Jeffrey Dean联署论文 The Case for Learned Index Structures
The Case for Learned Index Structures是一篇谈ML运用到计算机系统中的论文,主要讲的是通过神经网络使得B-tree、Hash index和布隆过滤更有效率。
Abstract
作者认为无论是Btree、BitMap-Index、Hash index还是布隆过滤器都是一种映射模型。而这种映射索引模型都可以被包括自深度学习模型在内的模型代替。实现的关键在于是模型可以学习查找键的排序顺序或结构,并以此有效地预测记录的位置或是否存在。并在理论上分析了使得自学习模型性能强于传统模型的几点因素。作者希望在未来,NN方式在系统设计方面有更大的表现空间。
1. Introduction
索引,Btree适合范围查询,Hash-map点查询性能突出,布隆过滤用于查看记录是否存在,由于索引在数据库和各种计算机系统中的重要位置,在近十年来得到了广泛的研究。但是目前这些索引结构都有通用性,并没有针对数据分布和当前流行的数据模式有优化(作者在这里举了个例子:如果系统的性能目标是提供高性能的范围存取,系统设计师会使用传统的B-tree,这样可以减少时间和空间的占用)。然而,作者也指出,对每种数据模型都设计相应的方法代价实在太高,但是使用ML技术就可以动态生成专用的索引结构,称之为自学习索引。
对于使用ML方法(神经网络NN)产生的巨大的训练代价,作者认为在更先进的硬件上这都不是事儿(we argue that none of these apparent obstacles are as problematic as they might seem......especially on the next generation of hardware.)
在保证语义方面,索引可以被其他类型的ML模型所替代了。比如,B-tree可以被看成一个通过一个key输入就能在有序数据模型中预测到数据记录位置的模型,bloom过滤器可以看作是一个区分指定key是否存在在的二分类器,但是存在一些差异,比如:bloom过滤器允许存在误检的positive但是不允许误检的negative。这篇文章中会通过新的学习技术或者简单的辅助数据结构来解决这些差异。
在性能方面,作者发现CPU大多都已经有了很强大的SIMD性能,很多笔记本和手机都有内置的GPU或者TPU,实现高强度的ML数学运算将不成问题,并举了Nvidia和Google TPU的例子。
作者强调:他们并不是想用自学习索引来替代掉传统的索引结构,而是为了评估这种建立索引的新方法的潜力,为当前的领域做补充,并开创一个全新的领域。这基于一个重要的观点:很多数据结构都可以分解为学习模型和一个辅助结构并提供和先前结构相同的功能。这种方法的潜在力量来自这样一个事实,即描述数据分布的连续函数可用于构建更有效的数据结构或算法。作者们在只读负载数据方面虽然得到了较好的结果,但是在写入繁忙的系统中还存在一些挑战。但是他们依然相信ML在数据库方面做出的研究如果成功的话,会在当前系统设计方面产生翻天覆地的变化。
在接下来的两个部分(2、3)会介绍利用B-tree的自学习索引。第4部分会扩展到Hash结构。第5部分将对在Bloom过滤的研究进行介绍。
2. Range Index
B-tree就是一个可以通过key值转换到postion值的结构,那么B-tree可以被ML中的回归树(regression tree)或者那些可以提供最小和最大误差的模型所替代(包括神经网络)。乍看起来,为ML模型提供和B-tree类似的最大和最小误差保证似乎十分困难,但是其实很简单:首先,B-tree只为已被存储的key提供最大最小误差,并不是全部key。对于新的数据,B-tree需要重新平衡,ML模型则需要重新训练以保证具有相同的误差保证。另外也是很重要的是,准确的误差定界并不是必不可少的条件,可以通过预测值附近的局部搜索对误差进行修正。总之,可以使用回归模型,包括线性回归和或者神经网络。Figure 1
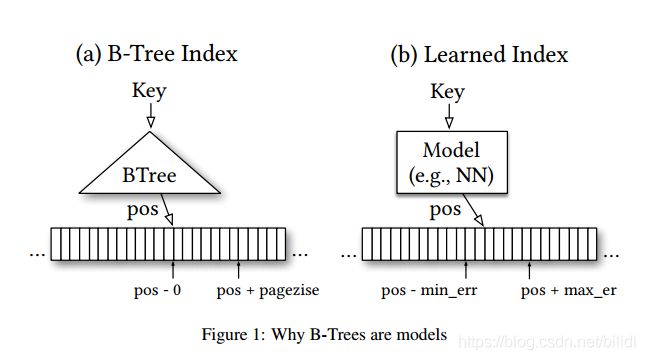
依然存在一些问题需要解决,在后续论文和附录中将得以仔细解释。
使用其他类型的模型可能将B-tree的查询复杂度从log n降到常量,机器学习,特别是神经网络的魅力在于,他们能够对大量复杂的数据分布、混合体和其他的数据特性还有模式进行学习。 而挑战在于如何去平衡模型的复杂性和准确性之间的关系。这篇文章中只对位于测内存中的热集建立索引。
2.1 What Model Complexity Can We Afford?
对比传统B-tree和ML模型在相同时间内工作量来对比复杂性。B-tree取到一个B-tree页大概花费50个周期,并且这些周期很难并行。所以只要一个模型的回报优于1/100每400个操作就会比传统B-tree更快。对于ML模型,其可以在相同的时间内完成更复杂的模型并且能够负载从CPU转换到GPU上,例如英伟达的V100GPU可以达到60000次操作每周期。虽然将计算转换到GPU上会带来更高的存取时延,但是,作者认为这些阻碍并不是不能够克服的,因为GPU/TPU的运算性能的增长在未来是可以预见的。不过,在本文中作者依旧将研究重点放在当前的CPU上(作者牛逼!)。
2.2 Range Index Models are CDF Models(累积分布函数模型)
对于范围索引而言,请求为点查询时,记录的顺序无关紧要,对于范围查询,必须根据查找键对数据进行排序,以便可以有效地检索范围(例如,在时间范围内)中的所有数据项。这就使得这种在一个有序序列中预测某个Key位置的模型可以很高效地被视作CDF(累积分布函数),可以把这种CDF模型格式定义为
p = F (Key) ∗ N
其中,p是估计位置,F(Key)是估计累计分布函数,用于评估估计值和目标位置P之间的相似度。N是所有键的数目。Figure 2
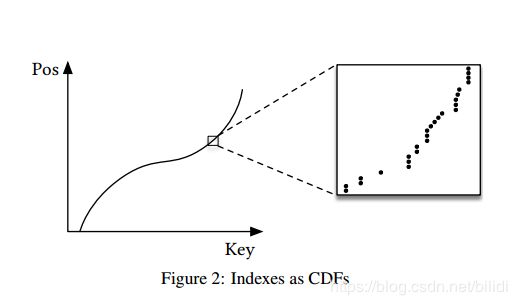
这开辟了一系列新的有趣方向:
- 意味着index需要学习数据分布。 B树通过构建回归树来“学习”数据分布。 线性回归模型将通过最小化线性函数的(平方)误差来学习数据分布。
- 估计数据集的分布当前的研究成果丰富,自学习index可以从先前的的研究成果中获得灵感。
- 学习CDF在优化其他类型的索引结构和潜在算法方面起着关键作用,将在本文后面概述。
- 关于理论CDF与实际CDF的接近程度的研究有着悠久的历史。 对附录A中的方法的适用程度进行了高级理论分析。
2.3 A First, Na¨ıve Learned Index
作者在Tensorflow中使用200M条web服务器记录在时间戳timestamps上建立了索引。这个训练神经网络是两层全联通神经网络结构,每层都有32个ReLU激活函数神经元,Na¨ıve Learned Index。但是,其1秒钟可以完成1250次的预测定位,每次耗时约80000ns,而且不包括找到实际记录的时间。而B-Tree可以达到800ns,二分查找900ns。作者列出了造成局限性的几个关键点:
- Tensorflow适用于体量较大的模型,不适用于小模型
- B-tree或者决策树这种简单的if结构很容易就能对数据进行过拟合。但是对于其他的模型,虽然他们可以对CDF做一般程度上的拟合,可是在个体数据层面上并不能达到精确(如果要精确定位需要很大的空间和时间来达到更低的精度。“最后一公里”)。
- B-tree的顶级节点缓存在cache中,并通过其查找其他page。而标准的神经网络模型需要将全局加载才能计算出预测值,这使得代价倍增。
3.The RM-Index
作者为了解决上部分提到的几点问题,使得自学习模型能真正胜任index工作,他们开发了一套学习索引框架LIF(learning index framework)、递归式模型索引RMI(recursive-model indexes)和基于标准错误的搜索策略(standard-error-based search strategies)
3.1 The Learning Index Framework (LIF)
LIF可以认为是一个索引合成系统, 它可以生成不同的索引配置并对它们进行优化,而且可以自动对它们进行测试。可以对简单的模型(线性回归模型)进行on-the-fly训练,对NN模型on-the-fly时需要Tensorflow,但是并不是直接使用Tensorflow,而是直接从模型中提取权值参数生成C++数据结构。可以在30ns中得到执行。当前处于试验阶段。
3.2 The Recursive Model Index
针对2.3中的“最后一公里”的问题,作者指出:达到100M数据只有百级别的误检是比较困难的,但是降到万级别的误检是相较容易的,所以将误检从万级降到百级只需要将模型要处理的数据进行划分就行了。将B-tree的前两层替换为模型。
基于上述内容和和前人的研究,研究人员提出了一种模型的垂直层次结构Figure 3。模型记为f(x),x代表key,y∈[0,N)代表预测位置。

模型f(x),其中x是key,y∈[0; N)是位置,我们假设阶段i有Mi个模型。 我们在阶段0训练模型,f0(x)≈y。 因此,阶段i中的模型k,由f^k(k)表示,由损失函数训练:

![]() 函数递归调用
函数递归调用  ,迭代训练每个模型,每个模型都负责在一定错误率下得到预测值,然后根据预测值选择下一个模型,和上一个模型一样,这个模型负责降低错误率并传递于再下一个模型。 最后,根据所使用的模型,不同阶段之间的预测不一定能被解释为位置估计,而应该被视为选择对某些关键字有更好了解的专家。
,迭代训练每个模型,每个模型都负责在一定错误率下得到预测值,然后根据预测值选择下一个模型,和上一个模型一样,这个模型负责降低错误率并传递于再下一个模型。 最后,根据所使用的模型,不同阶段之间的预测不一定能被解释为位置估计,而应该被视为选择对某些关键字有更好了解的专家。
作者列出了这种模型结构的优势:
- 执行成本并不需要考虑模型的大小和模型复杂度
- 数据分布形态容易取得
- 高效地解决了‘最后一公里’的问题
- 并不是"seach"的操作,而是转换成了可以利用TPU或者GPU的矩阵乘法
3.3 Hybrid Indexes
递归型模型的另一个优势是可以构建混合模型,比如,模型顶层使用一个小的RLU神经网络,因为它们可以模拟出复杂的数据分布。在模型底部可以使用大量的线性回归模型,或者直接使用B-tree。本文中,作者主要使用激活函数是ReLU的全连接神经网络和B-tree。在给定模型stage数和每个stage模型数的情况下,使用如下算法进行训练。

以全体数据为数据集(line3)训练第一层模型 ,基于该顶级节点模型的预测,然后从下一阶段(第9行和第10行)中挑选模型并添加落入该模型的所有键(第10行)。在混合模型中如果NN的min-/max-误差不满足阈值,则使用Btree替换。
作者特别指出,混合索引允许我们将learned索引的最坏情况性能与B树的性能联系起来。在极端的情况下,所有的模型会被替换成Btree而成为一个完整的Btree。
3.4 Search Strategies and Monotonicity(查询策略和单调性)
范围索引一般需要确定一个upper bound(key) 或者[lower bound(key)]的位置来实现,learned范围索引亦同。虽然人们做了很多的尝试,但二分查找和小负载还是很快的方法,因为任何其他方法带来的多余复杂度都会拖慢这个过程。然而,learned范围索引对比(Btree)的优势在于,它给出确定的key位置而并不是给出所在region。在本文中,作者讨论了两种查询策略:Model Biased Search策略和Biased Quaternary Search策略
Model Biased Search策略:是作者默认的查询策略,和传统的二分法不同的是:第一个中间点设置为模型预测的值。
Biased Quaternary Search策略:四分法查询是将一个分裂点变为三个分裂点,将分裂点放入cache以提升性能。作者在文中将分裂点初始化为pos - σ、pos和pos + σ
在所有的方法中作者都使用最大最小误差来确定查询范围。
3.5 Indexing Strings
实现索引字符串首先需要注意的问题是,如何将一个字符串转化为模型的特征。作者将一个长度为n的字符串当成一个在n维空间的向量。
为了提升效率,作者采用了前向后向神经网络的结构(输入不是单个值而是一个向量),线性模型w·x + b
作者认为,在tokenization方面和字符串的语言处理方面还有很广阔的研究前景。
3.6 Training
训练时间的讨论并不是本文的重点,NNs、线性和多元回归模型的训练时间相对较短。NNs可以使用随机梯度下降法。在200M条记录上训练出一个简单的RMI模型并不需要耗费多长的时间。
3.7 Results
作者在learned范围查询索引模型的空间和时间两个方面和一些读优化的索引结构做了对比。
3.7.1 Integer Datasets(整型数据集)
作者使用一个两层的RMI模型,并将其第二层设置为不同大小(10k, 50k, 100k, and 200k)和经过读优化的BTree进行对比,测试的数据集是为三种不同的数据集,分别是有200M条log记录的Weblogs(结构复杂,建模困难),大约200M的用户指定的道路、博物馆和咖啡馆的位置信息(相较weblog的数据更有规律),190M的合成数据并且符合(0,2)的正态分布(主要用来测试模型在很大数据偏移的情况下的性能,因其非线性)。对于所有的B-Tree实验,作者使用64bits的key和64bits的value。
实验的基准使用有catch优化的Btree,具有理想的性能。learned模型,使用NN,有0~2层隐藏层,每层有4~32个神经元。作者发现,simple(没有隐藏层)到semi-complex(2了隐藏层 8或16个神经元)的模型作为RMI的第一层是最理想的。对于第二层使用simple线性模型是具有较好的表现。作者认为这并不难理解,因为“最后一英里”问题不值得使用非常复杂的结构,线性模型就足以胜任。