【经典网络学习笔记3】VGG-Very Deep Convolutional Networks for Large-Scale Image Recognition
论文链接:http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks
主要是针对原论文,和参考相关笔记,进行了个人解读,抽丝而成,请大家多多指教。
要点掌握
1、VGG16网络结构

2、3*3和1*1小卷积核的优点

3、训练数据的处理



多尺度训练是原图的尺寸的最小边在256-512变化、训练是随机截取224*224,训练数据的尺寸是224*224,是不会变的。
mult-crop test测试的时候则是 central crop方式。正中间截取224*224送进interface中
dense evaluation 测试的时候则是原图的尺寸,即(256,384,512),其如何实现的呢?就是将最后三层全连接变成了3层全卷积。如何理解呢?如下:

处理数据的大值流程,但实际工程的情况则比较复杂,这只是为了知道流程。

4、网络特点:(VGG和alxnet的区别)

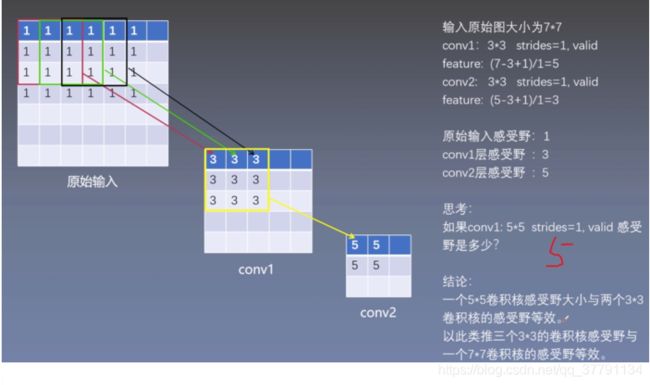
5、感受野:
通俗来说,特征图上的一个点跟原题上有关系的点的区域!!

感受野怎么理解?
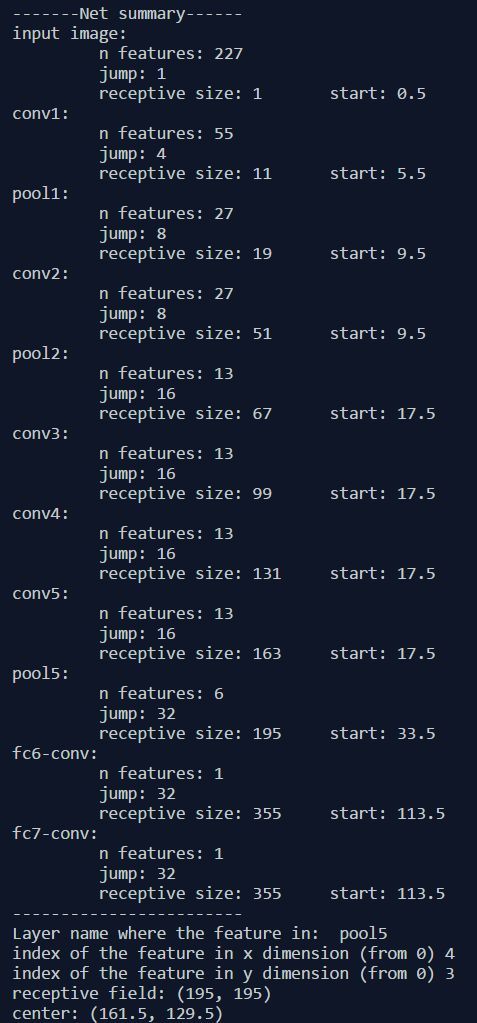
感受野计算公式

这是AlexNet的感受野计算(待考证)
摘要
在这项工作中,主要研究卷积网络Convolutional networks (ConvNets)深度在大规模的图像识别环境下对准确性的影响。主要贡献是使用非常小的(3×3)卷积滤波器架构对网络深度的增加进行了全面评估,这表明通过将深度推到16-19加权层可以实现对现有技术配置的显著改进,在定位和分类过程中分别获得了第一名和第二名,对于其他数据集泛化的很好,在其它数据集上取得了最好的结果。
1、引言
卷积网络(ConvNets)近来在大规模图像和视频识别方面取得了巨大成功,原因1有开源ImageNet和高性能计算系统的出现,例如GPU或大规模分布式集群,原因2方法上从高纬浅层features encoding到深层的ConvNets。
随着ConvNets在计算机视觉领域越来越商品化,为了达到更好的准确性,很多人尝试改进改进Krizhevsky等人(2012)最初的架构。从两方面改进,1是更小filter尺寸,在第一层卷积上更小的stride;2是在整个图像和多个尺度上对网络进行密集地训练和测试。该论文是在深度上下功夫。固定其他超参数,不断增加层数,技巧:3×3filters。
2.1 通用结构:
- input: 224×224 RGB
- 预处理:从每个像素中减去在训练集上计算的RGB均值。
- Conv filter: 3×3,1×1(只在C中使用,可以看作输入通道的线性变换(后面是非线性))
- stride:1
- padding: same,1,for 3×3
- pooling:5 max_pool (并非所有的conv后面都有),2×2 ,stride=2
通用结构,多个conv层加3个FC层(2层4096+ 1层1000,然后 soft-max),所有隐藏层都配备了修正(ReLU(Krizhevsky等,2012))非线性。没有使用局部响应规划化LRN(只有A-LRN使用),不使用的原因1:对比A和A-LRN结果显示没有帮忙改进效果,原因2:增加内存占用和计算时间,在应用的地方,其LRN层的参数是(Krizhevsky等,2012)的参数。
2.2配置
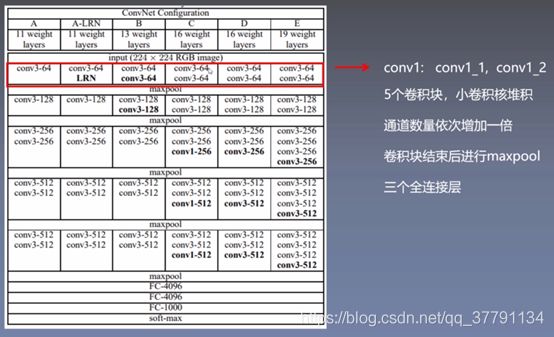
图1 不同VGG网络的结构

 转存失败重新上传取消
转存失败重新上传取消
图2 VGG-16的结构

表1 参数数量(百万级别)
表1 表明,尽管深度很大,网络中权重数量并不大于具有更大卷积层宽度和感受野的较浅网络中的权重数量(144M的权重在(Sermanet等人,2014)中)
2.3 讨论
之前的竞赛模型:11×11strides4 ,7×7strides2,VGG模型filters 3×3 strides1.很容易看到两个3×3卷积层堆叠(没有空间池化)有5×5的有效感受野;三个3×3卷积层堆叠具有7×7的有效感受野。意义呢? 如下:
- 在于1:2-3层relu,比单个relu,有更强的分辨能力;在于2:减少参数数量:1个7×7conv:7×7*C**2,3个3×3conv:3×3×3conv。少了80%。(这可以看作是对7×7卷积滤波器进行正则化,迫使它们通过3×3滤波器(在它们之间注入非线性)进行分解。)
- 1×1conv层,维持input output维数不变,简单线性计算,增加非线性出来(relu)。
对此前人成果:Ciresan等人(2011)以前使用小尺寸的卷积滤波器,没有在大规模的ILSVRC数据集上进行评估,Goodfellow等人(2014),街道号识别任务中采用深层ConvNets(11个权重层),显示出增加的深度导致了更好的性能,GooLeNet(Szegedy等,2014),ILSVRC-2014分类任务的表现最好的项目,是独立于我们工作之外的开发的,但是类似的是它是基于非常深的ConvNets(22个权重层)和小卷积滤波器(除了3×3,它们也使用了1×1和5×5卷积),它们的网络拓扑结构比我们的更复杂,并且在第一层中特征图的空间分辨率被更积极地减少,以减少计算量。本模型:在单网络分类精度方面胜过Szegedy等人(the single-network classification accuracy更好)
3、1 如何训练
S = 训练尺度 Q = 测试尺度(虽然裁剪尺寸固定为224×224,但原则上S可以是不小于224的任何值)不论256还是384,还是随机的S,都必须crop成224×224,这样才有统一的input shape。
- 站在AlexNet肩膀上(只是没有做图片的cropping)
- loss:最优化multinomial logistic regression
- mini -batch fradientdescent:bp+momentum,batch_size:256,momentum:0.9,weight decay:L2=5e-4
- dropout:前2个FC rate :0.5
- learning_rate:设置为10e-2,当validetion loss 不下降时手动将learning_rate下降e-1,总共训练了74个poches,下调了learning 3次。
- 对比AlexNet,该模型能更快找到最低loss,在于1:深度+小filter===间接regularization ,在于2对某些层做了预初始化处理。
weights的初始化的意义:影响反向传递的稳定性。如何确保良好的weights初始值?
- 给予A模型随机weights,训练A模型,从而获取训练好的conv,FC的weights,给更深的模型使用,其他层的weights使用randdom weights(mean =0,var=0.01),bias =0。
- learning_rate从原始初始化值开始,设置为10e-2。
- 值得注意的是,在提交论文之后,我们发现可以通过使用Glorot&Bengio(2010)的随机初始化程序来初始化权重而不进行预训练。
图片处理,input layer:压缩,修剪到224×224,cpu计算(在循环训练中进行),水平翻转和RGB演的shift:依然保持识别的能力。下面解释训练图像归一化。
如何修剪原始图片:crop_size:224×224,s=teainubf scale =最小边,若s==224.以此为修剪成为224×224就可以,若s>>224,任意截取一小部分图片。那么如何设置s?
- 方法1单尺度训练:对同一个模型,首先s固定为两个值,256,384,对于s=256,处理,先训练,获取weights,s=384,使用上面的weights,learning_rate变小10倍(我们使用较小的初始学习率10e-3)。
- 方法2:s取件[256,512]随机取值,对原图做scale,可看做data augmentation,增加样本,训练效果是一个模型对于不同scale图片具备一致的预测能力,为了加速训练,先训练好s=384的模型,提取参数作为初始参数,再开始训练。
3、2 如何测试
测试图片:Q!=S,only rescale not crop,测试模型:1st FC变成7×7卷积,2nd,3rd FC变成1×1卷积,fully-conv net :输入是whole uncroped images,水平翻转(增加样本),输出是3d tensor,通道是num_classes,w和h使用sum-pooled处理,输出a vector of class scores,原图的class score :原图score和水平翻转图score的平均值。
因为测试没有做croping,速度更快,使用croping,预测精度更好(基于细致的修剪图片抽样,同时需要坐padding,从而帮助抓住更多的图片context),但修剪导致增加的时间成本,vs产生的预测精度,得到结论是不划算,故没有croping。
3.3 实现细节
模型编写:c++caffe,大量modification
能做到:使用多GPU,能接收全尺寸,无修剪,不同scale,mini-batch分GPU做反向传递,再收集取均值。gradient计算与但GPU计算无差异。4GPU,提速3.75倍,耗时2-3周
3.4 分类实验
数据集:1000 class,train130w张,valid5w,test10w
measures评估指标:top1 error (错误预测占比,预测错误图片/总的图片),top5 error(正确class超出前5预测class范围的占比,正确预测超过前5分数的总数/总数)
实验时,用validation set 作为测试集使用。
4.1 单一scale评估
选取单一确定的Q值:方法1 Q=S,方法2 Q=0.5(Smin+Smax),在A-LRN模型中,LRN无效,所以后面模型就不采用了。

表2:在单测试尺度的ConvNet性能
观察现象:
- 1. 越深,分类错误率越低。
- 2. 增加1×1conv效果更好,因为增加了non-linearity。
- 3. 3×3conv比1×1conv效果好,能抓住更多spatial context。
- 4. 到19层后,error rate saturate(无法进一步下降),相信更深模型+更大数据,可以下降。
- 5 对比B和由B变形的宽浅模型B*,B的一对3×3conv兑换一个5×5conv放入B*,B*的conv深度只有B的一半,B精度高出7%,深且小的conv要优于浅且宽的conv模型。
- 6 对原图做浮动S处理,训练处的模型,优于只做单一s值处理的训练出来的模型,当然,测试时只用一个固定的Q值。
4.2 多 scale 评估
用不同的scale处理后的图片一起来测试模型。如果模型只被单一S处理的训练,Q只选择3个值,相差32,如果模型是被多S值图片训练而成:Q也是三个值,但区间很大[Smin,ave(Smin,Smax),Smax],实验显示多个S值处理样本时,表现更优。
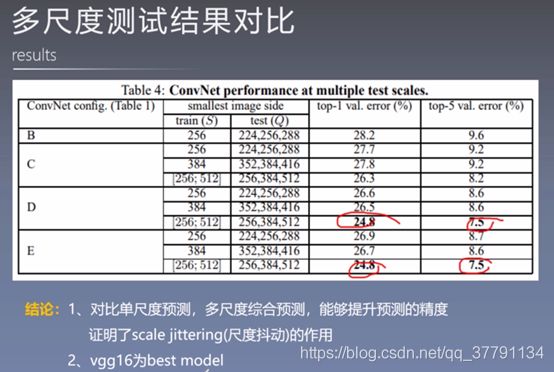
表3:ConvNet评估技术比较。在所有的实验中训练尺度S从[256;512]采样,三个测试适度Q考虑:{256, 384, 512}。
4.3 多 srop 评估
对数据样本做多cropping处理后让模型evaluate:
combination样本下的模型error < multi-crop样本下的模型error < 只是scale样本下模型error。
4.4 convNet fusion
将多个模型组合在一起使用,将多个模型的softmax output相加再取平均值,作为混合模型的output。上交结果后的模型都被多s处理的样本所训练,其表现更加好,由于上交的模型(值被单一s处理的样本训练)。

表4:多个卷积网络融合结果
参考内容:
图解论文:VGGhttps://zhuanlan.zhihu.com/p/36440919
VGG论文翻译——中英文对照 http://noahsnail.com/2017/08/17/2017-8-17-VGG%E8%AE%BA%E6%96%87%E7%BF%BB%E8%AF%91%E2%80%94%E2%80%94%E4%B8%AD%E8%8B%B1%E6%96%87%E5%AF%B9%E7%85%A7/
VGG笔记https://www.jianshu.com/p/5412d1dec69d
以VGG为例,分析深度网络的计算量和参数量https://blog.csdn.net/weixin_38300566/article/details/80703890
代码:
# ==============================================================================
from datetime import datetime
import math
import time
import tensorflow as tf
#创建卷积层且把本层的参数存入参数列表 name:层的名字
def conv_op(input_op, name, kh, kw, n_out, dh, dw, p):
# 得到输入图片的通道数
n_in = input_op.get_shape()[-1].value
# 设置scope
with tf.name_scope(name) as scope:
# kernel卷积核参数用tf.variable创建
# layers.xavier_initializer_conv2d()做参数初始化
kernel = tf.get_variable(scope+"w",
shape=[kh, kw, n_in, n_out],
dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer_conv2d())
# tf.nn.conv2d进行卷积核处理
conv = tf.nn.conv2d(input_op, kernel, (1, dh, dw, 1), padding='SAME')
# biases使用tf.constant赋值为0
bias_init_val = tf.constant(0.0, shape=[n_out], dtype=tf.float32)
# tf.Variable将其转换为训练的参数
biases = tf.Variable(bias_init_val, trainable=True, name='b')
# 使用tf.nn.bias_add将卷积结果conv和biases相加
z = tf.nn.bias_add(conv, biases)
# 再做relu非线性变换得到activation
activation = tf.nn.relu(z, name=scope)
# 将这个卷积层用到参数kernel、biases添加到参数列表p,且将activation作为函数结果返回
p += [kernel, biases]
# 将卷积层的输出activation作为函数结果返回
return activation
# 定义全连接层的创建函数
def fc_op(input_op, name, n_out, p):
n_in = input_op.get_shape()[-1].value
with tf.name_scope(name) as scope:
# tf.get_variable创建全连接层的参数,这个参数为两个,第一个为维度为输入通道数in,第二维度为输出的通道数out
# 初始化用xavier_initializer方法
kernel = tf.get_variable(scope+"w",
shape=[n_in, n_out],
dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer())
# biases使用tf.constant赋值为0.1 避免dead neuron
biases = tf.Variable(tf.constant(0.1, shape=[n_out], dtype=tf.float32), name='b')
# relu_layer对输入变量input_op与kernel做矩阵乘法 且加上biases,再做relu非线性变化为activation
activation = tf.nn.relu_layer(input_op, kernel, biases, name=scope)
# 将这个全连接层用到参数kernel、biases添加到参数列表p,
p += [kernel, biases]
# 且将activation作为函数结果返回
return activation
# 最大池化层的创建函数mpool_op
def mpool_op(input_op, name, kh, kw, dh, dw):
# tf.nn.max_pool输入为input,池化尺寸kh*kw,步长dh*dw,padding模式设为SAME
return tf.nn.max_pool(input_op,
ksize=[1, kh, kw, 1],
strides=[1, dh, dw, 1],
padding='SAME',
name=name)
# 创建VGG16的网络结构,输入input_op,keep_prob是控制dropout比例的一个placeholder
def inference_op(input_op, keep_prob):
# 初始化参数p
p = []
# assume input_op shape is 224x224x3
# 创建第一段卷积网络,2个3*3*64,步长为1*1,全像素扫描的卷积层,1个2*2,步长为2*2的最大池化
# block 1 -- outputs 112x112x64
conv1_1 = conv_op(input_op, name="conv1_1", kh=3, kw=3, n_out=64, dh=1, dw=1, p=p)
conv1_2 = conv_op(conv1_1, name="conv1_2", kh=3, kw=3, n_out=64, dh=1, dw=1, p=p)
# 经过最大池化尺寸变为四分之一
pool1 = mpool_op(conv1_2, name="pool1", kh=2, kw=2, dw=2, dh=2)
# 创建第二段卷积网络,2个3*3*64,步长为1*1,全像素扫描的卷积层,1个2*2,步长为2*2的最大池化
# block 2 -- outputs 56x56x128
conv2_1 = conv_op(pool1, name="conv2_1", kh=3, kw=3, n_out=128, dh=1, dw=1, p=p)
conv2_2 = conv_op(conv2_1, name="conv2_2", kh=3, kw=3, n_out=128, dh=1, dw=1, p=p)
# 经过最大池化尺寸变为四分之一
pool2 = mpool_op(conv2_2, name="pool2", kh=2, kw=2, dh=2, dw=2)
# 创建第三段卷积网络,3个3*3*64,步长为1*1,全像素扫描的卷积层,1个2*2,步长为2*2的最大池化
# # block 3 -- outputs 28x28x256
conv3_1 = conv_op(pool2, name="conv3_1", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
conv3_2 = conv_op(conv3_1, name="conv3_2", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
conv3_3 = conv_op(conv3_2, name="conv3_3", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
# 经过最大池化尺寸变为四分之一
pool3 = mpool_op(conv3_3, name="pool3", kh=2, kw=2, dh=2, dw=2)
# 创建第四段卷积网络,3个3*3*64,步长为1*1,全像素扫描的卷积层,1个2*2,步长为2*2的最大池化
# block 4 -- outputs 14x14x512
conv4_1 = conv_op(pool3, name="conv4_1", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv4_2 = conv_op(conv4_1, name="conv4_2", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv4_3 = conv_op(conv4_2, name="conv4_3", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
# 经过最大池化尺寸变为四分之一
pool4 = mpool_op(conv4_3, name="pool4", kh=2, kw=2, dh=2, dw=2)
# 创建第五段卷积网络,3个3*3*64,步长为1*1,全像素扫描的卷积层,1个2*2,步长为2*2的最大池化
# block 5 -- outputs 7x7x512
conv5_1 = conv_op(pool4, name="conv5_1", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv5_2 = conv_op(conv5_1, name="conv5_2", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv5_3 = conv_op(conv5_2, name="conv5_3", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
# 经过最大池化尺寸变为四分之一
pool5 = mpool_op(conv5_3, name="pool5", kh=2, kw=2, dw=2, dh=2)
# 将卷积网络的输出的结果进行偏平化
# flatten
shp = pool5.get_shape()
flattened_shape = shp[1].value * shp[2].value * shp[3].value
# 使用tf.reshape将每个样本化为长度7×7×512 = 25088 的一维向量
resh1 = tf.reshape(pool5, [-1, flattened_shape], name="resh1")
# fully connected
# 链接一个隐含节点数为4096的全连接层,激活函数为ReLu
fc6 = fc_op(resh1, name="fc6", n_out=4096, p=p)
# 链接一个Dropout层,在训练时节点保留为0.5,预测时为1.0
fc6_drop = tf.nn.dropout(fc6, keep_prob, name="fc6_drop")
# 和前面一样的全连接层,之后同样一个dropout层
fc7 = fc_op(fc6_drop, name="fc7", n_out=4096, p=p)
fc7_drop = tf.nn.dropout(fc7, keep_prob, name="fc7_drop")
# 链接一个1000的全连接层
fc8 = fc_op(fc7_drop, name="fc8", n_out=1000, p=p)
# 使用softmax处理得到分数输出概率
softmax = tf.nn.softmax(fc8)
# 使用argmax求输出概率的最大的类别
predictions = tf.argmax(softmax, 1)
# 将predictions、softmax、fc8、p一起返回
return predictions, softmax, fc8, p
# 测评函数
def time_tensorflow_run(session, target, feed, info_string):
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target, feed_dict=feed)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print ('%s: step %d, duration = %.3f' %
(datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print ('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %
(datetime.now(), info_string, num_batches, mn, sd))
# 测评函数的主函数,仅测评forward和backward的运算性能,不进行实质的训练和预测
def run_benchmark():
with tf.Graph().as_default():
image_size = 224
# 生成224的随机图片,通过tf.random_normal函数生成标差为0.1的正态分布的随机数
images = tf.Variable(tf.random_normal([batch_size,
image_size,
image_size, 3],
dtype=tf.float32,
stddev=1e-1))
# 创建keep_prob的placeholder
keep_prob = tf.placeholder(tf.float32)
# 调用inference函数构建VGGNEt-16的网络结构,获得 predictions, softmax, fc8, p
predictions, softmax, fc8, p = inference_op(images, keep_prob)
config = tf.ConfigProto()
# 为了令其瘦身,我们需要修改
# TensorFlow
# Session
# 创建部分的代码。
config.gpu_options.allow_growth = True
# 使用的GPU 分配策略类型,"BFC":最佳适配对齐算法
config.gpu_options.allocator_type = 'BFC'
# 创建session且初始化全局参数
init = tf.global_variables_initializer()
sess = tf.Session(config=config)
sess.run(init)
# 测试前传和backward的速度
time_tensorflow_run(sess, predictions, {keep_prob:1.0}, "Forward")
# 计算vGG16最后的全连接层的输出fc8的12loss
objective = tf.nn.l2_loss(fc8)
# 使用tf.gradients求相当于这个loss的所有模型参数的梯度
grad = tf.gradients(objective, p)
time_tensorflow_run(sess, grad, {keep_prob:0.5}, "Forward-backward")
batch_size=10 #32 - 20 -10就可以,前面两个batch都内存溢出
num_batches=100
run_benchmark()
