【论文精读】Noiseprint: a CNN-based camera model fingerprint
paper:https://ieeexplore.ieee.org/document/8713484
开源代码:https://github.com/grip-unina/noiseprint
文献分类
- 基于semantic或者physical不连续性
- 像素级的统计方法
- model-based approach
- 目的:建立针对某些特征的数学模型
- 缺点:每一种方法的适用范围都较窄
- 包括:lens aberration,camera response function,color filter array(CFA),JPEG artifacts
- data-driven approach
- 目的:使用大规模样本进行算法训练
- 在所有的方法中,依赖photo-response non-uniformity(PRNU)的算法是比较流行的,并且性能较好。
- noise residual还可以用于异常检测发现局部图像篡改中【25-28】
- 大多数data-driven方法作用于noise residual,将图片减去denoising算法得到的图像估计或者空域/频域高通滤波【19-24】得到
- model-based approach
PRNU pattern: device fingerprint
在文献【30】中,作者显示每一个独立的设备对其所有照片上留有一个独特的mark,也就是PRNU模式。这是由于设备加工过程中的不完美性导致的。
由于PRNU的唯一性和稳定性,其被用于设备指纹(device fingerprint),并被用于图片伪造检测任务中。
- source identification【31】
- image forgery detection and localization【30】【32-35】
缺点:
- 一个camera需要大量图像才能提取较好的PRNU估计
- 如果图像中内容比较模糊(相对noise),则也会大大影响PRNU的提取
Noiseprint: camera model fingerprint
为了解决PRNU的问题,作者提出了一种新的提取noise residual的方法。
目标:
- 增强语义内容的提取,同时强化所有的相机相关的artifacts
- 没人先验知识,没有标注样本
原理:
- 采用Siamese Network的理念,使用相同或不同相机的images进行配对训练。
- 一旦训练完成,网络参数固定,用于对任意相机model拍摄的images,不论该model是否在训练集中。
- 因此,本方法是完全无监督的,被认为是camera model fingerrint。
需要注意的是,图像篡改将在noiseprint中留下明细的痕迹,因而可以只是定位篡改的部分。
noiseprint抽取过程
目标:

事实上,目的是从原始图像中减去高层次的场景内容,这些内容被认为是抽取noiseprint的干扰。这也是CNNbased的降噪器的目标【59】。通过【59】可以作为新系统的起点,并且将其得到的最有参数作为新系统的初始参数使用。然后,再在训练过程中更新这些参数。
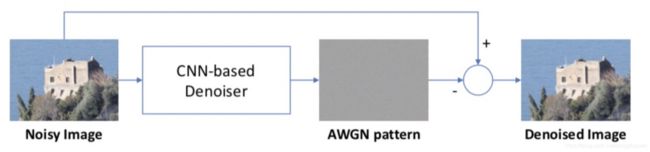
在【59】中,使用有监督的方式来训练CNN网络,其输入是噪声图像,输出是噪声。如图4所示。在本文中,使用该结构时,输入是一个一般的图像,输出是noiseprint。但是,问题是我们没有noiseprint的生成模型,因此,我们无法得到图4中的output patch。

核心改进:
- 考虑到,从同一个camera model得到的image patches应该具有相似的noiseprint patches,从不同camera model得到的image patches具有不同的noiseprint patches。
- 因此,需要训练一个noise residual生成网络,不仅使得场景内容被消除,同时也使得所有的不可区分信息(camera model之间)被消除,而可区分信息被加强。
- 于是考虑到如下的Siamese网络结构,该机构中有两个并行且完全一致(相同结构和参数)的CNNs。需要注意的是,负样本和正样本是一样重要的,它们使得网络丢弃无用的信息(所有model公共的),只在noiseprint中保持最有区分度的特征。
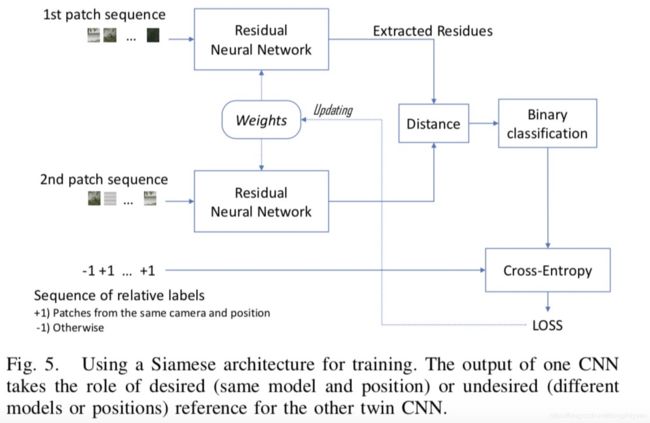
网络训练的细节
1)初始化
【59】中的CNN结构:
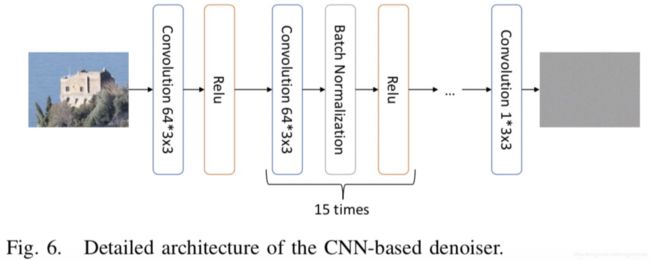
考虑到复杂度问题,该CNN网络使用minibatch进行训练N=200,每个image patch是48*48。需要强调的是,该CNN是fully卷积,因此,一旦训练好后,可以用于任意大小的输入图像,不仅仅是48*48
2)boosting minibatch information
Siamese结构只是用于展示说明,实际训练的只有一个CNN。在每个minibatch中,包括了200个patches,用于形成合适的输入输出对。因此,每个minibatch提供了O(N^2)个样本用于训练,大大提升了训练速度。如果两个patch来自同一个model,则为正label,否则为负label。为了执行上述策略,我们的minibatch包含了50个组,每个组包含4个patches。每个组是相同model+相同位置。
3)Distance-based logistic loss
最小化如下的目标函数:
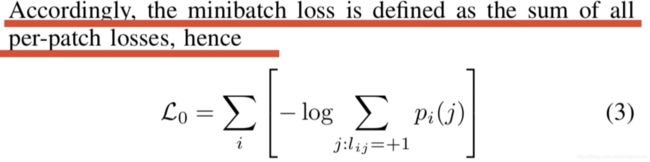
其中,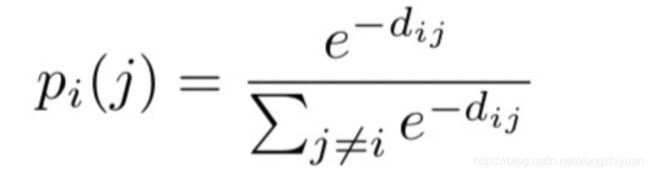

4)Regularization
为了保持noiseprint之间的差异性(上述L0会使得不同model之间趋于一致),使用2D离散傅立叶变换。给定一个camera model,其功率谱的尖峰在于artifacts的基础频率处以及它们的组合处。而对于不同的camera models,期望它们的功率谱峰值在不同地方。考虑到峰值位置是重要的区分性特征,因此,期望对于一个minibatch在所有频率上能够均匀分布。
故而,使用minibatch的PSD的几何均值于算术均值作为新的惩罚项:
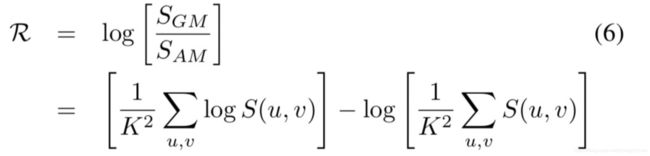
其中,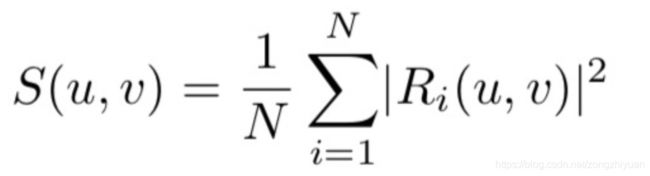
是minibatch的功率谱密度PSD。
最终,整个损失函数是:
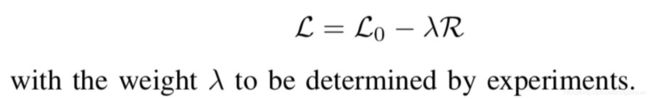
实验结果分析
主要研究noiseprint在image manipulation location上的性能。
A. 基于noiseprint的Forgery localization
自动化定位工具,用于后续的检测能力分析使用。该工具以原始图像和它的noiseprint作为输入,输出一个real-valued热力图,该图中每个像素值表示其被篡改的概率。
因此,使用【28】中的盲定位算法,其中将noiseprint代替了3阶图像residual方法。
参考代码:
https://github.com/grip-unina/noiseprint/blob/master/noiseprint/post_em.py
B. 参考的方法
为了保持与noiseprint方法一致,只考虑blind方法,即不需要特殊的数据集用于训练或者fine tuning,也不需要使用测试集的metadata或者先验知识。
根据它们使用的特征,这些方法可以大致分为3类:
- JPEG artifacts【60-64】,【16】
- CFA artifacts【13】【14】
- 特征空域分布的非连续性【65】【26】【66】【27】【28】【58】
https://github.com/MKLab-ITI/image-forensics
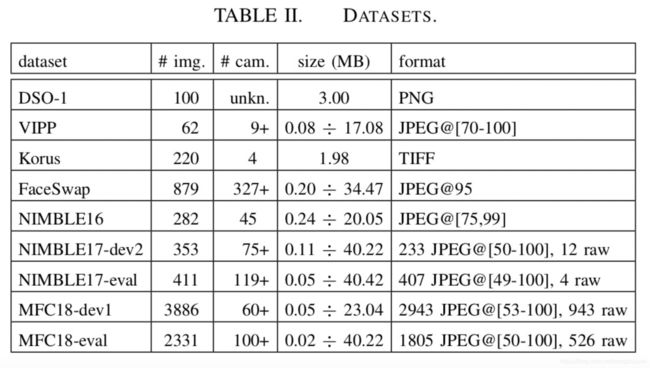
C. 数据集
使用了如下9个数据集:
D. 性能衡量标准
Forgery localization可以被认为是一个二分类问题,即每个像素属于正常或者伪造两种情况。
1)整体准确率
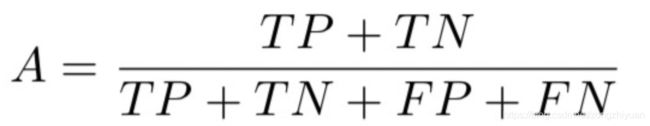
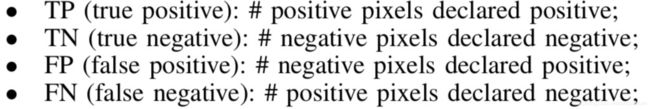
2)精度、召回和F1
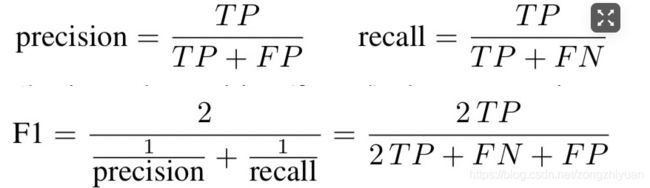
3)Matthews Correlation Coefficient(MCC)
决策面与ground truth的交叉相关系数:
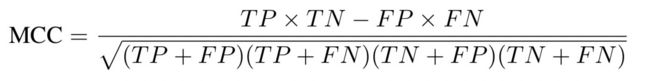
对类别不平衡的情况是robust的。
4)Average Precision(AP)
由precision-recall曲线的面就计算得到,因此可以衡量所有检测阈值下的平均性能。
E. 训练过程
构造一个数据集,包括相机和手机,包括:
- Dresden数据集中44个cameras【68】
- Socrates数据集中32个cameras【69】
- VISION数据集中32个cameras【70】
- 自己提供的数据集包含17个cameras
上述一共是125个独立的cameras,涉及70个不同的models以及19个品牌。为了进行实验,划分为你训练和验证集,分别包含100和25个cameras,并且保证这些数据不包含在测试阶段。所有images是JPEG形式。
网络使用denoising算法【59】的结果进行初始化。在训练过程中,每个minibatch包含200个48*48的patches,这些patches来自25个不同cameras拍摄的100个不同images。在每个minibatch中,包含了50个组,每组有相同camera和位置的4个patches组成。
F. 实验结果
尽管每个实验中,数值变化很大,每个方法的相对排名几乎是一致的。在表III-V中分别展示了MCC、F1和AP衡量指标下不同方法的性能。具体分析见arXiv论文。