } \right) / \sum _ { m } \exp \left( g _ { m j } \right) \\ \mathbf { V } ^ { r } = \left[ v _ { i j } ^ { r } \right] _ { p \times p } \; 行相似度矩阵 \\ v _ { i j } ^ { r } = \exp \left( g _ { i j } \right) / \sum _ { n } \exp \left( g _ { j n } \right) Vc=[vijc]p×p列相似度矩阵vijc=exp(gij)/m∑exp(gmj)Vr=[vijr]p×p行相似度矩阵vijr=exp(gij)/n∑exp(gjn)
最终 loss error 值为(类似 softmax loss, − l o g -log −log):
E 3 = − 1 2 ( ∑ i log v i i c + ∑ i log v i i r ) E _ { 3 } = - \frac { 1 } { 2 } \left( \sum _ { i } \log v _ { i i } ^ { c } + \sum _ { i } \log v _ { i i } ^ { r } \right) E3=−21(i∑logviic+i∑logviir)
这里提出的方法为 Discriminative Intermediate Feature maps (DIF),实验证明 DIF 应用在 normalized feature maps 后更好。本文把 DIF 放在 BN 层后面,具体的是放在 first 和 last 的 BN 层后面。主要是 first BN 层之间跟着输入数据,last BN 层后面直接跟着输出,这样 feature maps 的顺序相对固定。 不太理解这个顺序影响。
最终的误差项
E 1 E _ { 1 } E1 跟在最后的输出后面, E 2 E _ { 2 } E2 跟在 last BN 层后面, E 3 E _ { 3 } E3 跟在first 和 last 的 BN 层后面。最终的误差项为:
E = E 1 + E 2 + E 3 E = E _ { 1 } + E _ { 2 } + E _ { 3 } E=E1+E2+E3
Training
L2-Net 没有预训练,直接从 scratch 开始训练。CS L2-Net 则是用训练好的 L2-Net 去初始化,两个分支都进行初始化,不过在训练时左边分支参数固定不进行 finetune,只是右边分支参数更新进行 finetune。
设置 p 1 = p 2 = q / 2 = 64 p 1 = p 2 = q / 2 = 64 p1=p2=q/2=64,其他超参和具体训练过过程参考论文。
实验
Brown
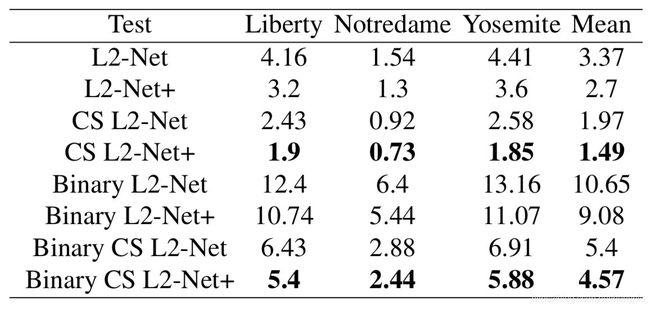
按照 Brown 数据集提出的方法进行评价,大概 100 K 100K 100K pairs,然后比较 false positive rate at 95% recall。结果如下图所示:

其中 + 表示做了 data augmentation。
其中 Binary 前缀表示根据 float 描述符的正负进行二值化,得到的 binary 的描述符,并比较性能。
同时本文还在 HPatches 上 train,在 Brown 数据集上 test,结果如下图所示:
Oxford
为了验证方法的泛化能力,在 Oxford 数据集上进行测试。在该数据集的 6 个图像序列上进行测试,分别是 graf (viewpoint),bikes(blur),ubc(JPEG compression),leuven(light),boat(zoom 和 rotation) 和 wall(viewpoint)。每个图像序列包括 6 张图像,每个序列是按照相对于第一张图像 distortions 程度递增的序列排列。在测试过程中,图像中的 keypoints 是用 Harris-Affine 方法检测得到,patches 统一归一化到 32 × 32 32 \times 32 32×32 大小(对于 DeepDesc 和 TNet-TGLoss 大小是 64 × 64 64 \times 64 64×64)。文中说 scale=3 不理解啥意思。

其中这里主要比较的是 m A P mAP mAP。
竖直分隔线前面表示都在 Liberty(来自 Brown) 数据集上训练(DeepDesc 除外,是在 Liberty 和 Notredame 两个数据集上训练)。从中可以看出, CS 结构不能完全保证性能的提高,主要是因为 CS 结果需要 crop patch 的中间部分,怎么取选择 patch 的scale 是一个问题。Brown 和 Hpatches 数据集的 patches 基本是 scale 比较类似,所以效果比较好。但是应用到不同的检测器以及 scale 上,可能任意 crop (patch 的 50%) 出来的包含的纹理信息很少,所以导致效果不好。本文从结果中还发现,CNN 特征学习的方法对 blur 的情况比较敏感。咋解释??
竖直线后面的表示本文提出的方法分别在 Liberty,Notredame,Yosemite 和 HPatches 上训练,在 Oxford 测试的性能结果。从结果可以看出,在 HPatches 数据集上训练的网络泛化性能更好。
HPatches
关于 HPatches 数据集的评测结果,具体查看 [2016 DescrWorkshop][http://icvl.ee.ic.ac.uk/DescrWorkshop/],L2-Net 方法在 HPatches 上三个任务上都是第一。
实用指南
compactness 的重要性
本文实验过在训练过程不加 E 2 E _ { 2 } E2,结果导致训练不收敛。文中给的解释是,如果没有 E 2 E _ { 2 } E2 的限制会导致 overfitting 比较严重,然后特征向量维度直接的关联性也比较大。
相对 distance 的优势
本文使用的 E 1 E_{1} E1 和 之前的 hinge loss 有很大的区别, patch pair 和 triplet 的 hinge loss 如下:
E p a i r = δ i j max ( 0 , ∥ y i − y j ∥ 2 − t p ) + ( 1 − δ i j ) max ( 0 , t n − ∥ y i − y j ∥ 2 ) E t r i p l e t = max ( 0 , 1 − ∥ y i − y i − ∥ 2 ∥ y i − y i + ∥ 2 + t ) \begin{array} { l } { E _ { p a i r } = \delta _ { i j } \max \left( 0 , \left\| \mathbf { y } _ { i } - \mathbf { y } _ { j } \right\| _ { 2 } - t _ { p } \right) } { + \left( 1 - \delta _ { i j } \right) \max \left( 0 , t _ { n } - \left\| \mathbf { y } _ { i } - \mathbf { y } _ { j } \right\| _ { 2 } \right) } \\ { E _ { t r i p l e t } = \max \left( 0,1 - \frac { \left\| \mathbf { y } _ { i } - \mathbf { y } _ { i } ^ { - } \right\| _ { 2 } } { \left\| \mathbf { y } _ { i } - \mathbf { y } _ { i } ^ { + } \right\| _ { 2 } + t } \right) } \end{array} Epair=δijmax(0,∥yi−yj∥2−tp)+(1−δij)max(0,tn−∥yi−yj∥2)Etriplet=max(0,1−∥yi−yi+∥2+t∥yi−yi−∥2)
其中 δ i j = 1 \delta _ { i j } = 1 δij=1,如果 y i { y } _ { i } yi 和 y j { y } _ { j } yj 匹配上,反之 δ i j = 0 \delta _ { i j } = 0 δij=0。
其中 t p t _ { p } tp, t n t _ { n } tn 和 t t t 都是阈值参数。
这两个公式比较好理解,这里就不详细解释了,该 loss 主要的缺点是由于阈值导致的不稳定的梯度。而且不能确定一个 training batch 里面多少样本对整体梯度起作用,这样不稳定的梯度很可能导致优化到坏的局部最小。所以后面很多工作希望用 hard sample mining 来解决这个问题,但也会带来一个更严格的采样阈值。而使用相对 distance 不涉及到绝对的 distance,所以不会引入阈值。
DIF 的有效性
第一种测试,在实际训练中移除 E 3 E_{3} E3 来验证 DIF 的有效性;第二种测试,在实际训练的每个 BN 层后面都加入 DIF 测试性能。比较结果如下图所示:
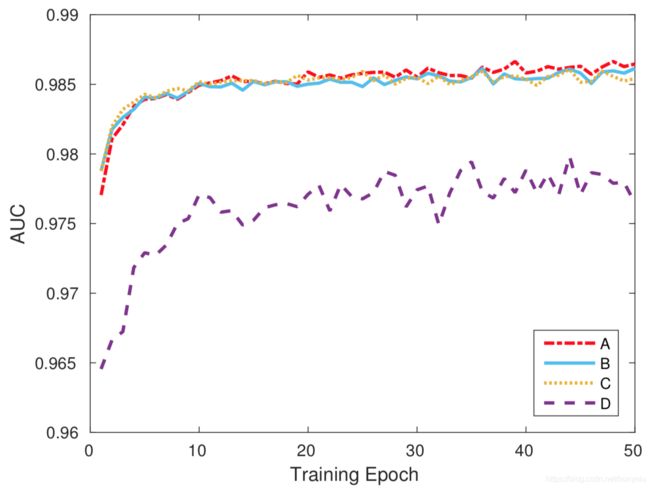
其中 AUC 具体含义参考:ROC曲线和AUC值
其中这里显示的是 L2-Net 是在 Hpatches 数据集上然后在 Brown 数据集上测试的结果(三个子集的平均值)。
其中 Curve A 表示默认配置,Curve B表示不加 DIF,即不加 E 3 E_{3} E3 ,Curve C 表示设置 BN 层参数为可学习的(用于验证 BN 不同条件下的效果),Curve D 表示每个 BN 层后面都加入 DIF 测试性能。
从上面结果可以看出,加上 DIF 确实比不加效果要好一点。 但感觉作用没有那么大??? 而且加多了明显效果会变差,文中解释说是限制了网络的解空间。。。
BN 层
在上面一节中 Curve A 和 Curve C 的对比,发现性能变化不大。
假设 a ∼ N ( μ 1 , σ 1 ) a \sim N \left( \mu _ { 1 } , \sigma _ { 1 } \right) a∼N(μ1,σ1) 和 b ∼ N ( μ 2 , σ 2 ) b \sim N \left( \mu _ { 2 } , \sigma _ { 2 } \right) b∼N(μ2,σ2) 为两个随机的服从高斯分布的变量。如果要区分这两个变量,最简单的方法就是增加 ∣ μ 1 − μ 2 ∣ \left| \mu _ { 1 } - \mu _ { 2 } \right| ∣μ1−μ2∣ 以及减少 ∣ σ 1 ∣ \left| \sigma _ { 1 } \right| ∣σ1∣ 和 $ \left| \sigma _ { 2 } \right|$,其实就是增加两个高斯的 bias,减少分布的不同。同理学习 BN 的两个参数就会导致学习到的描述符非常 sharp 而且都是非零分布,这样破坏了描述符的性能。而固定则表示每个 patch 的 feature maps 都是独立分布的,这样网络就会学习分布的不同,而不是 bias的不同。
Binary 描述符
虽然说 binary 描述符是从 float 描述符简单的生成的,但这里也想给出一些说明。从不同的 3D 点中随机选取 100 K 100K 100K 个 patches 去探索生成的描述符中值的分布情况。分布结果如下图所示:
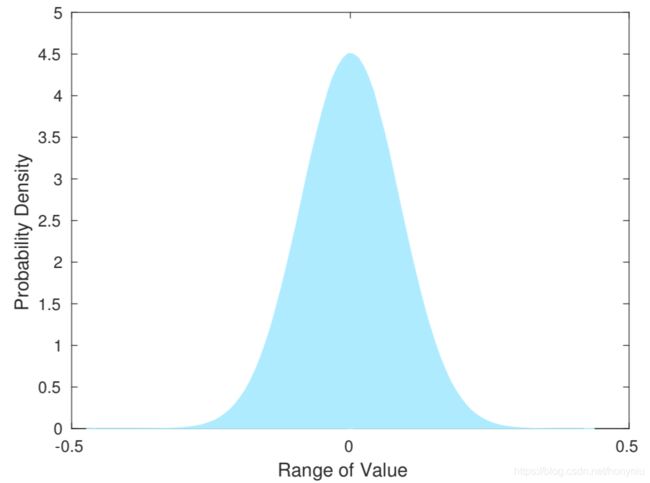
可以看出描述符的值服从 mean 为 0 的高斯分布。
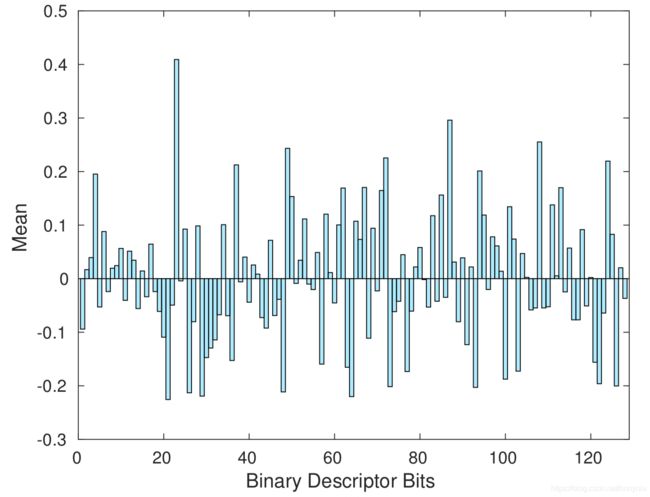
Binary 描述符每个 bit 在大量 patches 上的均值非常靠近 0,这是一个好的 binary 描述符具有的属性。具体结果如下图所示:
训练和提取速度
训练速度参考论文,提取速度为 21.3 K p a t c h / s e c 21.3K \; patch/sec 21.3Kpatch/sec,在 GTX 970 GPU 上。