JAVA总结(五)----- 容器(一)-----List
注:以下程序与概念均参考自《java编程思想》、《数据结构与java集合框架》、《算法导论》
目录
一、集合是什么
二、基于数组实现的——ArrayList
1、类标题
2、类字段
3、构造方法
4、add()以及数组扩容
5、常用方法
三、基于链表实现的——LinkedList
1、LinkedList类标题
2、LinkedList的字段
3、LinkedList的构造方法
4、LinkedList的实现
5、与ArrayList的对比
四、迭代器
1、Iterator
2、ListIterator
3、Iterable
五、Queue
一、集合是什么
当我们遇到这样的问题,创建一组对象并保存这组对象。或许我们可以使用数组进行保存并持有这组对象的引用,但数组具有固定长度尺寸,它并不能保证我们将在程序中需要多少个对象,或者是否需要更复杂的方式来存储对象。数组固定的尺寸限制它无法提供我们持有对象的更多操作。
java中提供了Collection框架解决这样的问题,或者称为集合框架。集合框架提供了完善的方法保存对象,无论我们是否在运行时还需要保存对象,它都能实现我们对于存储对象的要求。另一方面,对于存储的对象提供一套完善的基本操作,给予我们管理持有的对象。
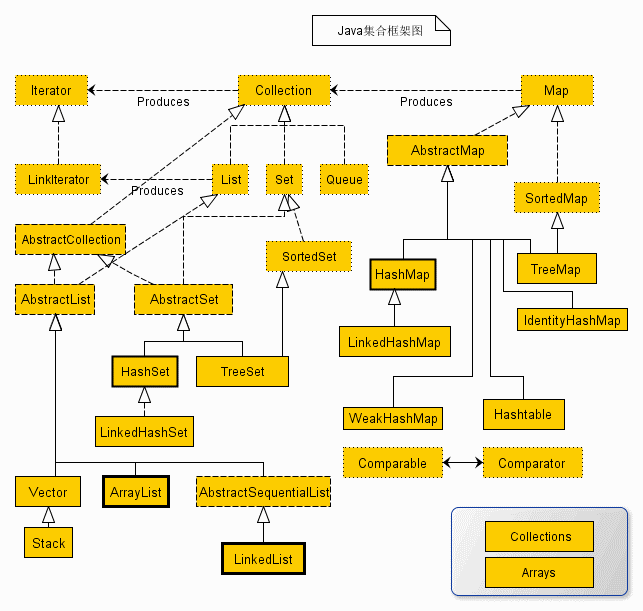
上图是java集合框架图,Collection接口为顶级接口,其中List、Set、Queue接口扩展该接口。
①、Collection接口:保存一组独立元素序列,这些元素服从一条或多条的规则。
②、List接口:List接口扩展Collection接口,提供了它保存元素的规则:“按照插入顺序保存元素,允许其中存在重复元素”。添加利用索引作为参数或者返回类型的方法。实现可修改的序列。

| List(interface) | 存入List的元素按照元素的存放顺序保存,加入List的元素必须顶equlas()确保元素的唯一性。 |
| ArrayList | 采用动态数组实现链表结构,插入将可能会把数组进行扩容,删除将会把数组中元素进行移动。具有快速的随机访问数据 |
| LinkedList | 采用双向循环链表实现链表结构,与ArrayList不同,它的随机访问效率很低,但插入删除具有不错的性能。 |
| Queue | 队列实现的链表结构,是一个先进先出的结果,可以采用LinkedList实现它 |
| Vector | 已经被弃用的同步链表结构,它同步性能差,集合复合操作时安全性差。通常采用CopyOnWriteArrayList作为同步List的实现 |
二、基于数组实现的——ArrayList
ArrayList基于数组实现,它是一个动态数组。类似于数组,ArrayList对象支持元素的随机访问;也就是说只要给出数组的索引,任何元素的访问时间都是常数。但它又不同于数组,ArrayList的数组大小在运行时可以自动的进行调整(进行扩容)。它是线程不安全的。
下面是ArrayList对象的定义属性:
1)ArrayList对象中每个元素的相对位置利用索引表示。索引范围从0-n-1的整数,其中n代表ArrayList对象中元素的数量。
2)给定任何一个索引值,ArrayList对象在这个索引值位置访问元素的访问时间为常数
3)删除在某个地方索引值元素的最坏估计时间worstTime(n)是O(n)。
4)对于在ArrayList对象的末尾插入一个元素,也就是说在索引值为n的位置插入一个元素,averageTime(n)为常数。但是如果ArrayList对象的元素已经用完了分配给ArrayList对象的所有空间,那么试图在索引值为n的位置插入一个元素,分配的空间将自动调整大小,然后在执行插入操作。因此对空间进行扩容操作的插入,worstTime(n)为O(n)。
5)对于在给定索引值位置的插入操作,如果插入操作不需要进行扩容操作,那么worstTime(n,index)为O(n-index)。也就是说,对于靠近开始位置的插入操作比靠近中间位置的插入操作所需时间更长。而靠近末尾的时间是最短。
1、类标题
ArrayList的类标题如下图所示:

ArrayList继承自AbstractList,并实现了四个接口:List、RandomAccess、Cloneable、Serializable。下图是它的类继承关系。

①、ArrayList的可串行化
ArrayList实现了Serializable接口,这是一个标记接口,实现对象的持久化。它用来告诉JVM:任何实现了这个口的类都将可以使用writeObject方法把类中的所有对象复制到输出流,也就是ArrayList保存的对象也要实现Serializable接口。也可以反串行化利用readObject读取对象。
下面是一个实例,展示了把保存对象的ArrayList输出到磁盘上后,再读取这个文件输出其元素。
public class SerializableArrayListObject {
static class Apple implements Serializable {
private final String name;
public Apple(String name) {
this.name = name;
}
@Override
public String toString() {
return "Apple: " + name;
}
}
public static void outputObject(ObjectOutputStream out, Object o) {
try {
out.writeObject(o);
} catch (IOException e) {
e.printStackTrace();
}
}
public static Object readObject(ObjectInputStream in) {
try {
return in.readObject();
} catch (ClassNotFoundException | IOException e) {
e.printStackTrace();
}
return null;
}
public static void main(String[] args) throws FileNotFoundException, IOException {
ArrayList apples = new ArrayList(100);
apples.add(new SerializableArrayListObject.Apple("1"));
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("D:\\name.data"));
ObjectInputStream in = new ObjectInputStream(new FileInputStream("D:\\name.data"));
SerializableArrayListObject.outputObject(out, apples);
@SuppressWarnings("unchecked")
ArrayList get = (ArrayList) SerializableArrayListObject.readObject(in);
System.out.println(get);
}
} ②、ArrayList的可克隆性
同Serializable接口一样,Clonable接口也是一个标识接口。这个接口仅仅说明clone方法在实现这个接口的类至少可以对调用对象进行字段对字段的克隆。
假设我们执行以下语句
ArrayList myList = new ArrayList(5);
myList.add("yes");
myList.add("no");
myList.add("if");
ArrayList temp = (ArrayList) myList.clone();
执行克隆语句后,将会在内存中开辟一块新空间创建temp。但myList中的元素并没有重新开辟空间创建,而是两个ArrayList的elementData同时指向这个对象。这种复制也称为“浅度复制”。

2、类字段
ArrayList类中有三个关键字段,分别是elementData、size与modCount。
①、elementData
![]()
ArrayList利用elementData数组字段存储对象。elementData字段被标识为transient,表明它无法被串行化。也就是说,保存的是元素本身,而不是这个数组。
②、size
![]()
ArrayList用整型的size字段,记录ArrayList存储了多少元素和用于add方法添加元素的索引值。
③、modCount
![]()
modCount字段是ArrayList从AbstractList继承获得。每次当ArrayList对象进行结构调整时(例如add方法或remove增删元素),这个字段就递增1。此外,每个迭代器实例都会有一个expectedModCount字段,初始化为modCount。一旦迭代器实例激活了next()方法,将检查expectedModCount是否等于modCount。如果不是,说明ArrayList已经被改变,next()返回的值可能不是ArrayList对象中的下一个元素。此时,将会弹出一个异常CouncurrentModificationException。(善意的提醒——“及时失败”)
3、构造方法
ArrayList总共有三个构造方法
①、默认容量的构造方法

创建一个无元素且容量为10的elementData数组。
②、指定容量的构造方法
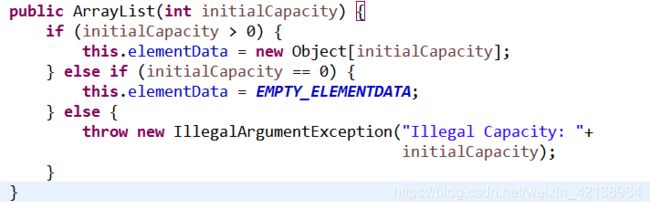
创建一个指定大小无元素的elementData数组。
③、固定容量与含有数据的构造方法
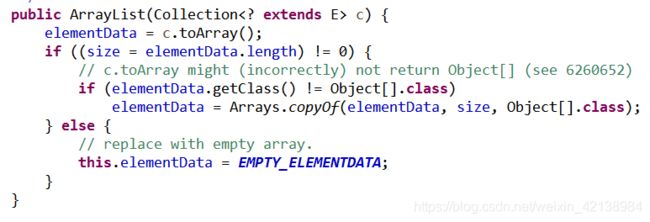
通过传递进来Collection构建elementData数组
4、add()以及数组扩容
在介绍怎么实现elementData扩容之前先来看看add方法的定义

调用ensureCapacityInternal方法将会扩充基本数组,然后新的元素e将会插入数组索引值size的位置处,size递增,并且返回true。
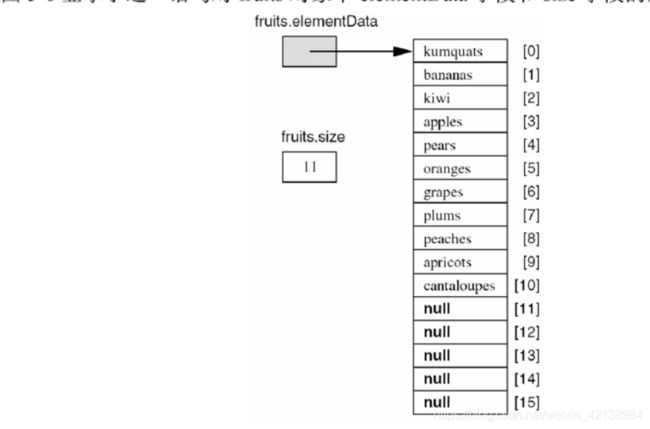
假设我们创建已经创建了ArrayList-friutes对象,调用fruites.add("kumquats")语句后,此时ArrayList的数据结构如下所示:
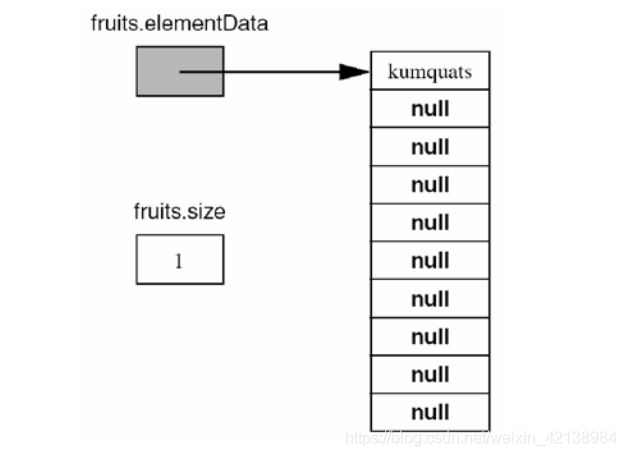
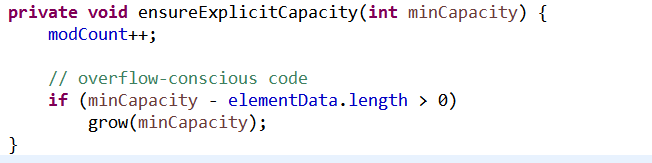
如果当前elementData数组已经存满数据,此时在添加一个数据时。即下面方法中minCapacity - elementData.length > 0时,将会进行扩容,扩容将在grow方法进行,扩充容量的逻辑是:在原有容量基础上加上原有容量右移一位。最后通过调用Arrays.copyOf方法,把原有数组的元素复制到新扩充容量的数组上。

假设原有容量是10,通过这种方式将容量扩充到15。在执行语句fruites.add("cantaloups");那么此时ArrayList数据结构将会是:
5、常用方法
①、indexOf()
方法签名:public int indexOf(Object o)
indexOf方法允许确定传递的对象在elementData数组哪个索引处(通过equlas()方法进行对象的比较),并返回这个索引值。如果对象不再elementData数组中,那么它会返回-1
②、contains()
方法签名:public boolean contains(Object o)
contains方法确定某个对象是否在elementData数组中。通过调用indexOf方法,判断返回值是否大于等于0。
③、remove()
方法签名:public boolean remove(Object o)或public E remove(int index)
remove有两种移除元素的策略:一种通过传递的对象,一种通过传递索引值。
三、基于链表实现的——LinkedList
LinkedList也实现了List接口,所以它支持各种基于索引的方法,如get或indexOf。但它实现的策略与ArrayList是截然不同的,LinkedList内置的数据结构采用链表实现,在运行时也不需要对数组进行扩容(它里面也没有数组存储元素)。
1、LinkedList类标题

LinkedList继承自AbstractSequentialList,实现了四个接口:List、Deque、Cloneable、Serializable接口。
2、LinkedList的字段
LinkList内置了四个重要的字段,分别是
①、size
![]()
size字段用于追踪LinkedList中元素的数目。
②、first
![]()
first类型为Node类型,Node构建了链接表结构的结点(在随后介绍),而first指向这个链接表的头结点
③、last
![]()
last也为Node类型,它指向了链接表的尾结点。
④、modCount
在ArrayList中已经描述过,当执行任何的添加或者移除元素的操作后,modCount的值将会递增。
3、LinkedList的构造方法
LinkedList的构造方法只有两个,一个空的链表。一个是具有初始数据的链表
①、空链表构造方法
![]()
②、含初始数据的链表构造方法

4、LinkedList的实现
在LinkedList中有一个私有静态Node类,它是作为链接表结点的结构,类定义如下:

每个Node含有三个字段,next字段保存LinkedList对象中后一个位置的Node对象,prev字段保存LinkedList对象中前一位置的Node对象,item字段则为保存的元素。其结构如下图:

假设我们创建了一个使用默认的构造方法的names后,产生的结果如下图。其中header为first字段,并且在LinkedList的生命周期中,header.item始终保持为null。注:所以指向Node对象的箭头都表示都代表Node的引用变量。

①、在链表开始插入
方法签名:public void addFirst(E e)
此时我们执行语句names.addFirst("Besty");将会执行以下两个步骤:
1)构造一个新的Node对象,其中next字段指向原链表的第一个元素(如果原链表没有第一个元素,那么这newNode将作为last,并且不执行第二步),prev字段指向null。即newNode.next = first,newNode.prev = null
2)调整原链接表的第一个Node对象,使其prev指向newNode。即first.prev = newNode
在LinkedList对象开始插入与最后插入没有任何特殊地方,其中worstTime(n)为常数。下面给出LinkedList的实现:

②、在链表最后插入
方法签名:public boolean add(E e)
此时我们执行语句names.add("Besty");将会执行以下两个步骤:
1)构造一个新的Node对象,其中next字段指向null,prev字段指向原链接表的最后一个Node对象(如果原链表没有最后一个Node对象,那么这个newNode将作为first,并且不执行第二步)。即newNode.prev = last;、newNode.next = null;。
2)调整原链接表的最后一个Node对象,使其next指向newNode.。即last.next = newNode
当在链表最后插入元素时,列表其他元素没有移动,这就是相当于基本数组已满的ArrayList对象末尾插入一个元素一样(只是前者不需要扩容)。此时worstTime(n)为常数。下面给LinkedList的实现:

③、在链表中间插入
方法签名:public void add(int index, E e)
若我们执行语句是names.add(2,"Besty");(在链表中间插入)将会执行以下三个步骤:
1)构造一个新的Node对象,其中next字段指向原2号位置Node对象,prev字段指向2号位置的prevNode对象。即。
newNode.next = Node2;newNode.prev = Node2.prev;
2)调整原2号位置前一个Node对象的next使其指向newNode。即Node2.prev.next = newNode。
3)调整原2号位置的prev使其指向newNode。即Node2.prev = newNode
当我们在中间进行插入操作时,难点不是插入,而是索引index处的Node对象。LinkedList采取的策略是:size右移一位作为搜索基准,当 i < (size >> 1)找其前面元素,那么再找(i >= (size >> 1)后面的元素。所以最坏的情况是index = (size >> 1)处的元素查找。此时worstTime(n)与n成线性关系。下面是LinkedList查找index处元素的实现:
注:以上操作都会导致size++,modCount++

④、删除链表开始元素
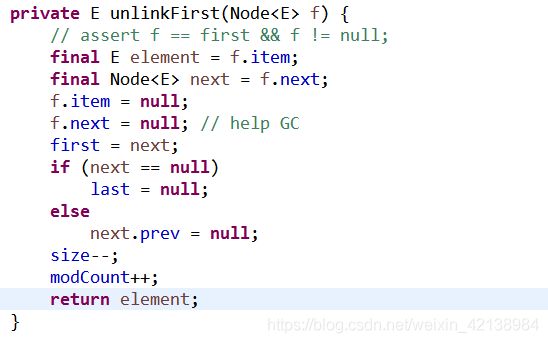
方法签名:public E removeFirst()
删除链表开始元素需要下列两个步骤:
1)获取带删除对象x的x.item(E类型),x.next(Node类型)对象。
2)把x.next作为first,如果x.next为null(说明链接表没有其它元素),那么last也为null。否则,x.next.prev = null。并把x.next = null。x.item = null。下面是LinkedList的实现:
⑤、删除链表最后元素
方法签名:public E removeLast()
删除链表最后元素需要下列两个步骤:
1)获取带删除对象x的x.item(E类型),x.prev(Node类型)对象。
2)把x.prev作为last,如果x.prev为null(说明链接表没有其它元素),那么first = null。否则,x.prev.next = null。并把x.prev = null,x.item = null。下面是LinkedList的实现:

⑥、在链表中间删除
方法签名:public E remove() 删除第一个元素
public E remove(Object o) 删除指定的元素
public E remove(int index) 删除指定索引的元素
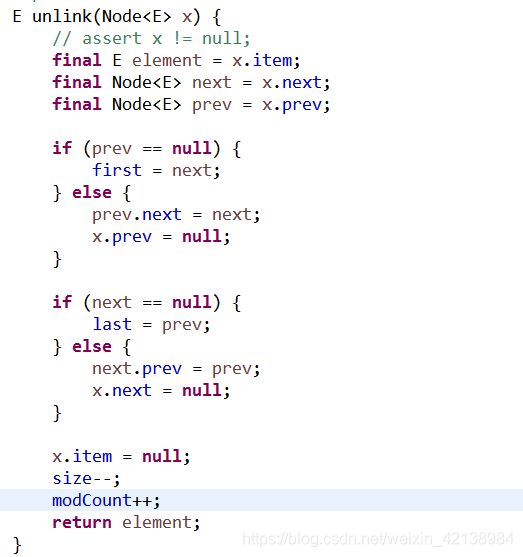
在链表中间删除需要下列三个步骤:
1)获取带删除对象x的x.item(E类型),x.prev(Node类型),x.next(Node类型)对象。
2)当x.prev为空时,说明这个对象是第一个结点,那么first = x.next。否则,x.prev的Node对象的next字段指向x.next,并把x.prev置为null。即 x.prev.next = x.next;x.prev = null
3)当x.next为空时,说明这个对象是最后一个结点,那么last = x.prev。否则,x.next的Node对象的prev字段指向x.prev,并把x.next置为null。即 x.next.prev = x.prev;x.next = null。并返回x.item对象。下面是LinkedList的实现:
⑦、索引第一个元素
方法签名:public E getFirst()
由于LinkedList内置了first字段指向头结点,所以索引第一个元素,将返回frist.item。若first为null则抛出异常
⑧、索引最后一个元素
方法签名:public E getLast()
同样LinkedList也内置last字段指向尾结点,当索引最后一个元素,将返回last,item。若last为null则抛出异常。
⑨、索引某个元素
方法签名:public E get(int index)
LinkedList如何索引某个位置的元素上述一说,就不赘述,这里要说一点,当索引值为负数或者大于size的数那么将抛出异常。
综上:LinkedList采用具有头尾指针的双向循环链表,其Node对象最为链表的结点,它含有prev、next、item三个字段,分别指向起一个Node结点,指向后一个Node结点,保存当前的元素。
5、与ArrayList的对比
①、随机访问:ArrayList基于数组实现,它的随机访问将直接通过索引值找到数组下标,所以其average(n)为O(1)。而LinkedList的随机访问将受限于对某结点索引的困难,它的索引策略是:通过索引值与size >> 1进行比较,把链接表划分为两个区域进行寻找,所以其worstTime(n)为O(n)。
②、插入(或随机插入):当进行大量元素插入,或者随机插入时,ArrayList性能将变得很差,当ArrayList的内置数组容量不够时,它就必须进行扩容操作,其扩容策略是:将原数组复制到扩容到(size + (size >> 1))的新数组中,这将花费O(n)的时间。如果是随机插入的话,除了扩容,将又会把原数组索引处的元素向右移一个的位置,此时worstTime(n)为O(n^2)。而对于LinkedList,它只需进行链表的链接,这也只花费常量的时间,如果是随机插入的话,先搜索到索引处的元素,在进行元素的链接。无论怎么样LinkedList的对于插入操作的性能要优于ArrayList。
③、删除(或随机删除):当进行元素删除时,ArrayList的性能也会很差,因为它会把索引处的元素都进行左移一个位置。而linkedList也只是进行元素重新链接。
下面是对于不同操作,ArrayList与LinkedList的对比图。

当然,我们对List首选的集合还是ArrayList,因为我们大多时候还是做元素的随机访问。当时,若有大量的元素插入或删除此时应选择LinkedList。
四、迭代器
任何的容器类,通过add()或者get()插入或者获取元素。但每一种容器的数据结构插入与获取元素又是那么不同的,那么有没有一种的通用的设计,使我们可以不断持有容器中存有的对象又不必管容器是什么样的数据结构。java采用迭代器模式提供了这种机制。
迭代器模式:提供一种方法顺序访问容器中所有元素,而又不暴露容器底层具体的数据结构。迭代器是轻量级对象,创建它的代价将会很小。
1、Iterator
Iterator是一个接口,它里面共有三个方法。它提供了类似于游标的思想,使得Iterator可以在集合中单向移动:
1)boolean hasNext():检查序列中是否还有元素。
2)E next():获得序列中的下一个元素。
3)default void remove():将迭代器新近返回的元素删除。
下面提供了Iterator对象遍历集合的方式:
public class Test {
public static ArrayList numsList(int size) {
Integer[] numbers = new Integer[size];
for (int i = 0; i < numbers.length; i++)
numbers[i] = i;
ArrayList list = new ArrayList();
Collections.addAll(list, numbers);
return list;
}
public static void main(String[] args) throws InterruptedException {
ArrayList list = Test.numsList(10);
Iterator it = list.iterator();
// 第一种遍历方式
while (it.hasNext()) {
System.out.println(it.next());
}
}
} 一种Iterator的实现:
public class ImplementIterator {
private int size;
private static Integer[] numbers;
private static Random random = new Random(47);
public ImplementIterator(int size) {
this.size = size;
numbers = randomNums(size);
}
public static Integer[] randomNums(int size) {
Integer[] nums = new Integer[size];
for (int i = 0; i < nums.length; i++)
nums[i] = random.nextInt(100);
return nums;
}
public Iterator iterator(){
return new Iterator() {
private int index = 0;
@Override
public boolean hasNext() {
// 索引值不应大于数组的长度
return index < numbers.length;
}
@Override
public Integer next() {
// 返回当前索引值元素,并把索引值加1
return numbers[index++];
}
// 可选操作
@Override
public void remove() {
throw new UnsupportedOperationException();
}
};
}
public static void main(String[] args) {
ImplementIterator im = new ImplementIterator(10);
Iterator it = im.iterator();
while(it.hasNext())
System.out.println(it.next());
}
} 2、ListIterator
ListIterator是一个更加强大的Iterator子类型,它只能用于各种List类的访问。ListIterator支持游标的双向移动,可以产生迭代器列表中指向的当前位置的前一个索引和后一个元素的索引,并且可以使用set()方法替换它访问过的最后一个元素。
可以通过调用listIterator()产生一个指向List开始处的ListIterator,并且可以调用listIterator(index)产生一个开始指向index处元素的ListIterator。
下面是使用ListIterator的遍历:
public class ListIteration {
public static void main(String[] args) {
ArrayList pets = Pets.createArrayList(10);
ListIterator lit = pets.listIterator();
// 游标向后移动
while (lit.hasNext())
System.out.println(lit.next() + ", " +
lit.nextIndex() + ", " + lit.previousIndex() );
// 游标向前移动
while (lit.hasPrevious())
System.out.println(lit.previous());
System.out.println(pets);
// 获取索引值为3开始处的游标
lit = pets.listIterator(3);
while(lit.hasNext()) {
lit.next();
// 修改迭代器访问过的元素
lit.set(Pets.randomPet());
}
System.out.println(pets);
}
} 3、Iterable
Iterable接口中有一个iterator()方法,它用于提供标准的迭代器实现。基本上所有的容器都实现了这个接口。这个接口还有另外一层含义:实现该接口的类可以作为foreach语句中的迭代对象。
Iterable接口需要我们编写标准用于迭代的iterator,下面是通过编写适合反向迭代ArrayList中的方法(通过适配器模式实现)。
class ReveribleArryaList extends ArrayList {
public ReveribleArryaList() {
super();
}
public ReveribleArryaList(Collection c) {
super(c);
}
public ReveribleArryaList(int initialCapacity) {
super(initialCapacity);
}
// 从后向前移动的迭代器 可以用于foreach语句
public Iterable reversed(){
return new Iterable() {
@Override
public Iterator iterator() {
return new Iterator() {
int current = size() - 1;
@Override
public boolean hasNext() {
return current > -1;
}
@Override
public T next() {
return get(current--);
}
};
}
};
}
}
public class AdapterMethodIdiom {
public static void main(String [] args) {
ReveribleArryaList ra1 = new ReveribleArryaList(Arrays.asList("To be or not to be".split(" ")));
// 默认的迭代器
for(String s : ra1) {
System.out.println(s);
}
System.out.println();
// 自定义的迭代器
for(String s : ra1.reversed()) {
System.out.println(s);
}
}
} 五、Queue
队列是一个典型的先进先出(FIFO)的容器。从一端放入对象,到另一端取出。对象放入容器的顺序与取出的顺序是一致的。在对队列中:
1)只能在队列尾进行插入
2)只能在队列头进行删除、获取和修改
下图展示了在队列中插入和删除的过程:
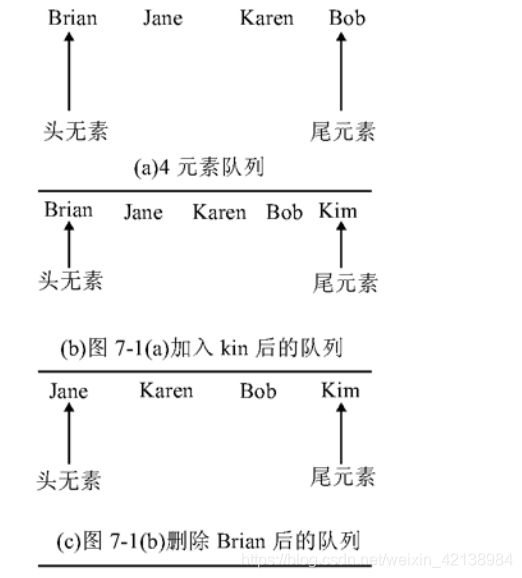
LinkedList提供了方法以支持队列的行为,它实现了Queue接口。所以可以作为Queue的一种实现。下面是Queue的一些相关方法:
1)offer():它在允许的情况下,将一个元素插入到队尾。
2)peek():在不移除元素的情况下返回队列头部元素,但当队列如果为空返回null
3)element():同peek()在不移除元素的情况下返回队列头部元素,但当队列为空时抛出NoSuchElementException异常
4)poll():移除并返回队头元素,当队列为空时返回null
5)remove():同poll()移除并返回队头元素,当队列为空时抛出NoSuchElementException异常。
下面程序是通过把LinkedList向上转型为Queue,使用Queue的一些相关方法。
public class QueueDemo {
public static void printQueue(Queue queue) {
while(queue.peek() != null) {
System.out.println(queue.poll() + " ");
}
System.out.println();
}
public static void main(String [] args) {
Queue queue = new LinkedList();
Random random = new Random(47);
for (int i = 0; i < 10; i++) {
// offer()方法用于入队列
queue.offer(random.nextInt(i + 10));
}
printQueue(queue);
Queue qc = new LinkedList();
for(char c : "Brontosaurus".toCharArray()) {
qc.offer(c);
}
printQueue(qc);
}
}