pandas下——进阶学习
6、缺失数据
缺失观测及其类型:了解缺失信息、三种缺失符号、Nullable类型与NA符号、NA的特性、convert_dtypes方法
缺失数据的运算与分组:加号与乘号规则、groupby方法中的缺失值
填充与剔除:fillna方法、dropna方法
插值:线性插值、高级插值方法、interpolate中的限制参数





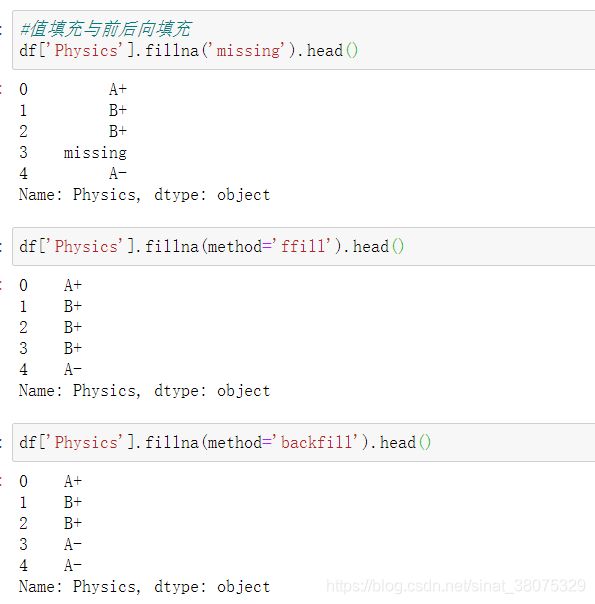
【问题⼀】 如何删除缺失值占比超过25%的列
【问题⼆】什么是Nullable类型?请谈谈为什么要引入这个设计
【问题三】对于一份有缺失值的数据,可以采取哪些策略或方法深化对它的了解?
7、文本数据
- string类型的性质:string与object的区别;string类型的转换
- 拆分与拼接:str.split方法;str.cat方法
- 替换:str.replace的常见方法;子组与函数替换
- 子串匹配与提取:str.extract方法;str.extractall方法;str.contains和str.match
- 常用字符串方法:过滤型方法;isnumeric方法
1.1、string与object的区别
字符存取方法会返回相应数据的Nullable类型,而object会随缺失值的存在而改变返回类型
某些Series方法不能在string上使用,因为存储的是字符串而不是字节
string类型在缺失值存储或运算时,类型会广播为pd.NA,而不是浮点型np.nan
1.2、string类型的转换
分两步转换,先转为str型,再转为string类型
2.1 、str.split方法:分隔符与str的位置元素选取,根据某个元素分隔,默认为空格

需注意split后的类型是object,因为现在Seires中的元素已经不是string,而包含了list,且string类型只能含有字符串
expand参数控制了是否将列拆开,n参数代表最多分割几次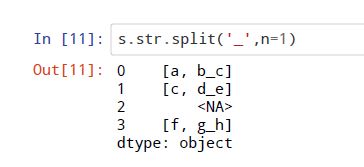
2.2、str.cat对于不同对象的作用结果并不相同。对象包括:单列、双列、多列
对于单个Series而言,是指所有的元素进行字符合并为一个字符串
对于两个Series而言,是对应索引的元素进行合并

8、分类数据
一、category的创建及其性质
分类变量的创建:用Series创建;对DataFrame指定类型创建;利用内置Categorical类型创建;利用cut函数创建(默认使用区间类型为标签;可指定字符为标签)
用Series创建
pd.Series(["a","b","c","a"],dtype="category")
对DataFrame指定类型创建
temp_df=pd.DateFrame({'A':pd.Series(["a","b","c","a"],dtype="category"),'B':list('abcd')})
temp_df.dtypes
利用内置Categorical类型创建
cat=pd.Categorical(["a","b","c","a"],categories=['a','b','c'])
pd.Series(cat)
利用cut函数创建
默认使用区间类型为标签
pd.cut(np.random.randint(0,60,5),[0,10,30,60])
可指定字符为标签
pd.cut(np.random.randint(0,60,5),[0,10,30,60],right=False,labels=['0-10','10-30','30-60'])
二、分类变量的结构
一个分类变量包括三个部分,元素值、分类类别、是否有序
使用cut函数创建的分类变量默认为有序分类变量
(a)describe方法
s=pd.Series(pd.Categorical(["a","b","c","a",np.nan],categories=['a','b','c','d']))
(b)categories和ordered属性
9、时序数据
时序的创建:四类时间变量;时间点的创建;DateOffset对象
时序的索引及属性:索引切片;子集索引;时间点的属性
重采样:resample对象的基本操作;采样聚合;采样组的迭代
窗口函数:Rolling;Expanding
1、四类时间变量:Date times;Time spans;Date offsets;Time daltas
2、时间点的创建:
to_datetime方法
使用列表可将其转为时间点索引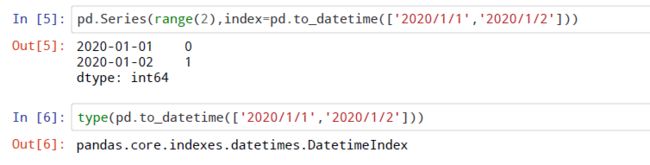
date_range方法
3、时序的索引及属性
索引切片: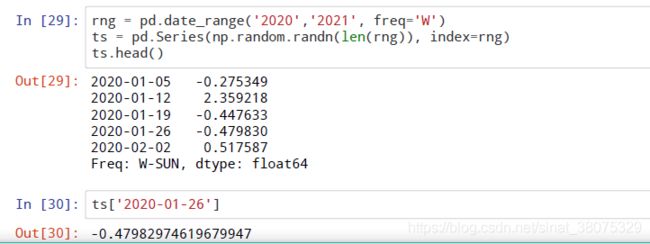
合法字符自动转换为时间点:
子集索引:
时间点的属性: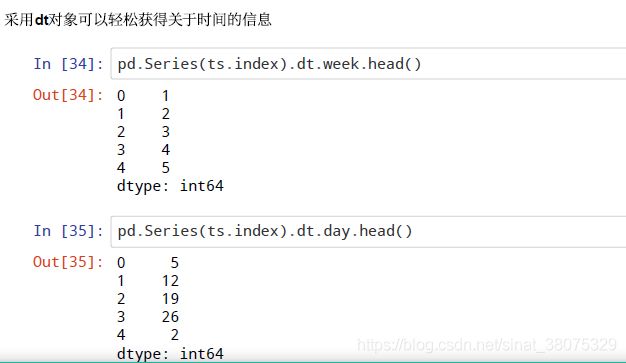
重采样:指resample函数,可以看作时序版本的groupby函数
10、综合练习
端午节的淘宝粽子交易
import pandas as pd
import numpy as np
df = pd.read_csv(r'data\Pandas(下)综合练习数据集\端午粽子数据.csv')
df.head()
#查看列名,去掉列名中为空的列
df.columns=[col.strip() for col in df.columns]
(1)请删除最后一列为缺失值的行,并求所有在杭州发货的商品单价均值
df1=df[df.发货地址.notnull()]df2=df1[df1.发货地址.str.contains('杭州')]
df2[~df2.价格.str.contains(r'^-?(\d+)(\.\d+)?$')]#.mean()
df2.价格.str.replace('_','').astype('float').mean()(2)商品标题带有“嘉兴”但发货地却不在嘉兴的商品有多少条记录?
df[df.标题.str.contains('嘉兴')][(df.发货地址.str.contains('嘉兴'))==False]
(3) 请按照分位数将价格分为“高、较高、中、较低、低”5 个类别,再将类别结果插入到标题一列之后,最后对类别列进行降序排序。
(4) 付款人数一栏有缺失值吗?若有则请利用上一问的分类结果对这些缺失值进行合理估计并填充。
(5) 请将数据后四列合并为如下格式的 Series:商品发货地为 ××,店铺为××,共计 ×× 人付款,单价为 ××。
(6) 请将上一问中的结果恢复成原来的四列。