前一篇文章介绍了机器学习的基本过程,然后讨论了如何对机器学习项目设置期望的问题。我们了解到,度量准确率的指标可以有多种,需要根据应用场景来选择。一旦选好了度量指标,接下来就可以围绕这个指标来划分任务、监控进度、管理风险。
机器学习项目涉及哪些工作
站在非常宏观的角度,机器学习系统工作的方式是:你有一个模型,你把一堆数据输入给它,然后你以某种方式使用它提供给你的输出。所以机器学习项目要完成的任务也是三大块:处理输入;获得模型;提供产出。
处理输入
a. 你需要获得已有的数据
b. 你需要对数据做矢量化操作,把原本丰富多样的数据变成有若干列的矢量
c. 你需要对数据做特征工程,找出可能蕴涵了知识、值得被学习的那些特征项
获得模型
a. 实际上很多时候你可以使用现成的模型,包括:(i)下载现成的离线模型,或者(ii)使用在线的人工智能服务
b. 如果没有现成的模型,你也可以考虑使用现有的数据来自行训练模型
提供产出
a. 机器学习的结果可能通过某种人-机(UI)或机-机界面(API)被用户直接使用
b. 作为项目的产出,机器学习模型需要被嵌入到整个数据流水线中
c. 作为项目的产出,机器学习模型的开发、测试、部署需要有DevOps的支撑
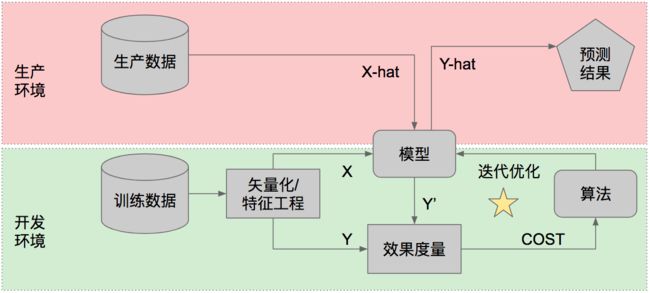
在所有这些任务中,只有2.b“自行训练模型”(上图右下角标星星的部分)需要新的技能和管理方法,其他都是传统的软件开发任务,可以用标准的Scrum等敏捷方法拆分任务和管理。也就是说,如果你需要的人工智能能力已经有一个现成的模型提供,那么整个项目就是一个传统的软件开发项目,只是需要使用一些新的工具或API而已。
下面我们聚焦讨论需要自行训练模型时,这部分工作应该如何拆分、如何管理进度和风险。
自行训练模型的流程
在自行训练模型的情况下,如上图所示,你会用历史数据(X和Y)来训练一个模型,然后用这个模型对未来的生产数据(X-hat)做预测(算出Y-hat)。不论采用什么指标来度量准确率,模型在训练数据上的表现一定好于在生产数据上的表现,这是因为模型从训练数据中“学到”的知识不一定在生产数据中完全重现,或者用黑话来说,模型在训练过程中“拟合”了训练数据的特征。也就是说,如果一个模型对训练数据表现出了95%的准确率(先不管采用哪个准确率指标),其实你并不知道这个模型对生产数据会表现什么水平的准确率,于是你也不知道这个模型是否好到可以上线运行。
为了更有效地衡量模型的表现,我们会在开始训练模型之前先拿出一小部分历史数据(例如全部历史数据的10%)用于测试,整个训练过程不接触这部分数据。于是我们就有了“训练集”(training set)和“测试集”(test set)。很多时候我们还会分出一小部分数据作为“验证集”(validation set),为了简化问题,我们可以先采用“训练集+测试集”这种设置。
把历史数据分成训练集和测试集以后,可以预期,模型在训练集上的表现会优于在测试集上的表现,这两个表现通常都会低于项目期望值。我们把“【模型在训练集上的表现】与【期望值】之间的差距”叫做Bias,把“【模型在训练集上的表现】与【模型在测试集上的表现】之间的差距”叫做Variance。
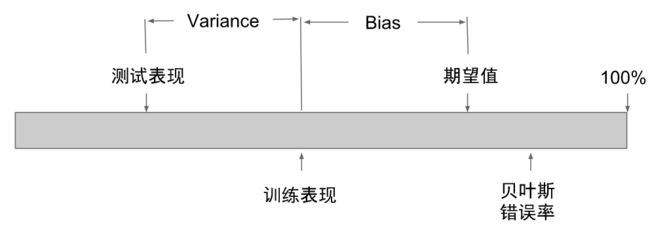
于是就有3种可能的情况:
High Bias:模型在训练集上的表现远低于期望,模型还不能实用(此时Variance如何并不重要);
Low Bias, High Variance:模型在训练集上表现好,但是在测试集上表现差,模型还不能实用;
Low Bias, Low Variance:模型在训练集和测试集上表现都好,可以投入实用。
我们通常会从简单的机器学习算法、手边立即能获得的数据开始尝试。这时候通常Bias会高,因为过于简单的模型不足以呈现数据背后的知识,这时我们说模型“拟合不足”(Under-fitting)。在这种情况下,可以采用的措施包括:
使用更复杂的机器学习算法
使用更复杂的神经网络架构

用更复杂的机器学习算法和神经网络训练出来的模型,通常能更好地拟合训练集,进入“Low Bias”的状态。这时我们再关注模型在测试集上的表现,如果测试集的表现远差于训练集的表现,就说明模型过度地针对训练集的特征做了优化,我们说模型“过度拟合”(Over-fitting)训练数据。在这种情况下可以采用的措施包括:
引入Regularization通常能降低over-fitting的程度
通过特征工程可以避免一些over-fitting的情况,例如排除掉一些严重过度拟合的特征
引入更多的训练数据,包括数据量和特征量
最终我们的目标是得到Bias和Variance双低的模型。
潜在风险点
从上述的工作流程中,我们可以预先识别一些潜在的风险:
在Under-fitting的状态下,如果人员能力不足,就无法应用更复杂的算法
在Under-fitting的状态下,如果计算资源不足,就无法训练更复杂的模型
在Over-fitting的状态下,如果数据质量不足,就无法开展有效的特征工程
在Over-fitting的状态下,如果数据数量不足,就无法训练高效的模型
如果整个项目涉及的数据基础设施不足,就无法快速迭代实验
于是,训练一个机器学习模型就不再是一个神秘的、盲目的、随机的过程。借助Bias、Variance、迭代实验的频率等量化数据,IT管理者和不懂技术的业务代表能更清晰地看到项目的进展,整个团队能更好地判断接下来需要做什么:是需要尝试更高级的神经网络呢?还是需要想办法获得更多的数据?或者是需要更多的计算资源?还是需要寻找某些特定的知识和技能?这样就避免了业务代表怀有不切实际的期望、又不知道技术团队在做什么而感到恐慌。
在下一篇文章里,我会更加具体地介绍,如何借鉴Scrum和看板等敏捷方法的思路,把训练一个机器学习模型的工作拆分成更小粒度、更易于管理的任务,以及如何对机器学习项目进行可视化管理。