第三章 K最近邻算法-近朱者赤,近墨者黑
3.1 kNN原理
- 在分类上, 原理是取最近的k个点, 按这些点的类标签来决定未知点的类型.
- 在回归上, 取最近k个点的y值取平均作为预测值.
- 默认的k是5, 根据经验可以调5, 10. 参数最好要优化.
-
metric和p可以改变距离的测量. weights可以改变各特征的权重(默认均等).
TODO: 如果分类时, k个点最多的类有2甚至3种, 是根据最近原则来确定类么?
3.2 kNN的用法
这里作者用了一个自建数据集和红酒数据集做测试, 针对分类和回归的应用都做了展示.
-
neighbors.KNeighborsClassifier能用于kNN分类. -
neighbors.KNeighborsRegressor能用于kNN回归 (取邻近的k个点的y值平均) - 一般习惯地,
clf代表分类器,reg代表回归器.
3.2.1 kNN在简单分类的应用
sklearn.datasets子模块是针对数据集的一个模块, 内含几个toy datasets, 另外, 也可以下载更大的数据集, 或者自己产生数据集. 这章书使用make_blobs来产生分类点, 使用make_regression来产生回归使用的点.
make_blobs 产生数据集
使用datasets.make_blobs 可以产生分类的数据点, 见下面例子.
-
make_blobs: 产生各同向性Gaussian blobs用于聚类. 返回(features, labels)的两个数组.-
n_samples=100: 产生点数. 如果给的是数组, 数组中每个元素是每个类的点数. -
n_features=2: 特征数. -
centers=None: 产生分类数(标签). 如果给定了n_samples, 而centers为None, 则会产生三个中心 -
cluster_std=1.0: 类的标准差. -
center_box=(-10.0, 10.0): 一个类的边界,(min,max) -
shuffle=True: 对样本洗牌. -
random_state=None: 随机状态.
-
# 导入数据集, 分类器, 画图工具, 数据集拆分工具
from sklearn.datasets import make_blobs
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
# 生成样本数200, 分类为2类的数据集,
data = make_blobs(n_samples=200, n_features=2, centers=2, random_state=8)
X, y = data
# 将生成的数据集进行可视化
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.spring, edgecolors='k')
plt.show()

- 该例子产生的是两个类, 为了便于可视化, 使用2个特征.
- 产生的返回值是
(features, labels)两个数组, 分别给了X和y.- 一般地, 大写X是多维数据(矩阵), 特征时用; y是一维数组(向量), 一般标签用.
scatter作散点图, 前两个是X轴和Y轴坐标(用的是特征1和特征2), c=y是指定颜色对应的是标签(0/1)
创建kNN分类模型
- 使用
neighbors.KNeighborsClassifier可以创建分类模型, 有很多参数可调, 最常用n_neighbors指定k值. - 创建的对象就是一个分类器. 或者说是模型. 使用
fit(X,y)方法可以进行训练, 使用predict(X)可以进行预测(返回相应标签y). - 模型训练使用训练集, 训练一次后即可进行多次的预测.
- 下面的例子使用上面的测试集进行训练(整个集作为训练集). 一般要将数据分割成训练集和测试集来测试.
- 为可视化表征模型, 作者创建了网格(
np.meshgrid, 格点距离0.02, 范围覆盖坐标), 并用网格的坐标利用模型进行预测(这步很费时), 预测值就是网格对应的类, 再结合plt.pcolormesh将坐标内根据类标签用不同颜色表示. -
array.ravel()可以将多维数组一维化.np.c_[A, B]可以将后面的slice中给定的数组连结为2D数组.
# 拟合
import numpy as np
clf = KNeighborsClassifier()
clf.fit(X, y)
# 画图
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
# 空间虚拟点的预测值
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Pastel1)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.spring, edgecolor='k')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("Classifier:KNN")
plt.show()

预测新点的分类
输入一个数据点的特征([[6.75,4.82]],注意两层中括号, 一层是元素, 一层是特征), 肉眼可见再灰色一类(类1). 进行预测, 其结果和观察一致.
# 加入新数据点, 并五星标记
plt.scatter(6.75, 4.82, marker='*', c='red', s=200)
plt.show()
# 对新点进行预测, 并显示其分类
print('新数据点的分类是:',clf.predict([[6.75,4.82]]))

新数据点的分类是: [1]
3.2.2 kNN在多元分类的应用
后续测试了复杂一点的5类点的例子(用下面的代码, 去掉random_state, 可以产生各色各样的点分类图), 下面选的这个分类有点麻烦, 因为有两个类粘在一起了. 如果是分得比较开的类, 后续的测试结果会好很多.
# 样品量500, 5类, 2特征, 还是设定种子8
data2 = make_blobs(n_samples=500,n_features=2, centers=5, random_state=8)
X2,y2 = data2
# 散点图可视化
plt.scatter(X2[:,0],X2[:,1],c=y2, cmap=plt.cm.spring,edgecolor='k')
plt.show()
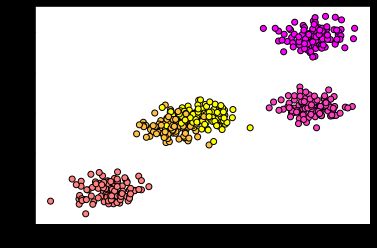
类似地, 进行拟合和模型显示. 可以看出中间两个类太接近了.
# kNN算法建立模型
clf = KNeighborsClassifier()
clf.fit(X2,y2)
#下面的代码用于画图
x_min, x_max = X2[:, 0].min() - 1, X2[:, 0].max() + 1
y_min, y_max = X2[:, 1].min() - 1, X2[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),
np.arange(y_min, y_max, .02))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Pastel1)
plt.scatter(X2[:, 0], X2[:, 1], c=y2, cmap=plt.cm.spring, edgecolor='k')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("Classifier:KNN")
plt.show()

print('模型正确率:{:.2f}'.format(clf.score(X2,y2)))
# 模型正确率:0.96
这里的正确率(score)实际是正确样本数/总样本数, 500点的话, 就是错了20个点. 如果样本分类分离较好, 则正确率会上升, 例如:

TODO: 怎么知道此时的随机种子是多少??
整体而言, kNN在分类时的效果还是不错的. 不过这里没有做训练集和测试集分离的测试.
如果想分割成训练集和测试集, 可以:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X2,y2,test_size=0.2)
clf2 = KNeighborsClassifier()
clf2.fit(X_train, y_train)
print('模型正确率:{:.2f}'.format(clf2.score(X_test, y_test)))
# 模型正确率:0.92
### 在不设随机值时, 正确率在0.91~0.97间波动
3.2.3 kNN用于回归分析
首先使用make_regression 创建一个数据集, 然后用KNeighborsRegressor 构建回归模型. 最后看看影响因素. 对比kNN用于分类, 回归的效果要差些.
-
make_regression: 产生随机回归问题的数据点.-
n_samples=100: 数据点数. -
n_features=100: 特征数.默认100个变量. -
n_targets=1:目标值的向量的大小. 默认是一个标量值. -
n_informative=10: 有效特征数. 用于构建模型使用的特征数. -
noise=0.0: 高斯噪音的标准差. -
bias=0.0: 偏差. 体现出来类似截距, 但不是一个概念. -
effective_rank=None: -
tail_strength=0.5: -
coef=False: 如设置为True, 返回时会返回线性模型的特征的系数. -
shuffle=True,random_state=None: 同上. - 返回
(X, y, coef), coef要在参数设置后才有返回.
-
这里构建了100样本(默认), 特征数1, 有效特征1, 噪音标准差50的数据集.
# 使用make_regression 生成特征1,噪音50
from sklearn.datasets import make_regression
X, y = make_regression(n_features=1,n_informative=1,noise=50,random_state=8)
plt.scatter(X,y,c='orange',edgecolor='k')
plt.show()

# 导入kNN回归分析的模型
from sklearn.neighbors import KNeighborsRegressor
reg = KNeighborsRegressor()
# 拟合数据并评分
reg.fit(X,y)
print('模型评分:{:.2f}'.format(reg.score(X,y)))
# 预测结果可视化.
z = np.linspace(-3,3,200).reshape(-1,1)
plt.scatter(X,y,c='orange',edgecolor='k')
plt.plot(z, reg.predict(z),c='k',linewidth=3)
plt.title('KNN Regressor')
plt.show()

# 导入kNN回归分析的模型
from sklearn.neighbors import KNeighborsRegressor
reg2 = KNeighborsRegressor(n_neighbors=20)
# 拟合数据并评分
reg2.fit(X,y)
print('模型评分:{:.2f}'.format(reg2.score(X,y)))
# 预测结果可视化.
z = np.linspace(-3,3,200).reshape(-1,1)
plt.scatter(X,y,c='orange',edgecolor='k')
plt.plot(z, reg2.predict(z),c='k',linewidth=3)
plt.title('KNN Regressor: n_neighbors=20')
plt.show()
# k = 2: 模型评分:0.86
# k = 5: 模型评分:0.77 (上面默认的5)
# k = 10: 模型评分:0.75
# k = 20: 模型评分:0.67
# k = 50: 模型评分:0.54




从上述可以看出, 随着k的增大, 评分下降. 但k太小的时候, 显然存在一定过拟合的情况.
# 尝试使用线性回归求解
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X,y)
print('模型评分:{:.2f}'.format(lr.score(X,y)))
# 预测结果可视化.
z = np.linspace(-3,3,200).reshape(-1,1)
plt.scatter(X,y,c='orange',edgecolor='k')
plt.plot(z, lr.predict(z),c='k',linewidth=3)
plt.title('Linear Regressor')
plt.show()
# 模型评分: 0.69

对比线性回归, kNN=20时较为接近. 太大时拟合不好, 太小时过拟合.
那究竟分开训练集和测试集后是不是能明显看出这种差异呢?
# 重新测试分割训练集合测试集后的效果
# 点数越多, 拟合越稳定, 效果更稳定
X, y = make_regression(n_samples=200, n_features=1,n_informative=1,noise=50,random_state=8)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=4)
# 喜欢的可以把下面的random_state=4去掉,看多个效果
# 测试分割训练集和测试集
for n in [2,5,10,20,50]:
reg3 = KNeighborsRegressor(n_neighbors=n)
reg3.fit(X_train, y_train)
print('训练集评分:{:.2f}'.format(reg3.score(X_train, y_train)))
print('测试集评分:{:.2f}'.format(reg3.score(X_test, y_test)))
# 预测结果可视化.
z = np.linspace(-3,3,200).reshape(-1,1)
plt.scatter(X_train, y_train,c='orange',edgecolor='k')
plt.scatter(X_test, y_test,c='green',edgecolor='k')
plt.plot(z, reg3.predict(z),c='k',linewidth=2)
plt.title('KNN Regressor: n_neighbors=2')
plt.show()
lr2 = LinearRegression()
lr2.fit(X_train, y_train)
print('训练集评分:{:.2f}'.format(lr2.score(X_train, y_train)))
print('测试集评分:{:.2f}'.format(lr2.score(X_test, y_test)))
# 预测结果可视化.
z = np.linspace(-3,3,200).reshape(-1,1)
plt.scatter(X_train, y_train,c='orange',edgecolor='k')
plt.scatter(X_test, y_test,c='green',edgecolor='k')
plt.plot(z, lr2.predict(z),c='k',linewidth=2)
plt.title('Linear Regressor')
plt.show()
- k = 2 训练集评分:0.87 测试集评分:0.66
- k = 5 训练集评分:0.82 测试集评分:0.71
- k = 10 训练集评分:0.80 测试集评分:0.72
- k = 20 训练集评分:0.78 测试集评分:0.76
- k = 50 训练集评分:0.68 测试集评分:0.64
- 线性回归 训练集评分:0.77 测试集评分:0.70
从上面结果来看, 的确存在过拟合现象, 尤其当k=2时最严重. k=5和10差不多, k=20时尽管训练集评分低些, 但测试集评分最高. 当k=50时, 出现欠拟合现象, 训练集和测试集评分均不高.
# 重新测试分割训练集合测试集后的效果
# 点数越多, 拟合越稳定, 效果更稳定
import pandas as pd
kv1 = [100, 200, 500, 1000, 2000]
kv2 = [2, 5, 10, 20, 50]
final_out = []
for sn in kv1:
X, y = make_regression(n_samples=sn, n_features=1,
n_informative=1, noise=50, random_state=8)
output = []
for i in range(100):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=i)
scores = []
# 测试分割训练集和测试集
for n in kv2:
reg3 = KNeighborsRegressor(n_neighbors=n)
reg3.fit(X_train, y_train)
scores += [reg3.score(X_train, y_train), reg3.score(X_test, y_test)]
lr2 = LinearRegression()
lr2.fit(X_train, y_train)
scores += [lr2.score(X_train, y_train), lr2.score(X_test, y_test)]
output.append(scores)
final_out.append(pd.DataFrame(output).mean().tolist())
pd.DataFrame(final_out,
columns=pd.MultiIndex.from_product([['k=2', 'k=5', 'k=10','k=20','k=50','LR']
,['train', 'test']]),
index = kv1).round(decimals=3)

上述做了个多次测试, 主要对采样训练和测试做了随机100次, 而不同的k, 以及不同的样本数的情况. 从上表中可以看到一个比较奇怪的是500样本时比较反常, 因为此时(随机为8)时, 样本点比较分散, 因此回归和kNN的效果都不甚好, 甚至在kNN中的测试集出现了负数.
从上表也可以看出, 当k较小时, 容易出现过拟合, 当k=5或10时, 其实已经比较稳定了, 继续增大时(k=50)部分就出现欠拟合情况(点多的情况, k=50也开始稳定.)在多次的随机训练可以看出, 线性回归在这里的测试表现最佳, 训练和测试的成功率相当.

书中说, k=2时覆盖更多点, 评分比k=5时显著提高. 这实在说得不科学. 上面测试做了更丰富的结果供参考.
3.3 kNN实战 - 酒的分类
其实这部分也没啥.. 和前面大同小异. 主要的差异就是, 继续学习使用sklearn的datasets模块读取已有的数据集.
3.3.1 数据集基本分析
#从sklearn的datasets模块载入数据集
from sklearn.datasets import load_wine
wine_dataset = load_wine()
print("红酒数据集中的键:\n{}".format(wine_dataset.keys()))
# 红酒数据集中的键:
# dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names'])
print('数据概况:{}'.format(wine_dataset['data'].shape))
# 数据概况:(178, 13)
print(wine_dataset['DESCR'])
# .. _wine_dataset:
# Wine recognition dataset
# ------------------------
# **Data Set Characteristics:**
# 后面接了一堆的说明. 只放出有意义的部分
:Summary Statistics:
============================= ==== ===== ======= =====
Min Max Mean SD
============================= ==== ===== ======= =====
Alcohol: 11.0 14.8 13.0 0.8
Malic Acid: 0.74 5.80 2.34 1.12
Ash: 1.36 3.23 2.36 0.27
Alcalinity of Ash: 10.6 30.0 19.5 3.3
Magnesium: 70.0 162.0 99.7 14.3
Total Phenols: 0.98 3.88 2.29 0.63
Flavanoids: 0.34 5.08 2.03 1.00
Nonflavanoid Phenols: 0.13 0.66 0.36 0.12
Proanthocyanins: 0.41 3.58 1.59 0.57
Colour Intensity: 1.3 13.0 5.1 2.3
Hue: 0.48 1.71 0.96 0.23
OD280/OD315 of diluted wines: 1.27 4.00 2.61 0.71
Proline: 278 1680 746 315
============================= ==== ===== ======= =====
:Missing Attribute Values: None
:Class Distribution: class_0 (59), class_1 (71), class_2 (48)
使用 load_xxxx的方法就可以简单地加载该数据集, 其实数据集是一种Bunch对象, 用于数据集的一种容器, 类似于字典, 有key和value. 可使用对象.key 来将键名作为属性来调用. 属性有: 'DESCR', 'data', 'feature_names', 'target', 'target_names', 部分数据集还有如'filename'等.
-
DESCR是数据集的描述. 一个字符串. 这里可以看到, 每个类有多少样本. -
data这里是一个(178,13)的ndarray, 类似地target是(178,1)的数组. -
feature_names和target_names,前者储存了13个feature的名字, 后者储存了对于目标0,1,2类(没有名, Iris集会有花种类名) .
此外, datasets 模块还有不少小数据集:

除此以外, 还能简单地获取更大的一些数据集:
3.3.2 生成训练数据集和测试数据集
使用model_selection模块的train_test_split方法可以将数据集随机分成一定大小的子集. 从而实现训练和测试两步. 前面已经说了, 一般使用大写X来储存多维数据的训练集, 而用小写y储存一位数组(向量).
-
train_test_split方法是个重要方法, 将数组分为随机的训练集和测试集. 须确保数据长度一致.-
*arrays: 等长的可索引化的序列. list, array, scipy-sparse矩阵, pandas dataframe都可以. -
test_size=None: 浮点0-1的话,是测试集的比例; 整数的话是测试集的样品数. 如果None, 根据训练集来定, 如果训练集也是None, 则默认设为0.25. -
train_size=None: 训练集大小或比例, 同上. None的话根据测试集来互补. -
random_state=None: 随机状态,int,RandomState. 对于随机种子想固定时有用. -
shuffle=True: 在分割数据集前进行洗牌(打乱顺序) . -
stratify=None: 分层??? - 返回 list(array), 长度为
2*arrays总数 (给定两个数组(特征和目标值), 会分成4份, 依次是输入数组分成的训练集和测试集,顺序很重要). 例如输入X,y,返回train_X, test_X, train_y, test_y.
-
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(wine_dataset['data'],
wine_dataset['target'], random_state=0)
print('X_train shape:{}'.format(X_train.shape))
print('X_test shape:{}'.format(X_test.shape))
print('y_train shape:{}'.format(y_train.shape))
print('y_test shape:{}'.format(y_test.shape))
# X_train shape:(133, 13)
# X_test shape:(45, 13)
# y_train shape:(133,)
# y_test shape:(45,)
3.3.3 kNN进行建模和预测
和前面类似, 包括了使用fit来拟合(使用训练集X_train, y_train), 使用predict来预测(使用测试集X_test, y_test), 使用score也可以预测并直接评分.
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 1)
knn.fit(X_train, y_train)
print('训练数据集得分:{:.2f}'.format(knn.score(X_train, y_train)))
# 训练数据集得分:1.00
print('测试数据集得分:{:.2f}'.format(knn.score(X_test, y_test)))
# 测试数据集得分:0.76
这里的得分其实是预测正确样本数/总输入样本数.
假设有一瓶新酒, 经测试各种指标后(如酒精含量,某某成分含量等), 可以建立其特征. 利用新特征, 就可以对其进行分类预测:
import numpy as np
X_new = np.array([[13.2,2.77,2.51,18.5,96.6,1.04,2.55,0.57,1.47,6.2,1.05,
3.33,820]])
prediction = knn.predict(X_new)
print("预测新红酒的分类为:{}".format(wine_dataset['target_names'][prediction]))
# 预测新红酒的分类为:['class_2']
kNN在实际应用时, 还要做好特征的处理, 有时特征的权重也很重要, 对高维数据容易拟合欠佳, 对稀疏数据束手无策.