HDU 1560 DNA sequence 【加深迭代dfs】【IDA*】
DNA sequence
Time Limit: 15000/5000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)
Total Submission(s): 4172 Accepted Submission(s): 2005
Problem Description
The twenty-first century is a biology-technology developing century. We know that a gene is made of DNA. The nucleotide bases from which DNA is built are A(adenine), C(cytosine), G(guanine), and T(thymine). Finding the longest common subsequence between DNA/Protein sequences is one of the basic problems in modern computational molecular biology. But this problem is a little different. Given several DNA sequences, you are asked to make a shortest sequence from them so that each of the given sequence is the subsequence of it.
For example, given "ACGT","ATGC","CGTT" and "CAGT", you can make a sequence in the following way. It is the shortest but may be not the only one.
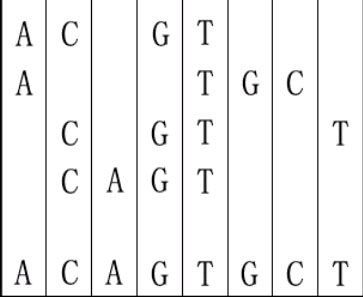
Input
The first line is the test case number t. Then t test cases follow. In each case, the first line is an integer n ( 1<=n<=8 ) represents number of the DNA sequences. The following k lines contain the k sequences, one per line. Assuming that the length of any sequence is between 1 and 5.
Output
For each test case, print a line containing the length of the shortest sequence that can be made from these sequences.
Sample Input
1 4 ACGT ATGC CGTT CAGT
Sample Output
8
Author
LL
Source
HDU 2006-12 Programming Contest
Recommend
LL
Statistic | Submit | Discuss | Note
题意:
给你n个字符串,让你构建一个字符串,使得所给的n个字符串都是这个字符串的子序列。求这个序列的最长长度。
什么是迭代加深搜索?
迭代加深搜索就是限制递归的层数,然后一层层地扩大限制的层数
比方说,你一开始限制只能递归到第1层,然后到第2层,第3层......以此类推,直到找到解
(摘自博客https://blog.csdn.net/myc0_0/article/details/79275435)
什么是IDA*算法?
而IDA*则在迭代加深搜索的基础上多了评估函数(或者说剪枝),每次预估如果这条路如果继续下去也无法到达终点,则放弃这条路(剪枝的一种,即最优性剪枝)
(摘自博客:https://blog.csdn.net/ljt735029684/article/details/78945098)
那么此题迭代搜索的最短层数必定等于所给n个字符串序列中最长的那个。然后一层层向下加,最后得到的一定是最优解。
#include
using namespace std;
#define LL long long
#define M(a,b) memset(a,b,sizeof(a))
const int MAXN = 15;
const int INF = 0x3f3f3f3f;
int T,n,maxlen,flag;
char str[MAXN][MAXN];
int slen[MAXN];///记录所有字符串的长度
int match[MAXN];
/*
match数组记录了当前第n个字符串所匹配到第几个字符
比如如果我们深搜到某一步得到的串是:ACGTCA
对于所给的四个字符串:
ACGT
ATGC
CGTT
CAGT
ACGT 匹配到了第四个字符 所以match[0]==4 (下标从零开始)
ATGC 匹配到了第二个字符 所以match[1]==2
CGTT 匹配到了第三个字符 所以match[2]==3
CAGT 匹配到了第二个字符 所以match[3]==2
所以当所有的match[i]都等于第i个字符串的长度时,匹配才完成
*/
char DNA[4] = {'A','C','T','G'};///所有的字符可能
void init()///初始化
{
M(match,0);
maxlen = -1;
flag = 0;
}
int get_h()
{
int sum = 0;
for(int i=0;is)///匹配所需字符数大于当前已匹配字符串长度,即此长度无法满足匹配条件。
{
return;
}
int temp_match[MAXN];///记录匹配情况,以便匹配失败恢复数据用。
for(int i=0;i>T;
while(T--)
{
init();
scanf("%d",&n);
for(int i=0;i