CS224d-深度学习与自然语言处理-Day 1:
原文地址:http://www.jianshu.com/p/6993edef96e4
CS224d-Day 1:
要开始系统地学习 NLP 课程 cs224d,今天先来一个课程概览。
课程一共有16节,先对每一节中提到的模型,算法,工具有个总体的认识,知道都有什么,以及它们可以做些什么事情。
简介:
1. Intro to NLP and Deep Learning
NLP:
Natural Language Processing (自然语言处理)的目的,就是让计算机能‘懂得’人类对它‘说’的话,然后去执行一些指定的任务。
这些任务有什么呢?
Easy:
• Spell Checking--拼写检查
• Keyword Search--关键词提取&搜索
• Finding Synonyms--同义词查找&替换
Medium:
• Parsing information from websites, documents, etc.--从网页中提取有用的信息例如产品价格,日期,地址,人名或公司名等
Hard:
• Machine Translation (e.g. Translate Chinese text to English)--自动的或辅助的翻译技术
• Semantic Analysis (What is the meaning of query statement?)--市场营销或者金融交易领域的情感分析
• Coreference (e.g. What does "he" or "it" refer to given a document?)
• Question Answering (e.g. Answering Jeopardy questions).--复杂的问答系统
NLP的难点:
- 情境多样
- 语言歧义
Deep Learning:
深度学习是机器学习的一个分支,尝试自动的学习合适的特征及其表征,尝试学习多层次的表征以及输出。
它在NLP的一些应用领域上有显著的效果,例如机器翻译,情感分析,问答系统等。
和传统方法相比,深度学习的重要特点,就是用向量表示各种级别的元素,传统方法会用很精细的方法去标注,深度学习的话会用向量表示 单词,短语,逻辑表达式和句子,然后搭建多层神经网络去自主学习。
这里有简明扼要的对比总结。
向量表示:
词向量:
-
One-hot 向量:
记词典里有 |V| 个词,每个词都被表示成一个 |V| 维的向量,设这个词在字典中相应的顺序为 i,则向量中 i 的位置上为 1,其余位置为 0. -
词-文档矩阵:
构建一个矩阵 X,每个元素 Xij 代表 单词 i 在文档 j 中出现的次数。 -
词-词共现矩阵:
构建矩阵 X,每个元素 Xij 代表 单词 i 和单词 j 在同一个窗口中出现的次数。
模型算法:
2. Simple Word Vector representations: word2vec, GloVe
word2vec:
word2vec是一套能将词向量化的工具,Google在13年将其开源,代码可以见https://github.com/burness/word2vec ,它将文本内容处理成为指定维度大小的实数型向量表示,并且其空间上的相似度可以用来表示文本语义的相似度。
Word2vec的原理主要涉及到统计语言模型(包括N-gram模型和神经网络语言模型),continuousbag-of-words 模型以及 continuous skip-gram 模型。
- N-gram的意思就是每个词出现只看其前面的n个词,可以对每个词出现的概率进行近似。
比如当n=2的时候:
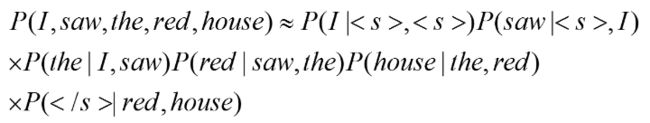
- 神经网络语言模型(NNLM)用特征向量来表征每个词各个方面的特征。NNLM的基础是一个联合概率:
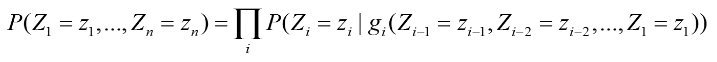
其神经网络的目的是要学习:
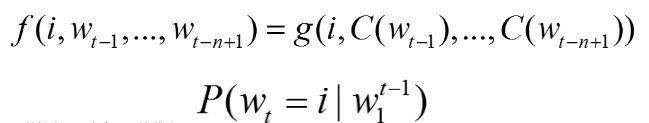
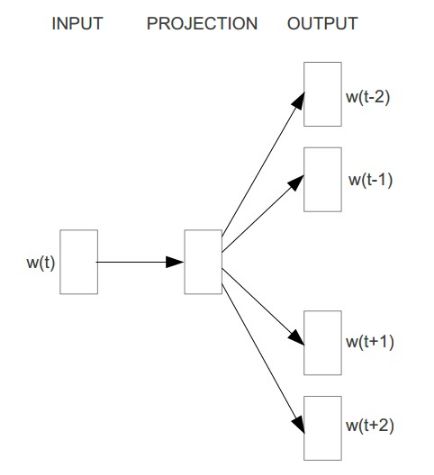
- Continuous Bag-of-Words(CBOW) 模型与NNLM类似,结构如下:
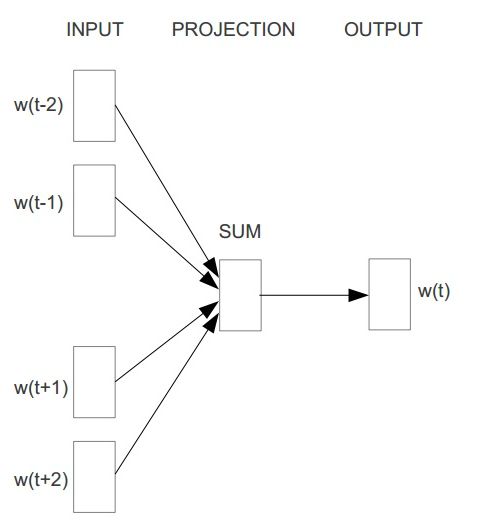
CBOW是通过上下文来预测中间的词,如果窗口大小为k,则模型预测:
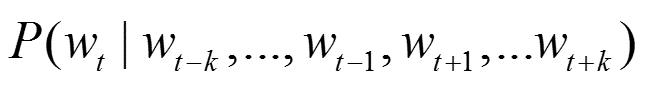
其神经网络就是用正负样本不断训练,求解输出值与真实值误差,然后用梯度下降的方法求解各边权重参数值的。
- Continuous skip-gram 模型与CBOW正好相反,是通过中间词来预测前后词,一般可以认为位置距离接近的词之间的联系要比位置距离较远的词的联系紧密。目标为最大化:
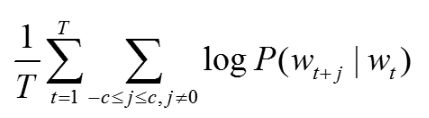
结构为:
应用:
- 同义词查找,
- 文本聚类,实现方法:用关键词来表征文本。关键词提取用TF-IDF,然后用word2vec训练得到关键词向量,再用k-means聚类,最后文本就能够以关键词的类别进行分类了。
- 文本类别投递,实现方法:人工标记出该词属于各个类别的概率,出全体词属于各个类别的概率。
Glove:
Global Vectors 的目的就是想要综合前面讲到的 word-document 和 word-windows 两种表示方法,做到对word的表示即 sementic 的表达效果好,syntactic 的表达效果也好:

3. Advanced word vector representations: language models, softmax, single layer networks
softmax:
softmax 模型是 logistic 模型在多分类问题上的推广, logistic 回归是针对二分类问题的,类标记为{0, 1}。在softmax模型中,label可以为k个不同的值。
4. Neural Networks and backpropagation -- for named entity recognition
5. Project Advice, Neural Networks and Back-Prop (in full gory detail)
Neural Networks:
神经网络是受生物学启发的分类器,可以学习更复杂的函数和非线性决策边界。
模型调优:
6. Practical tips: gradient checks, overfitting, regularization, activation functions, details
UFLDL:Unsupervised Feature Learning and Deep Learning
Gradient Checking(梯度检测):
反向传播因为细节太多,往往会导致一些小的错误,尤其是和梯度下降法或者其他优化算法一起运行时,看似每次 J(Θ) 的值在一次一次迭代中减小,但神经网络的误差可能会大过实际正确计算的结果。
针对这种小的错误,有一种梯度检验(Gradient checking)的方法,通过数值梯度检验,你能肯定确实是在正确地计算代价函数(Cost Function)的导数。
GC需要对params中的每一个参数进行check,也就是依次给每一个参数一个极小量。
overfitting:
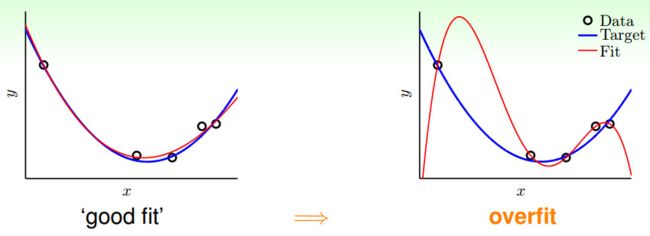
就是训练误差Ein很小,但是实际的真实误差就可能很大,也就是模型的泛化能力很差(bad generalization)
发生overfitting 的主要原因是:(1)使用过于复杂的模型(dvc 很大);(2)数据噪音;(3)有限的训练数据。
regularization:
为了提高模型的泛化能力,最常见方法便是:正则化,即在对模型的目标函数(objective function)或代价函数(cost function)加上正则项。
平台:
7. Introduction to Tensorflow
Tensorflow:
Tensorflow 是 python 封装的深度学习库,非常容易上手,对分布式系统支持比 Theano 好,同时还是 Google 提供资金研发的
在Tensorflow里:
- 使用张量(tensor)表示数据.
- 使用图(graph)来表示计算任务.
- 在被称之为会话(Session)的上下文 (context)中执行图.
- 通过变量 (Variable)维护状态.
- 使用feed和fetch可以为任意的操作(arbitrary operation)赋值或者从其中获取数据.
TensorFlow 算是一个编程系统,它使用图来表示计算任务,图中的节点被称之为operation(可以缩写成op),一个节点获得0个或者多个张量(tensor,下文会介绍到),执行计算,产生0个或多个张量。
模型与应用:
8. Recurrent neural networks -- for language modeling and other tasks
RNN:
在深度学习领域,传统的前馈神经网络(feed-forward neural net,简称FNN)具有出色的表现。
在前馈网络中,各神经元从输入层开始,接收前一级输入,并输入到下一级,直至输出层。整个网络中无反馈,可用一个有向无环图表示。
不同于传统的FNNs,RNNs引入了定向循环,能够处理那些输入之间前后关联的问题。定向循环结构如下图所示:
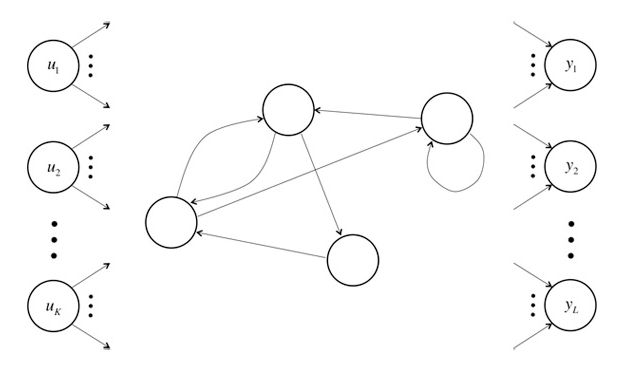
9. GRUs and LSTMs -- for machine translation

传统的RNN在训练 long-term dependencies 的时候会遇到很多困难,最常见的便是 vanish gradient problem。期间有很多种解决这个问题的方法被发表,大致可以分为两类:一类是以新的方法改善或者代替传统的SGD方法,如Bengio提出的 clip gradient;另一种则是设计更加精密的recurrent unit,如LSTM,GRU。
LSTMs:
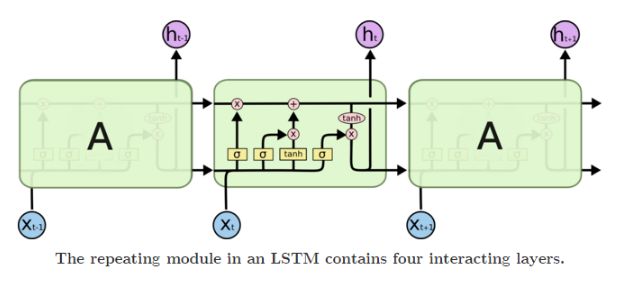
长短期内存网络(Long Short Term Memory networks)是一种特殊的RNN类型,可以学习长期依赖关系。
LSTMs 刻意的设计去避免长期依赖问题。记住长期的信息在实践中RNN几乎默认的行为,但是却需要很大的代价去学习这种能力。
LSTM同样也是链式结构,但是重复的模型拥有不同的结构,它与单个的神经网层不同,它有四个, 使用非常特别方式进行交互。
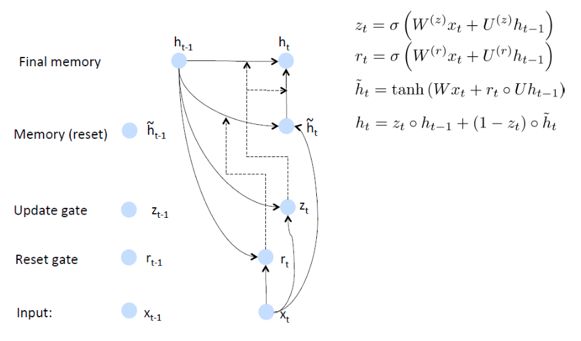
GRUs:
Gated Recurrent Unit 也是一般的RNNs的改良版本,主要是从以下两个方面进行改进。
一是,序列中不同的位置处的单词(已单词举例)对当前的隐藏层的状态的影响不同,越前面的影响越小,即每个前面状态对当前的影响进行了距离加权,距离越远,权值越小。
二是,在产生误差error时,误差可能是由某一个或者几个单词而引发的,所以应当仅仅对对应的单词weight进行更新。
10. Recursive neural networks -- for parsing
11. Recursive neural networks -- for different tasks (e.g. sentiment analysis)
Recursive neural networks:
和前面提到的 Recurrent Neural Network 相比:
recurrent: 时间维度的展开,代表信息在时间维度从前往后的的传递和积累,可以类比markov假设,后面的信息的概率建立在前面信息的基础上。
recursive: 空间维度的展开,是一个树结构,就是假设句子是一个树状结构,由几个部分(主语,谓语,宾语)组成,而每个部分又可以在分成几个小部分,即某一部分的信息由它的子树的信息组合而来,整句话的信息由组成这句话的几个部分组合而来。
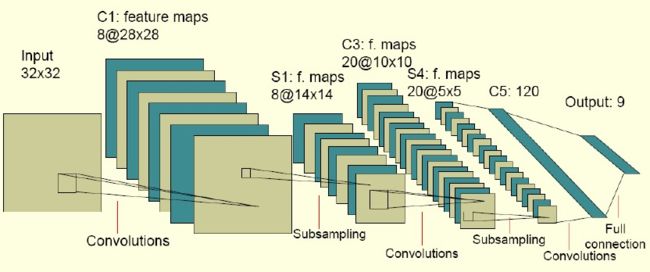
12. Convolutional neural networks -- for sentence classification
Convolutional neural networks:
卷积神经网络是一种特殊的深层的神经网络模型,它的特殊性体现在两个方面,一方面它的神经元间的连接是非全连接的, 另一方面同一层中某些神经元之间的连接的权重是共享的(即相同的)。它的非全连接和权值共享的网络结构使之更类似于生物 神经网络,降低了网络模型的复杂度,减少了权值的数量。
13. Guest Lecture with Andrew Maas: Speech recognition
14. Guest Lecture with Thang Luong: Machine Translation
大数据:
15. Guest Lecture with Quoc Le: Seq2Seq and Large Scale DL
Seq2Seq:
seq2seq 是一个机器翻译模型,解决问题的主要思路是通过深度神经网络模型(常用的是LSTM,长短记忆网络,一种循环神经网络)将一个作为输入的序列映射为一个作为输出的序列,这一过程由编码输入与解码输出两个环节组成。
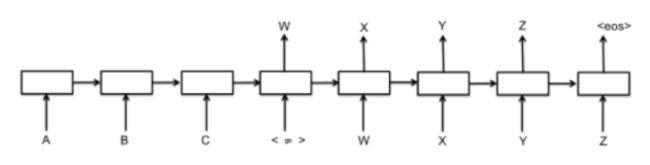
Encoder:
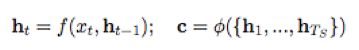
Decoder:
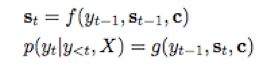
注意机制是Seq2Seq中的重要组成部分:
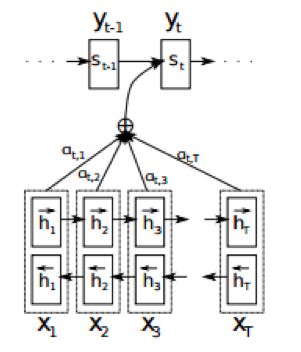
应用领域有:机器翻译,智能对话与问答,自动编码与分类器训练等。
Large Scale DL:
为了让 Neural Networks 有更好的效果,需要更多的数据,更大的模型,更多的计算。
Jeff Dean On Large-Scale Deep Learning At Google
未来方向:
16. The future of Deep Learning for NLP: Dynamic Memory Networks
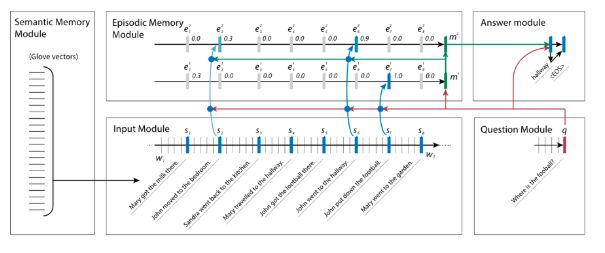
dynamic memory network (DMN):
利用 dynamic memory network(DMN)框架可以进行 QA(甚至是 Understanding Natural Language)。
这个框架是由几个模块组成,可以进行 end-to-end 的 training。其中核心的 module 就是Episodic Memory module,可以进行 iterative 的 semantic + reasoning processing。
有了一个总体的了解,看的热血沸腾的,下一次开始各个击破