【论文笔记】CrowdNet: A Deep Convolutional Network for Dense Crowd Counting

ABSTRACT
我们的工作提出了一种新的深度学习框架,用于从高度密集人群的静态图像中估计人群密度。我们结合使用深度和浅层,全卷积网络来预测给定人群图像的密度图。这种组合用于有效地捕获高级语义信息(人脸/身体检测器)和低级特征(斑点检测器),这是大规模变化下的人群计数所必需的。由于大多数人群数据集的训练样本有限(<100幅图像),而基于深度学习的方法需要大量的训练数据,因此我们进行了多尺度数据增强。我们的方法在具有挑战性的UCF CC 50数据集上进行了测试,结果显示其性能优于现有的方法。
1. INTRODUCTION
在这项工作中,我们提出了一种基于深度学习的方法来估计人群密度和人群计数从静止图像。在高密度场景下(>2000人)计算人群带来了各种挑战。高度密集的人群图像受到严重的遮挡,使得传统的人脸/人探测器无效。
我们利用浅层和深层卷积架构的结合来解决人群图像的尺度变化问题。此外,我们通过从多尺度图像表示中采样小块来进行广泛的数据扩充,以使系统对尺度变化具有鲁棒性。我们的方法在具有挑战性的UCF CC 50数据集[8]上进行了评估,并获得了最新的结果。
3. PROPOSED METHOD
3.1 Network Architecture
人群图像经常从不同的视角捕捉,导致各种各样的视角和规模变化。靠近相机的人经常被捕捉在一个伟大的细节水平,即他们的脸,有时他们的整个身体被捕捉。然而,当人们远离相机或从空中拍摄图像时,每个人只被表示为一个头部斑点。在这两个场景中有效地检测人员需要模型同时在高度语义级别(人脸/身体检测器)上操作,同时还需要识别低级的头部斑点模式。我们的模型使用深度和浅层卷积神经网络的组合来实现这一点。所提议的体系结构的概述如图2所示。在下面的小节中,我们将详细描述这些网络。
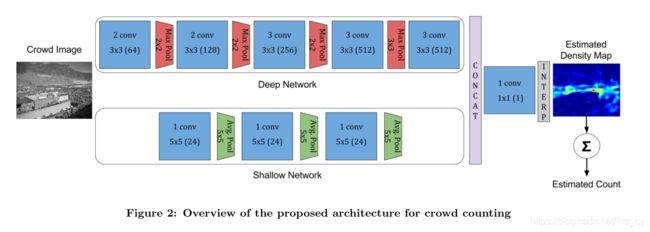
3.1.1 Deep Network
我们的深度网络通过类似于著名的vga -16[17]网络的架构设计来捕获人群计数所需的高级语义。然而,人群密度估计需要超像素预测,这与图像分类问题不同,后者是为整幅图像分配单个离散标签。我们通过去除VGG体系结构中存在的全连接层来获得这些像素级预测,从而使我们的网络在本质上完全卷积。
VGG网络有5个max-pool层,每个层的步长为2,因此最终的输出特征的空间分辨率只有输入图像的1/32倍。在对VGG模型的修改中,我们将第4个最大池层的stride设置为1,并删除了第5个池层。这使得网络能够在1/8倍于输入分辨率的情况下进行预测。我们采用空洞卷积处理了第4个最大池层中stride的移除引起的接收场失配问题。带孔的卷积滤波器可以有任意大的接受域,而与它们的内核大小无关。通过使用holes,我们将卷积层的接受野在第4个最大池层之后增加了一倍,从而使卷积层能够使用其原本训练好的接受野进行操作。
3.1.2 Shallow Network
在我们的模型中,我们的目标是使用一个浅层卷积网络来识别从远离摄像机的人那里产生的低级头部斑点模式。由于斑点检测不需要捕获高级语义,因此我们将该网络设计为浅层,深度只有3个卷积层。每一层都有24个过滤器,其内核大小为5×5。为了使该网络预测的空间分辨率与深度预测的空间分辨率相等,我们在每个卷积层之后使用池化层。我们的浅层网络主要用于检测小的头斑。为了确保最大池不会丢失计数,我们在浅网络中使用平均池层。
3.1.3 Combination of Deep and Shallow Networks
我们将深网络和浅网络的预测连接起来,每个网络的空间分辨率都是输入图像的1/8,然后用1x1卷积层来处理它。利用双线性插值将这一层的输出数据向上采样到与输入图像相同的大小,从而得到最终的人群密度预测。图像中总人数可以通过对预测密度图的求和得到。网络是通过反向传播根据groundtruth计算的l2损失来训练的。
3.2 Ground Truth
我们通过使用归一化的高斯核简单地模糊每个head注释来生成我们的ground truth。这种模糊导致密度图的总和与人群中的总人数相同。这样准备ground truth可以让CNN更容易学习ground truth,因为CNN不再需要得到head annotation的准确点。
3.3 Data Augmentation
由于cnn需要大量的训练数据,我们对训练数据集进行了广泛的扩充。我们主要提出两种数据增强的方法。第一类增强有助于解决人群图像中尺度变化的问题,而第二类增强可以提高CNN在易出错区域的性能,如高度密集的人群区域。
为了使CNN对尺度变化具有鲁棒性,我们从每个训练图像的多尺度金字塔表示中裁剪出了patch。我们考虑尺度为0.5到1.2,以1步递增,乘以原始图像分辨率(如图3所示)来构建图像金字塔。我们从这个金字塔的表示中裁剪出225×225个重叠50%的斑块。通过这种增强,CNN被训练成可以识别不同尺度的人。
我们观察到cnn发现高度密集的群体固有地难以处理。为了克服这个问题,我们通过更频繁地对高密度patch进行采样来增加训练数据。
4. EXPERIMENTS
我们评估了我们在具有挑战性的UCF CC 50[8]数据集上的人群计数方法。该数据集包含50幅灰度图像,每幅图像都有头部标注。每张图片的人数在94到4543之间,平均每幅图像有1280个人。数据集包括各种场景的图像,如音乐会、政治集会、宗教集会、体育场等。
与最近的研究类似[19,8],我们使用5倍交叉验证来评估我们的方法的性能。我们将数据集随机分成五组,每组包含10张图像。在每次交叉验证中,我们考虑4个分割(40张图像)用于训练网络,其余的分割(10张图像)用于验证其性能。我们按照前面描述的数据增强方法,从40张训练图像中每一张采样225×225的图片patch。这个过程每次平均产生50,292个训练补丁。我们使用Caffe[9]深度学习框架的Deeplab[5,14]版本,使用Titan X gpu来训练我们的深度卷积网络。我们的网络使用随机梯度下降(SGD)优化训练,学习率为1e−7,动量为0.9。每次训练的平均时间大约是5小时。
4.1 Results
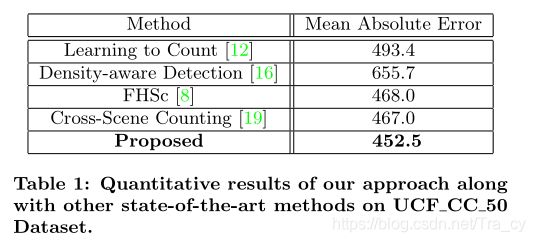
我们使用平均绝对误差(MAE)来量化我们的方法的性能。所提及的方法与其他方法结果比较如表4.1所示。
我们还在图4中显示了数据集中每幅图像的预测计数和实际计数。对于大多数图像,预测的数量接近实际的数量。然而,我们观察到,在图像中超过2500人的情况下,所提出的方法往往会低估计数。这种估计误差可能是由于数据集中的训练图像数量不足造成的。

4.2 Analysis
Deep and Shallow Networks: 在这里,我们通过实验证明,将深网和浅网结合,可以在多个尺度上有效地捕获个体,从而减少MAE。

Count based Augmentation:

5. CONCLUSION
在本文中,我们提出了一种基于深度学习的方法来估计人群密度和人群总数从高度密集的人群图像。我们证明了在大尺度变化和严重遮挡下,使用深度网络和浅层网络的结合是检测人的必要条件。我们还表明,通过增加训练图像,可以有效地解决在高度密集的人群中不同尺度的挑战和固有的困难。在具有挑战性的UCF CC 50数据集上,我们的方法优于最先进的方法。