搭建Spark开发环境并完成wordcount示例
一、搭建Spark开发环境流程
1.安装eclipse,我这里用的是集成环境,解压就能用。(包含了scala环境)
安装包传送门:
2.导入相关的jar包
Jar包传送门:
具体操作:
(1)装上以上的eclipse之后,如图所示,先切换到scala模式。

(2)新建项目的时候,会看到已经可以新建Scala项目了。如图所示新建Scala项目。

(2)如图所示,导入jar包

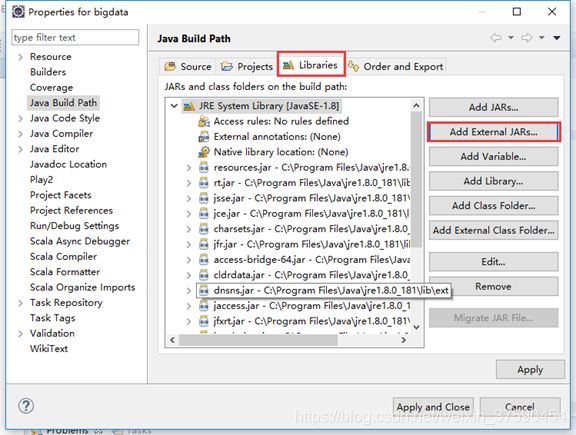

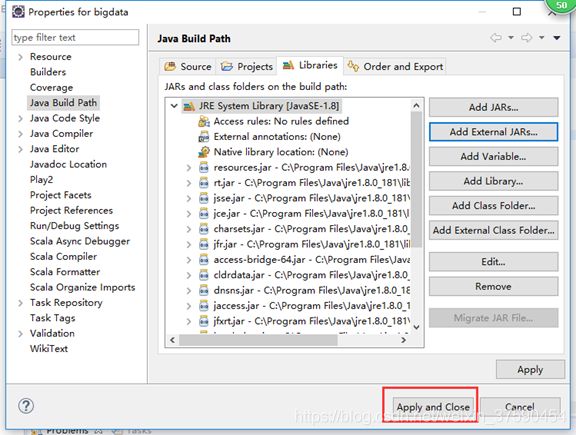
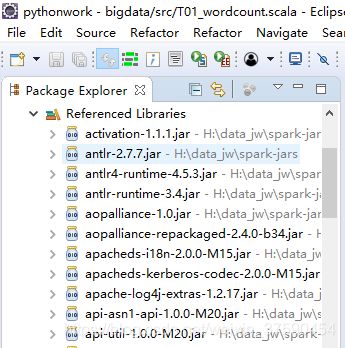
导入之后,就能看到项目里已经有很多jar包(截图中省略)
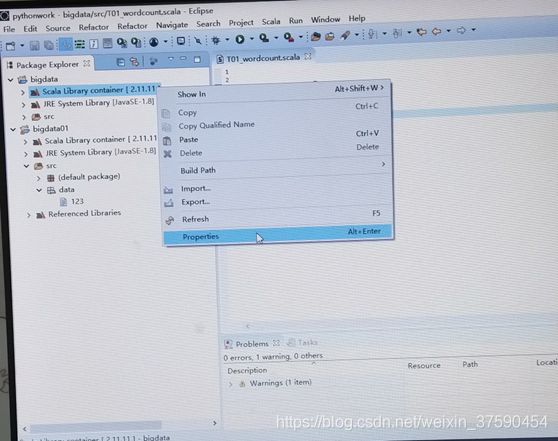
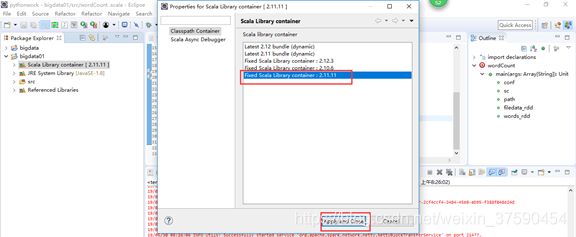
(3)修改版本号,因为我们的jar包是2.11的
3.测试运行,打印 Helloworld
(1)新建测试文件,如图所示:
(2)打印输出helloworld

二、完成WordCount实例(一个打印输出单词的实例)
(1)如上述:新建一个Scala项目,然后导入jar包,修改版本号,建一个Scala Object。
(2)造数据。先建一个Folder命名为data,在data目录下建一个File命名为123;在123里写上数据。


(3)写上WordCount完整代码
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.SparkConf
object wordCount {
def main(args: Array[String]):Unit = {
//System.setProperty("hadoop.home.dir", "D:\\RJ\\hadoop-2.6.5");
//spark处理---并发迭代大数据
//RDD.map word->(w,1)
//rdd.reduce->w->sum 1
//1.sc
var conf = new SparkConf()
conf.setMaster("local[*]").setAppName("lhn")
var sc = new SparkContext(conf)
sc.setLogLevel("WARN");
//2.sc.textFile ->RDD
var path = "src/data/123"
var filedata_rdd = sc.textFile(path,2)
var words_rdd=filedata_rdd
.flatMap(_.split("\\W+"))
.map(x=>(x,1))
.reduceByKey(_+_)
.map(_.swap)
.sortByKey(false)
// words_rdd.foreach(println)
print(filedata_rdd.count())
words_rdd.foreach{line=>
println("word="+line._1+" ,num="+line._2)
}
println("end....")
}
}
(4)编译运行
