Flink学习(二):集群部署
Flink可以有多种集群模式,例如独立集群、on YARN、Docker、AWS等。
对于独立集群模式,需要有至少两台独立的机器(物理机、虚拟机或者Docker/K8s等容器),其中一台作为Master,剩下的作为Slave,或者称为Worker。
首先需要修改配置文件 conf/flink-conf.yaml,将jobmanager.rpc.address修改为Master机器的地址,然后修改conf/slaves文件,将其他机器的地址写进去,我这边想尝试修改成
localhost:8082
localhost:8083但是运行start-cluster.sh脚本时提示找不到Slave节点,没办法尝试单机集群,不过可以多次运行start-cluster.sh脚本,启动多个TaskManager。
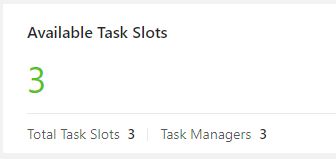
这里有三个Task Slot,代表集群具有的并发能力。也可以单独运行jobmanager.sh或taskmanager.sh,单独添加JobManager或TaskManager:
-
bin/jobmanager.sh ((start|start-foreground) [host] [webui-port])|stop|stop-all -
bin/taskmanager.sh start|start-foreground|stop|stop-all
各节点配置时,需保证Master节点能够免密登录到其他Slave机器。flink-conf.yaml还提供了一些配置项,例如:
jobmanager.heap.size:每个jobmanager的可用内存量taskmanager.heap.size:每个Taskmanager的可用内存量taskmanager.numberOfTaskSlots:每个机器可用的CPU数量parallelism.default:集群总的CPU数,即实际可用的并发数io.tmp.dirs:临时目录
对于基于YARN的集群模式,需要下载嵌入式Hadoop:
然后放到Flink安装目录的lib文件夹下。然后安装并部署Hadoop集群,过程略。
使用Flink on YARN模式,有两种方案,第一种是启动一个长期运行的Flink集群,Flink任务都提交到这个集群中,需要使用bin/yarn-session.sh脚本,该脚本的选项如下:
- -D arg:动态传递配置
- -d,--detached:分离模式,在该模式下,客户端只负责提交任务,然后退出,需要使用YARN来管理Flink集群的生命周期
- -jm,--jobManagerMemory:配置每个JobManager的内存
- -nm,--name:给YARN上的程序设置一个名字
- -q,--query:显示YARN中可用的CPU、内存等资源
- -qu,--queue:指定YARN队列
- -s,--slots:配置每个TaskManager有多少个任务槽
- -tm,--taskManagerMemory:配置每个TaskManager的内存
- -z,--zookeeperNamespace:配置高可用模式下ZK的命名空间
- -id,--applicationId:指定YARN集群的任务ID,附着到一个YARN会话中,使用YARN ResourceManager确定Job Manager的RPC端口
- -n:TaskManager数量
例如: bin/yarn-session -jm 1024m -tm 4096m
添加一个YARN会话,需要使用-id选项
执行Flink任务,类似于本地模式,也是使用 bin/flink run 待运行的Jar包路径
在启动on YARN模式时,也是基于 conf/flink-conf.yaml配置文件的,但是会覆盖jobmanager.rpc.address、io.tmp.dirs等配置,也可以用-D选项传递自定义配置。并且在启动yarn-session.sh之前,必须配置YARN_CONF_DIR或HADOOP_CONF_DIR为环境变量。
第二种启动模式是为每一个Flink任务创建一个新的YARN会话,各任务间互不影响,任务执行完毕后自动结束对应的YARN会话。
使用方法是提交任务时带上-m参数:
./bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar
-m参数指定了需要连接的JobManager地址,这里的yarn-cluster代表了YARN集群的地址,即一个host:port对。
Flink客户端到环境变量指定的Hadoop或YARN配置文件,去找到YARN资源管理器和HDFS地址并连接。在新任务提交时,如果YARN资源可用,就会上传Flink配置和JAR包到HDFS。YARN的AppilicationManager会应Flink客户端请求启动,从而得到JobManager地址,并为TaskManager生成Flink配置,是之和JobManager连接。然后AppilicationManager会为TaskManager分配容器,并把新的配置文件和JAR包从HDFS下载给TaskManager。
还有就是如果需要用到文件作为输入,类似于Hadoop的WordCount示例,需要提前上传到HDFS中,然后通过--input选项,提交hdfs协议的地址。
高可用模式:
一般情况下,每个集群都是一个JobManager,有可能会有单点风险,Flink也提供了高可用(HA)模式。
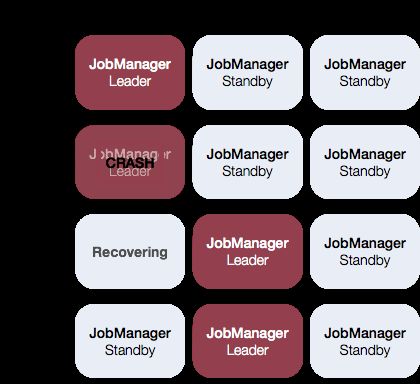
Standalone模式下,高可用需要依赖Zookeeper(ZK)和HDFS,需要预先部署,过程略。
假设现在集群里有3个JobManager,地址分别是 jm00,jm01,jm02
TaskManager、Zokkeeper、Hadoop节点依此类推,分别用tm、zk、hadoop代替
对flink-conf.yaml修改如下:
high-availability: zookeeper
high-availability.zookeeper.quorum: zk00:2181,zk01:2181,zk02:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /default_ns
high-availability.storageDir: hdfs://hadoop00:9000/recovery在conf/masters文件中,添加所有主节点的地址:
jm00:8081
jm01:8081
jm02:8081同样,slaves文件也要添加所有从节点的地址,将配置在其他Flink节点全都复制一份
然后按照Hadoop -> Zookeeper -> Flink的顺序启动即可。
如果是on YARN集群模式,可以借助YARN的任务恢复机制来实现高可用,同样需要Zookeeper和Hadoop。
首先是需要设置Hadoop的YARN提交任务的最大尝试次数,例如3次
然后修改Flink配置,例如:
high-availability: zookeeper
high-availability.zookeeper.quorum: zk00:2181,zk01:2181,zk02:2181
high-availability.zookeeper.path.root: /flink
high-availability.storageDir: hdfs://hadoop00:9000/recovery
yarn.application-attempts: 10然后启动Hadoop、Zookeeper、Flink集群即可。