spark基础概念及实验
RDD 可伸缩不可改变分布式集合,缓存进内存,每次转换生成新的RDD,因此有依赖关系,丢失后可恢复;指定partition个数,分到cpu中,每个partition被一个任务处理,对于key-value的RDD存在分片函数,存在一个列表存储分片的位置
对RDD的创建,转换,返回;创建后不可改变,对外部的HDFS或List操作,转换时生成新的RDD,直到action时才计算,返回driver程序或外部存储
task,stage,shuffle,依赖,DAG即是RDD的依赖关系
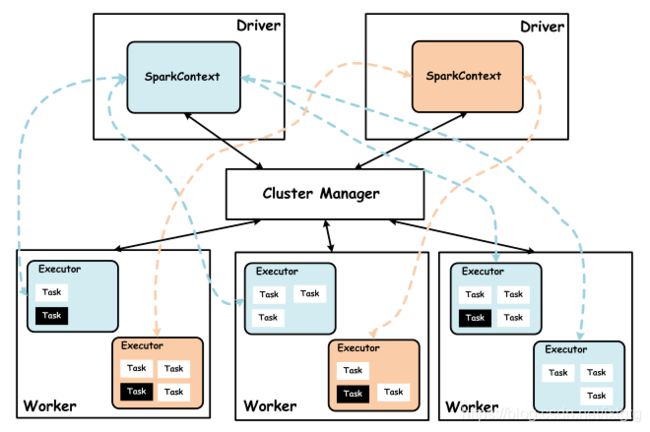
Spark 集群由集群管理器 Cluster Manager、工作节点 Worker、执行器 Executor、驱动器 Driver、应用程序 Application 等部分组成 https://www.jianshu.com/p/bd53509dc237
application由driver执行连接到集群管理器,使用SparkAPI。driver运行main函数,执行sparkContext,生成DAG并且协调资源,发送task到executor。executor是运行在worker上的进程,运行task,worker同步资源信息到资源管理器。
- Spark Core:Spark的核心功能实现,包括:
- 基础设施:Spark 中有很多基础设施,被 Spark 中的各种组件广泛使用,这些基础设施包括 SparkConf、Spark 内置 RPC 框架、事件总线 ListenerBus、度量系统。
- SparkConf 用于管理Spark应用程序的各种配置信息。
- Spark 内置 RPC 框架 使用 Netty 实现,有同步和异步的多种实现,Spark 各个组件间的通信都依赖于此 RPC 框架。
- 事件总线是 SparkContext 内部各个组件间使用事件——监听器模式异步调用的实现。
- 度量系统由Spark中的多种度量源(Source)和多种度量输出(Sink)构成,完成对整个Spark集群中各个组件运行期状态的监控。
- SparkContext:SparkContext 是 Spark 的入口,Spark 程序的提交与执行离不开 SparkContext。它隐藏了网络通信、分布式部署、消息通信、存储体系、计算引擎、度量系统、文件服务、Web UI 等内容,开发者只需要使用 SparkContext 提供的 API 完成功能开发。
- SparkEnv:Spark 执行环境。SparkEnv 内部封装了 RPC 环境(RpcEnv)、序列化管理器、广播管理器(BroadcastManager)、map任务输出跟踪器(MapOutputTracker)、存储体系、度量系统(MetricsSystem)、输出提交协调器(OutputCommitCoordinator)等Task运行所需的各种组件。
- 存储体系:它优先考虑使用各节点的内存作为存储,当内存不足时才会考虑使用磁盘,这极大地减少了磁盘 I/O,提升了任务执行的效率,使得 Spark 适用于实时计算、迭代计算、流式计算等场景。Spark 的内存存储空间和执行存储空间之间的边界是可以控制的。
- 调度系统:调度系统主要由 DAGScheduler 和 TaskScheduler 组成。DAGScheduler 负责创建 Job、将 DAG 中的 RDD 划分到不同的 Stage、给 Stage 创建对应的 Task、批量提交 Task 等功能。TaskScheduler 负责按照 FIFO 或者 FAIR 等调度算法对批量 Task 进行调度。
- 计算引擎等:计算引擎由内存管理器、任务内存管理器、Task、Shuffle 管理器等组成。
- 基础设施:Spark 中有很多基础设施,被 Spark 中的各种组件广泛使用,这些基础设施包括 SparkConf、Spark 内置 RPC 框架、事件总线 ListenerBus、度量系统。
- Spark SQL:提供SQL处理能力,便于熟悉关系型数据库操作的工程师进行交互查询。此外,还为熟悉 Hive 开发的用户提供了对 Hive SQL 的支持。
- Spark Streaming:提供流式计算处理能力,目前支持 Apache Kafka、Apache Flume、Amazon Kinesis 和简单的 TCP 套接字等多种数据源。此外,Spark Streaming 还提供窗口操作用于对一定周期内的流数据进行处理。
scala> val file = sc.textFile("/spark/hello.txt")读取文件RDD,本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
scala> val array = Array(1,2,3,4,5)
array: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val rdd = sc.parallelize(array)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[27] at parallelize at
Spark支持两个类型(算子)操作:Transformation和Action https://www.cnblogs.com/qingyunzong/p/8899715.html
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class SparkWordCountWithJava7 {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("WordCount");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD
JavaRDD
@Override
public Iterator
return Arrays.asList(line.split(",")).iterator();
}
});
JavaPairRDD
@Override
public Tuple2
return new Tuple2<>(word, 1);
}
});
JavaPairRDD
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
JavaPairRDD
@Override
public Tuple2
return new Tuple2<>(tuple._2, tuple._1);
}
});
JavaPairRDD
JavaPairRDD
@Override
public Tuple2
return new Tuple2<>(tuple._2, tuple._1);
}
});
resultRDD.saveAsTextFile("E:\\result7");
}
}
窄依赖:是指每个父RDD的一个Partition最多被子RDD的一个Partition所使用,例如map、filter、union等操作都会产生窄依赖;(独生子女)
宽依赖:是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖;(超生)
Hadoop中MapReduce操作中的Mapper和Reducer在spark中的基本等量算子是map和reduceByKey;不过区别在于:Hadoop中的MapReduce天生就是排序的;而reduceByKey只是根据Key进行reduce,但spark除了这两个算子还有其他的算子;
日志分析 https://blog.csdn.net/love__live1/article/details/84860872