MapReduce重点知识总结
MapReduce定义
mapred是一个分布式运算程序的编程框架,它的核心功能是将用户编写的业务逻辑代码和
自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。
MapReduce优缺点
优点:
1)mapreduce易于编程(简单的实现一些接口,就可以完成一个分布式程序)
2)良好的扩展性(计算资源不能满足时,可以通过简单的增加机器来扩展它的计算能力)
3)高容错性(有多个副本)
4)适合PB级以上海量数据的离线处理(可以实现上千台服务器集群并发工作,提供数据处理能力)
缺点:
1)不擅长实时计算(mapreduce无法像mysql一样,在毫秒或者秒级内返回结果)
2) 不擅长流式计算(流式计算的输入数据时动态的,而mapreduce的输入数据集是静态的)
3)不擅长线性计算(即前一个程序的输出作为后一个程序的输入,这样会造成大量的磁盘IO,导致性能非常低下)
MapReduce核心思想
MapReduce运算程序一般需要2个阶段,即Map阶段和Reduce阶段。
map阶段根据输入数据大小分为多个MapTask任务,又会根据任务进行分区,
reduce阶段对多个分区的任务进行汇总,然后输出。
map和reduce并发实例完全并行运行,互不相干。
Hadoop序列化
序列化:把内存中的对象通过字节流的方式写入到磁盘,做到持久化。
反序列化:把磁盘中的字节流读出转换成对象。
数据切片与MapTask并行度
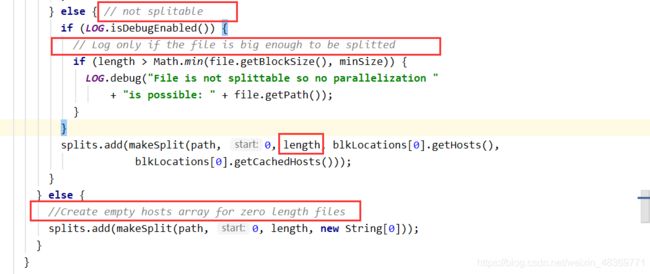
数据切片大小最好设置为一个数据块的大小,如果切片过大或者过小,MapTask就会从不同的节点中去读取数据,导致多次IO,而如果把切片大小设置为数据块大小,可大大减少IO次数,提高性能。
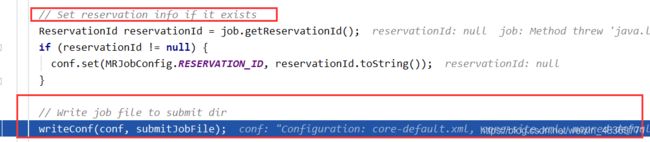
JOB提交流程源码

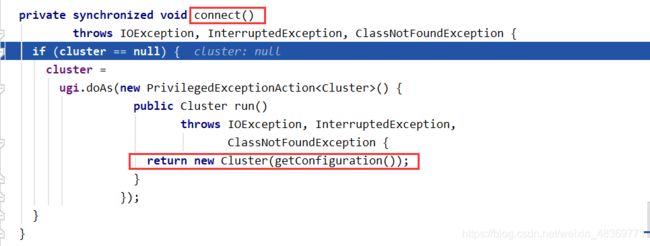

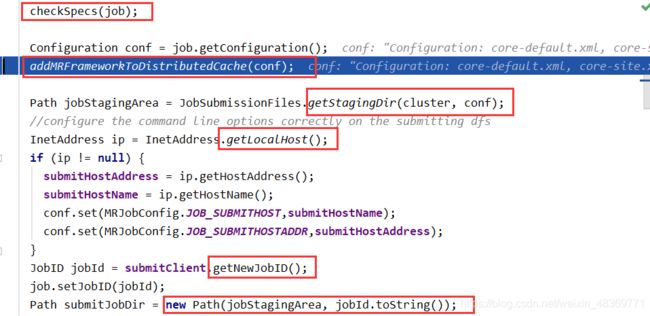
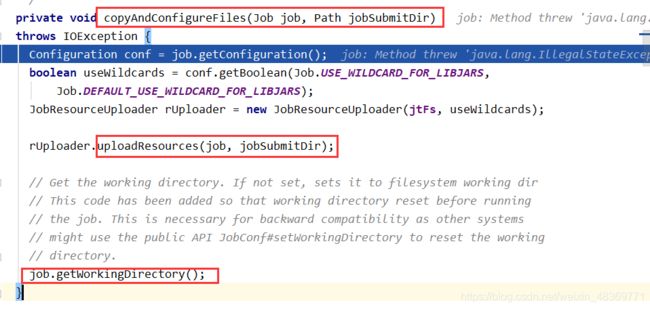

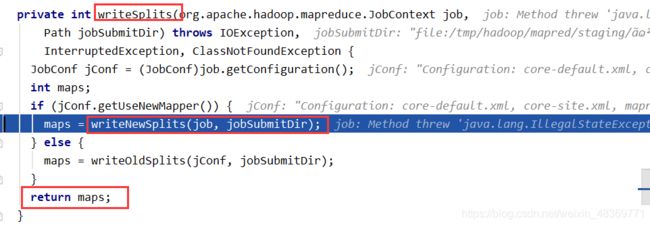

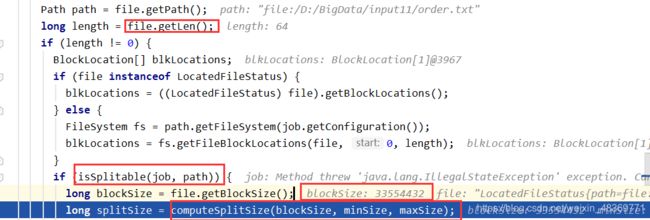









FileInputFormat切片原理
1)程序通过Namenode先找到数据存储的目录。
2)开始遍历处理目录下的每一个文件。
3)遍历第一个文件(获取文件大小,为了切片做准备,集群默认切片大小128M,本地默认32M)。
4)开始切片(注意:如果切片之后剩余数据量除以默认切片大小不大于1.1,则与前一个切片合成一个切片,也就是在这种情况下,切片的大小可以稍大于默认切片大小,否则在创建一个切片)。
5)将切片信息写到一个切片规划文件中。
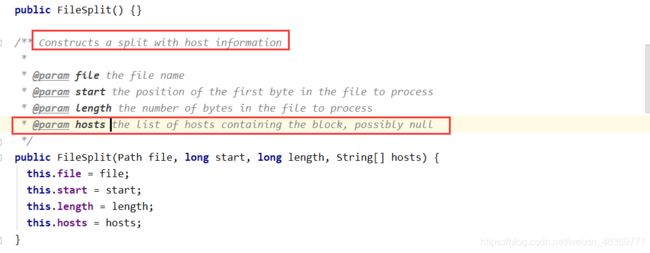
6)InputSplit只记录了切片的元数据信息,比如起始位置,长度以及所在的节点列表等。
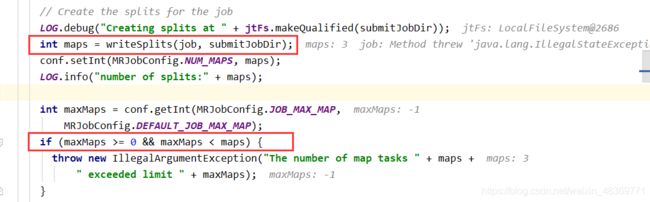
7)提交切片规划文件到yarn上,yarn的AppMaster就可以根据切片规划文件计算开启的MapTask个数。
注意:切片是不考虑数据集整体,而只考虑每一个文件,即不可把多个文件大小加到一起来计算切片数量。
computeSplitSize(Math.max(minSize,Math.min(maxSize,blocksize));
默认块大小blocksize=128M minSize = 1 maxSize=0x7fffffffffffffff
根据上面方法:想要下调切片大小,把maxSize调小即可
想要上调切片大小,把minSize调大即可
FileInputFormat的实现类
1)TextInputFormat
2)CombineTextInputFormat
①虚拟存储切片的最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4M);
注意:虚拟存储切片最大值最好根据实际的小文件大小来设置
②切片机制
生成切片过程包括:虚拟存储过程和切片过程
1.虚拟存储过程
a.根据虚拟切片的最大值来判断,如果文件不大于这个值,则单独划分为一个块,如果大于则划分成两个或者多个块。划分出来的块不可以太小,如果太小,则把这部分均分给它原来它划分的块(块大小可以稍微大于虚拟存储切片的大小)。
2.切片过程
a.判断虚拟存储之后的块是否有大于虚拟存储切片的最大值,大于则单独形成一个切片。
b.如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
如:1.3 4.5 6.8 3.4
经过虚拟存储过程,则会形成1.3 2.25 2.25 3.4 3.4 3.4这几个文件块
在经过切片过程,则会形成3个切片,分别为:3.55 5.65 6.8这三个切片,然后把切片信息放到切片规划文件里,以后提交给yarn,告诉yarn要开启几个MapTask
MapReduce详细工作流程
1)客户端上传一个待处理文件。
2)获取待处理文件数据的信息,根据信息,形成一个切片规划文件。
3) 把切片规划文件提交给ResourceManager,判断yarn还是在local上运行,RM根据切片数,分配相等数量的MapTask。
4)在MapTask里面,通过默认的TextInputFormat按行读取文件,把读取的文件放到Mapper方法里,经过Mapper处理,把处理结果写到一个收集器中。
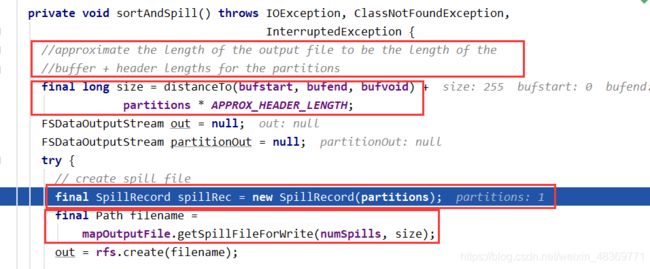
5)把收集器中的数据写到环形缓冲区中去(缓冲区中从一个节点开始,一边写索引,一边写keyValue键值对),环形区大小为100M ,当缓冲区中数据写到80%时,就会发生溢写,把数据全部写到磁盘文件中,然后开始反向写,即反向溢写(前面谈过一个MapTask大小切片大小128),在这个缓冲区中索引会占很大部分,所以会发生多次溢写。
6)在把数据写到缓冲区的时候,就会进行分区,分区是根据实际业务逻辑决定的。
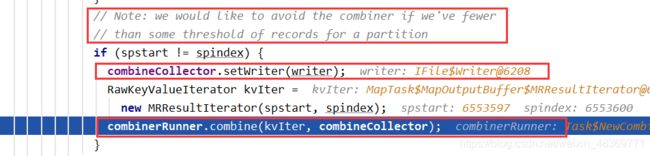
7)每次溢写的时候都会对分区中的数据进行排序,当溢写结束(即把缓冲区中的数据全部读出),会对不同文件,相同分区的数据进行归并排序(放到一个文件中)。
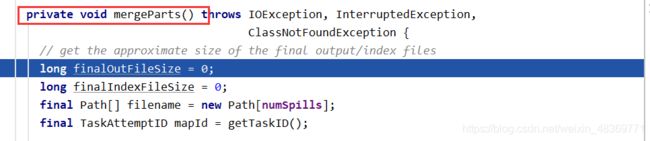
8)接着会把不同的MapTask任务,处于相同分区的数据拷贝到一个文件中,再次进行归并排序。
9)把归并排序后的数据放到Reducer里面,进行业务处理。
10)最后通过TextOutputFormat把处理后的数据写出到part-r/m-000001中去。
分区源码


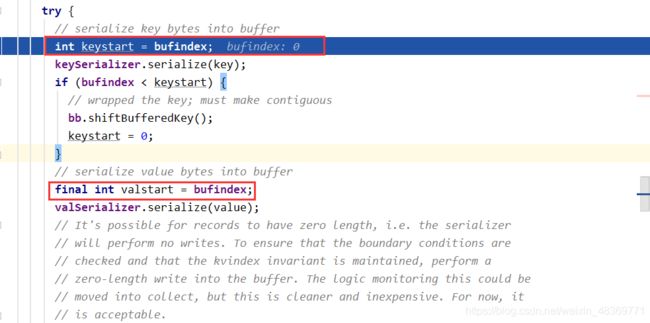
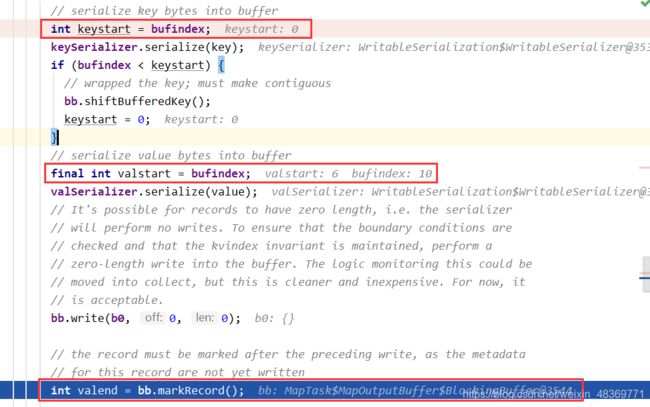
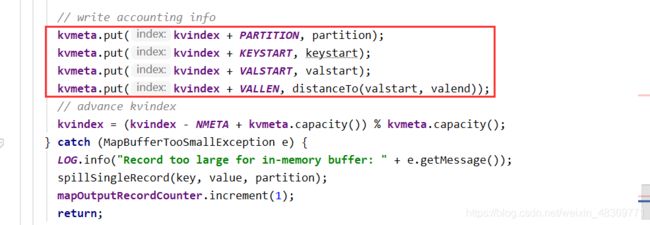
分区步骤
1)自定义Customer类,继承 Partitioner ,重写getPartition()方法,获得分区号(一个分区号对应一个分区)。
2)在驱动类driver中写入以下代码,定义分区时要执行的类
Job.getInstance(new Configuration()).setPartitionerClass(Customer.class);
- 设定ReduceTask数目,如下 ,*不能少于分区数。
Job.getInstance(new Configuration()).setNumReduceTasks(task num);
MapTask阶段流程
1)read阶段:读取传入数据信息,划分切片,启动MapTask,通过行处理工具读取数据。
2)Map阶段:Mapper – Map – Collector(partitioner) – Circle Area(distanceTo,keyStart,valStart,valEnd,partition) | (kv pairs) – Spill out – Sort
– Conbiner – MapTaskSort
ReduceTask阶段流程
1)reduce阶段:Copy – Merge – ReduceTaskSort
2)result to HDFS
Container源码