(DPRL+GCNN读书笔记)Deep Progressive Reinforcement Learning for Skeleton-based Action Recognition
(DPRL+GCNN读书笔记)Deep Progressive Reinforcement Learning for Skeleton-based Action Recognition
- 1.摘要
- 2.引言
- 3.相关工作
- 3.1Skeleton-based Action Recognition
- 3.2Deep Reinforcement Learning
- 4. Approach
- 4.1GCNN
- 4.11图卷积
- 4.2Deep Progressive Reinforcement Learning(深度递进强化学习)
- 5.实验
论文的特点:就是使用了DPRL方法,在全部的帧中挑选出了更重要的帧;使用更重要的帧进行识别。
1.摘要
总结一下,首先作者在摘要中解释了贯穿全文的一个概念DPRL(Deep Progressive Reinforcement Learning:深度递进强化学习)。这也是这篇文章的亮点之一。作者解释了这个理论的作用:提取出包含信息量大的帧,丢弃序列中信息量小的帧。
由于每个视频的代表性帧的选择是众多的,作者将帧的选择建模为一个渐进的过程。在深度强化学习中,作者通过两个重要因素逐步调整选择的帧:1)所选帧的重要程度。2)所选帧与整个视频之间的关系。
然后在使用图卷积神经网络,和大部分论文的思路一样,将关节看成图中的结点,将骨骼看成图中的边。
2.引言
简单介绍了由于姿态估计等算法的飞速发展,骨架数据越来越容易获取。所以数据驱动的方法盛行,深度学习得到跨越性的进步。简单介绍了RNN对时间建模能力很强,CNN很容易捕捉相邻帧之间的关系;但大多数CNN算法考虑了视频中的所有帧,并不能将注意力集中在重要的帧上。 作者举了个例子:有一些画面中,主体是直立的,还有一些画面中,主体是站着的。演示者进行踢腿动作,后者对于识别这种行为更有帮助。这也说明将“注意力”集中在关键帧的重要性。
为了寻找序列中信息量最大的帧,作者提出了一种深度递进强化学习(DPRL)方法。因为选择的不同,每个视频的帧数太多,作者将帧的选择过程建模为一个渐进的过程。具体地说,给定初始化的帧从输入序列中均匀采样,逐步调整,每个状态下根据两个重要因素选择帧。一个是所选帧对于动作识别的识别能力。二是所选帧与整个动作序列的关系。
然后就是根据关节和骨骼构造图,使用GCNN进行动作识别
3.相关工作
3.1Skeleton-based Action Recognition
1.传统方法(翻译)
1)Vemulapalli将人体骨骼表示为Lie群中的一个点,并在Lie代数中实现时间建模和分类。
2)Weng 将Naive-Bayes最近邻(NBNN)方法[25]扩展到时空NBNN,并利用阶段到类别的距离对行为进行分类
3)Koniusz 用两个基于核的张量表示来捕捉两个动作序列之间的兼容性和单个动作的动态信息
4)Wang等人提出了一种无向完全图表示,并提出了一种新的图核来度量图之间的相似性。并且作者使用这种图结构表示来对视频进行建模,并且作者用这种图结构捕捉人体的拓扑结构。
2.深度学习(翻译)
2.1基于CNN
1)Liu等人将骨骼转化为一系列彩色图像,并将其输入CNN架构中进行动作分类。
2)Li等人采用了双流CNN架构来结合人体关节的位置和速度信息。不同于基于cnn的所有帧都被平等对待的方法,本文的方法旨在找到视频中最有信息的帧进行动作识别。
2.2基于RNN
1)Zhu等人提出了一种用于共现特征学习的正则化LSTM模型。
2)Song等人提出了一个时空注意模型,将不同的权重分配给视频中的不同帧和节点。
3)Liu等人提出了一个信任门模块来解决骨骼数据中的噪声问题。
4)Jain等人将RNN与时空图相结合,对人体运动的三个部分(脊柱、手臂和腿)之间的关系进行了建模。与Jain不同的是,作者的图模型将人体的每个关节作为一个顶点,这是利用基于骨骼的数据的一种更好的方式。
3.2Deep Reinforcement Learning
大概意思就是说深度强化学习在近些年发展非常迅速,在各个领域都有了相关的应用。但是在基于骨骼数据的动作识别中,应用还是相对较少。
4. Approach
作者给了一张关于此项工作整个流程的pipline的图:
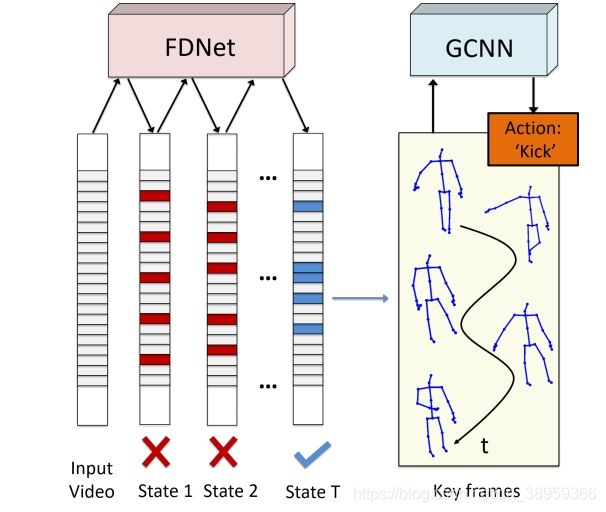 作者提出,工作中有两个子网络:
作者提出,工作中有两个子网络:
1)frame distillation network (FDNet)
目标是从输入序列中提取固定数量的关键帧,采用深度渐进强化学习方法。
2)graph-based convolutional network (GCNN)
根据人类关节之间的依赖关系将FDNet的输出组织成图结构,并将其输入到GCNN中以识别动作标签。
4.1GCNN
接下来论文中给出了一张“拍手”的人体骨骼结构的示意图:
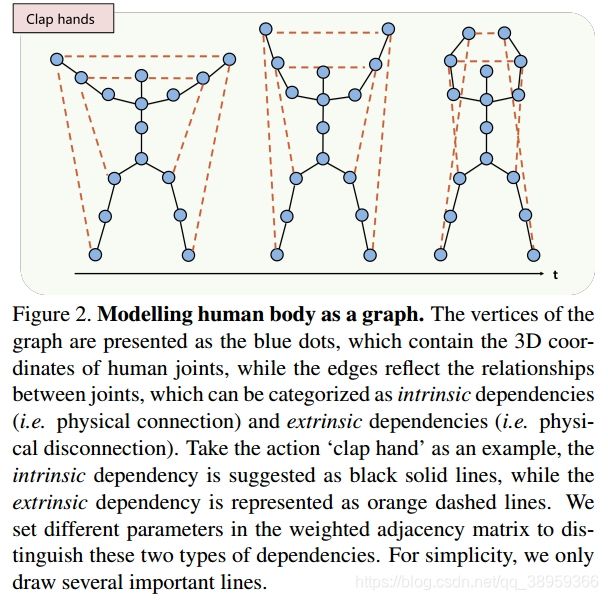 这里作者将关节点之间的连接关系分为两种类型:**内连接和外连接。**正如图中所示,蓝色部分关节点被称为内部连接;橙色部分被称为外连接。不同的连接类型对应着不同的权重,数学描述如下:
这里作者将关节点之间的连接关系分为两种类型:**内连接和外连接。**正如图中所示,蓝色部分关节点被称为内部连接;橙色部分被称为外连接。不同的连接类型对应着不同的权重,数学描述如下:

说明:
1)自连接为0
2)i与j为身体上的连接,即内连接用α来表示权重。
3)i与j为外部连接,用β来表示权重。
接下来就是常见的图卷积操作了:
![]()
其中:1)t表示是视频中的某一帧
2)y(η, W)是卷积核
3)*为卷积运算符
作者将输出得到的feature map结果 输入全连接层得到输出 g t g_t gt,一个视频中的不同帧连接构成了3D的tensor (张量):G:
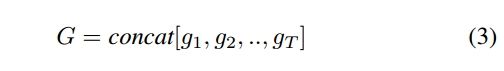
最后将张量G送入传统的CNN进行动作识别。我们采用Cross-entropy作为loss。
4.11图卷积
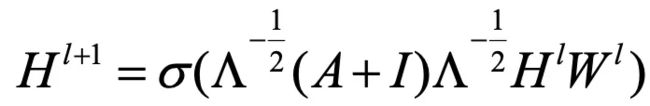
对于图卷积网络,这是最基本的公式。 D D D这个符号代表的是度矩阵。
L = I n − D − 1 / 2 W D − 1 / 2 L=I_n-D^{-1/2}WD^{-1/2} \\ L=In−D−1/2WD−1/2
度矩阵的定义如下:
D : d i i = ∑ j w i j D:d_{ii}=\sum_jw_{ij} \\ D:dii=j∑wij
使用基于图的拉普拉斯进行归一化:
L ∼ = 2 L / λ m a x − I n x ‾ k = T k ( L ∼ ) ∗ x L^\sim= 2L/λ_{max }− I_n \\ \overline{x}_k = T_k(L^\sim) ∗ x L∼=2L/λmax−Inxk=Tk(L∼)∗x
λmax是L的最大特征值,Tk是切比雪夫多项式
最后图卷积运算定义如下:
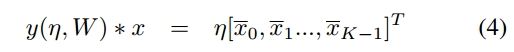
η ∈ [η0, η1…, ηK−1]是需要训练的参数,K是卷积核的大小。
4.2Deep Progressive Reinforcement Learning(深度递进强化学习)
这一小节也是整篇论文的一个很大的亮点
对于骨骼视频中的动作识别任务,并非每一帧都具有同等的重要性。这是我们应用基于强化学习的注意力机制的关键。
这其实可以描述为一个马尔可夫决策过程(MDP)。大致过程如下图所示:
学习笔记:其实这里直白的说所要实现的事情就是从视频所有帧中挑选出包含着重要信息的关键帧。对关键帧做出以后对操作。这也是我们所说注意力机制。
基于这个思想,对图中做出简单解释。首先刚开始对时候,通过随机抽样对方法抽样出部分帧。经过逐步调整,我们得到了视频中信息量最大的帧。
接下来对这个逐步调整对过程进行说明:
这整个过程是基于 frame distillation network (FDNet)。其实现如下图所示:
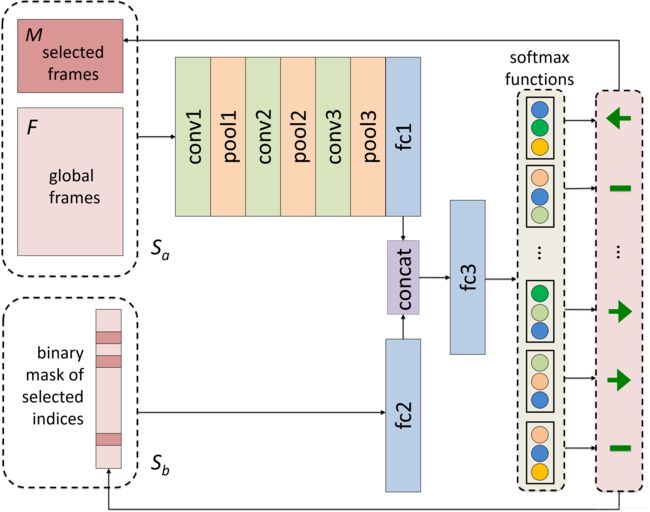
1)Sa由已经选择的帧M和全部帧F两个部分组成
2)Sb由一个对于选择帧二进制的MASK组成。已经被选择了,设置为1;未被选择设置为0
可以看出,该网络有两个入口:
a)将Sa输入第一个入口,结果三个卷积层和一个全连接层得到输出的feature map
b)将Sb输入第二个入口,经过一个全连接层得到输出。
c)将a,b输出输入全连接层。得到我们的 action
action的说明在下面,
States:
引入M是为了隐式地向FDNet说明哪些帧被选择。Sb是所选索引的二进制Mask,其设计目的是显式地使FDNet知道哪些帧被选择。它是一个f维向量,其中m个元素为1,其余元素为0。这里我们设f = 100, m = 30
Actions:其实就是FDNET的输出,其实action就是一个指令。每一个关键帧对应一个action。对所选对关键帧对集合,根据action来修改关键帧的选择。这就是之前所提到的逐步调整。action存在三种类型:
action0:向左转移
action1:维持原样
action2:向右转移
刚开始的转移步长设为1
Ai,j∈[0,1]表示第i个选中帧选择动作j的概率
Rewards:
使用预先训练的GCNN生成Rewards,它将视频的m个选定帧作为输入(作者设置T = m)。
对于第一次迭代,如果预测正确,r被设置为1,否则为- 1。对于第n次迭代(n > 1),首先定义r0奖励如下:
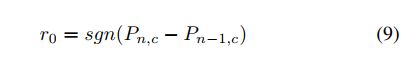
c为视频的ground truth标签,Pn,c表示第n次迭代时预测视频为class c的概率。选择这个函数通过概率变化来增强奖励。并且文中还提出来强刺激(在一次迭代之后,预测的操作从不正确变为正确)和强惩罚(在一次迭代之后,预测的操作从正确变为不正确),数学表示如下:

注:可能存在的问题及解决方法
1)对于不完全是f帧长的视频,作者使用双三次插值生成出f帧长的视频。
2)存在一个很关键的问题:频繁的执行action无法保证selected帧集合的顺序。论文中给出的解决方法是:设置界限函数。
上界函数:

下界函数:
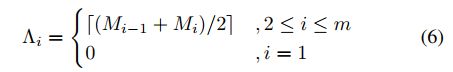
Υ 和 Λ是两个大小为m的数组。对选择帧对调整应该在 [Λi, Υi)范围内。也可以写成:
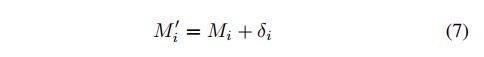
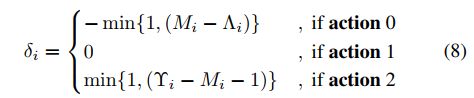
总结一下整个算法流程图如下:

5.实验
简单展示了一下结果:
在NTU数据集,结果如下:
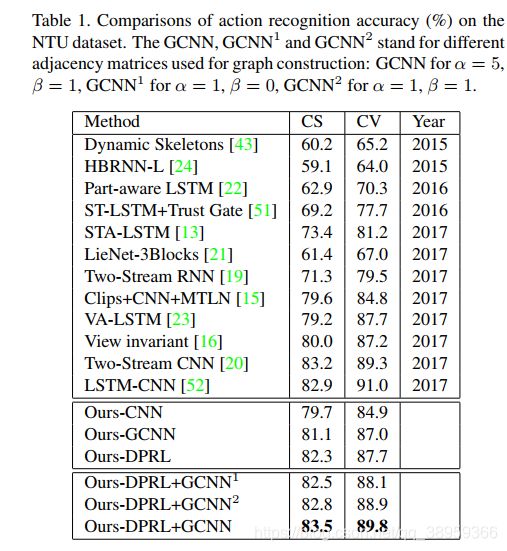
在SYSU数据集,结果如下:

在UT数据集,结果如下:
