【Python】Mac环境下爬取国内Android应用市场指定应用下载量
Mac环境Python配置
安转最新版 Python 3.6.4:Mac OS X 64-bit/32-bit installer
安装最新Mac版 PyCharm 2017.3.3
打开PyCharm,新建Project,新建Python File
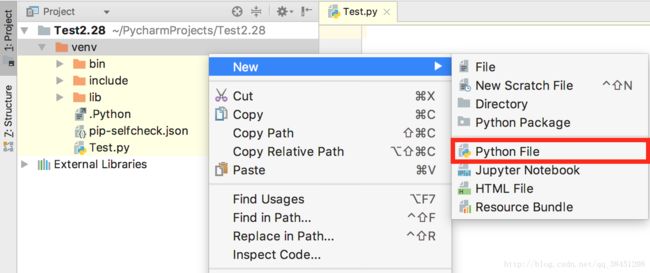
点击File/ Default Settings/ Project Interpreter/ 选择你当前的项目,然后选择”+”号(Install)
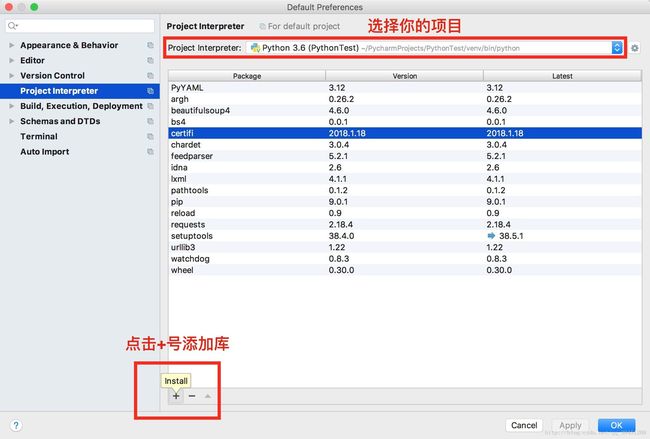
搜索并安装用于网页解析库BeautifulSoup的bs4和beautifulsoup4、HTTP库requests、网页解析库lxml以及用于正则表达式的re,关于正则表达式入门可以参考唯心不易博主的『Python 正则表达式入门(初级篇)』
应用搜索
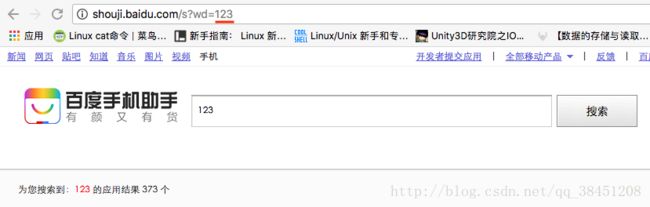
使用Chrome浏览器打开安卓应用市场页面,这里用百度手机助手举例,搜索栏中输入目标应用关键词,如『123』。
跳转后观察地址栏:
http://shouji.baidu.com/s?wd=123&data_type=app&f=header_software%40input,其实我们只需要http://shouji.baidu.com/s?wd=123,而末尾的『123』就是刚才搜索的关键词。
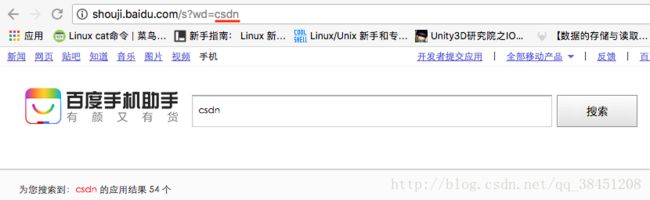
若只更改『123』为『CSDN』,页面就会跳转到『CSDN』的搜索结果:http://shouji.baidu.com/s?wd=CSDN,所以通过修改 = 号后面的变量(部分网站是 search/ 或 app/ ),我们可以快速获取相关搜索页面,这个变量我们取名为AppName。
最终,我们的搜索网址searchUrl为固定值http://shouji.baidu.com/s?wd= + AppName。部分网站链接稍微复杂,多搜索几次,找到不变的部分,修改剩余部分即可。
有了网址和关键词,我们可以初步编写脚本实现搜索功能:
#引入相关库
from bs4 import BeautifulSoup
import requests
import re
# 手动爬虫方法
def ManualCrawl():
# 交互式输入应用名作为参数
appName = input("please print app's name:")
# 输入完成后执行方法
CaculateDownloadTimes(appName)
# 传入搜索应用名
def CaculateDownloadTimes(AppName):
# 完整的搜索链接
searchUrl = 'http://shouji.baidu.com/s?wd=' + AppName
# 获取网页html码
htmlData = requests.get(searchUrl)
# 解析网页
soup = BeautifulSoup(htmlData.text, 'lxml')信息提取
搜索结果有了,怎么对结果进行分析呢?右击页面,点击『检查』,网页会出现一片区域(即上文注释中的html代码),像这样:
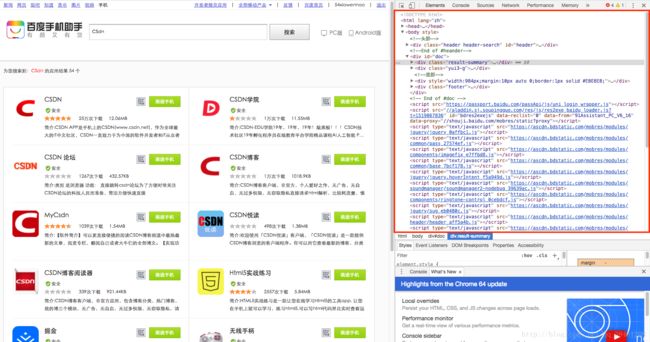
鼠标在红框区域内上下移动,可以发现左边会根据鼠标悬浮位置不同,高亮不同区域。我们找到第一个应用『CSDN』的名字所对应的html代码块:
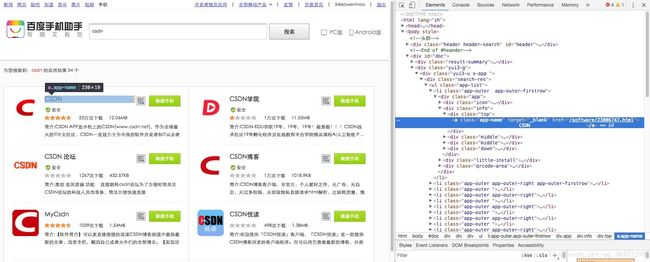
右击代码块 -> Copy -> Copy selector,可以得到应用名在html中的路径:”#doc > div.yui3-g > div > div > ul > li:nth-child(1) > div > div.info > div.top > a”,通过select方法我们可以得到第一个搜索结果的应用名firstRecordName :
firstRecordName = soup.select(
'body > div:nth-of-type(2) > div:nth-of-type(2) > div > div > ul > li:nth-of-type(1) > div > div:nth-of-type(2) > div:nth-of-type(1)')[
0].get_text().encode('latin1').decode('utf-8').strip()
print('firstRecordName: ' + firstRecordName)有以下几点需要注意:
- nth-child 要替换成 nth-of-type;
- 可以发现路径不尽相同,因为完全用 Copy selector 的路径可能会发生莫名的错误,这时候就需要手写路径:一般从 body 开始,然后若< a b >内的前半段a唯一,则直接写a即可;若不唯一,要写出其序列n,从1开始: a:nth-of-type(n);
- get_text方法是将select的soup[0]转换成str格式,有些网站需要先用 latin1 编码,再用 utf-8 解码才能正常显示。
示例代码
from bs4 import BeautifulSoup
import requests
import re
# 网上说可以绕过反爬虫,但是加了没啥效果,应用宝依旧显示无相关搜索内容
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko)'}
# 传入安卓市场名、搜索应用名
def DownloadTimes(MarketName, AppName):
# 木蚂蚁
if MarketName == 'mumayi' or MarketName == '木蚂蚁' or MarketName == 'ant':
searchUrl = 'http://s.mumayi.com/index.php?q=' + AppName
# 获取网页源码
htmlData = requests.get(searchUrl, headers=headers)
# print('content:' + htmlData.text)
# 解析网页
soup = BeautifulSoup(htmlData.text, 'lxml')
# 获取应用名字
try:
firstRecordName = soup.select(
'#allbody > div.main960.pos_rel > div.w670.fl > div:nth-of-type(2) > ul.applist > li:nth-of-type(1) > h3 > a:nth-of-type(1)')[
0].get_text().strip().split()[0]
# print('firstRecordName: ' + firstRecordName)
# 获取下载量
try:
times = soup.select(
'#allbody > div.main960.pos_rel > div.w670.fl > div:nth-of-type(2) > ul.applist > li:nth-of-type(1) > a.agray > ul > li.num')[
0].get_text()[5:-1] #[x:-y]表示: 切除掉从左往右x个字符,同时切除掉从右往左y个字符
print("'" + firstRecordName + "'" + "在'木蚂蚁'的下载量: " + times)
except:
print(MarketName + ' search error')
except:
print("在'木蚂蚁'中未找到与'" + AppName + "'相关的内容")
# *****************需要在获取下载量之前判断搜索结果*****************
# 乐商店
elif MarketName == 'lenovomm' or MarketName == '乐商店' or MarketName == 'le':
searchUrl = 'http://www.lenovomm.com/search/index.html?q=' + AppName
# 获取网页源码
htmlData = requests.get(searchUrl, headers=headers, verify=False)
# print('content:' + htmlData.text)
# 解析网页
soup = BeautifulSoup(htmlData.text, 'lxml')
try:
# 获取第一个搜索内容的名字
tip = soup.select('body > div.w1000.bcenter > p')[0].get_text()
# print(tip)
if tip == '抱歉,没有找到相关应用。':
print("'乐商店'没有找到相关应用")
# 终止程序
quit()
firstRecordName = soup.select(
'body > div.w1000.bcenter > div.border1.h-100.boxShadow.fl.searchAppsBox > ul > li:nth-of-type(1) > div.appDetails > p.f16.ff-wryh.appName > a')[
0].get_text().strip()
# print(firstRecordName)
# 获取下载量
try:
times = soup.select(
'body > div.w1000.bcenter > div.border1.h-100.boxShadow.fl.searchAppsBox > ul > li:nth-of-type(1) > div.appInfo.tcenter.pr > p:nth-of-type(1) > span')[
0].get_text()[:-3]
print("'" + firstRecordName + "'" + "在'乐商店'的下载量: " + times)
except:
print(MarketName + ' search error')
except:
print("在'乐商店'中未找到与'" + AppName + "'相关的内容")
# *******************需要latin1、utf-8解码*******************
# 智汇云
elif MarketName == 'zhihuiyun' or MarketName == '智汇云' or MarketName == 'huawei':
searchUrl = 'http://app.hicloud.com/search/' + AppName
# 获取网页源码
htmlData = requests.get(searchUrl, headers=headers)
# 解析网页
soup = BeautifulSoup(htmlData.text, 'lxml')
# 获取第一个搜索内容的名字
try:
firstRecordName = soup.select(
'body > div.lay-body > div.lay-main > div.lay-left.corner > div > div > div:nth-of-type(2) > div.game-info.whole > h4 > a')[
0].get_text().encode('latin1').decode('utf-8').strip()
# print(firstRecordName)
try:
times = soup.select(
'body > div.lay-body > div.lay-main > div.lay-left.corner > div > div > div:nth-of-type(2) > div.game-info.whole > div.app-btn > span')[
0].get_text().encode('latin1').decode('utf-8')
times = times.split('次')[0].split(':')[1]
print("'" + firstRecordName + "'" + "在'智汇云'的下载量: " + times)
except:
print(MarketName + ' search error')
except:
print("在'智汇云'中未找到与'" + AppName + "'相关的内容")
# ********************需要跳转2级页面获取下载量********************
# 当贝
elif MarketName == 'dangbei' or MarketName == '当贝':
searchUrl = 'http://www.dangbei.com/app/plus/search.php?kwtype=0&q=' + AppName
# 获取网页源码
htmlData = requests.get(searchUrl, headers=headers)
# print('content:' + htmlData.text)
# 解析网页
soup = BeautifulSoup(htmlData.text, 'lxml')
try:
# 获取第一个搜索内容的名字
firstRecordName = soup.select('#softList > li:nth-of-type(1) > div > div.softInfo > p.title > a')[
0].get_text().strip()
# 正则表达式找出抬头与红色关键词之间的跳转链接文本
# 正则表达式的运用可以参考这篇博客: https://www.cnblogs.com/chuxiuhong/p/5885073.html
pattern0 = re.compile(r'"")
linkUrls = pattern0.findall(htmlData.text)
# print(linkUrls[0])
# 获取二级页面链接
linkUrl = 'http://www.dangbei.com' + linkUrls[0].split()[1].split('"')[1]
# print(linkUrl)
# 进入二级页面,以获取下载量
htmlData = requests.get(linkUrl, headers=headers)
soup = BeautifulSoup(htmlData.text, 'lxml')
# 获取下载量
try:
times = soup.select(
'#softAbs > div.info > p:nth-of-type(4) > span.lInfo')[
0].get_text().encode('latin1').decode('utf-8').strip()
times = times.split(':')[1]
print("'" + firstRecordName + "'" + "在'当贝'的下载量:" + times)
except:
print(MarketName + ' search error')
except:
print("在'当贝'中未找到与'" + AppName + "'相关的内容")
# 输入有误,重新输入市场名
else:
print("input market's name error")
ManualCrawl()
# 手动输入
def ManualCrawl():
marketName = input("please print market's name:")
appName = input("please print app's name:")
# 输入完成后执行方法
DownloadTimes(marketName, appName)
# 各类数组
marketsArr = ['木蚂蚁', '乐商店', '智汇云', '当贝']
appsArr = ['A', '天', '3', '心']
exampleAppName = ['QQ', '微信', '王者荣耀', '抖音', '爱奇艺', '优酷']
# 自动检测, 以市场区分
def AutoCrawlUponMarkets():
# 设置计数器
count = 0
for marketName in marketsArr:
for appName in appsArr:
count = count + 1
DownloadTimes(marketName, appName)
if count >= len(appsArr):
print('------------------------------------------------------------')
count = 0
# 自动检测, 以应用名区分
def AutoCrawlUponApps():
# 设置计数器
count = 0
for appName in exampleAppName:
for marketName in marketsArr:
count = count + 1
DownloadTimes(marketName, appName)
if count >= len(marketsArr):
print('------------------------------------------------------------')
count = 0
# 更换方法名后Run
AutoCrawlUponApps()Git下载
包括”百度”、”360”等18个Android手机、TV应用市场。
DTHunter
存在的问题
乐视、应用宝、91、Google Play皆显示搜索失败。
若有建议或意见,欢迎大家与我交流!