最近在STM32做一个关于USB音频的应用,调试过程中一直被一个随机产生的HARD FAULT折磨。问题很奇怪,进入HARD FAULT的时间不定,可能连上USB后几秒就触发HARD FAULT,也可能程序跑几分钟甚至几十分钟才会触发。尽管感觉问题极有可能来自USB部分代码,但起初一直没有办法找到导致问题的代码,百度上搜素了一下,但是感觉对自己没什么启发。经过努力,最终找到了问题所在,同时也学到了新的东西,现在先介绍下调试过程。
首先在KEIL下进入DEBUG模式运行程序,待MCU"死掉"后停止,显然是卡在HARD FAULT的while(1)里面的。接下来打开FAULT REPORTS窗口:
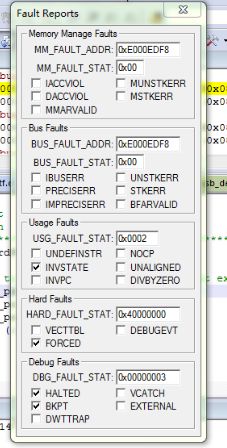
可以看到HARD FAULT是由USAGE FAULT导致的,原因是INVSTATE,从“STM32常见Hard+Fault的诊断”的PPT中可以了解到,INVSTATE表示MCU尝试进入ARM状态,这是非法的,所以产生了USAGE FAULT。此外,PPT里还有这样的描述:

另外,在Cortex-M3权威指南中也有这样描述:使用BXL的时候要小心,因为它还带有改变状态的功能。因此reg的LSB必须是1,以确保不会尝试进入ARM状态,如果忘记置位LSB,则FAULT伺候;同理,你也必须保证送给PC的值必须是奇数(LSB=1)。
虽然了解了这些,但是还是不能直接产生帮助。接下来,在GOOGLE上找到了一个名为“keil_hardfault”的PDF文件,是KEIL公司写的,该文档的后半部分通过一个例子介绍了定位产生HARD FAULT之前代码的方法。通过一些摸索,利用这个方法我成功找到了问题的位置。
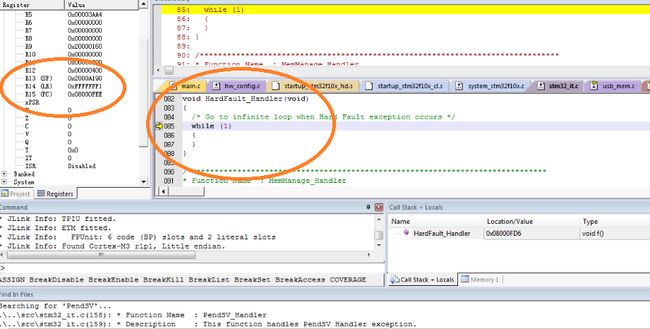
首先,看到此时MCU停在了HARD FAULT里,寄存器LR里放存放的是HARD FAULT返回的地址,可以看到此时LR = 0xFFFF_FFF1,显然是一个错误的指令地址,所以可以判断是程序跳转到错误的地址,并且该地址的LSB是0,故触发了USAGE FAULT。出错的流程是这样的:
[正确代码] --(出错)--> [0xFFFF_FFF0]。接下来需要做的是,找到导致错误跳转的代码,
注意到寄存器SP(R13),它指向当前使用的栈顶,在MEMORY窗口中输入SP的值[0x2000A190]:
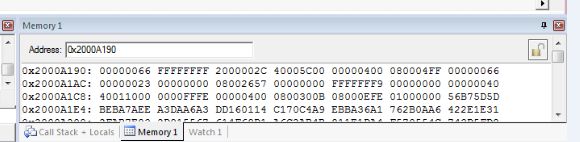
根据CM3内核的栈是从上往下生长,并且按寄存器标号从大到小的顺序压入栈,这样就可以找到“出事”时的寄存器情况。
在 keil_hardfault.pdf 里的这幅图可以看得更直观:

可以看到跳转到中断函数HARD FAULT之前的寄存器情况,例如R0 = 0000_0066,R2 = FFFF_FFFF。
这时候我们需要关注的是LR寄存器,其值指向 错误跳转指令 的下一条指令,可以看到栈里的LR = 0x0800_04FF,那么产生错误的指令就是 LR = 0x0800_04FC,
在汇编窗口里定位这个地址,如下图:

可以看到指令是BLX R0,而“当时”寄存器R0的值是0x0000_0066,显然是错误的跳转地址。找到了指令的地址也就可以看到对应的C语言代码,大概也能猜到了,问题出在数组越界了,导致越界的原因就是EPindex,之后在这里加了一些调试代码,很容易的就确认了问题是由EPindex的值为0导致的。
之后的就不多说了,既然找到了产生HARD FAULT的代码,也可以松一口气了。总之这个方法在处理这个问题上的确很有效。