SparkMLLib中基于DataFrame的TF-IDF

一 简介
假如给你一篇文章,让你找出其关键词,那么估计大部分人想到的都是统计这个文章中单词出现的频率,频率最高的那个往往就是该文档的关键词。实际上就是进行了词频统计TF(Term Frequency,缩写为TF)。
但是,很容易想到的一个问题是:“的”“是”这类词的频率往往是最高的对吧?但是这些词明显不能当做文档的关键词,这些词有个专业词叫做停用词(stop words),我们往往要过滤掉这些词。
这时候又会出现一个问题,那就是比如我们在一篇文章(浪尖讲机器学习)中得到的词频:“中国人”“机器学习“ ”浪尖”,这三个词频都一样,那是不是随便选个词都能代表这篇文章呢?显然不是。中国人是一个很泛很泛的词,相对而言“机器学习”,“浪尖”对于这篇文章重要性要拍在中国人前面。
所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词("的"、"是"、"在")给予最小的权重,较常见的词("中国")给予较小的权重,较少见的词("蜜蜂"、"养殖")给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
再啰嗦的概述一下:
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
二 TF-IDF统计方法
本节中会出现的符号解释:
TF(t,d):表示文档d中单词t出现的频率
DF(t,D):文档集D中包含单词t的文档总数。
TF-词频计算方法

考虑到文档内容有长短之分,进行词频标准化

IDF-逆向文档频率

数学表达方法
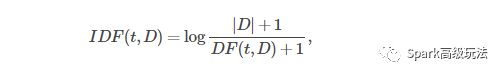
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
TF-IDF
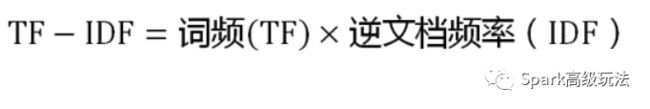
数学表达式

可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
三 Spark MLlib中的TF-IDF
在MLlib中,是将TF和IDF分开,使它们更灵活。
TF: HashingTF与CountVectorizer这两个都可以用来生成词频向量。
HashingTF是一个Transformer取词集合并将这些集合转换成固定长度的特征向量。在文本处理中,“一组术语”可能是一堆文字。HashingTF利用哈希技巧。通过应用hash函数将原始特征映射到index。这里是有的hash算法是MurmurHash3. 然后根据映射的index计算词频。这种方式避免了计算一个全局的term-to-index的映射,因为假如文档集比较大的时候计算该映射也是非常的浪费,但是他带来了一个潜在的hash冲突的问题,也即不同的原始特征可能会有相同的hash值。为了减少hash冲突,可以增加目标特征的维度,例如hashtable的桶的数目。由于使用简单的模来将散列函数转换为列索引,所以建议使用2的幂作为特征维度,否则特征将不会均匀地映射到列。默认的特征维度是
=262,144。可选的二进制切换参数控制术语频率计数。设置为true时,所有非零频率计数都设置为1. 这对建模二进制(而不是整数)计数的离散概率模型特别有用。
CountVectorizer将文本文档转换为词条计数的向量。这个后面浪尖会出文章详细介绍。
IDF:是一个Estimator,作用于一个数据集并产生一个IDFModel。IDFModel取特征向量(通常这些特征向量由HashingTF或者CountVectorizer产生)并且对每一列进行缩放。直观地,它对语料库中经常出现的列进行权重下调。
注意:spark.ml不提供文本分割的工具。推荐你参考http://nlp.stanford.edu/ 和https://github.com/scalanlp/chalk
四 举例说明
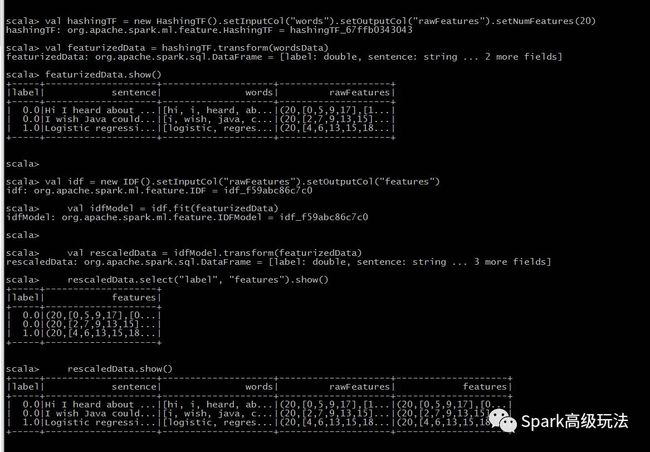
下面的例子中,使用Tokenizer将句子分割成单词。对于每个句子(单词包),我们使用HashingTF 将句子散列成一个特征向量。我们IDF用来重新调整特征向量;使用文本作为特征向量的时候通常会提高性能。然后特征向量就可以传递给学习算法了。
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}
import org.apache.spark.sql.SparkSession
object TfIdfExample {
def main(args: Array[String]) {
val spark = SparkSession
.builder
.appName("TfIdfExample")
.getOrCreate()
// $example on$
val sentenceData = spark.createDataFrame(Seq(
(0.0, "Hi I heard about Spark"),
(0.0, "I wish Java could use case classes"),
(1.0, "Logistic regression models are neat")
)).toDF("label", "sentence")
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
val wordsData = tokenizer.transform(sentenceData)
val hashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(20)
//也可以使用CountVectorizer来获取词频向量
val featurizedData = hashingTF.transform(wordsData)
// alternatively, CountVectorizer can also be used to get term frequency vectors
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel = idf.fit(featurizedData)
val rescaledData = idfModel.transform(featurizedData)
rescaledData.select("label", "features").show()
spark.stop()
}
}
推荐阅读:
1,基于java的中文分词工具ANSJ
2,基于DataFrame的StopWordsRemover处理
3,Spark的Ml pipeline
4,基于zookeeper leader选举方式一

kafka,hbase,spark,Flink等入门到深入源码,spark机器学习,大数据安全,大数据运维,请关注浪尖公众号,看高质量文章。

更多文章,敬请期待