高效大数据开发之 bitmap 思想的应用

作者:xmxiong,PCG 运营开发工程师
数据仓库的数据统计,可以归纳为三类:增量类、累计类、留存类。而累计类又分为历史至今的累计与最近一段时间内的累计(比如滚动月活跃天,滚动周活跃天,最近 N 天消费情况等),借助 bitmap 思想统计的模型表可以快速统计最近一段时间内的累计类与留存类。
一、背景
数据仓库的数据统计,可以归纳为三类:增量类、累计类、留存类。而累计类又分为历史至今的累计与最近一段时间内的累计(比如滚动月活跃天,滚动周活跃天,最近 N 天消费情况等),借助 bitmap 思想统计的模型表可以快速统计最近一段时间内的累计类与留存类。
二、业务场景
我们先来看几个最近一段时间内的累计类与留存类的具体业务问题,作为做大数据的你建议先不要急着往下阅读,认真思考一下你的实现方案:
1.统计最近 30 天用户的累计活跃天(每个用户在 30 天里有 N 天使用微视 app,N 为 1-30,然后将月活跃用户的 N 天加总)?
2.统计最近 7 天的用户累计使用时长?
3.统计最近 30 天有播放的累计用户数?
4.统计最近 30 天活跃用户有多少在最近 30 天里有连续 3 天及以上活跃?
5.统计 28 天前活跃用户的 1、3、7、14、28 天留存率?
三、传统解决方案
在进入本文真正主题之前,我们先来看看常规的解决思路:1.统计最近 30 天用户的累计活跃天?
--用dau表(用户ID唯一),取最近30天分区,sum(活跃日期)。
select
sum(imp_date) active_date
from
weishi_dau_active_table
where
imp_date>=20200701
and imp_date<=20200730
2.统计最近 7 天的用户累计使用时长?
--用dau表(用户ID唯一),取最近7天分区,sum(使用时长)。
select
sum(log_time) log_time
from
weishi_dau_active_table
where
imp_date>=20200701
and imp_date<=20200707
3.统计最近 30 天有播放的累计用户数?
--用用户播放表(用户ID唯一),取最近30天分区,count(distinct if(播放次数>0,用户ID,null))。
select
count(distinct if(play_vv_begin>0,qimei,null)) play_user
from
weishi_play_active_table
where
imp_date>=20200701
and imp_date<=20200730
4.统计最近 30 天活跃用户有多少在最近 30 天里有连续 3 天及以上活跃?
--用dau表(用户ID唯一),取最近30天分区,关联两次最近30天分区,关联条件右表分别为imp_date-1,imp_date-2。
select
count(distinct a.qimei) active_num
from
( select
imp_date
,qimei
from
weishi_dau_active_table
where
imp_date>=20200701
and imp_date<=20200730
)a
join --第一次join,先取出连续2天的用户,因为7月1日用户与7月2号-1天关联得上,表示一个用户在1号和2号都活跃
( select
date_sub(imp_date,1) imp_date
,qimei
from
weishi_dau_active_table
where
imp_date>=20200701
and imp_date<=20200730
)b
on
a.imp_date=b.imp_date
and a.qimei=b.qimei
join --第二次join,取出连续3天的用户,因为第一次join已经取出连续两天活跃的用户了,再拿这些7月1日用户关联7月3日-2天关联得上,表示一个用户在1号和3号都活跃,结合第一步join得出用户至少3天连续活跃了
( select
date_sub(imp_date,2) imp_date
,qimei
from
weishi_dau_active_table
where
imp_date>=20200701
and imp_date<=20200730
)c
on
a.imp_date=c.imp_date
and a.qimei=c.qimei
当然这里也可以用窗口函数 lead 来实现,通过求每个用户后 1 条日期与后 2 条日期,再拿这两个日期分布 datediff 当前日期是否为日期相差 1 且相差 2 来判断是否 3 天以上活跃,但是这个方法也还是避免不了拿 30 天分区统计,统计更多天连续活跃时的扩展性不好的情况 5.统计 28 天前活跃用户的 1、3、7、14、28 天留存率?
--用dau表(用户ID唯一),取统计天的活跃用户 left join 1、3、7、14、28天后的活跃用户,关联得上则说明对应天有留存。
select
'20200701' imp_date
,count(distinct if(date_sub=1,b.qimei,null))/count(distinct a.qimei) 1d_retain_rate
,count(distinct if(date_sub=3,b.qimei,null))/count(distinct a.qimei) 3d_retain_rate
,count(distinct if(date_sub=7,b.qimei,null))/count(distinct a.qimei) 7d_retain_rate
,count(distinct if(date_sub=14,b.qimei,null))/count(distinct a.qimei) 14d_retain_rate
,count(distinct if(date_sub=28,b.qimei,null))/count(distinct a.qimei) 28d_retain_rate
from
weishi_dau_active_table partition (p_20200701)a
left join
( select
datediff(imp_date,'20200701') date_sub
,qimei
from
weishi_dau_active_table
where
datediff(imp_date,'20200701') in (1,3,7,14,28)
)b
on
a.qimeib=b.qimei
四、传统解决方案存在的问题
1.每天大量中间数据重复计算,比如昨天最近 30 天是 8 月 1 日~ 8 月 30 日,今天最近 30 天为 8 月 2 日~ 8 月 31 日,中间 8 月 2 日~ 8 月 30 日就重复计算了。
2.统计逻辑复杂,类似业务场景 4,困难点在于统计每一天活跃的用户第二天是否还继续活跃。
3.耗费集群资源大,场景 4 和场景 5 都用到了 join 操作,场景 4 还不止一个 join,join 操作涉及 shuffle 操作,shuffle 操作需要大量的网络 IO 操作,因此在集群中是比较耗性能的,我们应该尽量避免执行这样的操作。
4.以上统计逻辑可扩展性差,由于数据分析经常进行探索性分析,上面传统方案能解决上面几个问题,但是数据分析稍微改变一下需求,就得重新开发,例如增加一个 15 天留存,或者统计最近 2 周的活跃天等。
五、bitmap 原理
上面的业务场景能否在一个模型表很简单就能统计出,且不需要数据重复计算,也不需要 join 操作,还能满足数据分析更多指标探索分析呢?答案是肯定的,可以借助 bitmap 思想。
何为 bitmap?bitmap 就是用一个 bit 位来标记某个元素,而数组下标是该元素,该元素是否存在时用 bit 位的 1,0 表示。比如 10 亿个 int 类型的数,如果用 int 数组存储的话,那么需要大约 4G 内存,当我们用 int 类型来模拟 bitmap 时,一个 int 4 个字节共 4*8 = 32 位,可以表示 32 个数,原来 10 亿个 int 类型的数用 bitmap 只需要 4GB / 32 = 128 MB 的内存。
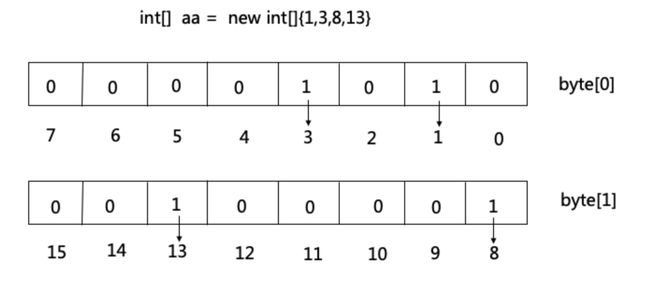
六、具体实现过程
大数据开发参考 bitmap 思想,就是参考其通过数组下标表示该元素的思想,将最近 31 天活跃用户是否活跃用逗号分隔的 0 1 串存储下来,将最近 31 天的播放 vv、赞转评等消费数也用逗号分隔的具体数值存储下来,形成一个字符数组,数组每一个下标表示距离最新一天数据的天数差值,第一位下标为 0,表示距离今天最新一天数据间隔为 0 天,如下所示:

active_date_set 表示 31 天活跃集,0 表示对应下标(距离今天的 N 天前)不活跃,1 表示活跃;这个数据是 8 月 23 日统计的,1,0,0,1,…… 即用户在 8 月 23 日,8 月 20 日有活跃,8 月 22 日,8 月 21 日并没有活跃。play_vv_begin_set 表示 31 天播放 vv 集,0 表示对应下标(距离今天的 N 天前)没有播放视频,正整数表示当天的播放视频次数;这里用户虽然在 8 月 23 日,8 月 20 日有活跃,但是该用户一天只播放了一次视频就离开微视了。这样做的好处一方面也是大大压缩了存储,极端状态下用户 31 天都来,那么就可以将 31 行记录压缩在一行存储。
假如 1 天活跃用户 1 亿,且这些用户 31 天都活跃,那么就可以将 31 亿行记录压缩在 1 亿行里,当然实际不会出现这样的情况,因为会有一部分老用户流失,一部分新用户加入,按照目前微视的统计可以节省 80%多的存储;另一方面可以更简单快捷地统计每个用户最近一个月在微视的活跃与播放、消费(赞转评)等情况。
该模型表的详细实现过程如下:
1.该模型表的前 31 天需要初始化一个集合,将第一天的数据写到该表,然后一天一天滚动垒起来,累计 31 天之后就得到这个可用的集合表了,也就可以例行化跑下去。
2.最新一天需要统计时,需要拿前一天的集合表,剔除掉相对今天来说第 31 天前的数据,然后每个集合字段将最后一位删除掉 。
3.拿最新一天的增量数据(下面用 A 表替代) full join 第 2 步处理后的前一天表(下面用 B 表替代)关联。
这里有三种情况需要处理:
a.既出现在 A 表,也出现在 B 表,这种情况,只需直接拼接 A 表的最新值与 B 表的数组集即可(在微视里就是最近 30 天用户有活跃,且在最新一天有留存);
b.只出现在 B 表(在微视里是最近 30 天活跃的用户在最新一天没留存),这时需要拿 “0,” 拼接一个 B 表的数组集,“0,” 放在第一位;
c.只出现在 A 表(在微视里是新用户或者 31 天前活跃的回流用户),这时需要拿 “1,”拼接一个 30 位长的默认数组集 “0,0,0,…,0,0” ,“1,” 放在第一位。经过如此几步,就可以生成最新一天的集合表了,具体脱敏代码如下:
select
20200823 imp_date
,nvl(a.qimei,b.qimei) qimei
,case
when a.qimei=b.qimei then concat(b.active_date_set,',',a.active_date_set)
when b.qimei is null then concat('0,',a.active_date_set)
when a.qimei is null then concat(b.active_date_set,',0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0')
end active_date_set
,case
when a.qimei=b.qimei then concat(b.log_num_set,',',a.log_num_set)
when b.qimei is null then concat('0,',a.log_num_set)
when a.qimei is null then concat(b.log_num_set,',0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0')
end log_num_set
,case
when a.qimei=b.qimei then concat(b.log_time_set,',',a.log_time_set)
when b.qimei is null then concat('0,',a.log_time_set)
when a.qimei is null then concat(b.log_time_set,',0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0')
end log_time_set
,case
when a.qimei=b.qimei then concat(b.play_vv_begin_set,',',a.play_vv_begin_set)
when b.qimei is null then concat('0,',a.play_vv_begin_set)
when a.qimei is null then concat(b.play_vv_begin_set,',0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0')
end play_vv_begin_set
from
( select
qimei
,substr(active_date_set,1,instr(active_date_set,',',1,30)-1) active_date_set
,substr(log_num_set,1,instr(log_num_set,',',1,30)-1) log_num_set
,substr(log_time_set,1,instr(log_time_set,',',1,30)-1) log_time_set
,substr(play_vv_begin_set,1,instr(play_vv_begin_set,',',1,30)-1) play_vv_begin_set
from
weishi_31d_active_set_table partition(p_20200822)a
where
last_time>=20200723
)a
full join
( select
qimei
,'1' active_date_set
,cast(log_num as string) log_num_set
,cast(log_time as string) log_time_set
,cast(play_vv_begin as string) play_vv_begin_set
from
weishi_dau_active_table partition(p_20200823)a
)b
on
a.qimei=b.qimei
初始化集合代码相对简单,只需保留第一位为实际数值,然后拼接一个 30 位的默认值 0 串,初始化脱敏代码如下:
select
20200823 imp_date
,qimei
,'1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0' active_date_set
,concat(cast(log_num as string),',0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0') log_num_set
,concat(cast(log_time as string),',0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0') log_time_set
,concat(cast(play_vv_begin as string),',0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0') play_vv_begin_set
from
weishi_dau_active_table partition(p_20200823)a
七、具体使用案例
在 hive 里对这些 0 1 集合串的使用是比较困难的,为了让这个模型表的可用性更高,因此写了几个 UDF 函数来直接对数组集合进行简单地运算,目前写了如下几个:str_sum()、str_count()、str_min()、str_max(),其中 str_sum、str_min、str_max 这几个函数的参数一样,第一个传入一个数组集合字符串,第二位传入一个整数,代表要计算最近 N 天的结果,第三个参数是传入一个分隔符,在本模型里分隔符均为逗号“,”。
这几个函数都是返回一个 int 值,str_sum 返回来的是最近 N 天的数值加总,str_min 返回该数组集合元素里最小的值,str_max 返回该数组集合元素里最大的值;str_count 前 3 个参数与前面三个函数一样,第 4 个参数是传入要统计的值,返回来的也是 int 值,返回传入的统计值在数组集合出现的次数,具体使用方法如下,由于是自定义函数,在 tdw 集群跑的 sql 前面需加@pyspark:
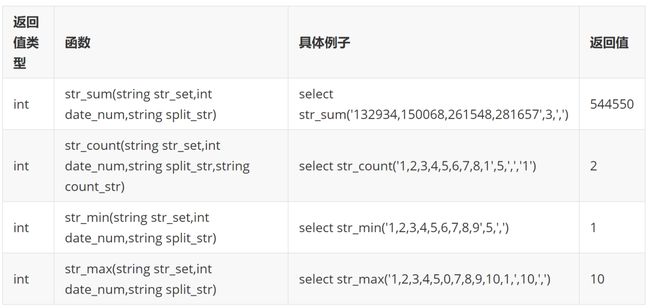
以上函数的具体使用案例脱敏代码如下:
@pysparkselect
qimei
,str_sum(active_date_set,30,',') active_date_num --每个用户最近30天活跃天数
,str_sum(play_vv_begin_set,30,',') play_vv_begin --每个用户最近30天播放视频次数
,30 - str_count(interact_num_set,30,',','0') interact_date_num --每个用户最近30天有互动的天数,通过 30 - 互动天数为0 统计得到
from
weishi_31d_active_set_table partition(p_20200823)a
where
last_time>20200724
当然除了上面几种 udf 统计所需指标之外,也可以通过正则表达式进行使用,比如统计活跃天可以这样统计:
--将数组集合里的'0'和','用正则表达式匹配去掉再来看剩下1的个数即可。
select
count(qimei) --月活
,sum(length(regexp_replace(substr(active_date_set,1,60),'0|,',''))) active_date_num --月活跃天
from
weishi_31d_active_set_table partition(p_20200823)a
where
last_time>20200724
开篇前的几个业务场景,也可以通过该表快速统计:1.统计最近 30 天用户的累计活跃天?
@pyspark
select
sum(active_date_num) active_date_num --滚动月活跃天
,count(1) uv --滚动月活
from
( select
qimei
,str_sum(active_date_set,30,',') active_date_num
from
weishi_31d_active_set_table partition(p_20200823)a
where
last_time>20200724
)a
2.统计最近 7 天的用户累计使用时长?
@pyspark
select
sum(log_time) log_time --滚动周活跃天
,count(1) uv --滚动周活
from
( select
qimei
,str_sum(log_time_set,7,',') log_time
from
weishi_31d_active_set_table partition(p_20200823)a
where
last_time>20200817
)a
3.统计最近 30 天有播放的累计用户数?
@pyspark
select
count(1) uv --播放次数>0
from
( select
qimei
,str_sum(play_vv_begin_set,30,',','0') play_vv_begin
from
weishi_31d_active_set_table partition(p_20200823)a
where
last_time>20200724
)a
where
play_vv_begin>0
4.统计最近 30 天活跃用户有多少在最近 30 天里有连续 3 天及以上活跃?
--只是判断活跃集合里面有连续3位 1,1,1, 即可select
count(if(substr(active_date_set,1,60) like '%1,1,1,%',qimei,null)) active_date_num
from
weishi_31d_active_set_table partition(p_20200823)a
where
last_time>20200724
5.统计 28 天前活跃用户的 1、3、7、14、28 天留存率?
--不需要join操作,只需找到活跃日期集对应位是否1即可select
'20200723' imp_date
,count(if(split(active_date_set,',')['29']='1',qimei,null))/count(1) 1d_retain_rate
,count(if(split(active_date_set,',')['27']='1',qimei,null))/count(1) 3d_retain_rate
,count(if(split(active_date_set,',')['23']='1',qimei,null))/count(1) 7d_retain_rate
,count(if(split(active_date_set,',')['16']='1',qimei,null))/count(1) 14d_retain_rate
,count(if(split(active_date_set,',')['2']='1',qimei,null))/count(1) 28d_retain_rate
from
weishi_31d_active_set_table partition(p_20200823)a
where
last_time>20200723
and split(active_date_set,',')['30']='1'
八、总结
从上面 5 个业务场景可以看出来,只要有这样一个借助 bitmap 思想统计的模型表,不管统计最近一段时间的累计(月活跃天、月播放用户等)与统计 1 个月内的留存,都可以一条简单语句即可统计,不需要 join 操作,每天例行化跑时不需要重复跑接近一个月的分区,1 个月内可以支持任意统计,比如只需最近 2 周的活跃天等,因此这样的模型相对通用,另外如果业务需要用到 2 个月的数据,也可以将模型从 31 位扩展到 61 位。
当然任何事情不可能只有优点,而不存在缺点的情况,这里这个优化的模型只是参考了 bitmap 思想,并不是 bitmap 方案实现,虽然可以将 31 天活跃用户压缩 80%多存储,但是每天都存储 31 天活跃用户的压缩数据,因此相比之前只保留天增量表来说,还是增加了实际存储空间,但是这个以存储换计算的方案是符合数仓设计原则的,因为计算是用成本昂贵的 cpu 和内存资源,存储是用成本低廉的磁盘资源,因此有涉及最近 N 天累计或者留存计算需求的朋友可以借鉴这样的思路。