SLAM闭合回环————视觉词典BOW小结
在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/dorian3d/DBoW2,而bag of words 又运用了数据挖掘的K-means聚类算法,笔者只通过bag of words 模型用在图像处理中进行形象讲解,并没有涉及太多对SLAM的闭环检测的应用。
PART ONE 1.Bag-of-words模型简介
Bag-of-words模型是信息检索领域常用的文档表示方法。在信息检索中,BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。 也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的。举个例子就好理解:
例如有如下两个文档:
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
基于这两个文本文档,构造一个词典:
Dictionary = {1:”Bob”, 2. “likes”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”, 8. “games”, 9. “Jim”, 10. “too”}。
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数):
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每个元素表示词典中相关元素在文档中出现的次数。不过,在构造文档向量的过程中可以看到,我们并没有表达单词在原来句子中出现的次序。
Bag-of-words模型应用于图像表示:
为了表示一幅图像,我们可以将图像看作文档,即若干个“视觉词汇”的集合,同样的,视觉词汇相互之间没有顺序。
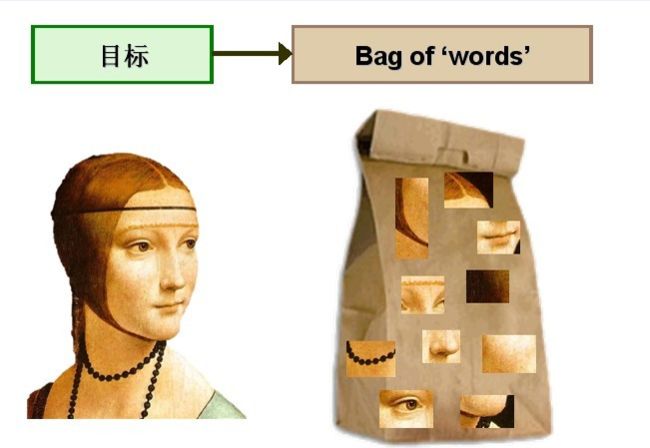
视觉词典的生成流程:

于图像中的词汇不像文本文档中的那样是现成的,我们需要首先从图像中提取出相互独立的视觉词汇,这通常需要经过三个步骤:(1)特征检测,(2)特征表示,(3)单词本的生成。 下图是从图像中提取出相互独立的视觉词汇:

过观察会发现,同一类目标的不同实例之间虽然存在差异,但我们仍然可以找到它们之间的一些共同的地方,比如说人脸,虽然说不同人的脸差别比较大,但眼睛, 嘴,鼻子等一些比较细小的部位,却观察不到太大差别,我们可以把这些不同实例之间共同的部位提取出来,作为识别这一类目标的视觉词汇。
构建BOW码本步骤:
利用K-Means算法构造单词表。用K-means对第二步中提取的N个SIFT特征进行聚类,K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。聚类中心有k个(在BOW模型中聚类中心我们称它们为视觉词),码本的长度也就为k,计算每一幅图像的每一个SIFT特征到这k个视觉词的距离,并将其映射到距离最近的视觉词中(即将该视觉词的对应词频+1)。完成这一步后,每一幅图像就变成了一个与视觉词序列相对应的词频矢量。
假定我们将K设为4,那么单词表的构造过程如下图所示:
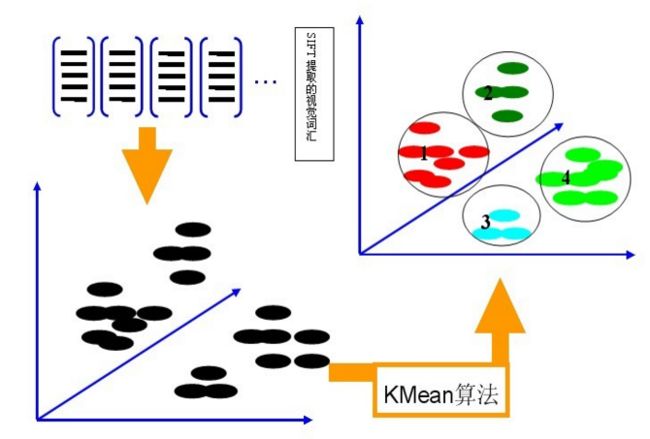
第三步:
利用单词表的中词汇表示图像。利用SIFT算法,可以从每幅图像中提取很多个特征点,这些特征点都可以用单词表中的单词近似代替,通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K=4维数值向量。将这些特征映射到为码本矢量,码本矢量归一化,最后计算其与训练码本的距离,对应最近距离的训练图像认为与测试图像匹配。请看下图:
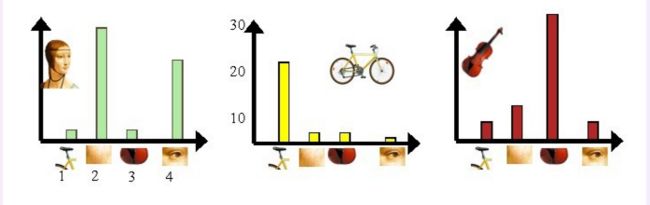
我们从人脸、自行车和吉他三个目标类图像中提取出的不同视觉词汇,而构造的词汇表中,会把词义相近的视觉词汇合并为同一类,经过合并,词汇表中只包含了四个视觉单词,分别按索引值标记为1,2,3,4。通过观察可以看到,它们分别属于自行车、人脸、吉他、人脸类。统计这些词汇在不同目标类中出现的次数可以得到每幅图像的直方图表示:
人脸: [3,30,3,20]
自行车:[20,3,3,2]
吉他: [8,12,32,7]
其实这个过程非常简单,就是针对人脸、自行车和吉他这三个文档,抽取出相似的部分(或者词义相近的视觉词汇合并为同一类),构造一个词典,词典中包含4个视觉单词,即Dictionary = {1:”自行车”, 2. “人脸”, 3. “吉他”, 4. “人脸类”},最终人脸、自行车和吉他这三个文档皆可以用一个4维向量表示,最后根据三个文档相应部分出现的次数画成了上面对应的直方图。一般情况下,K的取值在几百到上千,在这里取K=4仅仅是为了方便说明。
总结一下步骤:
第一步:利用SIFT算法从不同类别的图像中提取视觉词汇向量,这些向量代表的是图像中局部不变的特征点;
第二步:将所有特征点向量集合到一块,利用K-Means算法合并词义相近的视觉词汇,构造一个包含K个词汇的单词表;
第三步:统计单词表中每个单词在图像中出现的次数,从而将图像表示成为一个K维数值向量。
具体的,假设有5类图像,每一类中有10幅图像,这样首先对每一幅图像划分成patch(可以是刚性分割也可以是像SIFT基于关键点检测的),这样,每一个图像就由很多个patch表示,每一个patch用一个特征向量来表示,咱就假设用Sift表示的,一幅图像可能会有成百上千个patch,每一个patch特征向量的维数128。
接下来就要进行构建Bag of words模型了,假设Dictionary词典的Size为100,即有100个词。那么咱们可以用K-means算法对所有的patch进行聚类,k=100,我们知道,等k-means收敛时,我们也得到了每一个cluster最后的质心,那么这100个质心(维数128)就是词典里德100个词了,词典构建完毕。
词典构建完了怎么用呢?是这样的,先初始化一个100个bin的初始值为0的直方图h。每一幅图像不是有很多patch么?我们就再次计算这些patch和和每一个质心的距离,看看每一个patch离哪一个质心最近,那么直方图h中相对应的bin就加1,然后计算完这幅图像所有的patches之后,就得到了一个bin=100的直方图,然后进行归一化,用这个100维德向量来表示这幅图像。对所有图像计算完成之后,就可以进行分类聚类训练预测之类的了。
图像的特征用到了Dense Sift,通过Bag of Words词袋模型进行描述,当然一般来说是用训练集的来构建词典,因为我们还没有测试集呢。虽然测试集是你拿来测试的,但是实际应用中谁知道测试的图片是啥,所以构建BoW词典我这里也只用训练集。
用BoW描述完图像之后,指的是将训练集以及测试集的图像都用BoW模型描述了,就可以用SVM训练分类模型进行分类了。
在这里除了用SVM的RBF核,还自己定义了一种核: histogram intersection kernel,直方图正交核。因为很多论文说这个核好,并且实验结果很显然。能从理论上证明一下么?通过自定义核也可以了解怎么使用自定义核来用SVM进行分类。
PART THREE 2.词袋模型在slam中的应用?
DBoW3库介绍
DBoW3是DBoW2的增强版,这是一个开源的C++库,用于给图像特征排序,并将图像转化成视觉词袋表示。它采用层级树状结构将相近的图像特征在物理存储上聚集在一起,创建一个视觉词典。DBoW3还生成一个图像数据库,带有顺序索引和逆序索引,可以使图像特征的检索和对比非常快。
DBoW3与DBoW2的主要差别:
1、DBoW3依赖项只有OpenCV,DBoW2依赖项DLIB被移除;
2、DBoW3可以直接使用二值和浮点特征描述子,不需要再为这些特征描述子重写新类;
3、DBoW3可以在Linux和Windows下编译;
4、为了优化执行速度,重写了部分代码(特征的操作都写入类DescManip);DBoW3的接口也被简化了;
5、可以使用二进制视觉词典文件;二进制文件在加载和保存上比.yml文件快4-5倍;而且,二进制文件还能被压缩;
6、仍然和DBoW2yml文件兼容。
DBoW3有两个主要的类:Vocabulary和Database。视觉词典将图像转化成视觉词袋向量,图像数据库对图像进行索引。
ORB-SLAM2中的ORBVocabulary保存在文件orbvoc.dbow3中,二进制文件在Github上:https://github.com/raulmur/ORB_SLAM2/tree/master/Vocabulary
二、K-Means聚类的效率优化
影响效率的一个方面是构建词典时的K-means聚类,我在用的时候遇到了两个问题:
1、内存溢出。这是由于一般的K-means函数的输入是待聚类的完整的矩阵,在这里就是所有patches的特征向量f合成的一个大矩阵,由于这个矩阵太大,内存不顶了。我内存为4G。
2、效率低。因为需要计算每一个patch和每一个质心的欧拉距离,还有比较大小,那么要是循环下来这个效率是很低的。
为了解决这个问题,我采用一下策略,不使用整一个数据矩阵X作为输入的k-means,而是自己写循环,每次处理一幅图像的所有patches,对于效率的问题,因为matlab强大的矩阵处理能力,可以有效避免耗时费力的自己编写的循环迭代。
三、代码
代码下载链接:PG_BOW_DEMO.zip
Demo中的图像是我自己研究中用到的一些Action的图像,我都采集的简单的一共6类,每一类60幅,40训练20测试。请注意图像的版权问题,自己研究即可,不能商用。分类器用的是libsvm,最好自己mex重新编译一下。
如果libsvm版本不合适或者没有编译成适合你的平台的,会报错,例如:
Classification using BOW rbf_svm
??? Error using ==> svmtrain at 172
Group must be a vector.
下面是默认的demo结果:
Classification using BOW rbf_svm
Accuracy = 75.8333% (91/120) (classification)Classification using histogram intersection kernel svm
Accuracy = 82.5% (99/120) (classification)Classification using Pyramid BOW rbf_svm
Accuracy = 82.5% (99/120) (classification)Classification using Pyramid BOW histogram intersection kernel svm
Accuracy = 90% (108/120) (classification)
当然结果这个样子是因为我已经把6类图像提前弄成一样大了,而且每一类都截取了最关键的子图,不太符合实际,但是为了demo方便,当然图像大小可以是任意的。
下图就是最好结果的混淆矩阵,最好结果就是Pyramid BoW+hik-SVM:
图6 分类混淆矩阵
这是在另一个数据集上的结果(7类分类问题):
Classification using BOW rbf_svm
Accuracy = 34.5714% (242/700) (classification)Classification using histogram intersection kernel svm
Accuracy = 36% (252/700) (classification)Classification using Pyramid BOW rbf_svm
Accuracy = 43.7143% (306/700) (classification)Classification using Pyramid BOW histogram intersection kernel svm
Accuracy = 55.8571% (391/700) (classification)
PART TWO 一、单目视觉SLAM
1.环境特征
分类:自然特征和人工特征;
必要性:移动SLAM机器人必须通过实时检测周围环境特征来对自身进行一个定位。
2.面临问题:
既包括路标位姿的估计,也包括机器人位姿与轨迹的优化。(在很多实际应用中,环境地图和移动机器人的位置都是未知的,且定位和地图构建二者相互依赖、互为耦合,使得问题求解非常复杂。)
3.解决方案
目前主要有两种解决方案:基于滤波器的方法和基于图的方法。
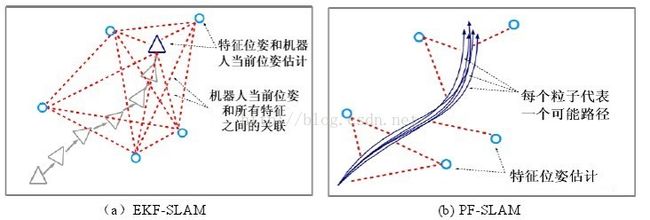
(2) 基于图的SLAM(Graph-basedSLAM)

算法致力于寻找一个最大可能的节点结构,得到一个最优位姿地图(近年来随着高效求解方法的出现,基于图的SLAM 方法重新得到重视,成为当前 SLAM研究的一个热点)
二、自然特征提取及视觉词典创建
2.1自然路标
优点:不改变工作环境,不需要额外设施和额外信息,并且在环境中大量存在;
缺点:受环境的影响较大,易受光线、遮挡、视角及环境相似度等变化的影响
2.2视觉词典
视觉词典是图像分类检索等领域的图像建模方法,该方法源于文档分析领域中的词典表示,词典表示将文档描述为词典中关键词出现频率的向量
2.3自然特征视觉词典创建框架
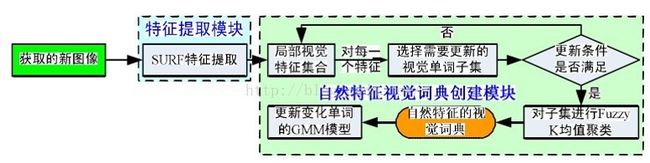
2.4具体实施
(1)用SURF(SpeededUp Robust Features)算子提取图像的自然局部视觉特征向量;(优点:保存了图像原有的色彩,而且改进了SIFT 算法计算数据量大、时间复杂度高、算法耗时长等缺点,可以用 64维向量建立特征点描述符,进一步提高了快速性和准确性)
(2)把相似的SURF 自然视觉特征向量划分为相同的自然视觉单词(采用 K-means算法对局部视觉特征集合进行聚类,一个聚类中心即为一个视觉单词);
(3)自然视觉词典的每一自然视觉单词采用GMM(GaussianMixture Model)方法进行建模自然视觉单词的概率模型,通过概率模型建立了更为精确的局部自然视觉特征与自然视觉单词间的匹配
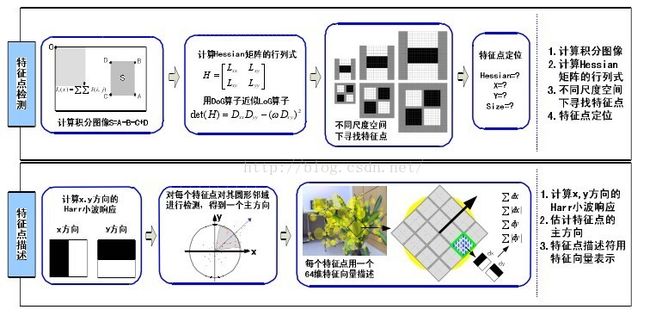
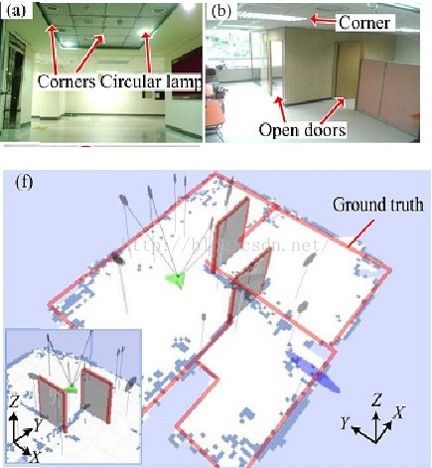
2.5实例
包括:室内走廊和室外视觉词典




三、视觉词典的人工路标模型创建


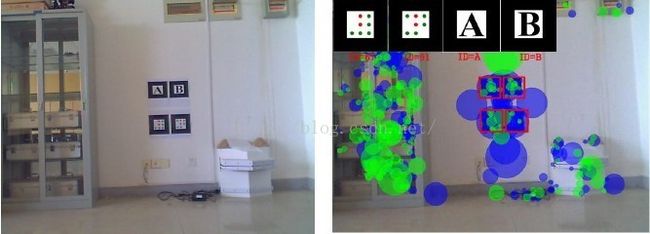
四、闭环检测
目前视觉 SLAM 闭环检测领域大部分算法都是首先准确建立基于图像外观的场景模型,然后基于场景外观进行闭环检测
BoVW(Bagof visual words)算法步骤:
①用SIFT或SURF算子提取图像的局部特征,每个局部特征用相同维数的特征向量表示;
②将检测到的局部特征集合进行聚类,每个聚类中心对应一个视觉单词;
③构建表征图像的视觉词典,动态调整视觉单词数量以评估视觉词典的大小;
④图像由视觉词典中的视觉单词权重向量表征。
BoVW(Bag of Visual Words)算法将一副图像类比为一篇文档
①SLAM采集图像具有时间连续性,利用时间连续性提升检测的准确性。
②图像匹配的相似度计算方法与视觉 SLAM 的时间连续特征,利用贝叶斯滤波融合当前观测量(也即当前图像匹配的相似度)和前一时刻的检测信息计算当前时刻闭环检测的概率,由此设计一种基于贝叶斯滤波的闭环检测跟踪算法;
4.1基于人工视觉词典的闭合检测算法:
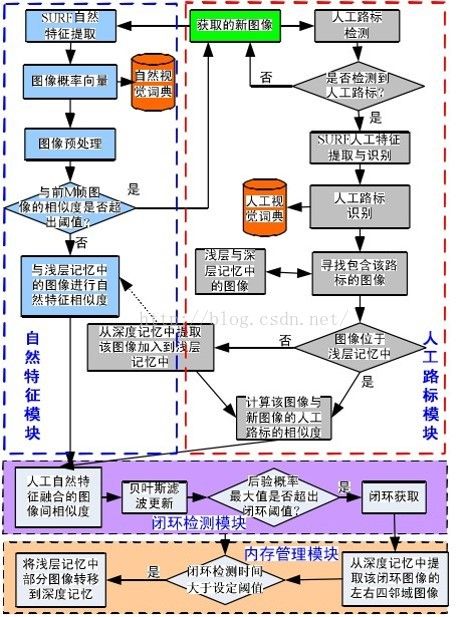
4.2基于贝叶斯滤波闭环检测算法:
相似度
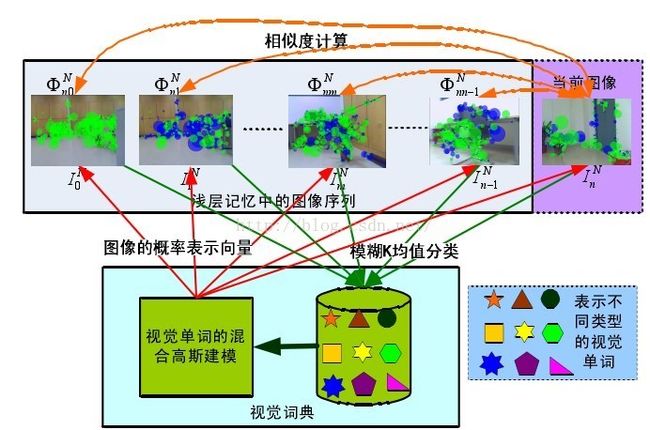
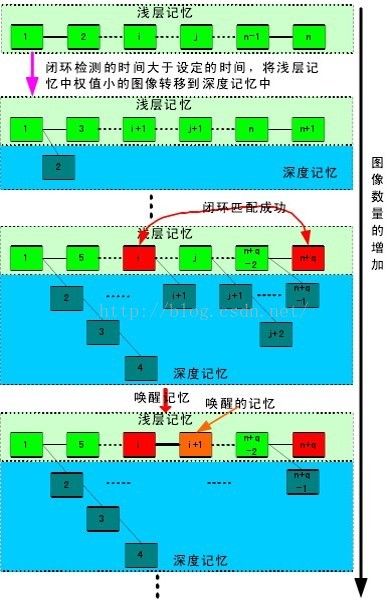
图像内存管理

五、混合人工自然特征的单目视SLAM
5.1算法整体框架
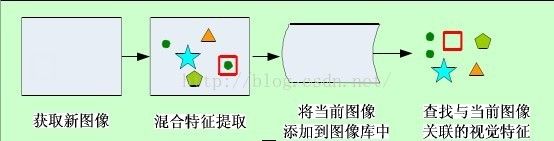
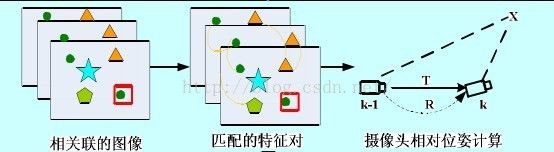
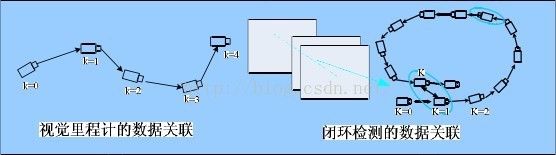
六、发展方向
借助Wifi或者伪卫星信号;三维场景地图实时性构建;机器人陌生环境内学习(模拟人类学习过程)以及高效内存管理模式;
设定室内路标的规范;POS系统微型化;
引用博客来自:
[1]https://blog.csdn.net/u011326478/article/details/52463556?locationNum=4&fps=1
[2]http://www.cnblogs.com/zjiaxing/p/5548265.html
[3]https://blog.csdn.net/chapmancp/article/details/80179765
个人学习使用,如有疑问,请联系博主惊醒修正