PCIE协议解析 synopsys IP Core operation 读书笔记(3)
3 Core operation
3.1 Initialization
1、 先disable link training
2、 通过DBI(data bus interface)配置core的stickyregisters,需要配置什么目前不知道??????
3、 Enable link training
4、 等待link完成。
5、 root Complex枚举Downstream Device(什么是Downstreamdevice????)
Ø 读取 Downstream device的配置空间
Ø 配置device的capabilites(具体配置什么???)
Ø 配置switch ports(???) 的base和limit寄存器,以反映devices enumerated downstream的BAR(Base Address Register)的范围。
Ø 配置endpoint的BAR。
(该部分是用户完成,还是IP自动完成????????)
6、 使能BME、MSE、ISE。
7、 开始传输数据。

3.2 Link Establishment
LTSSM是IP core根据PCI Express Base 3.1标准完成的,(是否说linkestablishment不用用户关心???,IP已经搞定了),在link建立的阶段,用户需要关注的只有3问题:
Ø “How to TieOff Unused Lanes” on page 1145.在系统中有没有用到的lane,需要进行tie off
Ø “LaneReversal and Broken Lanes” on page 1149.对lanes进行颠倒或者翻转调整,主要是为了解决物理层上的连接错误问题。
Ø Runtime Link Width Adjustment Through Detect。在传输过程中调整link路的位宽。
个人认为以外问题都属于pcie的高级功能,在bring up可以不予考虑,只有在系统跑起来后需要进一步考虑这些细致的问题。
3.3 Transmit TLP(Tansaction Layer Packet)Processing
主要涉及3个问题:
Ø “Transmit TLPArbitration” 仲裁
Ø “ACK/NAKScheduling”
Ø “TransmitReplay”
3.3.1 Transmit TLP Arbitration
阅读本章节可以参考http://blog.sina.com.cn/s/blog_6472c4cc01018893.html相关的内容
需要注意的:
Ø Core 不检测TLP是否有错误
Ø Core不检测TLP是否超出有效负载的最大值
TLP(Tansaction Layer Packet)和DLLP(Data Link Layer Packet)在发送的仲裁中优先级相同。

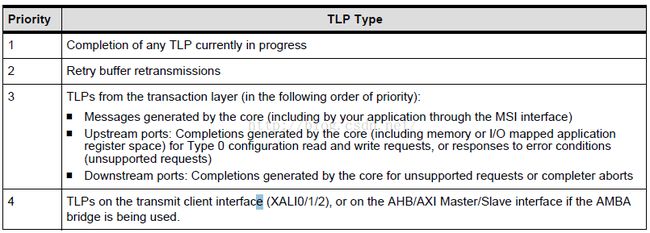

Selecting Transmit ClientArbitration Scheme
所有的发送端的接口XALI0/1/2(或者AHB/AXI master 或者slave)都遵循3中仲裁的方式,
(注:其实PCIe规定的内部仲裁规则,而作为用户,只有了解仲裁规则即可,在core内部已经完成,而且做为FPGA系统,在PCIe的总线体系中,一般扮演endpoint的角色较多,而作为RC,其组成的拓扑结构也会相对简单。)
0: VC(virtual channal) based,virtual channel的概念来自switch中,规定的是多个EP向一个设备发送数据包时的仲裁规则。
1:round robin(RR)可以翻译为轮叫调度
2:strictpriority()
For moredetails, see “VC-BasedArbitration” on page1173.
Effects of Flow Control Credits On Transmit Client Arbitration(重要)
在允许远程的设备发送一个TLP(transation layer package )之前,core需要检测远程设备的特殊传输方式(posted, non-posted,completion)的flow control credit 是有效的。而TLPs是否通过credit check 取决于所提供的仲裁方案,内部生产的报文(completions)和消息(messages)同样需要经过仲裁,即使是最高优先级也不例外。
(注:其中posted和non-posted的解释如下,PCI总线规定了两类数据传送方式,分别是Posted和Non-Posted数据传送方式。其中使用Posted数据传送方式的总线事务也被称为Posted总线事务;而使用Non-Posted数据传送方式的总线事务也被称为Non-Posted总线事务。
其中Posted总线事务指PCI主设备向PCI目标设备进行数据传递时,当数据到达PCI桥后,即由PCI桥接管来自上游总线的总线事务,并将其转发到下游总线。采用这种数据传送方式,在数据还没有到达最终的目的地之前,PCI总线就可以结束当前总线事务,从而在一定程度上解决了PCI总线的拥塞。
而Non-Posted总线事务是指PCI主设备向PCI目标设备进行数据传递时,数据必须到达最终目的地之后,才能结束当前总线事务的一种数据传递方式。)
see “FlowControl” on page 139.
比如当使用RR仲裁方式,当posted数据传输(通过XALI1接口完成)紧跟在completion(通过XALI0进行)传输的后面,而此时如果credit通过,则posted传输将先于completion进行传输,但是如果posted的credit是无效的,那么completion可以绕过posted通过XALI0,发送出去,但是XALI1接口将会被posted阻塞,而之后的XALI1将无法通过任何的no-posted、posted、CPL(completion)的TLP(tansaction layer packet)。也就是XALI1接口被完全阻塞了。而作为用户,需要合理的利用这3个数据接口,以避免阻塞。
当应用单一的接口发送多种类型的信息(posted、non-posted),但是当前的请求(如posted)如果因为缺失credit而导致阻塞,那么当前接口将会同时阻塞其他类型的信息传输(比如no-posted),即使其可以通过credit。为了避免这种情况,你的应用应该保证不同的接口发送不同类型的请求(如:XALI0 for postedrequests, XALI1 for non-posted requests, and XALI2 for completions),而另外的方法就是保证你的每次只生成可以通过FC credit的request,具体的实现方式就是每次通过检查core输出的FC credit的标准位xadm_*_cdts。
(注:该部分应该细细的了解下)
当使用xadm_*_cdts检查credit是,应用程序需要考虑以下问题,core在生成一个message或者completion TLP 的同时,应用程序刚好需要生成一个request并正在检查xadm_*_cdts。
see “FlowControl” on page 139.
3.3.2 ACK/NAK Scheduling
应答机制由core内部完成,用户了解便可,而且你涉及到的控制寄存器一般情况也不许要用户进行修改。
3.3.3 Transmit Replay
而应答机制一样,重发机制用户了解便可。