小样本学习(Few-shot Learning)在图像领域的研究现状
最近在做华为杯的竞赛,涉及小样本学习,总结一下相关的知识及论文
小样本学习(Few-shot Learning)在图像领域的研究现状
- 1.introduction
- 1.1注意力机制
- 1.2 LSTM(Long short-term memory)
- 2. 小样本学习(Few-shot Learning)
- 2.1基于度量的小样本学习(Metric Based)(主流方法)
- 2.1.1孪生网络(Siamese Network)
- 2.1.2匹配网络(Match Network)
- 2.1.3原型网络(Prototype Network)
- 2.1.4关系网络(Relation Network)
- 2.2基于模型的小样本学习(Model Based)
- 2.2.1基于记忆Memory的方法
- 2.2.2 Meta Network
- 2.3基于优化的小样本学习(Optimization Based)
1.introduction
人类具有通过极少量样本识别一个新物体的能力,如小孩子只需要书中的个别图片,就可以认识什么是“苹果”,什么是“草莓”。研究人员希望机器学习模型在学习了一定类别的大量数据后,对于下游任务中遇到的新类别,只需要少量的样本就能快速学习,实现“小样本学习”。
传统的小样本学习考虑训练数据与测试数据均来自于同一个域。如果下游任务中包含了未知域, 则传统小样本学习方法效果不理想。这就是这次竞赛要解决的问题.
one-short learning : 待解决的问题只有少量的标注数据,先验知识很匮乏,迁移学习属于one-short learning的一种
zero-short learning: 这个种情况下完全没有标注数据,聚类算法等无监督学习属于zero-short learning的一种
小样本学习(Few-shot Learning) 是 元学习(Meta Learning) 在监督学习领域的应用。 Meta Learning,又称为 learning to learn,在 meta training 阶段将数据集分解为不同的 meta task,去学习类别变化的情况下模型的泛化能力,在 meta testing 阶段,面对全新的类别,不需要变动已有的模型,就可以完成分类。
形式化来说,few-shot 的训练集中包含了很多的类别,每个类别中有多个样本。在训练阶段,会在训练集中随机抽取 C 个类别,每个类别 K 个样本(总共 CK 个数据),构建一个 meta-task,作为模型的支撑集(support set)输入;再从这 C 个类中剩余的数据中抽取一批(batch)样本作为模型的预测对象(batch set)。即要求模型从 C*K 个数据中学会如何区分这 C 个类别,这样的任务被称为 C-way K-shot 问题。
训练过程中,每次训练(episode)都会采样得到不同 meta-task,所以总体来看,训练包含了不同的类别组合,这种机制使得模型学会不同 meta-task 中的共性部分,比如如何提取重要特征及比较样本相似等,忘掉 meta-task 中 task 相关部分。通过这种学习机制学到的模型,在面对新的未见过的 meta-task 时,也能较好地进行分类。
Few-shot Learning 模型大致可分为三类:Mode Based,Metric Based 和 Optimization Based。

1.1注意力机制
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
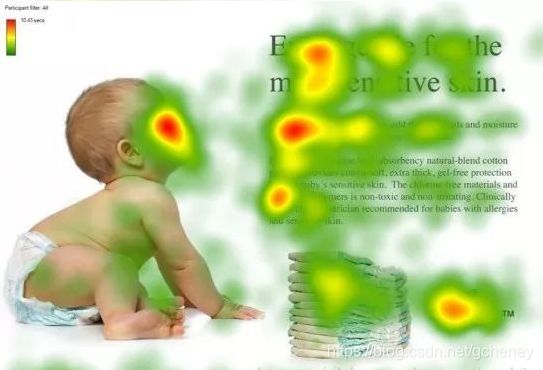
图1形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于图1所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
小样本学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
注意力机制的基本思想和实现原理
1.2 LSTM(Long short-term memory)
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
LSTM结构(图右)和普通RNN的主要输入输出区别如下所示:

LSTM基本思想和实现原理
LSTM的内部结构,通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息;而不像普通的RNN那样只能够仅有一种记忆叠加方式。对很多需要“长期记忆”的任务来说,尤其好用。
但也因为引入了很多内容,导致参数变多,也使得训练难度加大了很多。因此很多时候我们往往会使用效果和LSTM相当但参数更少的GRU来构建大训练量的模型。
2. 小样本学习(Few-shot Learning)
2.1基于度量的小样本学习(Metric Based)(主流方法)
Metric Based 方法通过度量 batch 集中的样本和 support 集中样本的距离,借助最近邻的思想完成分类。
2.1.1孪生网络(Siamese Network)
- 孪生 是指网络结构中的Network_1和Network_2
这两个网络的结构一般是相同的,并且参数是共享的 即参数是一致的。
还有一种网络叫伪孪生网络 直观理解就是左右两边的网络结构是不同的。 - 在图中的网络中 左右两个网络的作用是用于提取输入图片的特征。特征提取器
比如在人脸领域,输入两个人的人脸图片信息,两个网络分别提取这两个人脸图片中不同部分。
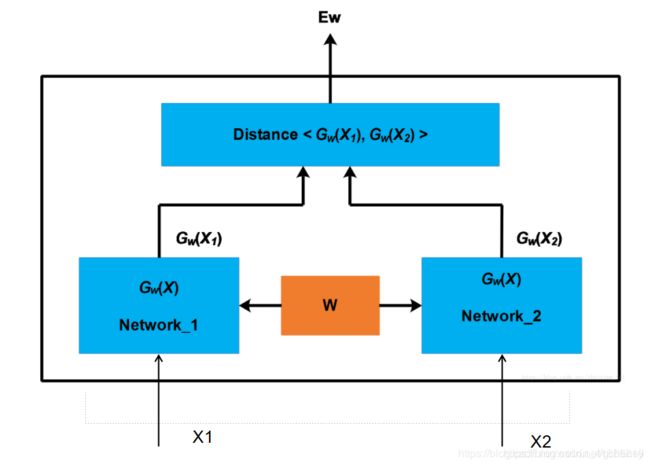
- 通过使用两个网络 提取出来了两个图片的特征 接下来计算特征之间的差距distance。之后返回网络的输出结果 :这两张图片是否属于同一人。
关于这个网络结构的损失函数 也可理解为 计算distance的地方设定为:
G w ( P T ) = G w ( X 1 , X 2 ) Gw(PT) = Gw(X1,X2) Gw(PT)=Gw(X1,X2)
指两个特征上属于同一个人的误差
G w ( P F ) = G w ( X 1 , X 2 ) Gw(PF) = Gw(X1,X2) Gw(PF)=Gw(X1,X2)
指两个特征上不属于同一个人的误差
损失函数
L o s s = G w ( P T ) − G w ( P F ) + α Loss = Gw(PT) - Gw(PF) + α Loss=Gw(PT)−Gw(PF)+α
我们要使损失函数最小,相当于使 G w ( P T ) Gw(PT) Gw(PT) 尽可能的小 可以理解为 这个网络 识别两张图片属于 一个人 能力 尽可能的厉害/准确
相当于使 G w ( P F ) Gw(PF) Gw(PF)尽可能的大(因为有负号) 可以理解为 这个网络 区分/判别两张图片不属于 一个人 能力 尽可能的厉害/准确
其中 参数 α α α 是为了避免损失函数的值为0 而设定的
因为在损失函数为0 的时候 优化过程中 求导求梯度会出现问题。
总的来说,孪生网络(Siamese Network)通过有监督的方式训练孪生网络来学习,然后重用网络所提取的特征进行 one/few-shot 学习。
该孪生卷积网络可以:
- 学习到一些通用的图片特征,可以预测数据量非常少的新分类
- 在数据源上进行随机采样生成成对的训练数据,然后使用标准的优化算法进行训练
- 该方法不依赖特定领域知识,只依赖深度学习

具体的网络是一个双路的神经网络,训练时,通过组合的方式构造不同的成对样本,输入网络进行训练,在最上层通过样本对的距离判断他们是否属于同一个类,并产生对应的概率分布。在预测阶段,孪生网络处理测试样本和支撑集之间每一个样本对,最终预测结果为支撑集上概率最高的类别。

L层,每层n个单位
h 1 , 1 h_{1,1} h1,1 表示第一个孪生的层 l l l
h 2 , 1 h_{2,1} h2,1 表示第二个孪生的层 l l l

前两层使用ReLU激活函数,其余的使用sigmoid单元。卷积层的filters尺寸可变,stide固定为1,。为了方便优化滤波器的数量的是16的倍数,然后使用ReLU激活函数,然后选择性的使用max-pooling,stride为2.

【1】Koch, Gregory, Richard Zemel, and Ruslan Salakhutdinov. “Siamese neural networks for one-shot image recognition.” ICML Deep Learning Workshop. Vol. 2. 2015.
代码地址
代码作者对论文的解析
论文解读
2.1.2匹配网络(Match Network)
相比孪生网络,匹配网络(Match Network)为支撑集和 Batch 集构建不同的编码器,最终分类器的输出是支撑集样本和 query 之间预测值的加权求和。
提出的框架学习一个网络,来映射少量的有标签的 Support Set 样本和将一个无标签的样本映射到它的标签(预测),同时避免在适应新的类上面进行微调。
(1)新的类;(2)每个类的训练样本只有一个;(3)学习一个网络映射输入空间到新的空间,比较相似度;
创新点:
模型层面:Matching Nets (MN),使用注意力机制和存储记忆来快速学习。
训练过程:Task 的概念,每个 task 模拟最后的 meta-testing 的任务,然后 switching the task from minibatch to minibatch,即一次训练几个任务 (minibatch),重复很多次 (switching)。
该文章也是在不改变网络模型的前提下能对未知类别生成标签,其主要创新体现在建模过程和训练过程上。对于建模过程的创新,文章提出了基于 memory 和 attention 的 matching nets,使得可以快速学习。

Matching Networks for One Shot Learning论文分析
对于训练过程的创新,文章基于传统机器学习的一个原则,即训练和测试是要在同样条件下进行的,提出在训练的时候不断地让网络只看每一类的少量样本,这将和测试的过程是一致的。
创新点:
- 基于双向 LSTM 学习训练集的 embedding(特征映射),使得每个支撑样本的 embedding (特征映射)是其它训练样本的函数;
- 基于 attention-LSTM 来对测试样本 embedding(特征映射),使得每个 Query 样本的 embedding 是支撑集 embedding 的函数。文章称其为 FCE (fully-conditional embedding)。
【2】Oriol Vinyals, Charles Blundell, Tim Lillicrap, Daan Wierstra, et al. Matching networks for one shot learning. In Advances in Neural Information Processing Systems, pages 3630–3638, 2016.
2.1.3原型网络(Prototype Network)
原型网络是解决小样本分类问题的一个比较实用且效果还不错的方法,它基于这样的想法:每个类别都存在一个原型表达,该类的原型是 support set 在 embedding 空间中的均值。然后,分类问题变成在 embedding 空间中的最近邻。
在小样本分类问题中,最需要解决的一个问题是数据的过拟合,由于数据过少,一般的分类算法会表现出过拟合的现象,从而导致分类结果与实际结果有较大的误差。为了减少因数据量过少而导致的过拟合的影响,可以使用基于度量的元学习方法,而原型网络便是。在此方法中,需要将样本投影到一个度量空间,且在这个空间中同类样本距离较近,异类样本的距离较远。
如图c1、c2、c3 分别是三个类别的均值中心(称 Prototype),将测试样本 x 进行 embedding 后(将样本x投影至这个空间),与这 3 个中心进行距离计算,从而获得 x 的类别。:
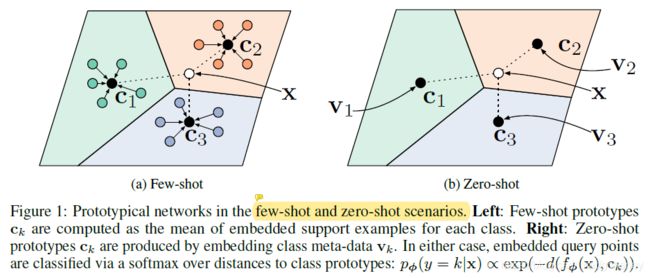
那么,现在有几个问题:
怎么将这些样本投影至一个空间且让同类样本间距离较近?
怎么说明一个类别所在的位置?从而能够让未标记的样本计算与类别的距离
首先,先来说明第一个问题,即如何投影。论文中提到了一个带参数的嵌入函数,这个函数可以理解为投影的过程,表示样本的特征向量,函数值表示投影到那个空间后的值,这个嵌入函数是一个神经网络,参数是需要学习的,可以认为参数决定了样本间的位置,所以需要学习到一个较好的值,让同类别样本间距离较近。
想法说完了,再来说具体实现。首先说明一下训练数据,论文中实验的数据分为支持集和查询集:
支持集:即训练集,在本论文中由一些已标记的样本组成,比如有N个类,每个类中有M个样本,则为N-way–M-shot。
查询集:即测试集,在本论文中由一些已标记的样本和部分未标记的样本组成,同理测试时要根据训练时来,如训练时为N-way–M-shot,则测试时也要为N-way–M-shot。
论文中认为一个类由这个类所有样本在投影空间里的平均值决定,所以,类k的原型为:
c k = 1 ∣ S k ∣ ∑ ( x i , y i ) ∈ S k f ϕ ( x i ) c_{k}=\frac{1}{|S_{k}|}\sum_{(x_{i},y_{i})\in S_{k}}f_{\phi }(x_{i}) ck=∣Sk∣1∑(xi,yi)∈Skfϕ(xi)
原型网络的原理较为简单,但是有一点小问题就是,对于两个或多个样本的相似度,用距离较近来度量是否合理。对于某一些数据集来说可能有用,但是对于一般的图片,效果可能就不那么好了。因此,两个样本或者图片间相似性的度量方法是下一步可以改进的地方。
Prototypical Networks for Few-shot Learning论文详解1
Prototypical Networks for Few-shot Learning论文详解2
Prototypical Networks for Few-shot Learning论文详解3
Prototypical Networks for Few-shot Learning论文详解4
Prototypical Networks for Few-shot Learning文章代码
【3】Snell, Jake, Kevin Swersky, and Richard Zemel. “Prototypical networks for few-shot learning.” Advances in Neural Information Processing Systems. 2017.
2.1.4关系网络(Relation Network)
关系网络其实就是引入注意力机制,通过对embedding(特征映射)后的特征计算注意力,利用注意力得分进行分析。因此
前面几个网络结构在最终的距离度量上都使用了固定的度量方式,如 cosine,欧式距离等,这种模型结构下所有的学习过程都发生在样本的 embedding 阶段。
而 Relation Network 认为度量方式也是网络中非常重要的一环,需要对其进行建模,所以该网络不满足单一且固定的距离度量方式,而是训练一个网络来学习(例如 CNN)距离的度量方式,在 loss 方面也有所改变,考虑到 relation network 更多的关注 relation score,更像一种回归,而非 0/1 分类,所以使用了 MSE 取代了 cross-entropy。
K-shot:对每个训练类的所有样本的Embedding模块输出进行逐元素求和,这个合并的类级特征映射与上面的查询图像特征映射相结合。
Objective function:使用均方误差MSE作为损失函数,将关系分数rij回归到ground truth:匹配的相似性为1,不匹配的相似性为0。
Zero-shot:每个训练类中使用语义嵌入向量代替one shot数据集作为支持集。模型结构中除了用于查询集的嵌入模块f1,还使用了第二个异构模块f2用于处理语义嵌入向量。

Embedding利用4个卷积块实现。每个卷积块包含64个filter大小为33,使用batch normalization和ReLU激活函数。前两个block包含22的max pooling操作,后两个block不需要。目的是需要在关系模块中为进一步的卷积层提供输出特征映射。
Relation模块由两个卷积块和两个全连接层组成,每一个卷积块是64个filter大小为33,使用batch normalization,ReLU激活函数,22的max pooling。最后一个max pooling层输出大小在Omniglot中为64,在miniImageNet中为6433=576。这两个全连接层分别是8和1。所有全连接层的激活函数为ReLU,除了最后一层全连接层是Sigmoid(目的是生成合理的关系分数范围)。
Few-shot:Adam学习率设置为10-3,每100,000个情景后折半,端到端训练,没有额外的数据集。
训练时的数据是Omniglot,通过对原始数据旋转90°,180°,270°来增加新类,选择1200类并通过旋转作为训练集,423类通过旋转作为测试集。并将大小resize为28*28。
Learning to compare: Relation network for few-shot learning.论文详解
Learning to compare: Relation network for few-shot learning.开源代码
【4】Sung, Flood, et al. “Learning to compare: Relation network for few-shot learning.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
2.2基于模型的小样本学习(Model Based)
Model Based 方法旨在通过模型结构的设计快速在少量样本上更新参数,直接建立输入 x 和预测值 P 的映射函数
2.2.1基于记忆Memory的方法
通过在神经网络上添加Memory来实现。Santoro等提出在网络的输入把上一次训练的y label也作为输入,并且添加了external memory存储上一次训练x的输入,这使得下一次输入后进行反向传播时,可以让y label和x建立联系,使得之后的x能够通过外部记忆获取相关图像进行比对来实现更好的预测。

One-shot Learning with Memory-Augmented Neural Networks论文详解
【5] Santoro, Adam, Bartunov, Sergey, Botvinick, Matthew, Wierstra, Daan, and Lillicrap, Timothy. Meta-learning with memory-augmented neural networks. In Proceedings of The 33rd International Conference on Machine Learning, pp. 1842–1850, 2016.
Meta-Learning论文笔记:Meta Network
【6】Munkhdalai T, Yu H. Meta Networks. arXiv preprint arXiv:1703.00837, 2017.
以Meta-Learning with memory-augmented neural networks这篇文章为例,我们看一下他的网络结构:
2.2.2 Meta Network
2.3基于优化的小样本学习(Optimization Based)
Optimization Based 方法认为普通的梯度下降方法难以在 few-shot 场景下拟合,因此通过调整优化方法来完成小样本分类的任务。
Optimization as a model for few-shot learning论文详解
[7] Ravi, Sachin, and Hugo Larochelle. “Optimization as a model for few-shot learning.” (2016).
Model-agnostic meta-learning for fast adaptation of deep networks论文详解
[8] Finn, Chelsea, Pieter Abbeel, and Sergey Levine. “Model-agnostic meta-learning for fast adaptation of deep networks.” Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017.