腾讯民汉翻译征战全国机器翻译大赛夺得双冠

导语 :一年一度的全国机器翻译大赛(CCMT 2019)于7月20日公布了比赛结果,来自TEG的腾讯民汉翻译团队自去年拿下英汉翻译冠军之后,再一次载誉而归。团队经过多日奋战,最终在30个参赛单位的角逐中脱颖而出,以绝对优势获得三个民族语种中“维吾尔-汉"、“蒙古-汉”任务冠军。而在一个月前国家部委举办的企业级机器翻译系统评测(非受限数据集)中,腾讯民汉翻译团队参加了两个项目,获得了藏语-汉语冠军,维吾尔语-汉语亚军的成绩,这些成绩彰显了腾讯在民族语言技术领域的核心竞争力。
第十五届全国机器翻译大赛(China Conference on Machine Translation,CCMT2019)由中国中文信息学会主办,旨在为国内外机器翻译界同行提供一个平台,加强国内外同行的学术交流,促进中国机器翻译事业,迄今为止已连续成功召开十四届。CCMT不仅是国内机器翻译领域最具影响力、最权威的学术和评测活动,而且也代表着汉语与民族语言翻译技术的最高水准,对民族语言技术发展具有重要意义。
长风破浪会有时,维蒙双冠出镜心
在本次大赛中,参赛队伍的数量再创新高,包括NICT、中科院自动化所、中科院计算所、北大、北航、上交大、华为、OPPO等30多个国内外知名高校和企业;尤以CCMT每年的特色项目——中国的三大少数民族语种维吾尔语,藏语和蒙古语三个方向的翻译任务竞争最为激烈。这次腾讯民汉翻译团队只参加了这三个项目,并且顶住压力,在维吾尔语-汉语,蒙古语-汉语任务中获得冠军,超越了去年的成绩。此次比赛为受限数据集,即必须使用组委会提供训练数据,这也就意味着,参赛各个单位必须以技术进行实力的角逐。
而在较早前,腾讯民汉翻译团队与腾讯翻译君团队强强联手,在国家部委举办的企业级机器翻译系统评测(非受限数据集)中,代表腾讯公司取得总成绩第一。其中腾讯民汉翻译团队参加了两个项目,最终结果为藏语-汉语冠军,维吾尔语-汉语亚军。而翻译君团队则获得了俄、法、韩、越、英等语种的前二名,为公司争取了荣誉。
下表列出本次CCMT大赛维吾尔语到汉语前10名系统得分情况:
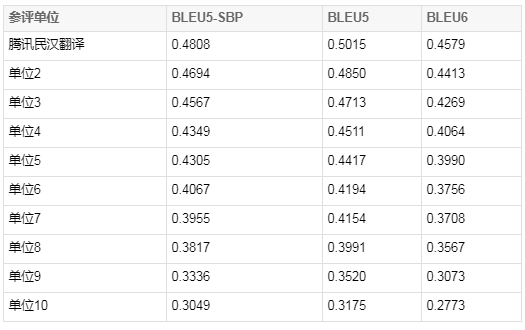
Fig.1 CCMT 2019 维汉评测主系统评测结果(仅列出前10)
下表列出本次CCMT大赛蒙古语到汉语前10名系统得分情况:

Fig.2 CCMT 2019 蒙汉评测主系统评测结果(仅列出前10)
注:为表示对参评单位的尊重,和各单位对共同促进机器翻译产学研落地做出的努力,评测结果中已隐去参评单位信息。
打造民族巴别塔,科技向善暖民心
此次团队在CCMT比赛能取得冠军,也得益于其特色产品“腾讯民汉翻译”,这款轻量级的小程序上实现了to C高并发的实时语音同声翻译,以及全自动图像拍照翻译。并支持蒙,藏(安多,康巴,卫藏),维,哈,朝,彝,壮等多种少数民族语言。上线半年以来,这款小众产品截至目前累计用户已经接近30万多,周留存率达到18%。在新疆驻村干部,语言学习者,旅游者中,获得了良好的口碑,也逐渐渗透到了少数民族同胞的生活当中,切切实实地解决了数十万民族同胞们日常跨语种实时交流、办公、学习的问题。
以下是民族语和汉语的同声传译:
以下是民族语和汉语全自动化拍照翻译,用户不用选择语种和图像方向,随心想拍就拍:
事实上,这款产品背后的腾讯民族语言音视图文技术已经得到众多组织和机构的认可,并在国内外各大学术和产业竞赛中获奖无数。如2018年全国维吾尔语分词大赛(MLWS) 第1名;2018年世界机器翻译大赛(WMT 18)第2名;2018年全国民汉CWMT翻译比赛总成绩第1名;2018年世界东方语种识别大赛第2名;2019年国家部委机器翻译评测藏语第1名,维语第2名;2019年ICDAR 多语种OCR识别竞赛第2名等等。在6月中国人工智能协会举办的中国人工智能峰会(CAIS 2019)上,腾讯民汉翻译也从50多个项目评选中脱颖而出,获得“紫金技术创新奖”。

腾讯民汉翻译获得“紫金技术创新奖”
宝剑锋从磨砺出,梅花香自苦寒来
在比赛过程中,腾讯民汉翻译团队以公司为家,鏖战了几个昼夜,将腾讯民汉翻译在产品中长期磨砺出来的一系列技术积累和丰富经验,结合2019年最前沿的机器翻译算法,研发出一整套民族语言翻译的技术参赛方案,如下图所示:

Fig. 3 提交系统的技术路线图
1. 系统主干模型
在模型的选择上,团队采用基于自注意力的Transformer框架作为基准模型结构,在此基础上为了能使模型有更好的性能表现,还做了以下几方面的改进:1)团队使用了更大的模型参数,将模型维度以及前馈网络层(FFN Layer)分别增大至1024维和4096维。更大的模型代表着更大的模型容量以及更强的表达能力;2)将前馈网络层的ReLU激活函数更换为Swish激活函数,试验结果表明Swish激活函数的使用带来了性能上的提升;3)将Transformer网络层中的Layer Normalization前置,即使用Pre-Layer Normlaization。以下为模型结构图:

Fig. 4 模型结构图
2. 低资源数据扩充算法
在数据增强方面,反向翻译(Back-translation)过程中不仅采用了束搜索的方法,同时不受限采样(unlimited sampling)、受限top-k采样(limited top-k samplling) 等方法的使用也增加了伪数据的多样性。在资源稀缺的情况下,为提高伪数据的质量,团队尝试了迭代的反向翻译(Iterative Back-translation)技术,通过多轮迭代达到了正反向模型性能相互促进的目的。此外,团队首次采用了带标签的反向翻译(Tagged Back-translation),该方法通过分别对真实数据和伪数据打特定标签的方式,使得模型能够更有效的分辨这两类数据。在数据选取(Data Selection)方面,该团队采用了最新的n-gram语言模型打分方法,即对训练集和测试集计算n-gram语言模型得分,后通过得分差从训练集选择与测试集相似的子集合。除此之外,在业界首次将最新的BERT框架引入到数据选取方法上。更具体的,在NLP团队的自研BERT框架基础上,通过增加两层前馈神经网络层,训练出具有高准确性的分类模型。下图列出反向翻译实验结果:

Fig. 5 反向实验结果
3. 模型蒸馏和训练
在训练方面,为了保证模型能够充分收敛,以校验集上的BLEU分作为标准采用Early-stop方法,在模型连续5至10次不能有性能上的提升时结束训练。同时,采用Optimizer-delay的方法模拟多卡数据并行以增加Batch大小,进一步提升了模型性能。另外,团队还尝试使用了Custom Embedding、Guided Alignment、Data Weighting等训练方法。其中,Custom Embedding方法在源和目标单语数据上使用word2vec工具预先训练好词向量,并将训练结果初始化给翻译模型,翻译模型进一步以训练或固定词向量的方法进行训练。Guided Alignment方法则使用传统的词对齐信息引导神经机器翻译模型中的注意力机制。Data Weighting方法可以给训练集中的句子或短语给予一定的权重,使权重较高的句子或短语能对模型有更大的影响。团队在使用大量伪数据和真实数据合并的数据进行预训练时对真实数据赋予更高的权重,同时适当降低了伪数据的权重,从而达到模型更偏向真实数据的目的。在机器翻译中,模型蒸馏是使用Teacher模型将训练数据的源语言进行解码,生成目标端是伪数据但源端为真实数据的新平行语料,Student模型使用该语料进行学习的方法。不同于反向翻译,模型蒸馏方法希望通过这种方式使Student模型学习Teacher模型的分布。在本次大赛中,民汉团队将模型蒸馏的方法应用在模型微调训练阶段,并在生成伪数据的方式上使用了以下几种方法:
Teacher模型解码时使用束搜索生成Top1译文供Student模型训练(Knowladge Distillation, KD);
Teacher模型输出nbest结果,并通过计算句子级的BLEU分选择与原始目标端句子最相似的译文供Student模型训练(Interpolation, Inter);
将上述两个方法有效融合,在KD的基础上进一步使用Inter方法进行微调(KD+Inter);
将单个Teacher模型升级为多个Teachter融合模型进行解码(Ensemble Distillation, ED);
4. 解码和调优
在解码部分,团队使用了分数平均的模型融合方法,并对输出nbest进行了重排序。模型融合方面使用了3至14个不等的模型进行融合。重排序方面除标准模型输出分(L2R)外,还包括从右至左翻译模型打分(R2L)、反向翻译模型打分(T2S)、n-gram语言模型打分(LM)、长度惩罚(WP)、正反向对其概率(FAP/RAP)以及翻译覆盖度(Translation Coverage)等特征,最终通过MIRA来对每个特征的权重进行调优。下图为提交系统结果:
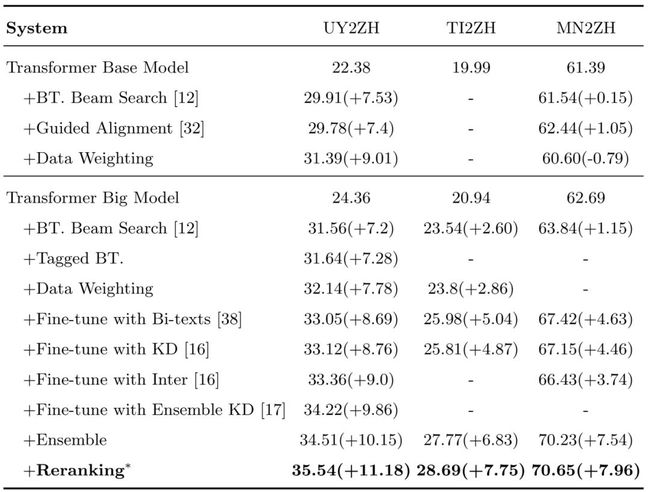
Fig. 6 提交系统结果
本次比赛中,大部分技术都已经反哺在“腾讯民汉翻译”产品中。
小结
我们深知,获得比赛冠军只是AI在民族语言落地的一小步。而如何将技术和人民群众的对于语言的需求和痛点结合,打造改善民族地区千万人群生活的产品,构建民族语言的终极巴别塔,才是团队持之以恒的追求。用技术改善生活,用实力落地情怀,是TEG er不变的信念与追求。
科技向善,我们一直在路上。
参考文献
[1] Hu, B., Han, A., Huang, S.: TencentFmRD Neural Machine Translation for WMT18
[2] Hu, B., Han, A., Huang, S.: TencentFmRD Neural Machine Translation System
[3] Sennrich, R., Haddow, B., Birch, A.:Improving Neural Machine Translation Models with Monolingual Data.
[4] Edunov, S., Ott, M., Auli, M., Grangier, D.,: Understanding Back-Translation at Scale.
[5] Imamura, K., Fujita, A., Sumita, E.:Enhancement of encoder and attention using target monolingual corpora in neural machine translation.
[6] Hoang, V. C. D., Koehn, P., Haari, G., Cohn, T.:Iterative Back-Translation for Neural Machine Translation.
[7] Kim, Y., Rush, A., M.:Sequence-Level Knowledge Distillation.
[8] Freitag, M., Al-Onaizan, Y., Sankaran, B.:Ensemble distillation for neural machine translation.