Quantum Tensor Networks in a Nutshell
目录
1. quantum Legos
2. From Tensors to Networks
3. Bending and Crossing Wires
4. Diagrammatic SVD
5. Matrix Product States
6. Counting by Tensor Contrsction
Counting Boolean Formula Solutions
Counting Graph Colorings
7. Frontiers in Tensor Networks
Acknowledgments
Regerences
A.Tensors and Tensor Products
1、量子基础
- 张量是一个数学概念,它是多线性映射的概括总结和推广,即:多变量函数关于每一个变量都是线性的。
- 张量网络是由张量缩并结合起来的张量的可数集。
张量网络以一种直观的图形语言展现出来。量子线路是一种特殊的张量网络,由特定类型的张量排列形成。 - 张量网络的著名的应用是:1D Matrix Product States(MPS)、Tensor Trains(TT)、Tree Tensor Networks(TTN)、the Multi-scale Entanglement Renormalization Ansatz(MERA)、Projected Entangled Pair States(PEPS)
- 利用简单、常规结构的张量网络去近似一个复杂量子态的方法,本质上应用了可以保留量子态最重要特性的有耗数据压缩。
- 下图表示了张量网络是如何以多种多样的方式表达或者近似一个量子态 ∣ ψ ⟩ \vert\psi\rangle ∣ψ⟩:

- 本文作者假设读者已经知晓:量子理论、线性代数、张量
2、从张量到网络
1、画张量
在张量图示中,一个张良是一个带有标签的图形,方形或者三角形,带有0条或者多条输出边,指向上;带有0条或者多条输入边,指向下。单独的边分别对应上下指标。表示边的线如果必要的话标记上表示的指标或者它们对应的向量空间, ( 0 , 0 ) (0,0) (0,0)阶的张量没有任何边,表示一个复数。例如,图(a)表示张量 ψ i \psi^i ψi有一个上指标,是一个向量。图(b)表示张量 A k j A_{~~k}^j A kj是一个矩阵,图©表示张量 T j k i T^i_{jk} Tjki.
2、张量并列
当有两个或者更多不连接的张量出现在同一个图里,它们通过张量积相乘,在抽象索引表示法中,张量积符号省略,张量可以很自由的穿过彼此移动,有时称为平面变形。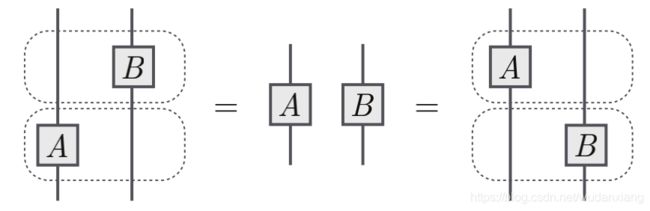
上图所对应的方程如下: ( I ⊗ B ) ( A ⊗ I ) = ( A ⊗ B ) = ( A ⊗ I ) ( I ⊗ B ) (I\otimes B)(A\otimes I)=(A\otimes B)=(A\otimes I)(I\otimes B) (I⊗B)(A⊗I)=(A⊗B)=(A⊗I)(I⊗B).其中,也用线来表示恒等张量 I I I.线允许穿过张量符号和其他线只要线的最后指向不变即可。下图没有对线标记,如果标记的话,可以记为: Q b d e g R a c f . Q^{deg}_bR^f_{ac}. QbdegRacf.

3、连接线
利用一条边连接两个张量的边表示对应指标的缩并(求和)。
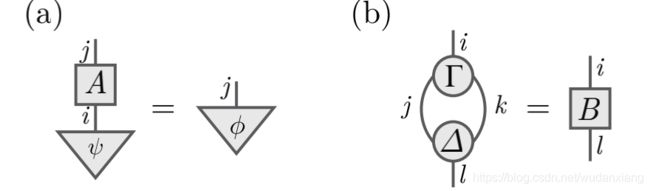
图(a)表示一个矩阵乘以一个向量得到一个向量,图(a)等价于下述表达: A i j ψ i = ϕ j A^j_{~~i}\psi^i=\phi^j A ijψi=ϕj注意到,表示指标 i i i的线完全连接起来了,因此对应的指标被缩并了。使用 E i n s t e i n s u m m a t i o n c o n v e n t i o n Einstein~summation~convention Einstein summation convention,任意的指标在同一项里出现两次(上下指标各一次)就缩并。图(b)缩并两个3阶张量的指标,等价于: Γ j k i Δ l j k = B l i . \Gamma^i_{~~jk}\Delta^{jk}_l=B^i_{~~l}. Γ jkiΔljk=B li.
两个及其以上的张量在一个图里形成一个张量网络,如果在这个张量网络中任何一个张量都没有边我们称之为充分缩并:计算得到一个复数,是一个标量。
4、连接到量子计算符号
张量是多重线性映射,可以在任意给定的基下展开,按照它的组成部分表达出来,在量子信息科学里,每一个 H i l b e r t s p a c e Hilbert ~space Hilbert space有一组计算基 { ∣ k ⟩ } k \left\{\vert k\rangle\right\}_k {∣k⟩}k并且张量可以在这组基下展开。 T = ∑ i j k T j k i ∣ i ⟩ ⟨ j k ∣ . T=\sum_{ijk}T^i_{~~jk}\vert i\rangle\langle jk\vert. T=ijk∑T jki∣i⟩⟨jk∣.其中 T j k i T^i_{~~jk} T jki是在计算基下张量的组合部分。
例1( ϵ \epsilon ϵ张量)
一个张量是完全反对称的,如果交换任意指标对它的符号就改变: A i j = − A j i A_{ij}=-A_{ji} Aij=−Aji, ϵ \epsilon ϵ张量用来表达这种完全反对称 L e v i − C i v i t a Levi-Civita Levi−Civita记号,在2维的情形表达如下: ϵ 00 = ϵ 11 = 0 , ϵ 01 = − ϵ 10 = 1 \epsilon_{00}=\epsilon_{11}=0,~~~~~~~~~~~\epsilon_{01}=-\epsilon_{10}=1 ϵ00=ϵ11=0, ϵ01=−ϵ10=1 ϵ \epsilon ϵ张量可以用来计算矩阵的行列式,在2维的情形,有: d e t ( S ) = ϵ i j S 0 i S 1 j . det(S)=\epsilon_{ij}S^i_{~0}S^j_{~1}. det(S)=ϵijS 0iS 1j.利用上式,可以得到:

对应的方程是: ϵ i j S m i S n j = d e t ( S ) ϵ m n . \epsilon_{ij}S^i_{~m}S^j_{~n}=det(S)\epsilon_{mn}. ϵijS miS nj=det(S)ϵmn.按照量子力学, ϵ \epsilon ϵ对应一个 2 − q u b i t 2-qubit 2−qubit纯态: 1 2 ∣ ϵ ⟩ = 1 2 ( ∣ 01 ⟩ − ∣ 10 ⟩ ) . \frac{1}{\sqrt2}\vert\epsilon\rangle=\frac{1}{\sqrt2}(\vert 01\rangle-\vert 10\rangle). 21∣ϵ⟩=21(∣01⟩−∣10⟩).这个量子态在任意一个形为 U ⊗ U U\otimes U U⊗U的变换下是不变的,(其中 U U U是 2 × 2 2\times2 2×2酉矩阵),仅仅相差一个全局相位因子。
例2(并发和纠缠)
给定一个 2 − q u b i t 2-qubit 2−qubit纯量子态 ∣ ψ ⟩ \vert \psi\rangle ∣ψ⟩,它的并发( c o n c u r r e n c e concurrence concurrence) C ( ψ ) = ∣ C ′ ( ψ ) ∣ C(\psi)=\vert C\prime (\psi)\vert C(ψ)=∣C′(ψ)∣是下列张量网络表达的绝对值:

其中 ψ ˉ \bar\psi ψˉ是 ψ \psi ψ在计算基下的复共轭。并发是一种纠缠单配性,是一种从态到非负正实数的函数,测量态是如何纠缠的。 ∣ ψ ⟩ \vert\psi\rangle ∣ψ⟩是纠缠的当且仅当并发是大于等于0的数。现在考虑将任意一个酉操作作用在 ∣ ψ ⟩ \vert\psi\rangle ∣ψ⟩上,即: C ( ( U 1 ⊗ U 2 ) ∣ ψ ⟩ ) = C ( ψ ) ∣ d e t ( U 1 ) d e t ( U 2 ) ∣ . C((U_1\otimes U_2)\vert\psi\rangle)=C(\psi)\vert det(U_1) det(U_2)\vert. C((U1⊗U2)∣ψ⟩)=C(ψ)∣det(U1)det(U2)∣.因为 ∣ d e t ( U 1 ) ∣ = ∣ d e t ( U 2 ) ∣ = 1 \vert det(U_1)\vert=\vert det(U_2)\vert=1 ∣det(U1)∣=∣det(U2)∣=1,这就得到,并发在局部酉变换下是不变量。因为局部酉变换并不能改变量子态的纠缠数量。更复杂的不变量可以被如下张量网络表示:

如果 ∣ ψ ⟩ \vert\psi\rangle ∣ψ⟩是一个 3 − q u b i t 3-qubit 3−qubit的量子态, τ ( ψ ) = 2 ∣ τ ′ ( ψ ) ∣ \tau(\psi)=2\vert\tau^\prime(\psi)\vert τ(ψ)=2∣τ′(ψ)∣表示纠缠不变性。
不使用 ϵ \epsilon ϵ张量,也可以构造不变性,例如 K e m p e i n v a r i a n t Kempe~invariant Kempe invariant是 3 − q u b i t 3-qubit 3−qubit纠缠不变性: K ( ψ ) = ψ i j k ψ ˉ i l m ψ n l o ψ ˉ p j o ψ p q m ψ ˉ n q k . K(\psi)=\psi^{ijk}\bar\psi_{ilm}\psi^{nlo}\bar\psi_{pjo}\psi^{pqm}\bar\psi_{nqk}. K(ψ)=ψijkψˉilmψnloψˉpjoψpqmψˉnqk.
画出等价的张量网络。
例3(量子线路)
量子线路是一种特殊的张量网络子类,它被广泛的应用在量子信息领域。在量子线路图中每一条水平线表示一个与量子子系统(典型的单比特)关联的希尔伯特空间,张量附着在线路上,表示作用在这些子系统上的酉矩阵,被称作量子门,另外的记号用来表示测量。考虑一个简单的量子线路,它可以生成贝尔态。由两个张量组成,一个 H a d a m a r d g a t e ( H ) Hadamard ~gate(H) Hadamard gate(H)和一个 c o n t r o l l e d N O T g a t e ( C N O T ) controlled ~NOT ~gate(CNOT) controlled NOT gate(CNOT):

CNOT和Hadamard 门被定义为: C N O T = ∑ a b ∣ a , a ⊕ b ⟩ ⟨ a , b ∣ CNOT=\sum_{ab}\vert a,a\oplus b\rangle\langle a,b\vert CNOT=ab∑∣a,a⊕b⟩⟨a,b∣ H = 1 2 ∑ a b ( − 1 ) a b ∣ a ⟩ ⟨ b ∣ H=\frac{1}{\sqrt 2}\sum_{ab}(-1)^{ab}\vert a\rangle\langle b\vert H=21ab∑(−1)ab∣a⟩⟨b∣
例4(COPY和XOR张量)
CNOT门可以看作2个3阶张量的缩并:

上边的张量称作COPY张量,当所有的指标值相等时,它等于1,否则等于0.
因此,COPY门作用可以复制二进制输入0和1:

下边的张量称作奇偶张量或者XOR张量,当它的指标包含偶数个1时它等于1,否则等于0.
XOR张量和COPY张量通过Hadamard门想联系:

因此在另外一组基下,XOR张量可以看作复制操作: 1 2 X O R ∣ + ⟩ = ∣ + ⟩ ∣ + ⟩ , \frac{1}{\sqrt 2}XOR\vert +\rangle=\vert +\rangle\vert +\rangle, 21XOR∣+⟩=∣+⟩∣+⟩, 1 2 X O R ∣ − ⟩ = ∣ − ⟩ ∣ − ⟩ \frac{1}{\sqrt 2}XOR\vert -\rangle=\vert -\rangle\vert -\rangle 21XOR∣−⟩=∣−⟩∣−⟩其中 ∣ + ⟩ : = H ∣ 0 ⟩ \vert +\rangle:=H\vert 0\rangle ∣+⟩:=H∣0⟩和 ∣ − ⟩ : = H ∣ 1 ⟩ \vert -\rangle:=H\vert 1\rangle ∣−⟩:=H∣1⟩按照组成部分来说: C O P Y k i j = ( 1 − i ) ( 1 − j ) ( 1 − k ) + i j k , COPY^{ij}_{~~~~k}=(1-i)(1-j)(1-k)+ijk, COPY kij=(1−i)(1−j)(1−k)+ijk, X O R s q r = 1 − ( q + r + s ) + 2 ( q r + q s + s r ) − 4 q r s XOR^{qr}_{~~~~s}=1-(q+r+s)+2(qr+qs+sr)-4qrs XOR sqr=1−(q+r+s)+2(qr+qs+sr)−4qrs
因此CNOT门做张量缩并后得到: ∑ m C O P Y i q m X O R m j r = C N O T i j q r . \sum_{m}COPY^{qm}_{~~~~~~~i}XOR^r_{~~~mj}=CNOT^{qr}_{~~~~~~ij}. m∑COPY iqmXOR mjr=CNOT ijqr.
3、弯曲交叉线
1、帽型和杯型
线是用来表示张量指标对的缩并,某种线结构可作为独立的张量,以下介绍3中线张量:
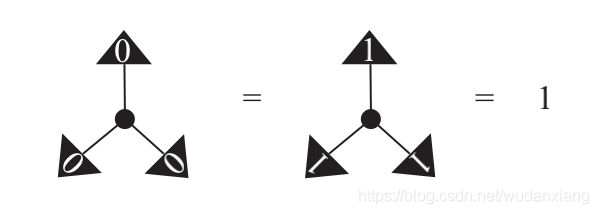
恒等张量(a)是用来做指标缩并,通过连接对应的边。杯型张量(b)和帽型张量©是通过弯曲对应的张量的边来上移和下移张量指标。在计算基下展开: I = ∑ i j δ j i ∣ i ⟩ ⟨ j ∣ = ∑ k ∣ k ⟩ ⟨ k ∣ I=\sum_{ij}\delta^i_{~~j}\vert i\rangle \langle j\vert=\sum_{k}\vert k\rangle\langle k\vert I=ij∑δ ji∣i⟩⟨j∣=k∑∣k⟩⟨k∣ ∣ ∪ ⟩ = ∑ i j δ i j ∣ i j ⟩ = ∑ k ∣ k k ⟩ \vert \cup\rangle=\sum_{ij}\delta ^{ij}\vert ij\rangle=\sum_{k}\vert kk\rangle ∣∪⟩=ij∑δij∣ij⟩=k∑∣kk⟩ ⟨ ∩ ∣ = ∑ i j δ i j ⟨ i j ∣ = ∑ k ⟨ k k ∣ \langle \cap\vert=\sum_{ij}\delta_{ij}\langle ij\vert=\sum_{k}\langle kk\vert ⟨∩∣=ij∑δij⟨ij∣=k∑⟨kk∣
2、蛇形方程
如果向上弯曲然后向下弯曲一个指标等同于什么操作都没有做,这就是蛇形方程或者之字形方程。

在抽象索引表示法中,蛇形方程简洁地表示为: δ i j δ j k = δ k i = δ k j δ j i \delta^{ij}\delta_{jk}=\delta^{i}_{~k}=\delta_{kj}\delta^{ji} δijδjk=δ ki=δkjδji
3、SWAP门
交叉两条线是交换两个向量空间的顺序,对应着量子计算中的SWAP门。如果两条线路表示地是同一个向量空间,可以理解为交换两个子系统地状态,如图a。
方程b说明SWAP操作是自逆的。表示为: s w a p k l i j = δ k j δ l i swap^{ij}_{~~kl}= \delta^j_{~k}\delta^i_{~l} swap klij=δ kjδ li,或者在一组计算基下展开为:SWAP= ∑ i j ∣ i j ⟩ ⟨ j i ∣ \sum_{ij}\vert ij\rangle\langle ji\vert ∑ij∣ij⟩⟨ji∣.

用3个CNOT门可以实现SWAP操作:

SWAP是一种简单的非平凡的置换张量,更复杂的置换张量可以由 δ j i \delta^i_{~j} δ ji张量构建。
4、转置
给定 A j i A^i_{~j} A ji,可以使用杯型和帽型来改变指标的位置。这相当于在计算基上相应的线性映射的转置。

5、迹
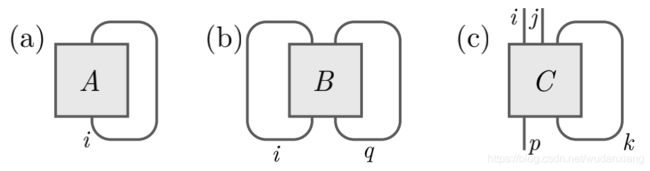
在张量网络标记中,迹是通过合理地连接一个张量中输出线和对应的输入线来完成的。图a表示迹 A i i A^i_{~i} A ii,图b表示迹 B i q i q B^{iq}_{~~~iq} B iqiq.偏迹是仅仅缩并一些输出和对应的输入,图c表示张量 C p k i j k C^{ijk}_{~~~~~~pk} C pkijk。
例5(偏迹)
左边的图表示 ∣ ψ ⟩ ⟨ ψ ∣ \vert\psi\rangle\langle\psi\vert ∣ψ⟩⟨ψ∣对第二系统的偏迹。
可以把弯曲的线解释为杯型和帽型,把交叉线解释为SWAP。
 例6(贝尔态的偏迹)
例6(贝尔态的偏迹)
如果选择 ∣ ψ ⟩ = ∣ ∪ ⟩ \vert \psi\rangle=\vert \cup\rangle ∣ψ⟩=∣∪⟩,即: ∣ ψ ⟩ \vert \psi\rangle ∣ψ⟩是一个非归一化的贝尔态,得到:

例7( ϵ \epsilon ϵ和SWAP之间的关系)
对于2阶张量,定义它的反对称化为: T [ i j ] = 1 2 ( T i j − T j i ) T^{[ij]}=\frac{1}{2}(T^{ij}-T^{ji}) T[ij]=21(Tij−Tji)只有指标的维数相同的指标才可以定义反对称化。完全反对称 ϵ \epsilon ϵ张量与SWAP门之间的关系如下:

或者表达为: ϵ k l ϵ i j = δ i k δ j l − δ j k δ i l \epsilon^{kl}\epsilon_{ij}=\delta^k_{~~i}\delta^l_{~~j}-\delta^k_{~~j}\delta^l_{~~i} ϵklϵij=δ ikδ jl−δ jkδ il对任意的张量, T i j T^{ij} Tij(每个指标都是2维的),则 T [ i j ] = 1 2 ϵ k l ϵ i j T i j . T^{[ij]}=\frac{1}{2}\epsilon^{kl}\epsilon_{ij}T^{ij}. T[ij]=21ϵklϵijTij.
例8(杯型和 ϵ \epsilon ϵ 态的量子线路)
例9(map-态的对偶性)
6、 † \dagger † 和复共轭
( p , q ) (p,q) (p,q)阶张量 T T T的自伴是 T † T^{\dagger} T†,是一个 ( q , p ) (q,p) (q,p)阶张量。定义如下: ⟨ x , T y ⟩ = ⟨ T † x , y ⟩ \langle x,Ty\rangle=\langle T^{\dagger}x,y\rangle ⟨x,Ty⟩=⟨T†x,y⟩,对任意的 x , y x,y x,y。图示自伴的张量网络是将原本的张量网络的输入和输出线换位置,则张量的序就相反了。 d a g g e r dagger dagger操作把希尔比特空间的向量一对一地映射到对偶向量空间中,反之亦然,利用 R i e s z r e p r e s e n t a t i o n t h e o r e m Riesz~ representation~ theorem Riesz representation theorem。即: ∣ a ⟩ † = ⟨ a ∣ \vert a\rangle^\dagger=\langle a\vert ∣a⟩†=⟨a∣。 d a g g e r dagger dagger是反线性的(或共轭线性)运算, ( c T + d U ) † = c ˉ T † + d ˉ U † (cT+dU)^\dagger=\bar cT^\dagger+\bar dU^\dagger (cT+dU)†=cˉT†+dˉU†,这也意味着它不能被线性杯型和帽型单独表示,不像转置。但是可以在同一组基下由转置和复共轭表示。如下图所示:
对向量和对偶向量,弯曲向量的一条线,产生对偶向量的复共轭,反之亦然。
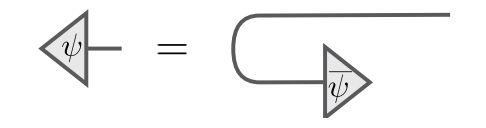
7、指标位置
使用杯型和帽型向前和向后弯曲张量线;使用SWAP交换张量线的顺序;
给定一个张量 T j i T^i_{~~j} T ji,使用杯型和帽型可以重排指标的高低和位置,得到: T j i , T i j , T i j , T i j , T i j , T j i , T j i , T j i T^i_{~~j},T^{ij},T_{ij},T_{i}^{~~j},T^j_{~~i},T^{ji},T_{ji},T_{j}^{~~i} T ji,Tij,Tij,Ti j,T ij,Tji,Tji,Tj i共8中可能的形状。如果指标数超过2个还可以加上SWAP操作重拍顺序,对n个指标的张量,共有 n ! ⋅ 2 n n!\cdot 2^n n!⋅2n种不同的方式,但是有多余的计算,在上例中, T j i = T j i , T i j = T i j T^i_{~~j}=T_j^{~~i},T_i^{~~j}=T^j_{~~i} T ji=Tj i,Ti j=T ij,如图所示:

因此,张量 T j i T^i_{~~j} T ji只有6种不同的形状:

4、图解奇异值分解
例10(纠缠拓扑)
例11(并发-part II)
例12(纯化)
5、矩阵乘积态
例13(MPS的近似错误)
例14(对GHZ态的MPS分解)
例15(W态的MPS分解)
例16(AKLT模型)
定义17( R e ˊ n y i R\acute{e} nyi Reˊnyi和von Neumann 熵)
6、用张量缩并来计数
1、计数布尔公式解
定义18(布尔张量类)
定理19(计数SAT解)
例子20(从Tofolli到AND)
例子21(从AND到Hadamard)
例子22(De Morgan定律)
2、计数图像着色
定理23(平面图3-着色)
例子24(量子计算中的 ϵ a b c \epsilon_{abc} ϵabc的物理实现)
7、张量网络的前沿
附录A:张量和张量积
- 张量积 ⊗ \otimes ⊗的定义: V V V、 W W W是数域 K K K上的两个有限维向量空间,则 V ⊗ W V\otimes W V⊗W也是 K K K上的一个向量空间,如果 { e j } j \left\{e_{j}\right\}_j {ej}j和 { f k } k \left\{f_{k}\right\}_k {fk}k分别是 V V V、 W W W的基,则 { e j ⊗ f k } j k \left\{e_{j}\otimes f_{k}\right\}_{jk} {ej⊗fk}jk是 V ⊗ W V\otimes W V⊗W的基。因此 d i m ( V ⊗ W ) = d i m V d i m W dim(V\otimes W)= dim V dim W dim(V⊗W)=dimVdimW。两个独立的向量 v ∈ V v\in V v∈V和 w ∈ W w\in W w∈W的张量积为: v ⊗ w v\otimes w v⊗w。张量积是一个双线性映射: V × W → V ⊗ W V \times W \to V\otimes W V×W→V⊗W,即对输入的变量都是线性的。对有限维空间可以得到两个向量的张量积的标准基下的坐标通过各自向量的标准基下的坐标的克罗内克积得到: ( v ⊗ w ) j k = v j w k (v\otimes w)^{jk}=v^jw^k (v⊗w)jk=vjwk.由于双线性映射 ⊗ \otimes ⊗把很多不同的向量对 ( v , w ) (v,w) (v,w)映为同一个积向量: v ⊗ ( s w ) = ( s v ) ⊗ w = s ( v ⊗ w ) v\otimes(sw)=(sv)\otimes w=s(v\otimes w) v⊗(sw)=(sv)⊗w=s(v⊗w),其中 s ∈ K s\in K s∈K。张量积空间中的内积: ⟨ v 1 ⊗ w 1 , v 2 ⊗ w 2 ⟩ V ⊗ W = ⟨ v 1 , v 2 ⟩ V ⟨ w 1 , w 2 ⟩ W {\langle v_1\otimes w_1,v_2\otimes w_2\rangle}_{V\otimes W}={\langle v_1,v_2\rangle}_V{\langle w_1,w_2\rangle}_W ⟨v1⊗w1,v2⊗w2⟩V⊗W=⟨v1,v2⟩V⟨w1,w2⟩W。
- 张量 T T T的定义:张量 T T T是同一个数域 K K K上,有限个线性空间的张量积中的元素。 V ∗ V^* V∗是 V V V的对偶空间,是 V → K V\to K V→K的线性映射组成的空间,也是一个线性空间。
- ( p , q ) (p,q) (p,q)阶张量的定义: T ∈ W 1 ⊗ W 2 ⊗ ⋯ ⊗ W p ⊗ V 1 ∗ ⊗ V 2 ∗ ⊗ ⋯ ⊗ V q ∗ T\in W_1\otimes W_2 \otimes \dots\otimes W_p\otimes V_{1}^* \otimes V_{2}^* \otimes \dots\otimes V_{q}^* T∈W1⊗W2⊗⋯⊗Wp⊗V1∗⊗V2∗⊗⋯⊗Vq∗
{ e ( i ) k } k \left\{{e^{(i)}}_k\right\}_k {e(i)k}k是每一个向量空间 W i W_i Wi的基, { η ( i ) k } k \left\{{\eta^{(i)k}}\right\}_k {η(i)k}k是每一个对偶空间 V i ∗ V_{i}^* Vi∗的基。 T T T展开成这些基向量的张量积:
T = T j 1 … j q i 1 … i p e i 1 ( 1 ) ⊗ ⋯ ⊗ e i p ( p ) ⊗ η ( 1 ) j 1 ⊗ ⋯ ⊗ η ( q ) j q T= T_{~~~~~~~~~~~j_1\dots j_q}^{i_1\dots i_p}e_{~~~~~i_1}^{(1)}\otimes \dots\otimes e_{~~~~~i_p}^{(p)}\otimes \eta^{(1)j_1} \otimes \dots\otimes \eta^{(q)j_q} T=T j1…jqi1…ipe i1(1)⊗⋯⊗e ip(p)⊗η(1)j1⊗⋯⊗η(q)jq其中 T j 1 … j q i 1 … i p T_{~~~~~~~~~~~j_1\dots j_q}^{i_1\dots i_p} T j1…jqi1…ip是 T T T在基下展开的系数。此处采用 E i n s t e i s u m m a t i o n c o n v e n t i o n Einstei~summation~convention Einstei summation convention,一般基向量有下指标(协变指标),对偶基向量有上指标(抗变指标)。 - 简单张量:如果一个张量可以写成基础向量空间中元素的张量积: T = v ( 1 ) ⊗ ⋯ ⊗ v ( q ) ⊗ φ ( 1 ) ⊗ ⋯ ⊗ φ ( p ) T=v^{(1)} \otimes \dots \otimes v^{(q) }\otimes \varphi^{(1)} \otimes \dots \otimes \varphi^{(p) } T=v(1)⊗⋯⊗v(q)⊗φ(1)⊗⋯⊗φ(p),则称这个张量是简单张量,这也是可分张量的一个特性。即可分张量是简单张量。任何一个张量是简单张量的线性组合。
- 缩并:对任意一个向量空间 W W W,存在唯一的双线性映射 W ⊗ W ∗ → K , w ⊗ ϕ ↦ ϕ ( w ) W\otimes W^*\to K,~w\otimes \phi\mapsto \phi(w) W⊗W∗→K, w⊗ϕ↦ϕ(w),我们把它称为一个自然配对,其中对偶向量把主向量映射为一个数。可以在一个张量中应用这种银蛇到任意的对上来匹配主空间和对偶空间。我们把它称为对应的上下指标的缩并。例如,如果 W 1 = V 1 W_1=V_1 W1=V1,在 T T T上可以缩并对应的指标: C 1 , 1 ( T ) = T j 1 … j q i 1 … i p η ( 1 ) j 1 ( e i 1 ( 1 ) ) ⊗ ⋯ ⊗ e i p ( p ) ⊗ η ( 2 ) j 2 ⊗ ⋯ ⊗ η ( q ) j q = T k j 2 … j q k i 2 … i p e i 2 ( 2 ) ⊗ ⋯ ⊗ e i p ( p ) ⊗ η ( 2 ) j 2 ⊗ ⋯ ⊗ η ( q ) j q \begin{array}{l}C_{1,1}(T) \\= T_{~~~~~~~~~~~j_1\dots j_q}^{i_1\dots i_p}\eta^{(1)j_1}(e_{~~~~~i_1}^{(1)})\otimes \dots\otimes e_{~~~~~i_p}^{(p)}\otimes \eta^{(2)j_2} \otimes \dots\otimes \eta^{(q)j_q}\\=T_{~~~~~~~~~~~~~~k~j_2\dots j_q}^{k~i_2\dots i_p}e_{~~~~~i_2}^{(2)}\otimes \dots\otimes e_{~~~~~i_p}^{(p)}\otimes \eta^{(2)j_2} \otimes \dots\otimes \eta^{(q)j_q}\\\end{array} C1,1(T)=T j1…jqi1…ipη(1)j1(e i1(1))⊗⋯⊗e ip(p)⊗η(2)j2⊗⋯⊗η(q)jq=T k j2…jqk i2…ipe i2(2)⊗⋯⊗e ip(p)⊗η(2)j2⊗⋯⊗η(q)jq
因为对偶基的特性是: η ( 1 ) j 1 ( e i 1 ( 1 ) ) = δ i 1 j 1 \eta^{(1)j_1}(e_{~~~~~i_1}^{(1)})=\delta_{~~~i_1}^{j_1} η(1)j1(e i1(1))=δ i1j1,因此缩并使得指标的影响消除,使得张量的阶数减少 ( 1 , 1 ) (1,1) (1,1)阶。
- ( 1 , 0 ) (1,0) (1,0)阶张量是一个向量, ( 0 , 1 ) (0,1) (0,1)阶的张量是一个对偶向量, ( 0 , 0 ) (0,0) (0,0)阶的张量是一个数。 ( p , q ) (p, q) (p,q)阶张量是向量到向量的多线性映射: T ′ : V 1 ⊗ ⋯ ⊗ V q → W 1 ⊗ ⋯ ⊗ W p T^\prime:V_1\otimes\dots\otimes V_q\to W_1\otimes \dots\otimes W_p T′:V1⊗⋯⊗Vq→W1⊗⋯⊗Wp T ′ ( v ( 1 ) ⊗ ⋯ ⊗ v ( q ) ) = T j 1 … j q i 1 … i p e i 1 ( 1 ) ⊗ ⋯ ⊗ e i p ( p ) × η ( 1 ) j 1 ( v ( 1 ) ) × ⋯ × η ( q ) j q ( v ( q ) ) T^\prime(v^{(1)}\otimes\dots\otimes v^{(q)})=T_{~~~~~~~~~~~j_1\dots j_q}^{i_1\dots i_p}e_{~~~~~i_1}^{(1)}\otimes \dots\otimes e_{~~~~~i_p}^{(p)}\times\eta^{(1)j_1} (v^{(1)})\times \dots\times \eta^{(q)j_q}(v^{(q)}) T′(v(1)⊗⋯⊗v(q))=T j1…jqi1…ipe i1(1)⊗⋯⊗e ip(p)×η(1)j1(v(1))×⋯×η(q)jq(v(q))将张量乘积 T T T和向量一起映射,则缩并对应的指标,但是这不是唯一的解释,我们也可以看做映射对偶向量为对偶向量: T ′ ′ : W 1 ∗ ⊗ ⋯ ⊗ W q ∗ → V 1 ∗ ⊗ ⋯ ⊗ V p ∗ , T^{\prime\prime}:W_1^*\otimes\dots\otimes W_q^*\to V_1^*\otimes \dots\otimes V_p^*, T′′:W1∗⊗⋯⊗Wq∗→V1∗⊗⋯⊗Vp∗, T ′ ′ ( φ ( 1 ) ⊗ ⋯ ⊗ φ ( q ) ) = T j 1 … j q i 1 … i p φ ( 1 ) ( e i 1 ( 1 ) ) × ⋯ × φ ( p ) ( e i p ( p ) ) × η ( 1 ) j 1 ⊗ ⋯ ⊗ η ( q ) j q . T^{\prime\prime}(\varphi^{(1)}\otimes\dots\otimes \varphi^{(q)})=T_{~~~~~~~~~~~j_1\dots j_q}^{i_1\dots i_p}\varphi^{(1)}(e_{~~~~~i_1}^{(1)})\times\dots\times \varphi^{(p)}(e_{~~~~~i_p}^{(p)})\times\eta^{(1)j_1}\otimes\dots\otimes \eta^{(q)j_q}. T′′(φ(1)⊗⋯⊗φ(q))=T j1…jqi1…ipφ(1)(e i1(1))×⋯×φ(p)(e ip(p))×η(1)j1⊗⋯⊗η(q)jq.本质上,我们可以利用对偶把任意的向量空间移动到箭头的另一边: W ⊗ V ∗ ≅ K → W ⊗ V ∗ ≅ V → W ≅ V ⊗ W ∗ → K ≅ W ∗ → V ∗ , W\otimes V^*\cong K\to W\otimes V^*\cong V\to W\cong V\otimes W^* \to K\cong W^* \to V^*, W⊗V∗≅K→W⊗V∗≅V→W≅V⊗W∗→K≅W∗→V∗,其中所有的箭头表示线性映射,所有输入的向量被对应的对偶基向量映射为数,因为输入的对偶向量映射对应的向量为一个数。
- 如果在展开张量 T T T的时候在同一组基下将输入向量 v ( k ) v^{(k)} v(k)也展开,就会得到带有下列展开系数的方程: T ′ ( v ( 1 ) ⊗ ⋯ ⊗ v ( q ) ) i 1 … i p = T j 1 … j q i 1 … i p v ( 1 ) j 1 … v ( q ) j q . T^{\prime}(v^{(1)}\otimes\dots\otimes v^{(q)})^{i_1\dots i_p}=T_{~~~~~~~~~~~~j_1\dots j_q}^{i_1\dots i_p}v^{(1)j_1}\dots v^{(q)j_q}. T′(v(1)⊗⋯⊗v(q))i1…ip=T j1…jqi1…ipv(1)j1…v(q)jq.
这使得我们开始使用张量的 a b s t r a c t i n d e x n o t a t i o n abstract ~index~ notation abstract index notation,在这种表示法中指标不再表示在一组特殊的基下张量的组成,而是张量的阶。张量基由张量符号写在一起来代替,在每一项里,任何重复的指标符号必须出现在上标和下标位置,并且表示对这些指标的缩并。因此, x a x^a xa表示一个向量(有一个协变指标), ω a \omega_a ωa是一个对偶向量(有一个抗变指标), T c a b T_{~~~~c}^{ab} T cab是一个 ( 2 , 1 ) (2,1) (2,1)阶张量,有两个协变指标和一个抗变指标。 S c d e a b x c y d P a e S^{ab}_{~~~~cde}x^cy^dP^e_{~~a} S cdeabxcydP ae表示一个 ( 2 , 3 ) (2,3) (2,3)阶张量 S S S,一个 ( 1 , 1 ) (1,1) (1,1)阶张量 P P P,和两个向量 x x x和 y y y的缩并,结果得到一个 ( 1 , 0 ) (1,0) (1,0)阶有一个不缩并的指标 b b b的张量。 - 在很多应用中,例如在微分几何中,与一个张量相关联的向量空间经常是 V V V与自身或者与其对偶空间 V ∗ V^* V∗的张量积,这就意味着任意上下指标对是可以缩并的,==并且导致张量的组成部分在基变换下以一种特殊的方式变换。==这种特殊类型的张量称为向量空间 V V V上的 ( p , q ) (p,q) (p,q)阶张量。本文中我们采用更一般的定义,我们假设 { V k } k \left\{V_k\right\}_k {Vk}k和 { W k } k \left\{W_k\right\}_k {Wk}k是两个不同的向量空间。