自动文摘(Automatic document summarization)方法综述(四)——基于神经网络的(neural summarization)方法
前三篇博客(一)、(二)、(三)总结了抽取式自动文摘的一些经典方法,传统抽取式自动文摘方法将文档简单地看作是一组文本单元(短语、句子等)的集合,忽略了文档所表达的全局语义,难免“断章取义”。随着算力的提升,深度学习在很多应用中非常的火热也取得了state-of-the-art的性能,因此,将神经网络模型引入自动文摘任务是理所当然的,将文档用神经网络模型进行表示被称为神经文档模型(neural document model),neural document model采用低维连续向量表示文档语义信息非常有效。这篇博客将介绍几种经典的neural document model。
1、DocRebuild
该模型是北京大学发表在COLING2016上的一篇文章中提出来的,通过一个neural document model将文档用摘要句进行重构,同时保证选取的摘要句最小化重构误差(construction error)。
An Unsupervised Multi-Document Summarization Framework Based on Neural Document Model
在模型中,文档集中每一篇文档用neural document model表示,然后取平均作为文档集内容的表示。文档集内容重构包括:1)选取摘要句,并将摘要句用文档模型进行表示。2)计算重构误差。因此,多文档摘要任务转化成最优化问题,目标函数是最小化重构误差,选择的摘要句需满足这个误差最小。下图展示了DocRebuild的框架:

① neural document model是该框架的基础,直接决定了模型的性能。文中作者分别采用了两种非监督文档模型:Bag-of-Words(BoW)和Paragraph Vector(PV)。在BoW中,作者简单采用词袋模型,没有考虑单词之间的顺序和关系,每一个单词被表示成相应的word embedding,文档被表示成成单词向量的加权平均。PV模型是另一种文档模型,考虑了单词顺序。具体的可以参考word2vec和Paragraph Vector的论文。
② 在定义目标函数之前,需要定义如下符号: D = { d 1 , d 2 , … , d n } D=\{d_1,d_2,\dots,d_n\} D={d1,d2,…,dn}表示多文档集, D D D中的文档都被处理成句子集合。 C = { s 1 , s 2 , … , s m } C=\{s_1,s_2,\dots,s_m\} C={s1,s2,…,sm}表示候选句子集。 S = { s 1 ∗ , s 2 ∗ , … , s l ∗ } S=\{s_1^*,s_2^*,\dots,s_l^*\} S={s1∗,s2∗,…,sl∗}表示摘要句子集,满足 S ⊂ C S\subset C S⊂C, ∣ S ∣ ≪ ∣ C ∣ |S|\ll |C| ∣S∣≪∣C∣。 θ \theta θ表示摘要长度限制。重构误差通过摘要向量和文档向量之间的距离衡量:
min S ⊂ C ∣ ∣ D M ( S ∗ ) − 1 n ∑ i = 1 n D M ( d i ) ∣ ∣ 2 2 s . t . l e n ( S ∗ ) ≤ θ \begin{aligned} &\min_{S\subset C}\enspace ||DM(S^*)-\frac{1}{n}\sum_{i=1}^nDM(d_i)||_2^2\\ &s.t.\quad\: len(S^*)\leq\theta \end{aligned} S⊂Cmin∣∣DM(S∗)−n1i=1∑nDM(di)∣∣22s.t.len(S∗)≤θ
其中, D M DM DM表示文档模型处理过程, S ∗ S^* S∗表示 S S S相应的摘要序列, l e n ( S ∗ ) len(S^*) len(S∗)表示摘要序列的长度。
③ 选择最优摘要集是一个NP-hard问题,在文中,作者提出了两种策略用于句子选择的效率和有效性。
句子过滤 \quad 这个策略主要用于缩减搜索空间,通过过滤掉无关的噪声句,保留最有价值的句子作为候选句(candidate set),同时删除噪声句也有助于文档表示。具体地,作者首先对句子进行排序然后选取top-ranked句子作为候选。
BeamSearch Algorithm \quad 为了提高搜索效率,作者提出了BeamSearch算法,算法的伪代码如下:

2、NN-SE
该模型由Cheng和Lapata在ACL 2016上提出:Neural Summarization by Extracting Sentences and Words。该论文中既提出了句子基于句子抽取的模型NN-SE,也提出了基于单词抽取的模型NN-WE,本博客中只讨论NN-SE。在判断一个句子是否属于摘要句时,传统方法依靠的是人工构建的特征。这篇文章中,作者提出了一个基于神经网络和连续句子特征的数据驱动方法。基于神经网络的方法的核心是一个encoder-decoder结构,encoder读取源序列并编码成一个连续向量,然后decoder从中生成目标序列。在decoder阶段,注意力机制(attention mechanism)通常被用来定位焦点区域(locate the focus)。
问题描述 \quad 对一篇文档 D = { s 1 , s 2 , … , s m } D=\{s_1,s_2,\dots,s_m\} D={s1,s2,…,sm},基于句子抽取的自动文摘希望选取一个包含 j j j个句子 ( j < m ) (j<m) (j<m)的子集形成摘要。我们可以对 D D D中每一个句子打分,然后预测一个标签 y L ∈ { 0 , 1 } y_L\in\{0,1\} yL∈{0,1}指示其是否属于摘要句。对于有监督学习,目标函数可以设定为最大化所有句子标签 y L = ( y L 1 , y L 2 , … , y L m ) \bold{y_L}=(y_L^1,y_L^2,\dots,y_L^m) yL=(yL1,yL2,…,yLm)的似然:
log p ( y L ∣ D ; θ ) = ∑ i = 1 m log p ( y L i ∣ D ; θ ) \log p(\bold{y_L}|D;\theta)=\sum_{i=1}^m\log p(y_L^i|D;\theta) logp(yL∣D;θ)=i=1∑mlogp(yLi∣D;θ)
NN-SE的关键成分包括一个基于神经网络的层次文档读取器(document reader)和一个基于注意力的层次内容抽取器(content extractor)。层次结构天然符合文档由单词、句子、段落甚至更大的单元合成。
Document Reader
作者首先采用一个单层卷积神经网络(CNN)和max-pooling操作获得句子级的向量表示。之后,采用一个标准的循环神经网络(RNN)建立文档向量表示。Convolutional Sentence Encoder \quad 采用CNN进行句子表示主要有两个原因:①单隐层神经网络能够高效训练(没有长期依赖);②CNN已经被成功地应用到句子级的分类任务中。假设 d d d表示word embedding的维度, s = ( w 1 , … , w n ) s=(w_1,\dots,w_n) s=(w1,…,wn)表示文档中的句子,因此一个句子可以表示成一个稠密矩阵 W ∈ R n × d W\in \mathbb{R}^{n\times d} W∈Rn×d。接着就可以采用一个宽度为 c c c的卷积核 K ∈ R c × d K\in \mathbb{R}^{c\times d} K∈Rc×d
f j i = tanh ( W j : j + c − 1 ⊗ K + b ) f_j^i=\tanh(W_{j:j+c-1}\otimes K+b) fji=tanh(Wj:j+c−1⊗K+b)
其中 ⊗ \otimes ⊗表示矩阵的哈达马积(乘积)并求和所有元素。 f j i f_j^i fji表示第 i i i个特征图的第 j j j个元素, b b b是偏置。采用最大池化操作获得一个单一特征(第 i i i个特征):
s i , K = max j f j i s_{i,K}=\max_jf_j^i si,K=jmaxfji
实践中,在每个卷积核上,作者采用多个特征图计算了 d d d个特征,作为句子向量。同时,作者也采用了多个不同宽度的卷积核得到多个句子向量。最后,这些句子向量累加作为最终的句子表示。如下图sentence encoder阶段所示
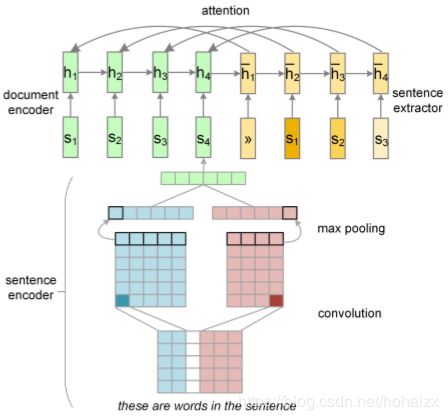
Recurrent Document Encoder \quad 在文档级别,作者采用了一个循环神经网络组合句子向量序列为一个文档向量。循环神经网络作者采用的是LSTM,假设一篇文档表示为 d = ( s 1 , … , s m ) d=(s_1,\dots,s_m) d=(s1,…,sm),在 t t t时刻隐藏层 h t h_t ht计算如下:
[ i t f t o t c ^ t ] = [ σ σ σ tanh ] W ⋅ [ h t − 1 s t ] \begin{bmatrix} i_t \\ f_t \\ o_t \\ \hat{c}_t \end{bmatrix}= \begin{bmatrix} \sigma \\ \sigma \\ \sigma \\ \tanh \end{bmatrix}W\cdot \begin{bmatrix} h_{t-1} \\ s_t \end{bmatrix} ⎣⎢⎢⎡itftotc^t⎦⎥⎥⎤=⎣⎢⎢⎡σσσtanh⎦⎥⎥⎤W⋅[ht−1st]
c t = f t ⊙ c t − 1 + i t ⊙ c ^ t c_t=f_t\odot c_{t-1}+i_t\odot\hat{c}_t ct=ft⊙ct−1+it⊙c^t
h t = o t ⊙ tanh ( c t ) h_t=o_t\odot\tanh(c_t) ht=ot⊙tanh(ct)
Sentence Extractor
在标准的sequence-to-sequence模型中,注意力机制作为生成下一个输出的一个中间环节,用来决定哪一块输入区域需要更加关注。相反地,本文中的句子抽取器(sentence extractor)在读入句子之后直接抽取显著的句子,抽取器是另一个循环神经网络,用来对句子进行标注,抽取器不仅考虑了每个句子的相关性,同时也考虑句子之间的冗余性。document reader和sentence extractor的完整结构如下图所示

在决定下一个标注时,同时考虑文档编码和之前句子的标签。假设encoder的隐藏层状态为 ( h 1 , … , h m ) (h_1,\dots,h_m) (h1,…,hm),抽取器的隐藏层状态为 ( h ˉ 1 , … , h ˉ m ) (\bar{h}_1,\dots,\bar{h}_m) (hˉ1,…,hˉm)
h ˉ t = L S T M ( p t − 1 s t − 1 , h ˉ t − 1 ) \bar{h}_t=LSTM(p_{t-1}s_{t-1},\bar{h}_{t-1}) hˉt=LSTM(pt−1st−1,hˉt−1)
p ( y L ( t ) = 1 ∣ D ) = σ ( M L P ( h ˉ t : h t ) ) p(y_L(t)=1|D)=\sigma(MLP(\bar{h}_t:h_t)) p(yL(t)=1∣D)=σ(MLP(hˉt:ht))
其中, M L P MLP MLP是一个多层神经网络,输入为 h ˉ t \bar{h}_t hˉt和 h t h_t ht的拼接, p t − 1 p_{t-1} pt−1表示extractor多大程度上认为前一个句子应该被抽取。在实践中,模型的训练和测试存在一个矛盾:在训练阶段,我们知道前一个句子的真实标签 p t − 1 p_{t-1} pt−1,然而在测试阶段, p t − 1 p_{t-1} pt−1是未知的,需要预测的。这个矛盾会造成预测误差的快速积累,特别是当错误发生在标注的早期。为了解决这个问题,作者采用了curriculum learning strategy:在训练的开始时,当 p t − 1 p_{t-1} pt−1没有正确预测,就将其改为正确的标签。
SummaRuNNer
SummaRuNNer由Nallapati等人在AAAI 2017上提出:SummaRuNNer: A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents。该模型既包含抽取式方法(SummaRuNNer)也包含生成式方法(SummaRuNNer-abs),本博客只讨论抽取式方法(SummaRuNNer)。作者将抽取式摘要看作是一个序列分类问题,采用GRU作为基本序列分类器的基本模块,GRU是一个包含两个门的循环神经网络:更新门 u u u和重置门 r r r,公式描述如下:
u j = σ ( W u x x j + W u h h j − 1 + b u ) r j = σ ( W r x x j + W r h h j − 1 + b r ) h j ′ = tanh ( W h x x j + W h h ( r j ⊙ h j − 1 ) + b h ) h j = ( 1 − u j ) ⊙ h j ′ + u j ⊙ h j − 1 \begin{aligned} u_j&=\sigma(W_{ux}x_j+W_{uh}h_{j-1}+b_u)\\ r_j&=\sigma(W_{rx}x_j+W_{rh}h_{j-1}+b_r)\\ h_j^{'}&=\tanh(W_{hx}x_j+W_{hh}(r_j\odot h_{j-1})+b_h)\\ h_j&=(1-u_j)\odot h_j^{'}+u_j\odot h_{j-1} \end{aligned} ujrjhj′hj=σ(Wuxxj+Wuhhj−1+bu)=σ(Wrxxj+Wrhhj−1+br)=tanh(Whxxj+Whh(rj⊙hj−1)+bh)=(1−uj)⊙hj′+uj⊙hj−1
其中, W W W和 b b b是GRU-RNN的参数, h j h_j hj是时刻 t t t的实值隐藏层向量, x j x_j xj是相应的输入向量, ⊙ \odot ⊙是哈达马积(乘积)。下图展示了模型框架图:
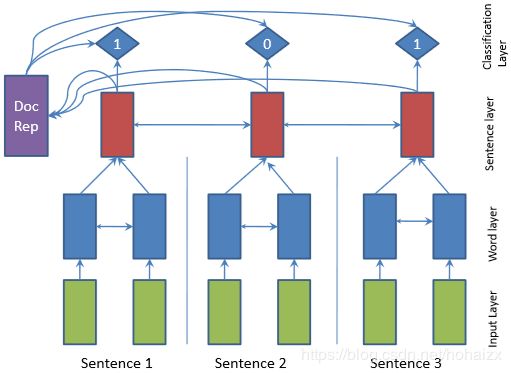
模型由一个两层的bi-directional GRU-RNN组成,第一层RNN操作在单词级,计算每个单词的隐藏层状态表示;第二层RNN操作在句子级,输入为word-level层的隐藏层向量经平均池化(average pooling)、首尾拼接而成的向量,得到的隐藏层向量作为文档中句子的表示。最后,sentence-level层隐藏层向量同样先经过平均池化、首尾拼接,然后再经过一个非线性变换,最终的结果作为整个文档的表示:
d = tanh ( W d 1 N d ∑ j = 1 N d [ h j f , h j b ] + b ) d=\tanh(W_d\frac{1}{N_d}\sum_{j=1}^{N_d}[h_j^f,h_j^b]+b) d=tanh(WdNd1j=1∑Nd[hjf,hjb]+b)
其中, h j f h_j^f hjf和 h j b h_j^b hjb分别代表第 j j j个句子的前向、后向隐藏层状态, N d N_d Nd表示文档句子数目, [ ] [] []表示向量拼接操作。在分类时,每个句子会按序输入分类器:
P ( y j = 1 ∣ h j , s j , d ) = σ ( W c h j # ( c o n t e n t ) + h j T W s d # ( s a l i e n c e ) − h j T W r tanh ( s j ) # ( n o v e l t y ) + W a p p j a # ( a b s . p o s . i m p . ) + W r p p j r # ( r e l . p o s . i m p . ) + b ) # ( b i a s t e r m ) \begin{aligned} P(y_j=1|h_j,s_j,d)=\sigma( W_ch_j&\quad\quad \#(\mathrm{content})\\ +h_j^TW_sd&\quad\quad \#(\mathrm{salience})\\ -h_j^TW_r\tanh(s_j)&\quad\quad \#(\mathrm{novelty})\\ +W_{ap}p_j^a&\quad\quad \#(\mathrm{abs.\enspace pos.\enspace imp.})\\ +W_{rp}p_j^r&\quad\quad \#(\mathrm{rel.\enspace pos.\enspace imp.})\\ +b)&\quad\quad \#(\mathrm{bias\enspace term})\\ \end{aligned} P(yj=1∣hj,sj,d)=σ(Wchj+hjTWsd−hjTWrtanh(sj)+Wappja+Wrppjr+b)#(content)#(salience)#(novelty)#(abs.pos.imp.)#(rel.pos.imp.)#(biasterm)
其中, y j ∈ { 0 , 1 } y_j\in \{0,1\} yj∈{0,1},指示第 j j j个句子是否属于文摘句, h j h_j hj是sentence-level隐藏层前向、后向( h j f , h j b h_j^f,h_j^b hjf,hjb)状态的拼接, s j s_j sj是摘要的动态表示,指示在第 j j j个句子时,目前摘要的表示,换句话说, s j s_j sj是到句子 j − 1 j-1 j−1为止,sentence-level隐藏层状态 h i h_i hi的加权求和,权重是他们相应属于摘要句的概率:
s j = ∑ i = 1 j − 1 h i P ( y i ∣ h i , s i , d ) s_j=\sum_{i=1}^{j-1}h_iP(y_i|h_i,s_i,d) sj=i=1∑j−1hiP(yi∣hi,si,d)
W a p p j a W_{ap}p_j^a Wappja和 W r p p j r W_{rp}p_j^r Wrppjr分别表示句子 j j j相对于文档的绝对重要度和相对重要度, p j a p_j^a pja和 p j r p_j^r pjr分别表示绝对位置、相对位置嵌入(position embedding),也是模型的参数。训练的目标是最小化负对数似然(negative log-likehood):
l ( W , b ) = − ∑ d = 1 N ∑ j = 1 N d ( y j d log P ( y j d = 1 ∣ h j d , s j d , d d ) ) + ( 1 − y j d ) log ( 1 − P ( y j d = 1 ∣ h j d , s j d , d d ) ) l(W,b)=-\sum_{d=1}^N\sum_{j=1}^{N_d}(y_j^d\log P(y_j^d=1|h_j^d,s_j^d,d_d))+(1-y_j^d)\log(1-P(y_j^d=1|h_j^d,s_j^d,d_d)) l(W,b)=−d=1∑Nj=1∑Nd(yjdlogP(yjd=1∣hjd,sjd,dd))+(1−yjd)log(1−P(yjd=1∣hjd,sjd,dd))
SWAP-NET
SWAP-NET模型由Jadhav和Rajan在ACL 2018上提出:Extractive Summarization with SWAP-NET: Sentences and Words from Alternating Pointer Networks。该模型创新性的使用一个两层的pointer network建模关键词和显著句之间的相关关系,SWAP-NET既能识别显著句也能识别关键词,然后将两者结合形成抽取式摘要。在我们的常识中,显著句中通常包含关键词,因此,SWAP-NET在选择句子时考虑了关键词的作用,这在以前的工作中是没有尝试的。作者通过一个two-level的encoder-decoder建模这种相互作用,一个用于words,一个用于sentences,同时,作者采用pointer-network建模注意力机制,用于从标注数据中学习重要的词和句子。decoder采用switch mechanism选择单词或句子,最终的摘要由选择的单词和句子综合而成。
输入文档 D D D可以写成句子的集合 s 1 , … , s N s_1,\dots,s_N s1,…,sN或者单词的集合 w 1 , … , w n w_1,\dots,w_n w1,…,wn。假设重要单词和句子序列是 V = v 1 , … , v m V=v_1,\dots,v_m V=v1,…,vm,其中 v j v_j vj既可以是句子也可以是单词。因此,训练目标可以写作( M M M是模型参数):
P ( V ∣ M , D ) = ∏ j p ( v j ∣ v 1 , … , v j − 1 , M , D ) P(V|M,D)=\prod_jp(v_j|v1,\dots,v_{j-1},M,D) P(V∣M,D)=j∏p(vj∣v1,…,vj−1,M,D)
SWAP-NET中,作者采用pointer-network表示注意力机制。对于一个包含 n n n个向量的序列 X = x 1 , … , x n X=x_1,\dots,x_n X=x1,…,xn以及其indices序列 R = r 1 , … , r m R=r_1,\dots,r_m R=r1,…,rm, r i ∈ [ 1 , n ] r_i\in [1,n] ri∈[1,n],pointer network是一个encoder-decoder结构,目标是最大化 p ( R ∣ X ; θ ) = ∑ j = 1 m p θ ( r j ∣ r 1 , … , r j − 1 , X ; θ ) p(R|X;\theta)=\sum_{j=1}^mp_\theta(r_j|r_1,\dots,r_{j-1},X;\theta) p(R∣X;θ)=∑j=1mpθ(rj∣r1,…,rj−1,X;θ),假设encoder和decoder的隐藏层状态分别是 ( e 1 , … , e n ) (e_1,\dots,e_n) (e1,…,en)和 ( d 1 , … , d m ) (d_1,\dots,d_m) (d1,…,dm),attention vector在第 j j j次输出时计算如下:
u i j = v T tanh ( W e e i + W d d j ) , i ∈ ( 1 , … , n ) α i j = s o f t m a x ( u i j ) , i ∈ ( 1 , … , n ) u_i^j=v^T\tanh(W_ee_i+W_dd_j),\enspace i\in(1,\dots,n)\\ \alpha_i^j=\mathrm{softmax}(u_i^j),\enspace i\in(1,\dots,n) uij=vTtanh(Weei+Wddj),i∈(1,…,n)αij=softmax(uij),i∈(1,…,n)
注意力机制帮助pointer network选出输入向量中概率最高的那个,因此,在解码阶段,能够有效地pointing输入:
p ( r j ∣ r 1 , … , r j − 1 , X ) = s o f t m a x ( u j ) p(r_j|r_1,\dots,r_{j-1},X)=\mathrm{softmax}(u^j) p(rj∣r1,…,rj−1,X)=softmax(uj)
下图展示了SWAP-NET的模型架构
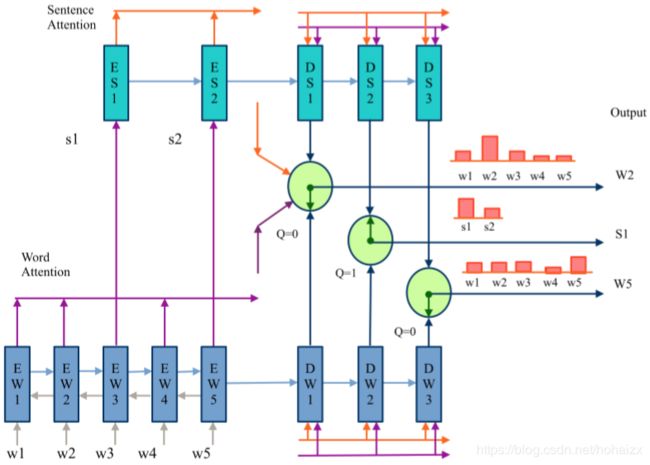
E W \mathrm{EW} EW是单词编码器, E S \mathrm{ES} ES是句子编码器, D W \mathrm{DW} DW是单词解码器, D S \mathrm{DS} DS是句子解码器,输入文档包含单词 [ w 1 , … , w 5 ] [w_1,\dots,w_5] [w1,…,w5]、句子 [ s 1 , s 2 ] [s_1,s_2] [s1,s2],目标摘要序列是 w 2 , s 1 , w 5 w_2,s_1,w_5 w2,s1,w5。下面具体介绍每一个模块
Encoder E W \quad\mathrm{EW} EW是一个bi-directional LSTM, E S \mathrm{ES} ES是一个LSTM。在输入之前,每一个单词被表示成一个 K K K维向量 x i x_i xi(例如:word2vec),word embedding x i x_i xi然后被BiLSTM编码成 e i \mathbf{e_i} ei,最后一个隐藏层状态被用来表示整个句子,随后被 E S \mathrm{ES} ES编码 E k = L S T M ( e k l , E k − 1 ) \mathbf{E_k}=\mathrm{LSTM}(e_{k^l},E_{k-1}) Ek=LSTM(ekl,Ek−1),其中 k l k^l kl第 k k k个句子的是最后一个单词的下标, E k E_k Ek是第 k k k个隐状态。
Decoder D W \quad\mathrm{DW} DW和 D S \mathrm{DS} DS都是LSTM,每一个decoder分别对句子和单词进行pointing,因此可以认为每次decoder的输出是输入encoder的序列的一个下标。假设 m m m是每一个decoder的解码步骤数, D S \mathrm{DS} DS生成的下标序列为 T 1 , … , T m T_1,\dots,T_m T1,…,Tm, T j ∈ { 1 , … , N } T_j\in \{1,\dots,N\} Tj∈{1,…,N}; D W \mathrm{DW} DW生成的下标序列为 t 1 , … , t m t_1,\dots,t_m t1,…,tm, t j ∈ { 1 , … , n } t_j\in \{1,\dots,n\} tj∈{1,…,n}。
Networks details \quad 在第 j j j个解码步骤,采用一个binary switch Q j Q_j Qj决定是选择句子还是单词, Q j = 0 Q_j=0 Qj=0表示选择单词, Q j = 1 Q_j=1 Qj=1表示选择句子。具体地,首先定义 h j \mathbf{h_j} hj和 H j \mathbf{H_j} Hj分别表示 D W DW DW和 D S DS DS第 j j j个隐藏层状态:
h j = L S T M ( h j − 1 , a j − 1 , ϕ ( A j − 1 ) ) H j = L S T M ( H j − 1 , A j − 1 , ϕ ( a j − 1 ) ) h_j=LSTM(h_{j-1},a_{j-1},\phi(A_{j-1}))\\ H_j=LSTM(H_{j-1},A_{j-1},\phi(a_{j-1})) hj=LSTM(hj−1,aj−1,ϕ(Aj−1))Hj=LSTM(Hj−1,Aj−1,ϕ(aj−1))
其中, a j = ∑ i = 0 n α i j w e i a_j=\sum_{i=0}^n\alpha_{ij}^we_i aj=∑i=0nαijwei, A j = ∑ k = 0 N α k j s E k A_j=\sum_{k=0}^N\alpha_{kj}^sE_k Aj=∑k=0NαkjsEk。 ϕ \phi ϕ表示非线性变换,作者采用的是 tanh \tanh tanh,用来联系word-level encodings与sentence decoder,sentence-level encodings与word decoder。

第 j j j个解码步骤的switch概率 p ( Q j ∣ v < j , D ) p(Q_j|v_{<j},D) p(Qj∣v<j,D)计算概率如下:
p ( Q j = 1 ∣ v < j , D ) = σ ( w Q T ( H j − 1 , A j − 1 , ϕ ( h j − 1 , a j − 1 ) ) ) p ( Q j = 0 ∣ v < j , D ) = 1 − p ( Q j = 1 ∣ v < j , D ) \begin{aligned} p(Q_j=1|v_{<j},D)&=\sigma(w_Q^T(H_{j-1},A_{j-1},\phi(h_{j-1},a_{j-1})))\\ p(Q_j=0|v_{<j},D)&=1-p(Q_j=1|v_{<j},D) \end{aligned} p(Qj=1∣v<j,D)p(Qj=0∣v<j,D)=σ(wQT(Hj−1,Aj−1,ϕ(hj−1,aj−1)))=1−p(Qj=1∣v<j,D)
其中, w Q w_Q wQ是模型参数, σ \sigma σ是sigmoid函数, ϕ \phi ϕ是 tanh \tanh tanh函数。然后定义 α k j s = p ( T j = k ∣ v < j , Q j = 1 , D ) \alpha_{kj}^s=p(T_j=k|v_{<j},Q_j=1,D) αkjs=p(Tj=k∣v<j,Qj=1,D)表示在第 j j j个解码步骤选择第 k k k个句子的概率, α i j w = p ( t j = i ∣ v < j , Q j = 0 , D ) \alpha_{ij}^w=p(t_j=i|v_{<j},Q_j=0,D) αijw=p(tj=i∣v<j,Qj=0,D)表示在第 j j j个解码步骤选择第 i i i个单词的概率,计算公式分别如下:
α i j w = s o f t m a x ( v t T ϕ ( w h h j + w t e i ) ) α k j s = s o f t m a x ( V T T ϕ ( W H H j + W T E k ) ) \alpha_{ij}^w=\mathrm{softmax}(v_t^T\phi(w_hh_j+w_te_i))\\ \alpha_{kj}^s=\mathrm{softmax}(V_T^T\phi(W_HH_j+W_TE_k)) αijw=softmax(vtTϕ(whhj+wtei))αkjs=softmax(VTTϕ(WHHj+WTEk))
v t , w h , w t , V T , W H , W T v_t,w_h,w_t,V_T,W_H,W_T vt,wh,wt,VT,WH,WT是模型参数,最后, v j v_j vj由如下公式确定:
v j = { k = arg max k p k j s if max k p k j s > max i p i j w i = arg max i p i j w if max i p i j w > max k p k j s v_j = \begin{cases} k=\arg \max_kp_{kj}^s &\text{if } \max_kp_{kj}^s>\max_ip_{ij}^w \\ i=\arg\max_ip_{ij}^w &\text{if } \max_ip_{ij}^w>\max_kp_{kj}^s \end{cases} vj={k=argmaxkpkjsi=argmaxipijwif maxkpkjs>maxipijwif maxipijw>maxkpkjs
p k j s = α k j s p ( Q j = 1 ∣ v < j , D ) , p i j w = α i j w p ( Q j = 0 ∣ v < j , D ) . p_{kj}^s=\alpha_{kj}^sp(Q_j=1|v_{<j},D),\\ p_{ij}^w=\alpha_{ij}^wp(Q_j=0|v_{<j},D). pkjs=αkjsp(Qj=1∣v<j,D),pijw=αijwp(Qj=0∣v<j,D).
损失函数定义为:
l j = − log ( p k j s q j s + p i j w q j w ) − log p ( Q j ∣ v < j , D ) l_j=-\log(p_{kj}^sq_j^s+p_{ij}^wq_j^w)-\log p(Q_j|v_{<j},D) lj=−log(pkjsqjs+pijwqjw)−logp(Qj∣v<j,D)
在每一个解码步骤中,如果第 j j j个输出是单词,则 q j w = 1 , q j s = 0 q_j^w=1,q_j^s=0 qjw=1,qjs=0;如果第 j j j个输出是句子,则 q j w = 0 , q j s = 1 q_j^w=0,q_j^s=1 qjw=0,qjs=1。最终的摘要是由句子组成,因此需要确定每个句子的重要度:
I ( s k ) = α k j s + λ ∑ w i ∈ s k α i l w I(s_k)=\alpha_{kj}^s+\lambda\sum_{w_i\in s_k}\alpha_{il}^w I(sk)=αkjs+λwi∈sk∑αilw
在实验中,作者将 λ \lambda λ设置为1,最终的摘要由三句得分最高的句子组成。
NEUSUM
该模型同样发表在ACL 2018:Neural Document Summarization by Jointly Learning to Score and Select Sentences。句子打分和句子抽取是抽取式文摘系统的两个主要步骤,传统的方法将这两个过程独立开来,分别考虑。这篇论文中,作者提出了一个端到端(end-to-end)的神经网络框架联合学习句子打分和句子抽取。首先通过一个多层encoder得到句子表示,然后sentence extractor逐一抽取摘要句。抽取过程中,sentence extractor读入最新被抽取的句子,产生一个新的句子抽取状态,以此作为剩余句子的相对重要度得分。
对于包含 L L L个句子的文档 D = ( S 1 , S 2 , … , S L ) \mathcal{D}=(S_1,S_2,\dots,S_L) D=(S1,S2,…,SL),抽取式摘要试图找出 D \mathcal{D} D的一个子集 S = { S ^ i ∣ S ^ i ∈ D } \mathcal{S}=\{\hat{S}_i|\hat{S}_i\in \mathcal{D}\} S={S^i∣S^i∈D}作为摘要。在训练阶段,参考摘要 S ∗ \mathcal{S}^* S∗以及摘要 S \mathcal{S} S相对于评估函数 r ( ⋅ ) r(\cdot) r(⋅)的得分 r ( S ∣ S ∗ ) r(\mathcal{S}|\mathcal{S}^*) r(S∣S∗)是已知的。训练目标是学习一个打分函数 f ( S ) f(\mathcal{S}) f(S)能够在测试阶段找出最佳摘要:
arg max S f ( S ) s . t . S = { S ^ i ∣ S ^ i ∈ D } ∣ S ∣ ≤ l . \begin{aligned} \arg \max_{\mathcal{S}}&\quad f(\mathcal{S})\\ s.t.&\quad \mathcal{S}=\{\hat{S}_i|\hat{S}_i\in \mathcal{D}\}\\ &\quad |\mathcal{S}|\leq l. \end{aligned} argSmaxs.t.f(S)S={S^i∣S^i∈D}∣S∣≤l.
其中, l l l是输出摘要的长度限制。在之前state-of-the-art的工作中,句子抽取策略主要是 MMR \text{MMR} MMR和 ILP \text{ILP} ILP。论文中,作者借用 MMR \text{MMR} MMR的思想:在给定已抽取句子的情况下,选择能最大化相对收益的句子。因此,模型训练的目标就是学得这个收益打分函数。更进一步,作者采用 ROUGE F1 \text{ROUGE F1} ROUGE F1作为评估函数 r ( ⋅ ) r(\cdot) r(⋅),因此,模型需要学得 ROUGE F1 \text{ROUGE F1} ROUGE F1收益:
g ( S t ∣ S t − 1 ) = r ( S t − 1 ∪ S t ) − r ( S t − 1 ) g(S_t|\Bbb{S}_{t-1})=r(\Bbb{S}_{t-1}\cup{S_t})-r(\Bbb{S}_{t-1}) g(St∣St−1)=r(St−1∪St)−r(St−1)
其中, S t − 1 \Bbb{S}_{t-1} St−1是已经选择的句子集合,省略了 r ( ⋅ ) r(\cdot) r(⋅)中的条件 S ∗ \mathcal{S*} S∗。在每一个时刻 t t t,摘要系统选择能最大化 ROUGE F1 \text{ROUGE F1} ROUGE F1收益的句子,直至达到句子数目限制。下图展示了NEUSUM的架构:
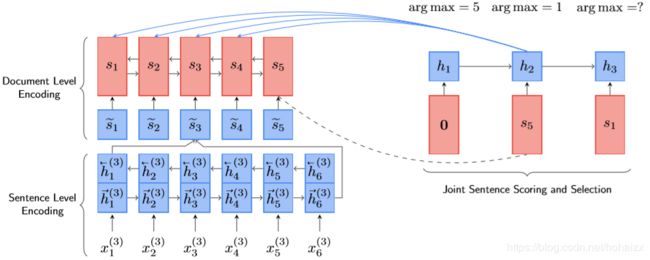
Document Encoding \quad 作者采用一个层次化文档编码器表示文档中的句子,分为sentence-level encoding和document-level encoding。sentence-level encoding读取第 j j j个输入句子 S j = ( x 1 ( j ) , … , x n j ( j ) ) S_j=(x_1^{(j)},\dots,x_{n_j}^{(j)}) Sj=(x1(j),…,xnj(j)),采用BiGRU得到句子表示 s ~ j \widetilde{s}_j s j, 其中GRU定义如下:
z i = σ ( W z [ x i , h i − 1 ] ) r i = σ ( W r [ x i , h i − 1 ] ) h ~ i = tanh ( W h [ x i , r i ⊙ h i − 1 ] ) h i = ( 1 − z i ) ⊙ h i − 1 + z i ⊙ h ~ i \begin{aligned} z_i&=\sigma(W_z[x_i,h_{i-1}])\\ r_i&=\sigma(W_r[x_i,h_{i-1}])\\ \widetilde{h}_i&=\tanh(W_h[x_i,r_i\odot h_{i-1}])\\ h_i&=(1-z_i)\odot h_{i-1}+z_i\odot \widetilde{h}_i \end{aligned} zirih ihi=σ(Wz[xi,hi−1])=σ(Wr[xi,hi−1])=tanh(Wh[xi,ri⊙hi−1])=(1−zi)⊙hi−1+zi⊙h i
W z , W r , W h W_z,W_r,W_h Wz,Wr,Wh是权值矩阵。BiGRU由一个前向GRU和一个反向GRU组成,前向GRU从左向右读入word embedding,得到隐状态序列 ( h → 1 ( j ) , … , h → n j ( j ) ) (\overrightarrow{h}_1^{(j)},\dots,\overrightarrow{h}_{n_j}^{(j)}) (h1(j),…,hnj(j));反向GRU从右向左读入word embedding,得到另一个隐状态序列 ( h ← 1 ( j ) , … , h ← n j ( j ) ) (\overleftarrow{h}_1^{(j)},\dots,\overleftarrow{h}_{n_j}^{(j)}) (h1(j),…,hnj(j)):
h → i ( j ) = G R U ( x i ( j ) , h → i − 1 ( j ) ) h ← i ( j ) = G R U ( x i ( j ) , h ← i + 1 ( j ) ) \overrightarrow{h}_i^{(j)}=GRU(x_i^{(j)},\overrightarrow{h}_{i-1}^{(j)})\\ \overleftarrow{h}_i^{(j)}=GRU(x_i^{(j)},\overleftarrow{h}_{i+1}^{(j)})\\ hi(j)=GRU(xi(j),hi−1(j))hi(j)=GRU(xi(j),hi+1(j))
sentence level表示 s ~ j \widetilde{s}_j s j是最后一个前向GRU与最后一个反向GRU隐状态的拼接:
s ~ j = [ h → 1 ( j ) h ← n j ( j ) ] \widetilde{s}_j=\begin{bmatrix} \overrightarrow{h}_1^{(j)} \\ \overleftarrow{h}_{n_j}^{(j)} \end{bmatrix} s j=[h1(j)hnj(j)]
同样,document level encoder采用另一个BiGRU,输入为 ( s ~ 1 , … , s ~ L ) (\widetilde{s}_1,\dots,\widetilde{s}_{L}) (s 1,…,s L),前向GRU和反向GRU分别得到两个因状态序列 ( s → 1 , … , s → L ) (\overrightarrow{s}_1,\dots,\overrightarrow{s}_L) (s1,…,sL)、 ( s ← 1 , … , s ← L ) (\overleftarrow{s}_1,\dots,\overleftarrow{s}_L) (s1,…,sL),document level表示 s i s_i si同上:
s i = [ s → i s ← j ] {s}_i=\begin{bmatrix} \overrightarrow{s}_i \\ \overleftarrow{s}_j \end{bmatrix} si=[sisj]
Joint Sentence Scoring and Selection \quad 给定前一个选择句子 S ^ t − 1 \hat{S}_{t-1} S^t−1,sentence extractor通过给剩余句子打分的形式决定下一个要选择的句子 S ^ t \hat{S}_t S^t。在对句子打分时,同时考虑其重要度和已经输出的摘要。因此,作者采用另一个GRU作为recurrent unit用来记住已经输出的摘要,采用一个多层感知机(MLP)对句子打分。具体来说,GRU接受前一个选择的句子 S ^ t − 1 \hat{S}_{t-1} S^t−1的document level表示 s t − 1 s_{t-1} st−1作为输入,产生当前隐藏层状态 h t h_t ht。句子打分器是一个两层的MLP,输入是当前隐藏层状态 h t h_t ht以及 s i s_i si,输出是 S i S_i Si的得分 δ ( S i ) \delta(S_i) δ(Si)。
h t = G R U ( s t − 1 , h t − 1 ) δ ( S i ) = W s tanh ( W q h t + W d s i ) h_t=GRU(s_{t-1},h_{t-1})\\ \delta(S_i)=W_s\tanh(W_qh_t+W_ds_i) ht=GRU(st−1,ht−1)δ(Si)=Wstanh(Wqht+Wdsi)
其中, W s , W q , W d W_s,W_q,W_d Ws,Wq,Wd是网络参数,当选择第一个句子时,作者对GRU隐藏层状态 h 0 初 始 化 如 下 h_0初始化如下 h0初始化如下:
h 0 = tanh ( W m s ← 1 + b m ) S 0 = Ø s 0 = 0 \begin{aligned} h_0&=\tanh(Wm\overleftarrow{s}_1+b_m)\\ S_0&=\text{\O}\\ s_0&=\bf{0} \end{aligned} h0S0s0=tanh(Wms1+bm)=Ø=0
对所有句子打分完成后,选择收益值最大的那个:
S ^ t = arg max S i ∈ D δ ( S i ) \hat{S}_t=\arg\max_{S_i\in \mathcal{D}}\delta(S_i) S^t=argSi∈Dmaxδ(Si)
Objective Function \quad 作者采用最优化模型预测 P P P与标注训练数据 Q Q Q之间的KL-散度。首先对 δ ( S i ) \delta(S_i) δ(Si)归一化得到预测分布 P P P:
P ( S ^ t = S i ) = exp ( δ ( S i ) ) ∑ k = 1 L exp ( δ ( S i ) ) P(\hat{S}_t=S_i)=\frac{\exp(\delta(S_i))}{\sum_{k=1}^L\exp(\delta(S_i))} P(S^t=Si)=∑k=1Lexp(δ(Si))exp(δ(Si))
考虑到标注数据中 F 1 \mathcal{F1} F1收益值可能是负值,作者采用 M i n − M a x N o r m a l i z a t i o n Min-Max Normalization Min−MaxNormalization将收益值调整到 [ 0 , 1 ] [0,1] [0,1]:
g ( S i ) = r ( S t − 1 ∪ { S i } ) − r ( S t − 1 ) g ~ ( S i ) = g ( S i ) − min ( g ( S ) ) max ( g ( S ) ) − min ( g ( S ) ) g(S_i)=r(\Bbb{S}_{t-1}\cup \{S_i\})-r(\Bbb{S}_{t-1})\\ \widetilde{g}(S_i)=\frac{g(S_i)-\min(g(S))}{\max(g(S))-\min(g(S))} g(Si)=r(St−1∪{Si})−r(St−1)g (Si)=max(g(S))−min(g(S))g(Si)−min(g(S))
然后采用一个附加temperature τ \tau τ的 s o f t m a x \mathrm{softmax} softmax操作生成标注数据的分布 Q Q Q作为训练目标,tempature τ \tau τ是一个平滑因子
Q ( S i ) = exp ( τ g ~ ( S i ) ) ∑ k = 1 L exp ( τ g ~ ( S i ) ) Q(S_i)=\frac{\exp(\tau\widetilde{g}(S_i))}{\sum_{k=1}^L\exp(\tau\widetilde{g}(S_i))} Q(Si)=∑k=1Lexp(τg (Si))exp(τg (Si))
因此,最小化 K L KL KL损失函数 J J J:
J = D K L ( P ∣ ∣ Q ) J=D_{KL}(P||Q) J=DKL(P∣∣Q)
总结
基于neural document model的方法,通常将摘要任务看作是一个序列标注问题,采用seq2seq的模式进行求解,首先采用 ( B i ) L S T M (Bi)LSTM (Bi)LSTM、 ( B i ) G R U (Bi)GRU (Bi)GRU循环神经网络或者 C N N CNN CNN等对句子编码,得到document-level的句子表示,然后同样采用 R N N RNN RNN进行句子抽取(输出该句子是否属于文摘句),在解码过程中通常也会加入注意力机制。
参考文献
[1] An Unsupervised Multi-Document Summarization Framework Based on Neural Document Model.
[2] Neural Summarization by Extracting Sentences and Words.
[3] SummaRuNNer: A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents.
[4] Extractive Summarization with SWAP-NET: Sentences and Words from Alternating Pointer Networks.
[5] Neural Document Summarization by Jointly Learning to Score and Select Sentences.