CNN模型压缩总结
CNN模型压缩总结
总结综述
参考:https://blog.csdn.net/shentanyue/article/details/83508497
模型裁剪/剪枝(Pruning)
单个权重(Weight)剪枝——非结构化
- 定义:任意权重被看作是单个参数并进行随机非结构化剪枝。
缺点:
- 导致网络连接不规整,需要通过稀疏表达来减少内存占用,进而导致在前向传播时,需要大量条件判断和额外空间来标明0或非0参数位置,因此不适合并行计算。
- 非结构化的稀疏性需要使用专门的软件计算库或者硬件。
核内权重(Intra Kernel Weight)剪枝/核的稀疏化——结构化
- 对权重的更新加以正则项进行限制,使其更加稀疏,使大部分的权值都为0。
卷积核(Kernel)/特征图(Feature Map)/通道(Channel/ Filter)剪枝——结构化
- 定义:减去第i层的filter,进而减去第i层产生的部分特征图和第i+1层的部分kernel。
- kernel粒度的显著性度量可以采用kernel的权重和来判断
- 采用Filter的权重和来判断
- 其他
- FeatureMap粒度的显著性度量确定:
- 采用Filter权重和来判断
- 其他
优点:
- 不依赖任何稀疏卷积计算库及专用软件
- 能大大减少测试的计算时间。
中间隐层(Layer)剪枝
- 定义:删除一些层,即改变网络结构
网络分解(张量分解)
- 方法:
- 将三维张量铺展成二维张量,使用标准SVD方法
- 使用多个一维张量外积求和逼近(用三个一维张量外积求和进行K次累加来逼近一个秩为K的三维张量)
- 目的:降低模型的时间复杂度
- 通常基于张量的低秩近似理论和方法,将原始的权重张量分解为两个或者多个张量,并对分解张量进行优化调整
- 优缺点:
- 低秩方法很适合模型压缩和加速。
- 低秩方法的实现并不容易,因为它涉及计算成本高昂的分解操作。
- 目前的方法逐层执行低秩近似,无法执行非常重要的全局参数压缩,因为不同的层具备不同的信息。
- 分解需要大量的重新训练来达到收敛。
CP分解
- [2014,JADERBER]Speeding up convolutional neural networks using fine-tuned CP-decomposition
- 思想:采用CP分解法将一层网络分解为五层低复杂度的网络层,但在基于随机梯度下降法的模型权重微调过程中难以获取张量分解的优化解.作者利用两个卷积神经网络模 型对该方法进行评估,结果表明该方法以较低的性能损失实现更高的计算速度
- [2014,Denton,NIPS]Exploiting linear structure within convolutional netowrks for efficient evalution
- 思想:探索多种张量分解方法,例如二维张量分解可采用奇异值分解法,三维张量可转化为二维张量进行分解,以及单色卷积分解和聚类法低秩分解等.作者利用 卷 积 参 数 的冗余性获得 近似计算过程,较大的减少所需的计算量,在保持原始模型浮动1%精度的条件下,基于 CPU和GPU的计算过程均取得近2倍的加速。
SVD分解
- [2016,Zhang]Accelerating very deep convolutional networks for classification and detection
- 思想:对参数矩阵进行张量SVD分解进行非线性问题的求解,同时不需要通过随机梯度下降过程进行优化,并在非对称重构中考虑前一网络层的累计重构误差,在不需要随机梯度下降(SGD)的情况下,开发了一种有效的非线性优化问题求解方法
- [2015,Jaderberg,BMVC]Speeding up convolutional neural networks with low rank expansions
- 思想:使用秩为1(可以分解为行向量与列向量乘积)的卷积核作用在输入图上产生相互独立的M个基本特征图,卷积神经网络大小为k×k 的卷积核分解为1×k 和k×1的卷积核, 然后通过学习到的字典权重利用线性组合重构出输出特征图。
- [2017,Tai]Convolutional neural networks with low-rank regularization. (Princeton University, etc.)
- 思想:提出从零开始训练低秩约束卷积神经网络模型的方法,不仅速度得到提升,而且在一些情况下模型性能也有所提高.作者提出一种低阶张量分解的新算法,用于消除卷积核中的冗余.该算法找 到 矩阵分解 的精神的全局优化器,比迭代方法更有效。
Tucker分解
张量分解知识(含CP分解,Tucker分解):
https://blog.csdn.net/Flying_sfeng/article/details/82109439
_________________________________________________________________
[2015,Kim,Computer science]Compression of deep convolutional neural networks for fast and low power mobile applications
- 思想:首先进行变分贝叶斯矩阵分解的秩选择,然后再进行核张量Tucker分解,最后再次对模型进行调整。
张量列分解(Tensor Train,TT)
- [2015,NOVIKOV]Tensorizing Neural Networks.
- Ultimate tensorization_compressing convolutional and FC layers alike. (Moscow State University, etc)
未归类
- [2013,Sainath,ieeeicassp]Low-rank matrix factorization for deep neural network training with high-dimensional output targets
- 思想:
- [2015,Liu,CVPR]Sparse convolutional neural networks
- 思想:利用通道间和通道内冗余,在通道上进行稀疏分解,然后将高计算代价的卷积操作转换成矩阵相乘。然后再将矩阵稀疏化,结合微调步骤,最小化含有稀疏性最大化正则项的损失函数
- [2013,Denil,NIPS]Predicting Parameters in Deep Learning
权值共享
结构化矩阵
- 思想:如果一个 m x n 阶矩阵只需要少于 m×n 个参数来描述,就是一个结构化矩阵。通常这样的结构不仅能减少内存消耗,还能通过快速的矩阵-向量乘法和梯度计算显著加快推理和训练的速度。
- Structured Convolution Matrices for Energy-efficient Deep learning. (IBM Research–Almaden)
- Structured Transforms for Small-Footprint Deep Learning. (Google Inc)
- An Exploration of Parameter Redundancy in Deep Networks with Circulant Projections.
- Theoretical Properties for Neural Networks with Weight Matrices of Low Displacement Rank.
哈希
- Functional Hashing for Compressing Neural Networks. (Baidu Inc)
- [2015,Chen,ICML]Compressing Neural Networks with the Hashing Trick
- 思想:将参数映射到相应的哈希桶内,在同一个哈希桶内的参数则共享同一值。
其他
- [2016,Han,ICLR]Deep compression:compressing deep neural networks with pruning,trained quantization and Huffman coding
- 思想:
- 利用k均值聚类算法计算权重的多个聚类中心,将权重量化为距离最近的聚类中心,通过训练微调的方式对权重进行补偿。
- 首先修剪不重要的连接,重新训练稀疏连接的网络。然后使用权重共享连接的权重,再对量化后的权重和码本(codebook)使用霍夫曼编码,以进一步降低压缩率。
- [2014,Gong,]Compressing deep convolutional networks using vector quantization
- 思想:通过使用kmeans算法将全部参数进行聚类,每簇中参数共享中心值。
- Learning compact recurrent neural networks. (University of Southern California + Google)
权重量化(Quantization)
- 思想:通过减少表示每个权重所需的比特数来压缩原始网络。
定点运算
- [2011,Vanhoucke,NIPS]Improving the speed of neural networks on CPUs
- [2014,Hwang,Journal of Signal Processing Systems]Fixed-point feedforward deep neural network design using weights+1,0,and -1
- [2016,DETTMERS]8-bit approximations for parallelism in deep learning
- 思想:开发并测试8bit近似算法,将32bit的梯度和激活值压缩到8bit,通过 GPU集群测试模型和数据的并行化性能,在保证模型预测精度的条件下,提出的方法取得两倍的数 据传输加速。
二值化、三值化
- [2015,Courbariaux,NIPS]Binarized Neural Networks:Training deep neural networks with weights and activations constrained to+1 or-1
- 思想:二值化的权重策略对网络的权重进行较为极端的量化,限制权重只能是-1或1。
- [2016,Rastegari,ECCV]Xnornet: Imagenet classification using binary convolutional neural networkSpeeding s
- 思想:网络权重二值化、输入二值化,从头开始训练一个二值化网络,不是在已有的网络上二值化。
- [2017,]Performance Guaranteed Network Acceleration via High-Order Residual Quantization
- 思想:本文是对 XNOR-Networks 的改进,将CNN网络层的输入 进行高精度二值量化,从而实现高精度的二值网络计算,XNOR-Networks 也是对每个CNN网络层的权值和输入进行二值化,这样整个CNN计算都是二值化的,这样计算速度快,占内存小。
- [2017,Lin]Neural networks with few multiplications
- 思想:
- [2017,Zhou,ICLR]Incremental network quantization:Towards lossless cnns with low-precision weights
- 思想:给定任意结构的全精度浮点神经网络模型,能将其转换成无损的低比特二进制模型。增量式网络量化方法,三种独立操作:权重划分、分组量化、再训练。
- [2017,Guo,CVPR]Network Sketching: Exploiting Binary Structure in Deep CNNs
- [2016,Fengfu,CVPR]Ternary weight networks
- 思想:三值化
未分类
- [2016,Soulie,ICANN]Compression of deep neural networks on the fly
- 思想:在模型学习阶段进行压缩的方法。首先在全连接层损失函数上增加额外的归一项,使得权重趋向于二进制值,然后对输出层进行粗粒度的量化。
- [2015,]Deep learning with limited numerical precision
- 思想:基于随机修约(stochastic rounding)的 CNN 训练中使用 16 比特定点表示法(fixed-point representation),显著降低内存和浮点运算,同时分类准确率几乎没有受到损失。
- [2016,ZHOU]DoReFa-Net:training low bitwidth convolutional neural networks with low bitwidth gradients
- 思想:利用低比特的梯度参数训练低比特的模型权重,且激活值也为低比特数据,该技术可对训练和预测过程进行加速。
- [2016,Wu,CVPR]Quantized convolutional neural networks for mobile devices
- 思想:提 出 一 个 量 化 卷 积 神 经 网 络 框 架 (CNN),基于k 均值聚类算法加速和压缩模型的卷积层和全连接层,通过减小每层输出响应的估计误差可实现更好的量化结果,并提出一种有效的训练方案抑制量化后的多层累积误差。用一个小矩阵(codebook)去量化大矩阵(权重矩阵)
- ShiftCNN: Generalized Low-Precision Architecture for Inference of Convolutional Neural Networks
- 思想:一个利用低精度和量化技术实现的神经网络压缩与加速方案。
- 该量化方法具有码本小、量化简单、量化误差小的优点。
迁移学习/网络精馏
- 迁移学习:将一个模型的性能迁移到另一个模型上
- 网络精馏:在同一个域上迁移学习的一种特例。
计算加速
- Faster CNNs with direct sparse convolutions and guided pruning
- 思想:提出一种基于向量形式的乘法,实现密集矩阵与稀疏矩阵之间的高效乘法运算。
- [2017,Gysel]Hardware-oriented approximation of convolutional neural networks
- 思想:提出一种模型近似框架 Ristretto,用于分析模型卷积层和全连接层的权重和输出的数值分辨率,进而将浮点型参数转化为定点型数值,并通过训练过程对定点型模型进行微调。
- [2017,ICML]MEC: Memory-efficient Convolution for Deep Neural Network
- 思想:内存利用率高且速度较快的卷积计算方法
- More is Less: A More Complicated Network with Less Inference Complexitv
- 思想:提前锁定哪些值将会为0,从而在矩阵乘法时直接避免相应运算。
- Speeding up Convolutional Neural Networks By Exploiting the Sparsity of Rectifier Units
- 思想:由于使用ReLU作为激活函数的网络,其网络输出通常都非常稀疏。本文不计算完整的矩阵乘法,而是只计算非0值导致的输出。并且,充分利用AVX或者SSE指令完成 (1×1)×(1×4)(1×1)×(1×4)的乘法。
对数据进行变换
WAE-Learning a Wavelet-like Auto-Encoder to Accelerate Deep Neural Networks
- 思想:WAE借助小波分解得思想,将原图分解成两个低分辨率图像,以达到网络加速的目。
核稀疏化
参考:https://blog.csdn.net/shentanyue/article/details/83539227
前言
目前在深度学习领域分类两个派别,一派为学院派,研究强大、复杂的模型网络和实验方法,为了追求更高的性能;另一派为工程派,旨在将算法更稳定、高效的落地在硬件平台上,效率是其追求的目标。复杂的模型固然具有更好的性能,但是高额的存储空间、计算资源消耗是使其难以有效的应用在各硬件平台上的重要原因。
最近正好在关注有关深度学习模型压缩的方法,发现目前已有越来越多关于模型压缩方法的研究,从理论研究到平台实现,取得了非常大的进展。
2015年,Han发表的Deep Compression是一篇对于模型压缩方法的综述型文章,将裁剪、权值共享和量化、编码等方式运用在模型压缩上,取得了非常好的效果,作为ICLR2016的best paper,也引起了模型压缩方法研究的热潮。其实模型压缩最早可以追溯到1989年,Lecun老爷子的那篇Optimal Brain Damage(OBD)就提出来,可以将网络中不重要的参数剔除,达到压缩尺寸的作用,想想就可怕,那时候连个深度网络都训练不出来,更没有现在这么发达的技术,Lecun就已经想好怎么做裁剪了,真是有先见之明,目前很多裁剪方案,都是基于老爷子的OBD方法。
目前深度学习模型压缩方法的研究主要可以分为以下几个方向:
更精细模型的设计,目前的很多网络都具有模块化的设计,在深度和宽度上都很大,这也造成了参数的冗余很多,因此有很多关于模型设计的研究,如SqueezeNet、MobileNet等,使用更加细致、高效的模型设计,能够很大程度的减少模型尺寸,并且也具有不错的性能。
模型裁剪,结构复杂的网络具有非常好的性能,其参数也存在冗余,因此对于已训练好的模型网络,可以寻找一种有效的评判手段,将不重要的connection或者filter进行裁剪来减少模型的冗余。
核的稀疏化,在训练过程中,对权重的更新进行诱导,使其更加稀疏,对于稀疏矩阵,可以使用更加紧致的存储方式,如CSC,但是使用稀疏矩阵操作在硬件平台上运算效率不高,容易受到带宽的影响,因此加速并不明显。
除此之外,量化、Low-rank分解、迁移学习等方法也有很多研究,并在模型压缩中起到了非常好的效果。
核的稀疏化(训练过程中使其稀疏)
核的稀疏化,是在训练过程中,对权重的更新加以正则项进行诱导,使其更加稀疏,使大部分的权值都为0。核的稀疏化方法分为regular和irregular,regular的稀疏化后,裁剪起来更加容易,尤其是对im2col的矩阵操作,效率更高;而irregular的稀疏化后,参数需要特定的存储方式,或者需要平台上稀疏矩阵操作库的支持,可以参考的论文有:
- Learning Structured Sparsity in Deep Neural Networks 论文地址
本文作者提出了一种Structured Sparsity Learning的学习方式,能够学习一个稀疏的结构来降低计算消耗,所学到的结构性稀疏化能够有效的在硬件上进行加速。 传统非结构化的随机稀疏化会带来不规则的内存访问,因此在GPU等硬件平台上无法有效的进行加速。 作者在网络的目标函数上增加了group lasso的限制项,可以实现filter级与channel级以及shape级稀疏化。所有稀疏化的操作都是基于下面的loss func进行的,其中Rg为group lasso:
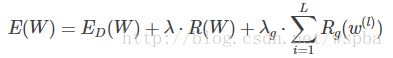
则filter-channel wise:
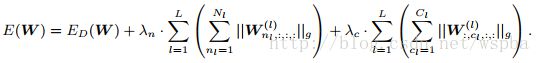
而shape wise:

由于在GEMM中将weight tensor拉成matrix的结构,因此可以通过将filter级与shape级的稀疏化进行结合来将2D矩阵的行和列稀疏化,再分别在矩阵的行和列上裁剪掉剔除全为0的值可以来降低矩阵的维度从而提升模型的运算效率。该方法是regular的方法,压缩粒度较粗,可以适用于各种现成的算法库,但是训练的收敛性和优化难度不确定。作者的源码为:https://github.com/wenwei202/caffe/tree/scnn - Dynamic Network Surgery for Efficient DNNs 论文地址
作者提出了一种动态的模型裁剪方法,包括以下两个过程:pruning和splicing,其中pruning就是将认为不中要的weight裁掉,但是往往无法直观的判断哪些weight是否重要,因此在这里增加了一个splicing的过程,将哪些重要的被裁掉的weight再恢复回来,类似于一种外科手术的过程,将重要的结构修补回来,它的算法如下:

作者通过在W上增加一个T来实现,T为一个2值矩阵,起到的相当于一个mask的功能,当某个位置为1时,将该位置的weight保留,为0时,裁剪。在训练过程中通过一个可学习mask将weight中真正不重要的值剔除,从而使得weight变稀疏。由于在删除一些网络的连接,会导致网络其他连接的重要性发生改变,所以通过优化最小损失函数来训练删除后的网络比较合适。
优化问题表达如下:

参数迭代如下:

其中用于表示网络连接的重要性 h 函数定义如下:
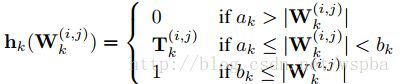
该算法采取了剪枝与嫁接相结合、训练与压缩相同步的策略完成网络压缩任务。通过网络嫁接操作的引入,避免了错误剪枝所造成的性能损失,从而在实际操作中更好地逼近网络压缩的理论极限。属于irregular的方式,但是ak和bk的值在不同的模型以及不同的层中无法确定,并且容易受到稀疏矩阵算法库以及带宽的限制。论文源码:https://github.com/yiwenguo/Dynamic-Network-Surgery - Training Skinny Deep Neural Networks with Iterative Hard Thresholding Methods 论文地址
作者想通过训练一个稀疏度高的网络来降低模型的运算量,通过在网络的损失函数中增加一个关于W的L0范式可以降低W的稀疏度,但是L0范式就导致这是一个N-P难题,是一个难优化求解问题,因此作者从另一个思路来训练这个稀疏化的网络。算法的流程如下:

先正常训练网络s1轮,然后Ok(W)表示选出W中数值最大的k个数,而将剩下的值置为0,supp(W,k)表示W中最大的k个值的序号,继续训练s2轮,仅更新非0的W,然后再将之前置为0的W放开进行更新,继续训练s1轮,这样反复直至训练完毕。 同样也是对参数进行诱导的方式,边训练边裁剪,先将认为不重要的值裁掉,再通过一个restore的过程将重要却被误裁的参数恢复回来。也是属于irregular的方式,边训边裁,性能不错,压缩的力度难以保证。
总结
以上三篇文章都是基于核稀疏化的方法,都是在训练过程中,对参数的更新进行限制,使其趋向于稀疏,或者在训练的过程中将不重要的连接截断掉,其中第一篇文章提供了结构化的稀疏化,可以利用GEMM的矩阵操作来实现加速。第二篇文章同样是在权重更新的时候增加限制,虽然通过对权重的更新进行限制可以很好的达到稀疏化的目的,但是给训练的优化增加了难度,降低了模型的收敛性。此外第二篇和第三篇文章都是非结构化的稀疏化,容易受到稀疏矩阵算法库以及带宽的限制,这两篇文章在截断连接后还使用了一个surgery的过程,能够降低重要参数被裁剪的风险。之后还会对其他的模型压缩方法进行介绍。
模型剪枝(Pruning)
参考:https://blog.csdn.net/shentanyue/article/details/83539359
前言
上一章,将基于核的稀疏化方法的模型压缩方法进行了介绍,提出了几篇值得大家去学习的论文,本章,将继续对深度学习模型压缩方法进行介绍,主要介绍的方向为基于模型裁剪的方法,由于本人主要研究的为这个方向,故本次推荐的论文数量较多,但都是非常值得一读的。
总结
可以看出来,基于模型裁剪的方法很多,其思路源头都是来自于Oracle pruning 的方法,即挑选出模型中不重要的参数,将其剔除而不会对模型的效果造成太大的影响,而如何找到一个有效的对参数重要性的评价手段,在这个方法中就尤为重要,我们也可以看到,这种评价标准花样百出,各有不同,也很难判定那种方法更好。在剔除不重要的参数之后,通过一个retrain的过程来恢复模型的性能,这样就可以在保证模型性能的情况下,最大程度的压缩模型参数及运算量。目前,基于模型裁剪的方法是最为简单有效的模型压缩方式。(未完待续)
模型蒸馏(Distilling)与精细模型网络
参考:https://blog.csdn.net/shentanyue/article/details/83539382
前言
在前两章,我们介绍了一些在已有的深度学习模型的基础上,直接对其进行压缩的方法,包括核的稀疏化,和模型的裁剪两个方面的内容,其中核的稀疏化可能需要一些稀疏计算库的支持,其加速的效果可能受到带宽、稀疏度等很多因素的制约;而模型的裁剪方法则比较简单明了,直接在原有的模型上剔除掉不重要的filter,虽然这种压缩方式比较粗糙,但是神经网络的自适应能力很强,加上大的模型往往冗余比较多,将一些参数剔除之后,通过一些retraining的手段可以将由剔除参数而降低的性能恢复回来,因此只需要挑选一种合适的裁剪手段以及retraining方式,就能够有效的在已有模型的基础上对其进行很大程度的压缩,是目前使用最普遍的方法。然而除了这两种方法以外,本文还将为大家介绍另外两种方法:基于教师——学生网络、以及精细模型设计的方法。
结论
目前关于深度学习模型压缩的方法有很多,本系列博文从四个角度来对模型压缩的方法进行了介绍,总的来说,所列出的文章和方法都具有非常强的借鉴性,值得我们去学习,效果也较明显。其中基于核稀疏化的方法,主要是在参数更新时增加额外的惩罚项,来诱导核的稀疏化,然后就可以利用裁剪或者稀疏矩阵的相关操作来实现模型的压缩;基于模型裁剪的方法,主要是对已训练好的网络进行压缩,往往就是寻找一种更加有效的评价方式,将不重要的参数剔除,以达到模型压缩的目的,这种压缩方法实现简单,尤其是regular的方式,裁剪效率最高,但是如何寻找一个最有效的评价方式是最重要的。基于迁移学习的方法,利用一个性能好的教师网络来监督学生网络进行学习,大大降低了简单网络学习到不重要信息的比例,提高了参数的利用效率,也是目前用的较多的方法。基于精细模型设计的方法,模型本身体积小,运行速度快,性能也不错,目前小的高效模型也开始广泛运用在各种嵌入式平台中。
总的来说,以上几种方法可以结合使用,比如说先对参数进行结构化的限制,使得参数裁剪起来更加容易,然后再选择合适的裁剪方法,考虑不同的评价标准以及裁剪策略,并在裁剪过程中充分考虑参数量、计算量、带宽等需求,以及不同硬件平台特性,在模型的性能、压缩、以及平台上的加速很好的进行权衡,才能够达到更好的效果。
Deep Compression
见我的另一篇博客韩松博士毕业论文https://blog.csdn.net/qq_23546067/article/details/103626894