Java面试笔记
基础篇
-
final,finally,finalize之前的区别
- final关键字,代表着不可变,可以保证在过程中不被修改。final修饰的数据,只能读取,不能修改。final修饰的方法表示任何继承类都无法重写。final修饰的类,表示无派生子类,无法被继承。
- finally表示始终被执行的意思,和try,catch一起使用,无论是否发生异常finally内的的语句都会执行。
- finalize是Object的方法,但JVM 进行 GC时,如果对象没有被调用,需要清除,就会执行此方法类,做生前最后的事情(最终遗言),且仅被调用一次
-
重载(Overload)和重写(Override)的区别
- 多个同名的函数存在,有不同类型的参数和不同个数的的参数。(返回类型、访问权限大小和异常不同不算为重载)。
- 又叫覆盖,是子类继承父类的方法,并重新定义。
-
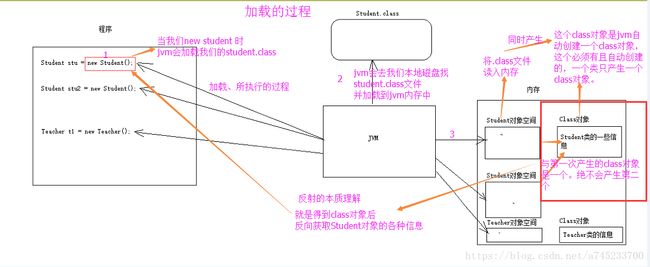
简单介绍一下反射机制,反射的用途和实现
-
反射在Java中有运行和编译两种状态。指在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象。
-
获取class对象的方法来使用反射
-
通过对象Object的getClass()方法、通过类的静态class属性、通过Class类的静态方法forName(String className)
-
-
反射获取私有方法
-
method.setAccessible(true);//获取私有权限 //可以绕过私有的安全检查,所以我们就可以调用类的私有方法啦。
-
-
序列化和反序列化的理解
- 序列化是将java对象转换成字节序列的过程,反序列化也即是相反的过程
- 作用:
- 持久化存储,(持久化存储到本地磁盘)
- 远程调用(序列化成流 远程传输)
-
抽象类和接口的区别
- 抽象类是被abstract修饰的类,抽象类中可以拥有任意范围的成员数据,可以定义非抽象方法。
- 接口时interface,接口中只能拥有静态的不可修改的数据且所有的方法都是抽象的
-
equals和==的区别
- ==可以比较基本数据类型,比较两者在内存中的值,当 == 比较的复合类型的时候是比较的堆内存地址。
- equals比较复合数据也是比较的堆内存地址和==的功能是一样的,底层equals也是 ==,但是String重写了equals()方法,比较的是内容是否相同。
-
各类内部类的区别
- 成员内部类:普通内部类,与外部类存在联系,需要依赖外部类方能实例化
- 静态内部类:与外部对象不存在联系。可直接实例化
- 匿名内部类:无名,继承或实现那个类
- 局部内部类:方法体内或作用域内可以使用
-
作用域 公开的public,受保护的protected默认friendly,私有的private的区别

-
Object常用的方法有哪些?
equals()、toString()、finalize()、getClass()、hashCode()、clone()、wait()、notify()、notifyAll()
-
wait和sleep的区别
- sleep是线程中的方法,但是wait是Object中的方法。
- sleep方法不会释放lock,但是wait会释放,而且会加入到等待队列中。
- sleep方法不依赖于同步器synchronized,但是wait需要依赖synchronized关键字。
- sleep不需要被唤醒(休眠之后推出阻塞),但是wait需要(不指定时间需要被别人中断)。
-
notify()、notifyAll()是什么,有什么区别
-
当线程执行wait()方法时候,会释放当前的锁,然后让出CPU,进入等待状态。
-
notify/notifyAll() 的执行只是唤醒沉睡的线程,而不会立即释放锁,锁的释放要看代码块的具体执行情况。所以在编程中,尽量在使用了notify/notifyAll() 后立即退出临界区,以唤醒其他线程让其获得锁。
-
notify 和wait 的顺序不能错,如果A线程先执行notify方法,B线程在执行wait方法,那么B线程是无法被唤醒的。
区别
notify()是只唤醒一个等待的线程,如果存在多个线程的情况,由操作系统对多线程管理来决定。notifyAll 会唤醒所有等待(对象的)线程,尽管哪一个线程将会第一个处理取决于操作系统的实现。如果当前情况下有多个线程需要被唤醒,推荐使用notifyAll 方法。比如在生产者-消费者里面的使用,每次都需要唤醒所有的消费者或是生产者,以判断程序是否可以继续往下执行。在多线程中如果根据条件决定是否执行,使用while不用if。因为while 具有判断条件成立后在执行。
-
-
String和StringBuffer、StringBuilder的区别
- String是一个Java的基础数据类型,在内存堆上被创建。因为被final修饰,String 一旦被创建后出来,值不能改变,String的所有方法都不能改变本身的值,而是返回一个新的String对象。String是使用字符数组保存字符串
- 共同的父类。StringBuffer是和StringBuilder的父类是AbstracStringBuilder,这两种对象都是可变的。
- 线程安全性。String不可变,可以理解为常量,所以是线程安全的,StringBuffer引入了同步锁或者对调用的方法使用了线程锁,所以也是线程安全的。
- StringBuilder没有线程锁,是线程不安全的。
-
可变与不可变化性
不可改变的都是一定是线程安全的,因为只有一种状态,被final修饰,对象创建后不可修改。
-
hashCode和equals方法的关系
- 对于两个对象,如果调用equals方法得到的结果为true,则两个对象的hashcode值必定相等;
- 如果equals方法得到的结果为false,则两个对象的hashcode值不一定不同;
- 如果两个对象的hashcode值不等,则equals方法得到的结果必定为false;
- 如果两个对象的hashcode值相等,则equals方法得到的结果未知。
-
HTTP 请求的 GET 与 POST 方式的区别

-
Session 与 Cookie 区别
-
cookie数据存放在客户的浏览器上,session数据放在服务器上。
-
cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,考虑到安全应当使用session。
-
session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能考虑到减轻服务器性能方面,应当使用cookie。
-
单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
所以个人建议:将登陆信息等重要信息存放为session。其他信息如果需要保留,可以放在cookie中
-
集合篇
-
List,Set,Map之间的区别
-
List,Set,Map都是接口,但是List,Set是继承Collection接口,Map为单独的接口
-
Set下有HashSet,LinkedHashSet,TreeSet
-
List下有ArrayList,Vector,LinkedList
-
Map下有Hashtable,LinkedHashMap,HashMap,TreeMap
-
Collection接口下还有个Queue接口,有PriorityQueue类

-
注意:
Queue接口与List、Set同一级别,都是继承了Collection接口。
看图你会发现,LinkedList既可以实现Queue接口,也可以实现List接口.只不过呢, LinkedList实现了Queue接口。Queue接口窄化了对LinkedList的方法的访问权限(即在方法中的参数类型如果是Queue时,就完全只能访问Queue接口所定义的方法 了,而不能直接访问 LinkedList的非Queue的方法),以使得只有恰当的方法才可以使用。SortedSet是个接口,它里面的(只有TreeSet这一个实现可用)中的元素一定是有序的。
-
-
集合类分析总结
-
— List 有序,可重复
ArrayList
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高
LinkedList
优点: 底层数据结构是链表,查询慢,增删快。
缺点: 线程不安全,效率高Vector
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低 -
Set 无序,唯一
HashSet
底层数据结构是哈希表。(无序,唯一)
如何来保证元素唯一性?
1.依赖两个方法:hashCode()和equals()LinkedHashSet
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一TreeSet
底层数据结构是红黑树。(唯一,有序)- 如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
- 如何保证元素排序的呢?
-
-
针对Collection集合我们到底使用谁呢?(掌握)
-
如何选择使用那个集合框架
if(唯一?){ 使用Set if(排序?){ TreeSet或LinkedHashSet }else{ HashSet(默认) } }else{ List if(线程安全吗?){ Vector }else{ ArrayList:查询速度快,增删慢 LinkedList: 查询速度慢,增删快 } }
-
-
Set存储是唯一,底层如何去重
- HashSet:采用Hash是通过调用元素内部的hashCode和equals方法实现去重,首先调用hashCode方法,比较两个元素的哈希值,如果哈希值不同,直接认为是两个对象,停止比较。如果哈希值相同,再去调用equals方法,返回true,认为是一个对象。返回false,认为是两对象
- **TreeSet:**如果compareTo返回0,说明是重复的,返回的是自己的某个属性和另一个对象的某个属性的差值,如果是负数,则往前面排,如果是正数,往后面排;
-
Map的结构

- Map接口有三个比较重要的实现类,分别是HashMap、TreeMap和HashTable。
- TreeMap是有序的,HashMap和HashTable是无序的。
- Hashtable的方法是同步的,也是线程安全,HashMap的方法不是同步的,也是线程不安全。这是两者最主要的区别。
-
HashTable和HashMap的区别
1. **线程安全**,HashTable 是同步的也是线程安全的,而HashMap是不同步的,也是线程不安全。 2. **效率**。HashTable的执行效率要比HashMap低一些,但是如果对同步性和线程问题没要求的情况下推荐使用HashMap 3. **Null值**。在HashTable 中是不允许使用Null值,但是在Hash Map中Key和Value 都可以为Null。 4. **父类不同**。HashTable 的父类是Dictionary而HashMap的父类是AbstractMap。 -
HashSet 和 HashMap 区别
- HashMap实现了Maps HashSet继承的是Collection接口
- HashMap存储kay-value,HashSet只存储对象
- 两者都使用hashCode来计算kay和对象,equals方法判断对象相同 也相同
-
ConcurrentHashMap 的工作原理
-
ConcurrentHashMap 的加锁粒度要比HashTable更细一点。将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。(分段锁)
-
Segment继承了ReentrantLock,所以它就是一种可重入锁(ReentrantLock)。在ConcurrentHashMap,一个Segment就是一个子哈希表,Segment里维护了一个HashEntry数组,并发环境下,对于不同Segment的数据进行操作是不用考虑锁竞争的。(就按默认的ConcurrentLeve为16来讲,理论上就允许16个线程并发执行)
-
具体解释和总结,很棒!
https://www.baidu.com/link?url=f3UWlcJcGkMogsmnsGc_Hrgbnh1Qfkdl8ojdzZM73lZIpjvOAXK0n8fCRHY-nKAWyhbe0wrA0TdJA1qEkmBgaa&wd=&eqid=bfc65ebf00036d59000000065b9a2f25
-
-
ConcurrentHashMap与HashMap的区别
- HashMap和concurrentHashMap都是基于散列,数组和链表
- 最大的区别就是线程安全问题,ConcurrentHashMap有分段锁的机制。当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
-
CopyOnWriteArrayList和CopyOnWriteArraySet的工作原理
CopyOnWriteArraySet是基于CopyOnWriteArrayList实现的,只有add的方法稍微有些不同,因为CopyOnWriteArraySet是Set也就是不能有重复的元素,故在CopyOnWriteArraySet中用了addIfAbsent(e)这样的方法。
写入时复制一个数组,对复制后产生的新数组进行操作,而旧的数组不会有影响,所以旧的数组可以依旧就行读取(可以看出来,读的时候如果有新的数据正在写是无法实时的读取到的,有延时,得等新数据写完以后,然后才可以读到新的数据)
多个线程同时去写,多线程写的时候会Copy出N个副本出来,那么可能内存花销很大,所以用一个重入显式锁ReetrantLock锁住,一次只能一个线程去添加。
读取时,不用进行线程同步。
可重入就意味着:线程可以进入任何一个它已经拥有的锁所同步着的代码块
java中常用的可重入锁
synchronized
java.util.concurrent.locks.ReentrantLock
线程篇
-
启动线程是run() 还是start()?
- Strat()方法是启动(开辟)线程的方法,因此线程的启动必须通过此方法.
- run()方法是线程的一个方法。主要写现成的具体业务内容,不具有启动的能力。
-
实现多线程的几种方式?
- 继承Thread
- 实现Runnable接口来实现,
- 通过Callable和FutureTask创建线程
- 通过线程池创建线程
-
ThreadLocal线程隔离
-
解释:ThreadLocal 是一个线程的内部存储类,主要方法有set和get,可以用于介于对现在多线程的情况下出现线程安全的问题。通过get和set方法就可以得到当前线程对应的值。
-
实际上是ThreadLocal的静态内部类ThreadLocalMap为每个Thread都维护了一个数组table,ThreadLocal确定了一个数组下标,而这个下标就是value存储的对应位置。。
-
public void set(T value) { //获取线程t, Thread t = Thread.currentThread(); //在ThreadLocalMap中 用线程t作为key 要存储的对象作为vlaue ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); } public T get() { //获取线程t, Thread t = Thread.currentThread(); //获取线程t的map ThreadLocalMap map = getMap(t); if (map != null) { //判断map是否存在 ThreadLocalMap.Entry e = map.getEntry(this); //判断 if (e != null) { @SuppressWarnings("unchecked") T result = (T)e.value; return result; } } return setInitialValue(); } -
作用:
- 进行事务操作,用于存储线程事务信息。
- 数据库连接,Session会话管理。
- 线程间数据隔离
- 在进行对象跨层传递的时候,使用ThreadLocal可以避免多次传递,打破层次间的约束。
-
-
Thread和Runnable 的区别
-
Java只支持单继承,所以使用Thread 有局限性,Runnable接口可以实现多个。
-
在实现Runable接口的时候调用Thread的Thread(Runnable run)或者Thread(Runnable run, String name)构造方法创建进程时,使用同一个Runnable实例,所以建立的多线程的实例变量是可以共享的。
public class TraditionalThread { public static void main(String[] args) { Runnable runnable = new Runnable() { public void run() { System.out.println("runnable :" + Thread.currentThread().getName()); } }; Thread thread = new Thread(runnable) { public void run() { System.out.println("thread :" + Thread.currentThread().getName()); } }; thread.start(); } } ———————————————— 结果 thread:Thread-0 当我们调用thread.start()方法时,虚拟机会自动去调用其run()方法。而当run()方法被覆盖时会调用我们重写的方法,便调用不到runnable .run()方法。这点我们可以从Thread类的源代码中看到。
-
-
什么叫守护线程,用什么方法实现守护线程?
- 守护线程是运行在后台的一种特殊进程。当前JVM实例中尚存在任何一个非守护线程没有结束,守护线程就全部工作;只有当最后一个非守护线程结束时,守护线程随着JVM一同结束工作。
- Thread.setDeamon(true)方法实现守护线程
-
如何停止一个线程?
- 使用interrupt方法中断线程。
-
sleep() 、join()、yield()、wait()有什么区别
- sleep()将运行状态的线程转为其他阻塞状态。,线程进入其他阻塞(睡眠)状态,期间对对象的锁并不会解开。会在指定时间结束后转为就绪状态。是Thread类的方法。不考虑优先级问题 。在指定的时间内不可能再次获得执行机会 。
- wait()该线程放弃对该对象的锁,线程进入等待阻塞状态,期间对对象的锁会解开。必须在经过其他线程调用notify()或notifyAll()方法唤醒后,转到锁池,等到得到对象的锁后,才会转为就绪状态 。是Object类的方法,和notify()和notifyAll()需要在synchronized(object)同步代码块中才能使用
- yield()暂停当前正在执行的线程对象,放入就绪状态,从就绪状态中重新调出相同或更高优先级的线程。在让步后,可能会再次获得执行机会 ,会考虑优先级问题 ,会直接转为就绪状态
- join()方法,在当前线程中调用另一个线程的join()方法,使当前前程进入其他阻塞状态,直到另一个线程运行结束,当前线程才从其他阻塞状态转为就绪状态
-
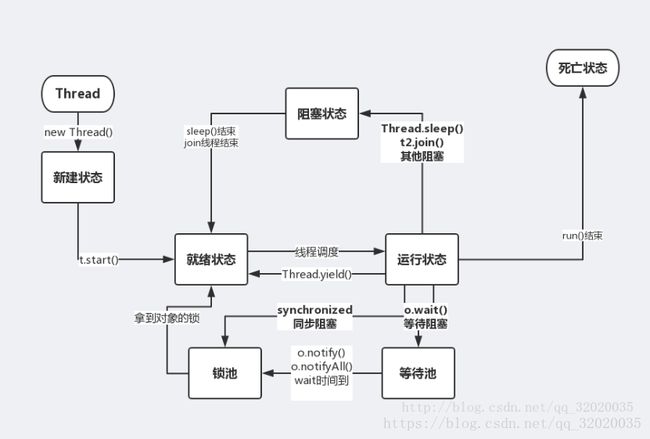
线程的生命周期
-
新建,就绪,运行,阻塞(等待阻塞,同步阻塞,其他阻塞),死亡
- 新建一个线程对象
- 使用start()方法将线程处于就绪状态
- 就绪状态后CPU会调度该线程
- 阻塞状态:是线程因为某些原因放弃了CPU使用权,暂时停止运行。只用当程序重新进入就绪状态,才有机会转为运行状态。阻塞状态分为三种:
(1) 等待阻塞:指运行的线程执行了wait()方法,当前线程会放弃对该对象的锁,JVM将该线程放入等待池中(wait会释放该线程所持有的锁)
(2) 同步阻塞:指运行的线程在获取对象的同步锁时,该锁被其他线程占用,JVM会将该线程放入锁池
(3)其他阻塞:运行的线程执行sleep()或join()方法,进入阻塞状态,等待CPU调度,线程重新进入就绪状态(sleep不会释放该线程所持有的锁) - 死亡状态:该线程执行完了,或者调用了某些方法退出了run()方法,结束了生命周期
-
-
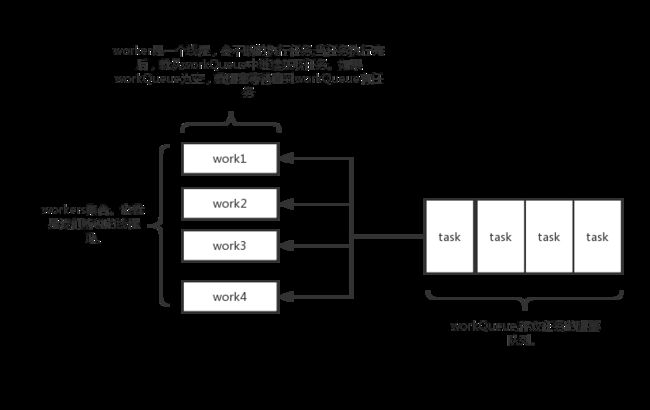
线程池的实现原理
- java线程池的实现原理很简单,说白了就是一个线程集合workerSet和一个阻塞队列workQueue。当用户向线程池提交一个任务(也就是线程)时,线程池会先将任务放入workQueue中。workerSet中的线程会不断的从workQueue中获取线程然后执行。当workQueue中没有任务的时候,worker就会阻塞,直到队列中有任务了就取出来继续执行。
-
public ThreadPoolExecutor(int corePoolSize, //核心线程数 ,规定可运行的线程数 int maximumPoolSize, //最大线程数 long keepAliveTime, //存活时间 TimeUnit unit, //存活时间的时间单位 BlockingQueue<Runnable> workQueue, //阻塞队列(用来保存等待被执行的任务) 存放任务的队列 ThreadFactory threadFactory, //线程工厂,主要用来创建线程 RejectedExecutionHandler handler //表示当拒绝处理任务时的策略,有以下四种取值 )注: 当线程池的饱和策略,当阻塞队列满了,且没有空闲的工作线程,如果继续提交任务,必须采取一种策略处理该任务,线程池提供了4种策略:
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
当然也可以根据应用场景实现RejectedExecutionHandler接口,自定义饱和策略,如记录日志或持久化存储不能处理的任务。
-
线程池的几种方式?应用场景
Executors类有一些静态方法可以创建线程池Executor。
newFixedThreadPool:创建固定长度的线程池
newCachedThreadPool:创建一个可缓存的线程池,自动回收空闲线程,自动扩展新线程
newSingleThreadExecutor:创建一个单线程来执行任务
newScheduledThreadPool:创建一个固定长度的线程池,可演示或定时执行任务
-
什么是死锁,如何预防?
-
死锁是指两个或两个以上的进程,因为资源的抢夺,而造成相互等待的情况,如果在无外力的情况下,他们无法推进下去,需要满足足四个条件:互斥条件,不剥夺条件,请求和保持条件,循环等待条件。
- 三种用于避免死锁的技术:
加锁顺序(线程按照一定的顺序加锁)
加锁时限(线程尝试获取锁的时候加上一定的时限,超过时限则放弃对该锁的请求,并释放自己占有的锁)
死锁检测
- 三种用于避免死锁的技术:
Java虚拟机篇
-
Java内存区域
-
-
程序计数器:当前线程所执行的字节码的行号指示器,通过改变计数器的值来选取下一条需要执行的字节码指令
-
java本地栈:本地栈为虚拟机使用到的Native方法服务,即被Native修饰的方法。
-
java虚拟机栈:虚拟机栈为java方法服务,存储局部变量表,操作数栈,动态链接,方法出口。局部变量表存放各种基本数据类型,对象引用。
-
java堆区: 存放几乎所有的对象实例,被所有线程所共享的内存区域,也是Java虚拟机所管理的最大一块内存。垃圾回收机制主要是在着,也被称做“GC堆”。所以 Java 堆中还可以细分为:新生代和老年代;再细致一点的有 Eden 空间、From Survivor 空间、To Survivor 空间等。从内存分配的角度来看,线程共享的 Java 堆中可能划分出多个线程私有的分配缓冲区(Thread Local Allocation Buffer,TLAB)。
-
元数据区(方法区):同样是被所有线程共享的区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据
-
JDK8的时候,永久代退出历史舞台,把JDK 7中永久代还剩余的内容(主要是类型信息)全部移到元空间中,方法区由本地内存的元空间实现。
-
元数据区代替永久代,以前永久代的字符串常量转移到堆内存中其他内容移至元空间,元空间直接在本地内存分配。
-
运行时常量池
-
直接内存
-
-
-
为什么要使用元空间取代永久代的实现?
- 字符串存在永久代中,容易出现性能问题和内存溢出。
- 类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
- 永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
- 将 HotSpot 与 JRockit 合二为一。
-
Java中的内存溢出是如何造成的
- 当无用对象不能被垃圾回收器收集的时,我们称之为内存泄露.
-
JVM垃圾回收机制
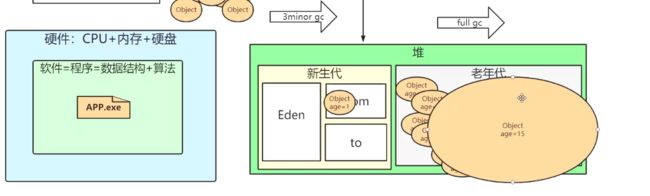
- 当java项目在运行时,会有很多object被类加载到堆中,堆中分为新生代和老年代,新生代中有Eden、s1,s2 一开始对象在eden区,随着每次发生minor gc的时候 对象的 age+1 有的对象一直被调用所以就没有被回收,进入了s1,s2,然后s1和s2 不断地更换,当object的age到了15 就进入了 老年代,当object的age到了35的时候机会发生full gc 被回收、
-
JVM为什么要回收
- 随着项目的运行,越来越多的对象被放到了堆栈中,而物理内存是有限的,最终导致电脑运行卡顿,所以对堆中没有引用的对象进行回收,来降低JVM虚拟机对物理内存的占用
-
JVM如何判断对象是可以被回收?
-
引用计数:每当有需要引用对象的地方就对对象的计数+1,引用失效则-1,
优点:实现简单、判断效率高。 缺点:难以解决对象之间的循环引用问题。
-
可达性分析算法:从一系列“GC Roots”对象作为起始点,从这些节点向下搜索,搜索走过的路径叫引用链。从GC Roots到该对象不可达,则该对象不可用。
Java中GC Roots包括以下几种对象:
a.虚拟机栈(帧栈中的本地变量表)中引用的对象
b.方法区中静态属性引用的对象
c.方法区中常量引用的对象
d.本地方法栈中JNI引用的对象
-
-
JVM GC如何回收对象?与其工作原理
- 标记-清除算法:标记所有要清除的对象,标记完成后统一清除,但是会产生大量不连续碎片
- 复制算法:将可用内存分为大小相等的两份,每次只使用一块。当一块内存用完了,就把还存活的对象复制到另外一块上,把使用过的内存空间清理掉。
- 标记-整理算法:标记完后,所有存活对象向一端移动,然后直接清理掉边界以外内存。
- 分代收集算法:把java堆分为新生代和老年代。新生代,每次垃圾收集都会有大批对象死去,少量存活,采用“复制”算法。老年代对象存活率高,可以使用“标记-清理”,“标记-整理”算法进行回收
-
垃圾收集器有哪些
-
Serial(单线程)
Serial GC,它是最古老的垃圾收集器,“Serial”体现在其收集工作是单线程的,并且在进行垃圾收集过程中,会进入臭名昭著的“Stop-The-World”状态。当然,其单线程设计也意味着精简的 GC 实现,无需维护复杂的数据结构,初始化也简单,所以一直是 Client 模式下 JVM 的默认选项。
从年代的角度,通常将其老年代实现单独称作 Serial Old,它采用了标记 - 整理(Mark-Compact)算法,区别于新生代的复制算法。
Serial GC 的对应 JVM 参数是:-XX:+UseSerialGC
-
ParNew(多线程)
很明显是个新生代 GC 实现,它实际是 Serial GC 的多线程版本,最常见的应用场景是配合老年代的 CMS GC 工作,下面是对应参数:
-XX:+UseConcMarkSweepGC -XX:+UseParNewGC
-
CMS
基于标记 - 清除(Mark-Sweep)算法,设计目标是尽量减少停顿时间,这一点对于 Web 等反应时间敏感的应用非常重要,一直到今天,仍然有很多系统使用 CMS GC。但是,CMS 采用的标记 - 清除算法,存在着内存碎片化问题,所以难以避免在长时间运行等情况下发生 full GC,导致恶劣的停顿。另外,既然强调了并发(Concurrent),CMS 会占用更多 CPU 资源,并和用户线程争抢。
-
Parrallel GC(并行),
在早期 JDK 8 等版本中,它是 **server** 模式 JVM 的默认 GC 选择,也被称作是吞吐量优先的 GC。它的算法和 Serial GC 比较相似,尽管实现要复杂的多,其特点是新生代和老年代 GC 都是并行进行的,在常见的服务器环境中更加高效。开启选项是:-XX:+UseParallelGC
-
G1 GC
这是一种兼顾吞吐量和停顿时间的 GC 实现,是 Oracle JDK 9 以后的默认 GC 选项。G1 可以直观的设定停顿时间的目标,相比于 CMS GC,G1 未必能做到 CMS 在最好情况下的延时停顿,但是最差情况要好很多。
G1 GC 仍然存在着年代的概念,但是其内存结构并不是简单的条带式划分,而是类似棋盘的一个个 region。Region 之间是复制算法,但整体上实际可看作是标记 - 整理(Mark-Compact)算法,可以有效地避免内存碎片,尤其是当 Java 堆非常大的时候,G1 的优势更加明显。
G1 吞吐量和停顿表现都非常不错,并且仍然在不断地完善,与此同时 CMS 已经在 JDK 9 中被标记为废弃(deprecated),所以 G1 GC 值得你深入掌握。
-
-
JVM回收机制的优化
-
性能调优建议:
-
针对JVM堆的设置,一般可以通过-Xms -Xmx限定其最小、最大值,为了防止垃圾收集器在最小、最大之间收缩堆而产生额外的时间,通常把最大、最小设置为相同的值;
-
年轻代和年老代将根据默认的比例(1:2)分配堆内存, 可以通过调整二者之间的比率NewRadio来调整二者之间的大小,也可以针对回收代。比如年轻代,通过 -XX:newSize -XX:MaxNewSize来设置其绝对大小。同样,为了防止年轻代的堆收缩,我们通常会把-XX:newSize -XX:MaxNewSize设置为同样大小。
-
年轻代和年老代设置多大才算合理
1)更大的年轻代必然导致更小的年老代,大的年轻代会延长普通GC的周期,但会增加每次GC的时间;小的年老代会导致更频繁的Full GC
2)更小的年轻代必然导致更大年老代,小的年轻代会导致普通GC很频繁,但每次的GC时间会更短;大的年老代会减少Full GC的频率
如何选择应该依赖应用程序对象生命周期的分布情况: 如果应用存在大量的临时对象,应该选择更大的年轻代;如果存在相对较多的持久对象,年老代应该适当增大。但很多应用都没有这样明显的特性。
在抉择时应该根 据以下两点:
(1)本着Full GC尽量少的原则,让年老代尽量缓存常用对象,JVM的默认比例1:2也是这个道理 。
(2)通过观察应用一段时间,看其他在峰值时年老代会占多少内存,在不影响Full GC的前提下,根据实际情况加大年轻代,比如可以把比例控制在1:1。但应该给年老代至少预留1/3的增长空间。
-
-
在配置较好的机器上(比如多核、大内存),可以为年老代选择并行收集算法: -XX:+UseParallelOldGC 。
-
线程堆栈的设置:每个线程默认会开启1M的堆栈,用于存放栈帧、调用参数、局部变量等,对大多数应用而言这个默认值太了,一般256K就足用。
理论上,在内存不变的情况下,减少每个线程的堆栈,可以产生更多的线程,但这实际上还受限于操作系统。
-
-
ClassLoader的功能和工作模式
Java中的所有类,必须被装载到jvm中才能运行,这个装载工作是由jvm中的类装载器完成的,类装载器所做的工作实质是把类文件从硬盘读取到内存中,JVM在加载类的时候,都是通过ClassLoader的loadClass()方法来加载class的,loadClass使用双亲委派模式。
1、防止重复加载同一个
.class。通过委托去向上面问一问,加载过了,就不用再加载一遍。保证数据安全。
2、保证核心.class不能被篡改。通过委托方式,不会去篡改核心.clas,即使篡改也不会去加载,即使加载也不会是同一个.class对象了。不同的加载器加载同一个.class也不是同一个Class对象。这样保证了Class执行安全
-
锁机制
-
解释是一下什么是线程安全?举例说明一个线程不安全的例子。
- 线程安全是指在多线程的情况下,当一个线程访问该类的某个数据时,对该类进行保护,其他线程不能访问直到该线程访问完成,不会出现数据不一致或者数据污染
- 当线程A对对象的某个数据赋值为11,线程B却赋值为22,当线程A再次访问该对象发现赋值变化了。被污染了
-
volatile
volatile是一种稍弱的同步机制,把变量声明为volatile类型后,JVM会注意到这个变量是共享的,不会进行重排序,也不会缓存到寄存器等不可见的地方,所以读取volatile类型的变量会返回最新写入的值
它在多处理器开发中保证了共享变量的“可见性”。可见性的意思是当一个线程修改一个共享变量时,另外一个线程能读到这个修改的值。
-
synchronized
synchronized可以保证方法或者代码块在运行时,同一时刻只有一个方法可以进入到临界区,同时它还可以保证共享变量的内存可见性
-
Synchronized方法锁、对象锁、类锁区别
- 无论是修饰方法还是修饰代码块都是 对象锁,当一个线程访问一个带
synchronized方法时,由于对象锁的存在,所有加synchronized的方法都不能被访问(前提是在多个线程调用的是同一个对象实例中的方法) - 2无论是修饰静态方法还是锁定某个对象,都是 类锁.一个class其中的静态方法和静态变量在内存中只会加载和初始化一份,所以,一旦一个静态的方法被申明为
synchronized,此类的所有的实例化对象在调用该方法时,共用同一把锁,称之为类锁。
- 无论是修饰方法还是修饰代码块都是 对象锁,当一个线程访问一个带
-
synchronized(隐式锁) 与 lock (显示锁)的区别
所谓的显示和隐式就是在使用的时候,使用者要不要手动写代码去获取锁和释放锁的操作。
- synchronized 是java的关键字,jvm来维护,lock是java的类jdk5后
- synchronized 无法判断锁的状态,lock可以判断锁的状态
- synchronized 可以自动释放锁,lock需要手动释放
- synchronized 的锁不可中断,lock的锁可以中断,轮询,定时
- synchronized锁适合代码少量的同步问题,Lock锁适合大量同步的代码的同步问题
-
读写锁和互斥锁
-
读写锁:允许多个读操作同时进行,但每次只允许一个写操作。
读写锁的机制:
* "读-读"不互斥
* "读-写"互斥
* "写-写"互斥即在任何时候必须保证:
* 只有一个线程在写入;
* 线程正在读取的时候,写入操作等待;
* 线程正在写入的时候,其他线程的写入操作和读取操作都要等待 -
互斥锁:一个线程获得资源的使用权后就会将该资源加锁,使用完后会将其解锁。所以不能读/读,不能写/写,更不能读/写
-
-
CAS乐观锁和悲观锁,行锁和表锁
- 悲观锁:顾名思义 总是假设最坏的情况,每次拿数据的时候总觉得别人会修改数据,所以拿到数据的时候就上锁,别人想拿到数据,就会堵塞直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。再比如Java里面的同步原语synchronized关键字的实现也是悲观锁。
- 乐观锁:顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
- Compare and Swap ( CAS )。CAS是乐观锁技术,其主要步骤是冲突检测和数据更新。当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。
设计模式
-
设计模式的设计理念
- 为了重用代码、让代码更容易被他人理解、保证代码可靠性。
- 开闭原则:对扩展开放,对修改关闭。
- 里氏代换原则:实现子父类互相替换,即继承;
- 依赖倒转原则:针对接口编程,实现开闭原则的基础;
- 接口隔离原则:降低耦合度,接口单独设计,互相隔离;
- 迪米特法则,又称不知道原则:功能模块尽量独立;
- 单一职责原则:一个类只负责一项职责
- 合成复用原则:尽量使用聚合,组合,而不是继承;
-
单例模式-》饿汉模式和懒汉模式
-
饿汉模式
/* *饿汉式 *类加载到内存后,就实例化一个单例,Jvm保证线程安全 *缺点:不管是否使用到了,类装载时就完成实例化 *(话说 你不用你装载它干啥) */ public class Mar01 { private static final Mar01 INSTANCE = new Mar01(); private Mar01() { } public static Mar01 getInstance() { return INSTANCE; } public void m(){ System.out.println("m"); } public static void main(String[] args) { Mar01 mar01=Mar01.getInstance(); Mar01 mar02=Mar01.getInstance(); System.out.println(mar01==mar02); } } -
懒汉模式
/* *lazy loading 懒汉模式 * 虽然达到了按需初始化 但是出现了线程不安全的问题 * */ class Mar01 { private static Mar01 INSTANCE; private Mar01() { }; public static Mar01 getInstance() {b if (INSTANCE == null) {// 如果线程A判断INSTANCE==null 然后 线程B执行了下面代码 创建了Mar01 然后A判断通过后 会创建2个Mar01 造成线程不安全问题 try { Thread.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } INSTANCE = new Mar01(); } return INSTANCE; } public void m() { System.out.println("m"); } public static void main(String[] args) { for (int i = 0; i < 100; i++) { new Thread(() -> { System.out.println(Mar01.getInstance().hashCode()); }).start(); } } } -
完美解决方法 静态内部方法
/* *静态内部类 * jvm保证单例 * 加载外部类,不会加载内部类,这样可以实现懒加载 */ class Mar01 { private Mar01() { }; private static class Mar01Holder { private final static Mar01 INSTANCE=new Mar01(); } public static Mar01 getInstance(){ return Mar01Holder.INSTANCE; } public void m() { System.out.println("m"); } public static void main(String[] args) { for (int i = 0; i < 100; i++) { new Thread(() -> { System.out.println(Mar01.getInstance().hashCode()); }).start(); } } }
-
JAVA I/O篇
-
NIO 和传统 IO 之间第一个最大的区别是
1. IO 是面向流的,NIO 是面向缓冲区的。- I/O主要有字符流和字节流组成,NIO主要有buffer和channel,selector(选择去)组成
-
阻塞IO与非阻塞IO的区别
-
阻塞性I/O是用户线程出现IO请求时,判断数据是否就绪,未就绪等待,用户线程阻塞,交出CPU,就绪后在执行,结束block状态。data = socket.read();
-
非阻塞性I/O是用户发送IO请求时,判断数据是否就绪并直接返回结果error,进行while循环 一直请求,直到准备好了,并且接收到用户请求才执行,也就是非阻塞I/O不交出CPU 从获得CPU一直到数据准备好了 完成I/O操作才释放
-
while(true){ data = socket.read(); if(data!= error){ 处理数据 break; } }
-
-
多路复用I/O当用户发起I/O请求时,会有一个线程不断去轮询socket的状态,当socket真正有读写时间的时候,才会调用资源进行I/O读写操作在 Java NIO 中,是通过 selector.select()去查询每个通道是否有到达事件。
- 多路复用优点:比非阻塞效率要高的原因是因为 多路复用是使用内核去轮询socket 非阻塞是使用的用户线程去轮询
- 多路复用缺点:一旦事件响应体很大,那么就会导致后续的事件迟迟得不到处理,并且会影响新的事件轮询。
-
异步I/O
当用户线程发起请求,内核接收到了 asynchronous read 之后立即返回结果,如果数据准备好了就返回状态 用户线程继续执行,不阻塞用户线程,直接使用数据(当完成后将结果拷贝给用户线程)
-
buffer和channel
-
buffer是是缓冲区,channel 是通道,
-
一般数据都是成channel 通道开始,可以读取buffer内的数据 也可以写入数据到buffer
-
channel和I/O中的流比较相似,但是不同在于流是单向的 channel是双向。
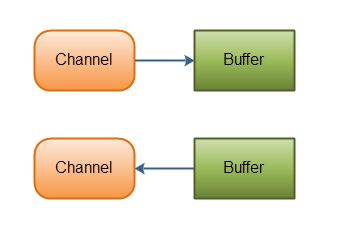
-
-
非直接缓冲区和直接缓冲区的区别
- 非直接缓冲区,通过 allocate() 方法分配缓冲区,将缓冲区建立在 JVM 的内存中
-
-
直接缓冲区,通过allocateDirect() 方法分配缓冲区,将缓冲区建立在物理内存中
-
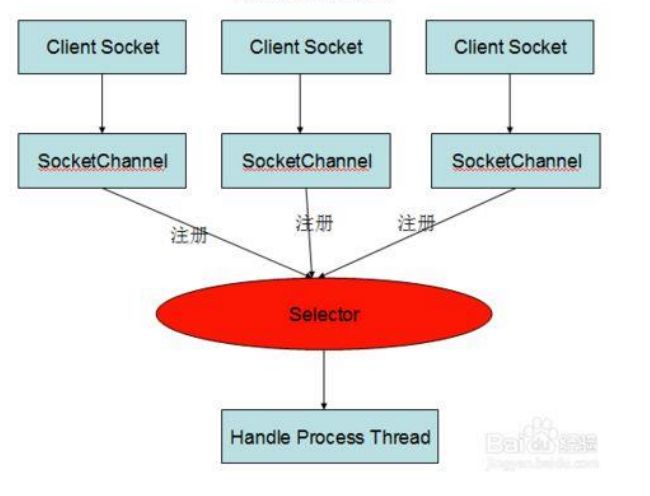
selector是什么?
-
选择区,用来监听多个注册的信道的连接打开和数据到达,实现单线程监控多个信道。
2.
-
Java NIO Channel通道和流非常相似,主要有以下几点区别:
- 通道可以读也可以写,流一般来说是单向的(只能读或者写,所以之前我们用流进行IO操作的时候需要分别创建一个输入流和一个输出流)。
-
-
通道可以异步读写。
- 通道总是基于缓冲区Buffer来读写。-
Channel的几种实现
-
FileChannel 用于文件数据读写
-
DatagramChannel 主要用于DCP的读写
-
SocketChannel 用于TCP数据读写,主要是客户端
-
ServerSocketChannel 允许我们监听TCP请求,每个请求会创建会一个SocketChannel主要是服务器端
如果要从写入缓冲区 读取数据需要调用
buffer.filp()方法 将Buffer从写模式变为可读模式
package filechannel; import java.io.IOException; import java.io.RandomAccessFile; import java.nio.ByteBuffer; import java.nio.channels.FileChannel; public class FileChannelTxt { public static void main(String args[]) throws IOException { //1.创建一个RandomAccessFile(随机访问文件)对象, RandomAccessFile raf=new RandomAccessFile("D:\\niodata.txt", "rw"); //通过RandomAccessFile对象的getChannel()方法。FileChannel是抽象类。 FileChannel inChannel=raf.getChannel(); //2.创建一个读数据缓冲区对象 ByteBuffer buf=ByteBuffer.allocate(48); //3.从通道中读取数据 int bytesRead = inChannel.read(buf); //创建一个写数据缓冲区对象 ByteBuffer buf2=ByteBuffer.allocate(48); //写入数据 buf2.put("filechannel test".getBytes()); buf2.flip(); inChannel.write(buf); while (bytesRead != -1) { System.out.println("Read " + bytesRead); //Buffer有两种模式,写模式和读模式。在写模式下调用flip()之后,Buffer从写模式变成读模式。 buf.flip(); //如果还有未读内容 while (buf.hasRemaining()) { System.out.print((char) buf.get()); } //清空缓存区 buf.clear(); bytesRead = inChannel.read(buf); } //关闭RandomAccessFile(随机访问文件)对象 raf.close(); } } public abstract class FileChannel extends AbstractInterruptibleChannel implements SeekableByteChannel, GatheringByteChannel, ScatteringByteChannel 1. 开启FileChannel
因为fileChannel 是虚拟类 无法直接实现,需要通过InputStream,OutStream及RandoAccessFile 开启。
2.从FileChannel读取数据/写入数据
创建读取缓冲区将数据读取
ByteBuffer buf=ByteBuffer.allocate(48);
inChannel.read(buf1);
创建写入缓冲区将数据写入
ByteBuffer buf2=ByteBuffer.allocate(48);
buf2.put(“filechannel test”.getBytes());//将这句话写入到文本中buf2.flip(); inChannel.write(buf2);3.关闭通道
channel.close();5. SocketChannel和ServerSocketChannel ```java 客户端 开启SocketChannel 1.通过SocketChannel连接到远程服务器 2.创建读数据/写数据缓冲区对象来读取服务端数据或向服务端发送数据 3.关闭SocketChannel //1.通过SocketChannel的open()方法创建一个SocketChannel对象 SocketChannel socketChannel = SocketChannel.open(); //2.连接到远程服务器(连接此通道的socket) socketChannel.connect(new InetSocketAddress("127.0.0.1", 3333)); //3.创建缓冲区 读取写入 关闭 服务端 ``` ``` 1.通过ServerSocketChannel 绑定ip地址和端口号 2.通过ServerSocketChannelImpl的accept()方法创建一个SocketChannel对象用户从客户端读/写数据 3.创建读数据/写数据缓冲区对象来读取客户端数据或向客户端发送数据 4. 关闭SocketChannel和ServerSocketChannel .通过ServerSocketChannel 的open()方法创建一个ServerSocketChannel对象,open方法的作用:打开套接字通道 ServerSocketChannel ssc = ServerSocketChannel.open(); //2.通过ServerSocketChannel绑定ip地址和port(端口号) ssc.socket().bind(new InetSocketAddress("127.0.0.1", 3333)); //通过ServerSocketChannelImpl的accept()方法创建一个SocketChannel对象用户从客户端读/写数据 SocketChannel socketChannel = ssc.accept();-
DatagramChannel的使用
- DataGramChannel,类似于java 网络编程的DatagramSocket类;使用UDP进行网络传输, UDP是无连接,面向数据报文段的协议,对传输的数据不保证安全与完整
-
-
//1.通过DatagramChannel的open()方法创建一个DatagramChannel对象 DatagramChannel datagramChannel = DatagramChannel.open(); //绑定一个port(端口) datagramChannel.bind(new InetSocketAddress(1234)); --------------------------------------- 因为是无连接的 无需建立连接 只需要知道地址就可以 2.接收消息 //先创建一个缓存区对象, ByteBuffer buf = ByteBuffer.allocate(48); buf.clear(); //然后通过receive方法接收消息,这个方法返回一个SocketAddress对象,表示发送消息方的地址 channel.receive(buf); 3.发送消息: //创建缓冲区 ByteBuffer buf = ByteBuffer.allocate(48); buf.clear(); //输入要发送的内容 buf.put("datagramchannel".getBytes()); //改为读模式 buf.flip(); 发送的地址 返回发送成功的字节数 int send = channel.send(buffer, new InetSocketAddress("localhost",1234)); -
通道之间的数据传输
- 在Java NIO中如果一个channel是FileChannel类型的,那么他可以直接把数据传输到另一个channel。
- transferFrom() :transferFrom方法把数据从通道源传输到FileChannel
- transferTo() :transferTo方法把FileChannel数据传输到另一个channel
- 在Java NIO中如果一个channel是FileChannel类型的,那么他可以直接把数据传输到另一个channel。
-
Scattering Reads
- “scattering read”是把数据从单个Channel写入到多个buffer,
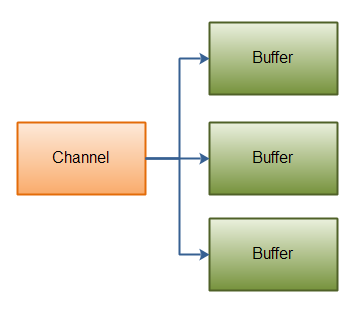
-
Gathering Writes
-
“gathering write”把多个buffer的数据写入到同一个channel中,
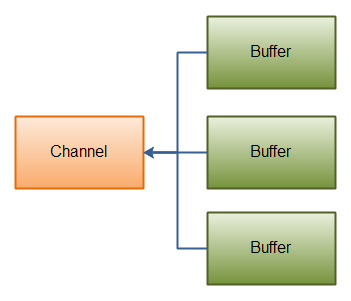
-
-
-
数据库篇
-
InnoDB和MyISAM的区别 和应用场景
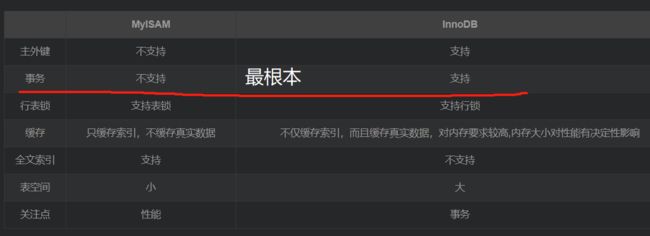
- 应用场景
- MyISAM是非事务表,提供快速的检索和高效的存储,如果应用中有大量的Select查询,使用MyISAM 是非常合适的
- Innodb是事务处理程序,具有众多特性,包括ACID事务支持,如果应用中由很多的Insert和Update操作,建议使用Innodb
- MyISAM特点
- 执行读取速度快,
- 不占用大量内存
- 支持全局索引,
- 支持表锁
- 不支持事务和外键
- InnoDB的特点 =>InnoDB 底层存储结构为B+树
- 经常更新的表,适合处理多重并发的更新请求。
- 支持事务。
- 可以从灾难中恢复(通过 bin-log 日志等)。
- 外键约束。只有他支持外键。
- 支持自动增加列属性 auto_increment
- 应用场景
-
InnoDB的事务和日志
- InnoDB有错误日志,查询日志,慢查询日志,二进制日志,事务日志。
错误日志:记录出错信息
查询日志:记录所有对数据库请求的信息
慢查询日志:设置一个阈值,运行时间超过该值的所有SQL语句都会被记录下来。
二进制日志:记录对数据库执行更改的所有操作
事务的原子性,一致性,隔离性,持久性。
并发事务产生的原因
- 脏读(dirty read):读到未提交更新数据,即读取到了脏数据;
- 幻读(phantom read):对同一张表的两次查询不一致,因为另一事务插入了一条记录;
- 不可重复读(unrepeatable read):对同一记录的两次读取不一致,因为另一事务对该记录做了修改;
- InnoDB有错误日志,查询日志,慢查询日志,二进制日志,事务日志。
-
事务4种隔离级别
- 串行化:不会出现任何并发问题,因为它是对同一数据的访问是串行的,非并发访问的;防止脏读,不可重读读,幻读
- 可重复读:防止脏读和不可重复读,不防幻读
- 读已提交:防止脏读,不防止不可重复读和幻读
- 读未提交:可能出现任何事务并发问题
-
Sql优化
- 索引失效:
- sql优化就是在编写查询SQL语句的过程中尽量用上索引,避免索引失效,避免全表扫描。
- 应尽量避免在 where 子句中对字段进行 null 值判断
- 最佳左前缀法则:如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
- 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
- 应尽量避免在 where 子句中使用!=或<>操作符,‘%模糊查询%’,字符串添加单引号
- 使用explan sql 对语句进行SQL语句优化
- 索引失效:
-
索引优化
频繁作为查询条件的字段应该创建索引
经常增删改的表不创建索引
单键/组合索引的选择问题,who?(在高并发下倾向创建组合索引)
关联查询优化:小表驱动大表,大表join字段已经被索引
order by关键字优化:尽量Index方式,避免FileSort排序;尽可能在索引列上完成排序操作,遵照索引建的最佳左前缀
GROUP BY关键字优化:group by实质是先排序后进行分组,遵照索引建的最佳左前缀;where高于having,能写在where限定的条件就不要去having限定了。 -
索引是什么?
- 索引是排好序的快速高效查找数据的数据结构.索引往往以索引文件的形式存储的磁盘上
-
索引的分类
-
普通索引:仅加速查询
-
唯一索引:加速查询 + 列值唯一(可以有null)
-
主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个
-
组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
-
全文索引:对文本的内容进行分词,进行搜索
注意:聚簇索引并不是一种单独的索引类型,而是一种数据存储方式,表示数据行和相邻的键值的存储在一起。数据行在磁盘的排列和索引排序保持一致。在查询的时候因为数据紧密相连的,不用从多个数据块提取,节约时间
-
-
什么时候应该使用索引?
- 表中的字段频繁被where 查询,建立索引
- 表中的外键,与其他表关联的建立索引
- order by group by的字段可以建立索引。
-
什么时候不建议使用索引?
- 表数据太少
- 频繁insert,update
- 数据重复且分布平均的表字段,因此应该只为最经常查询和最经常排序的数据列建立索引。
- 索引其实是用空间换时间的概念,所以要很良好两者之间的舍去。
-
BTree和B+Tree的区别
-
Mysql索引类型Btree和Hash的区别以及使用场景
 2. BTREE类型的索引,在存储的时候是存储的Kay-value的形式在链表上有顺序的存储。 3. 为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引? 1. B+树的磁盘读写代价更低 2. B+树的查询效率更加稳定 4. 在B_TREE上查找x,现将x的关键字与根结点的n个关键字di逐个比较,然后做如下处理: - 若x.key==28,则查找成功返回; - 若x.key<28,则沿着指针p1所指的子树继续查找; - 若28 -
什么是show profile?
- 是mysql提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于SQL的调优的测量
诊断SQL,show profile cpu,block io for query
- 是mysql提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于SQL的调优的测量
-
查询语句中select from where group by having order by的执行顺序
-
from–where–group by–having–select–order by,
from:需要从哪个数据表检索数据
where:过滤表中数据的条件
group by:如何将上面过滤出的数据分组
having:对上面已经分组的数据进行过滤的条件
select:查看结果集中的哪个列,或列的计算结果
order by :按照什么样的顺序来查看返回的数据
-
SQL Select语句完整的执行顺序【从DBMS使用者角度】:
1、from子句组装来自不同数据源的数据;
2、where子句基于指定的条件对记录行进行筛选;
3、group by子句将数据划分为多个分组;
4、使用聚集函数进行计算;
5、使用having子句筛选分组;
6、计算所有的表达式;
7、使用order by对结果集进行排序。
-
Spring框架
-
Spring管理如何创建自定义注解
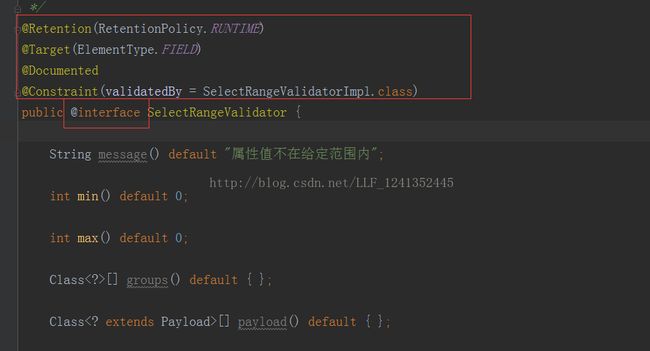
- 只要在定义接口的基础上再interface前面加上@符号,这时候接口就变成了注解的定义了。但是还不完全是完成了注解,还要加上上面几个关键字
- @ target表示该注解的作用域,值有TYPE, METHOD, CONSTRUCTOR, FIELD,我们常用field和method,表示作用在java bean的字段和作用在方法层面上。
- @retention表示注解类型保留时间的长短,它接收RetentionPolicy参数,可能的值有SOURCE, CLASS, 以及RUNTIME,我们常用runtime,表示
- @constraint表示注解的约束关系,其中有属性值validateBy这个属性开放出来给我么使用,目的是设定约束关系的实现类,这点与我们上面谈到的第2点有关
- @document表示该注解可以被javadoc等工具文档化
-
Spring 如何创建对象?
-
利用构造函数创建对象
-
<bean class="com.mc.base.learn.spring.bean.Person" id="person"> <constructor-arg name="id" value="123">constructor-arg> <constructor-arg name="name" value="LiuChunfu">constructor-arg> bean>
-
-
通过静态方法创建对象
-
<bean id="person" class="com.mc.base.learn.spring.factory.PersonStaticFactory" factory-method="createPerson">bean>
-
-
通过工厂方法创建对象
-
<bean id="personFactory" class="com.mc.base.learn.spring.factory.PersonFactory">bean> <bean id="person2" factory-bean="personFactory" factory-method="createInstance">bean>
-
-
-
Spring 如何解决循环依赖的问题
-
三级缓存
- singletonFactories : 单例对象工厂的cache
- earlySingletonObjects :提前暴光的单例对象的Cache 。【用于检测循环引用,与singletonFactories互斥】
- singletonObjects:单例对象的cache
-
分析getSingleton()的整个过程,Spring首先从一级缓存singletonObjects中获取。如果获取不到,并且对象正在创建中,就再从二级缓存earlySingletonObjects中获取。如果还是获取不到且允许singletonFactories通过getObject()获取,就从三级缓存singletonFactory.getObject()(三级缓存)获取,
Spring解决循环依赖的诀窍就在于singletonFactories这个三级cache。这个cache的类型是ObjectFactory
alue=“LiuChunfu”>
-
通过静态方法创建对象
-
<bean id="person" class="com.mc.base.learn.spring.factory.PersonStaticFactory" factory-method="createPerson">bean>
-
-
通过工厂方法创建对象
-
<bean id="personFactory" class="com.mc.base.learn.spring.factory.PersonFactory">bean> <bean id="person2" factory-bean="personFactory" factory-method="createInstance">bean>
-
-
-
Spring 如何解决循环依赖的问题
-
三级缓存
- singletonFactories : 单例对象工厂的cache
- earlySingletonObjects :提前暴光的单例对象的Cache 。【用于检测循环引用,与singletonFactories互斥】
- singletonObjects:单例对象的cache
-
分析getSingleton()的整个过程,Spring首先从一级缓存singletonObjects中获取。如果获取不到,并且对象正在创建中,就再从二级缓存earlySingletonObjects中获取。如果还是获取不到且允许singletonFactories通过getObject()获取,就从三级缓存singletonFactory.getObject()(三级缓存)获取,
Spring解决循环依赖的诀窍就在于singletonFactories这个三级cache。这个cache的类型是ObjectFactory
-