Kubernetes 中, 容器总是以 Pod(容器组)的方式进行调度与运行。因此对 Pod 的理解与掌握是学习 Kubernetes 的基础。
理解 Pod
Pod(容器组)是 Kubernetes 中最小的调度单元,每一个Pod都是某个应用程序的一个运行实例。以前我们的 Web 应用都是以 Tomcat 等 Web 容器进程的形式运行在操作系统中,在 Kubernetes 中,我们需要将 Web 应用打成镜像,以容器的方式运行在 Pod 中。
Kubernetes 不会直接管理容器,而是通过 Pod 来管理。一个Pod包含如下内容:
- 一个或多个容器, 一般是一个,除非多个容器紧密耦合共享资源才放在一个 Pod 中;
- 共享的存储资源(如数据卷),一个 Pod 中的容器是可以共享存储空间的;
- 一个共享的 IP 地址,Pod 中容器之间可以通过 localhost:port 彼此访问;
- 定义容器该如何运行的选项。
Pod 中的容器可包括两种类型:
- 工作容器:就是我们通常运行服务进程的容器
- 初始化容器:完成一些初始化操作的容器,初始化容器在工作容器之前运行,所有的初始化容器成功执行后,才开始启动工作容器
管理 Pod
创建 Pod
在 Kubernetes 中,我们一般不直接创建 Pod,而是通过控制器来调度管理(Deployment,StatefulSet,DaemonSet 等),这里为了便于了解,先通过 yaml 配置文件的方式定义 Pod 来直接创建 Pod。定义配置文件 pod-test.yaml 如下,
apiVersion: v1
kind: Pod
metadata:
name: pod-test # pod 名称
namespace: default # pod 创建的 namespace
spec:
containers: # pod 中容器定义
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
hostPort: 8081
volumeMounts:
- name: workdir
mountPath: /usr/share/nginx/html
restartPolicy: OnFailure # 重启策略
volumes: # 数据卷定义
- name: workdir
hostPath:
path: /tmp
type: Directory
其中 spec 部分的 containers 定义了该 Pod 中运行的容器,从 containers 的复数形式也可以看出一个 Pod 中是可以运行多个容器的。
执行 kubectl create 或 kubectl apply 命令创建 Pod,
[root@kmaster test]# kubectl create -f pod-test.yaml
或
[root@kmaster test]# kubectl apply -f pod-test.yaml
该 Pod 创建后将会拉取一个最新的 nginx 镜像,运行一个 nginx 容器,并将容器的 80 端口映射到宿主机的 8081 端口。
查看 Pod
可使用 kubectl get pods 命令查看当前 namesapce 下的所有 Pod,加 Pod 名称查看具体某个 Pod。 如果需要查看 Pod 调度到了哪个节点,可加 -o wide 选项,如果查看 yaml 文件信息则可加 -o yaml 选项, 如下所示
[root@kmaster test]# kubectl get pods
NAME READY STATUS RESTARTS AGE
pod-test 1/1 Running 0 116s
[root@kmaster test]# kubectl get pods pod-test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-test 1/1 Running 0 2m19s 10.244.1.42 knode2
[root@kmaster test]# kubectl get pods pod-test -o yaml
如果要查看更多的信息,可使用 kubectl describe 命令,
[root@kmaster test]# kubectl describe pod pod-test
该命令输出内容如下图,
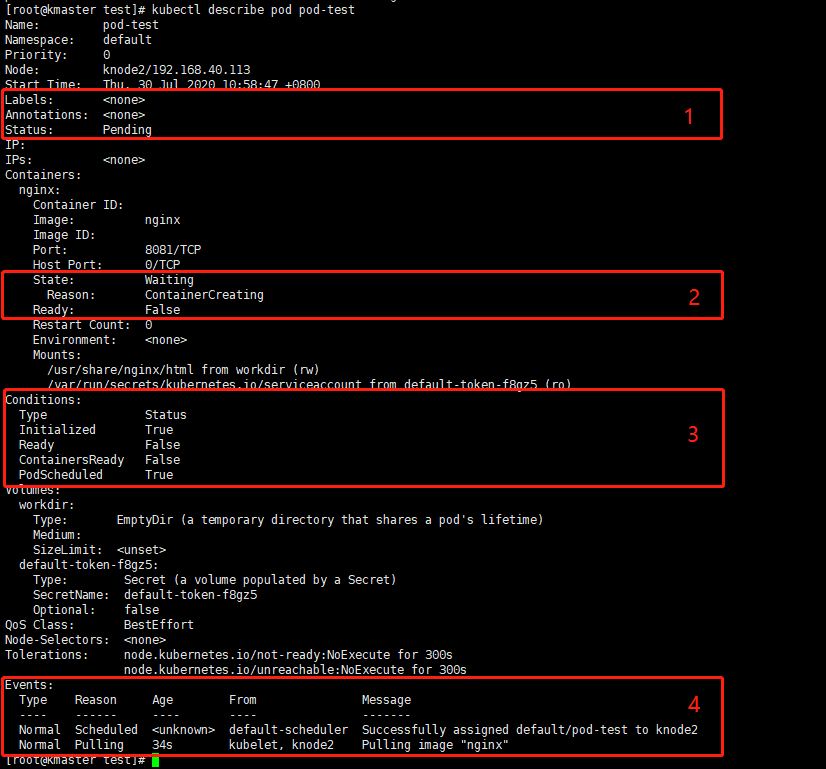
各部分说明:
- Status: Pending, 表示 Pod 的整体状态,当前处于 Pending 状态;
- State: Waiting,Pod 中每个容器都有一个自己的状态 State, 当前容器 nginx 处于 Waiting 状态,Reason: ContainerCreating 表示容器还处于创建中,Ready:False 表明容器还未就绪,还不能对外提供服务;
- Conditions, 这部分聚合了一些状态,第一个 Initialized:True,表明已经完成了初始化;而第二个 Ready:False,表明 Pod 还未就绪;ContainersReady:False,表明容器还未就绪; PodScheduled:True,表明 Pod 已经被调度到某个具体的节点上了;
- 3中不同的状态之间的转换都会发生相应的事件,事件类型包括 Normal 与 Warning 两种, 从上图可看到一个 Pulling image 的 Normal 事件,表示当前正在拉取 Pod 中容器的镜像。
当 Pod 在调度或运行中出现问题时,我们都可以使用 kubectl describe 命令来进行排查,通过其中的状态及事件来判断问题产生的可能原因。
进入 Pod 容器
通过 kubectl exec 命令可进入 Pod, 类似于 docker exec, 如
# 如果 Pod 中只有一个容器
[root@kmaster test]# kubectl exec -it pod-test bash
root@pod-test:/#
# 如果 Pod 中有多个容器
kubectl exec -it pod-name -c container-name /bin/bash
如果一个 Pod 中有多个容器,则需要通过 -c 指定进入哪个容器。
更新/删除 Pod
Kubernetes 对 Pod 的更新做了限制,除了更改 Pod 中容器(包括工作容器与初始化容器)的镜像,以及 activeDeadlineSeconds (对 Job 类型的 Pod 定义失败重试的最大时间), tolerations (Pod 对污点的容忍),修改其它部分将不会产生作用,如我们可以尝试在前面 Pod 定义文档 pod-test.yaml 中将宿主机端口 8081 改为 8082,重新执行 kubectl apply, 将提示如下错误,
[root@kmaster test]# kubectl apply -f pod-test.yaml
The Pod "pod-test" is invalid: spec: Forbidden: pod updates may not change fields other than `spec.containers[*].image`, `spec.initContainers[*].image`, `spec.activeDeadlineSeconds` or `spec.tolerations` (only additions to existing tolerations)
通过 kubectl delete 命令可删除一个 Pod
[root@kmaster test]# kubectl delete pod pod-test
在 Kubernetes 中,一般不直接创建,更新或删除单个 Pod,而是通过 Kubernetes 的 Controller(控制器)来管理 Pod,包括 ReplicSet(一般也不直接用,推荐Deployment方式), Deployment,StatefulSet,DaemonSet 等。
控制器提供如下功能:
- 水平伸缩,控制运行 Pod 指定个数的副本
- rollout,即版本更新
- 故障恢复,当一个节点出现故障,或资源不够,或进入维护中,控制器会自动在另一个合适的节点调度一个一样的 Pod,以保障 Pod 以一定的副本数运行
Pod 状态
Pod状态并不是容器的状态,容器的状态一般包括:
Waiting: 容器的初始状态,处于 Waiting 状态的容器,表示仍然有对应的操作在执行,例如:拉取镜像、应用 Secrets等
Running: 容器处于正常运行的状态
Terminated: 容器处于结束运行的状态
而Pod的状态一般包括:
- Pending: Kubernetes 已经创建并确认该 Pod,可能两种情况: 1. Pod 还未完成调度(例如没有合适的节点);2. 正在从 docker registry 下载镜像
- Running: 该 Pod 已经被绑定到一个节点,并且该 Pod 所有的容器都已经成功创建,其中至少有一个容器正在运行,或者正在启动/重启
- Succeeded:Pod 中的所有容器都已经成功终止,并且不会再被重启
- Failed:Pod 中的所有容器都已经终止,至少一个容器终止于失败状态:容器的进程退出码不是 0,或者被系统 kill
- Unknown: 因为某些未知原因,不能确定 Pod 的状态,通常的原因是 master 与 Pod 所在节点之间的通信故障
状态之间的变迁关系如图
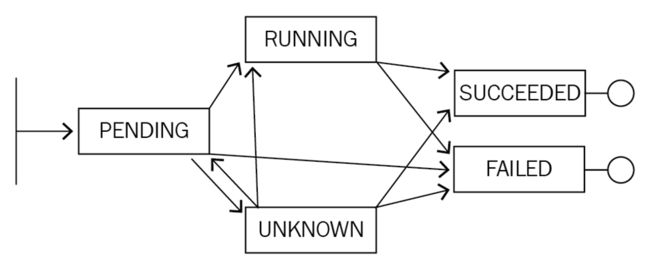
Pod 刚开始处于 Pending 的状态,接下来可能会转换到 Running,也可能转换到 Unknown,甚至可能转换到 Failed。然后,当 Running 执行了一段时间之后,它可以转换到类似像 Successded 或者是 Failed。 当出现 Unknown 这个状态时,可能由于一些状态的恢复,它会重新恢复到 Running 或者 Successded 或者是 Failed。
重启策略
定义 Pod 或工作负载时,可以指定 restartPolicy,可选的值有:
- Always:默认值,只要退出就重启
- OnFailure:失败退出时(exit code 不为 0)才重启
- Never: 永远不重启
restartPolicy 作用于 Pod 中的所有容器。kubelete 将在五分钟内,按照递延的时间间隔(10s, 20s, 40s ...)尝试重启已退出的容器,并在十分钟后再次启动这个循环,直到容器成功启动,或者 Pod 被删除。在控制器 Deployment/StatefulSet/DaemonSet 中,只支持 Always 这一个选项,不支持 OnFailure 和 Never 选项。
健康检查
提高应用服务的可用性与稳定性,一般可从两个方面来进行:
- 首先是提高应用的可观测性,如对应用的健康状态,资源的使用情况,应用日志等可进行实时的观测
- 第二是提高应用的可恢复能力,在应用出现故障时,能通过自动重启等方式进行恢复
Kubernetes 中对 Pod 的健康检查提供了两种方式:
- Readiness probe,就绪探测,用来判断一个 Pod 是否处于就绪状态,是否能对外提供相应服务了。当Pod处于就绪状态时,负载均衡器才会将流量打到这个 Pod,否则将把流量从这个 Pod 上面摘除。
- Liveness probe,存活探测,用来判断一个 Pod 是否处于存活状态,如果一个 Pod 被探测到不处于存活状态,则由上层判断机制来处理,如果上层配置重启策略为 restart always 的话,Pod 就会被重启。
Liveness probe 适用场景是支持那些可以重新拉起的应用,而 Readiness probe 主要应对的是启动之后无法立即对外提供服务的应用。
就绪探测、存活探测目前支持三种不同的探测方式:
- httpGet,通过发送http Get请求来判断,返回状态码在 200-399之间,认为是探测成功
- Exec,通过执行容器中的一个命令来判断服务是否正常,如果命令的退出状态码为 0,表示成功
- tcpSocket,通过容器的IP,端口来进行TCP连接检查,如果TCP连接能被正常建立,则认为成功
以 httpGet 为例,示例配置文件如下,
apiVersion: v1
kind: Pod
metadata:
name: pod-test
spec:
containers:
- # ... 与前同
- name: workdir
mountPath: /usr/share/nginx/html
livenessProbe:
httpGet:
path: /
port: 80
httpHeaders: # 此处header无意义,仅作示例
- name: purpose
value: for-test
initialDelaySeconds: 2
periodSeconds: 5
# ... 与前同
删除之前的 Pod, 重新创建,使用 kubectl describe 查看,可看到 Events 部分如下图,

Http 存活探测失败,状态码返回 403, 导致容器重启。出现这个错误的原因是前面做目录挂载时将 nginx 的 html 目录挂载到了宿主机的 /tmp 目录, 而 /tmp 目录没有 index.html 文件,导致请求返回403, 在 Pod 调度到的宿主机 /tmp 目录下创建 index.html 文件即可。
echo 'Hello, K8s!
' > /tmp/index.html
其它 Exec,tcpSocket 探测的配置示例如下(配置在 containers 元素下),
# exec
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
# tcpSocket
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
支持的参数说明:
- initialDelaySeconds:延迟探测时间,表示 Pod 启动延迟多久后进行一次检查,比如某个应用启动时间如果较长的话,可以设置该值为略大于启动时间;
- periodSeconds:探测频率,表示探测的时间间隔,正常默认的这个值是 10 秒;
- timeoutSeconds:超时时间,表示探测的超时时间,当超时时间之内没有检测成功,那会认为失败;
- successThreshold:健康阈值,表示当这个 Pod 从探测失败到再一次判断探测成功,所需要的阈值次数,默认情况下是 1 次。如果之前探测失败,接下来的一次探测成功了,就会认为这个 Pod 是处在一个正常的状态;
- failureThreshold: 不健康阈值,与 successThreshold 相对,表示认为探测失败需要重试的次数,默认值是 3。意思是当从一个健康的状态连续探测到 3 次失败,就会认为Pod 的状态处在一个失败的状态。
readinessProbe 配置与 livenessProbe 类似。阿里云上配置就绪检查如图所示:
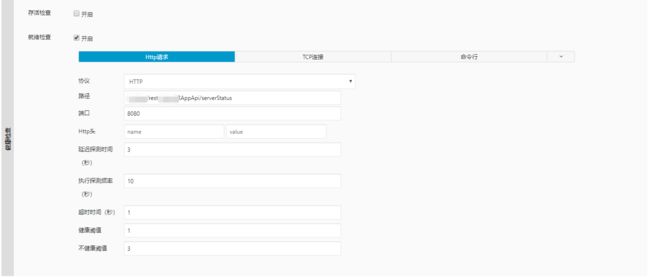
健康检查的结果分为三种:
- Success,表示 container 通过了健康检查,也就是 Liveness probe 或 Readiness probe 是正常的一个状态;
- Failure,表示 container 没有通过健康检查。针对 Readiness probe,service 层就会将没有通过 Readiness probe 的 pod 进行摘除,不再分发请求到该 Pod;针对 Liveness probe,就会将这个 pod 进行重新拉起,或者是删除。
- Unknown,表示当前的执行机制没有进行完整的一个执行,可能是因为类似像超时或者像一些脚本没有及时返回,此时 Readiness probe 或 Liveness probe 不做任何操作,会等待下一次的机制来进行检查。
健康检查的一些实践建议:
- 如果容器中的进程在碰到问题时可以自己 crash,就不需要执行存活探测,因为 kubelet 可以自动的根据 Pod 的 restartPolicy(重启策略)来执行对应的动作;
- 如果希望在容器的进程无响应后,将容器重启,则指定一个存活探测 livenessProbe,并同时指定 restartPolicy(重启策略)为 Always 或者 OnFailure;
- 如果希望在 Pod 确实就绪之后才向其分发服务请求,就指定一个就绪检查 readinessProbe;
- 适当调大 exec 探测的超时阈值,因为在容器里面执行一个 shell 脚本,它的执行时长是非常长的,平时在一台虚机上执行可能 3 秒返回的一个脚本在容器里面可能需要 30 秒。可以适当调大超时阈值,来防止由于容器压力比较大的时候出现偶发的超时;
- 调整失败判断的次数,3 次的默认值有时候可能不一定是最佳实践,适当调整一下判断的次数也是一个比较好的方式;
- 使用 tcpSocket 方式进行判断的时候,如果遇到了 TLS 的服务,那可能会造成后边 TLS 里面有很多这种未鉴权的 tcp 连接,这时候需要自己针对业务场景判断这种连接是否会对业务造成影响。
总结
本文对 Pod 的概念与基本的管理操作,Pod 的状态变迁机制与重启策略进行了介绍,对 Pod 的健康检查进行了详细的了解。但在 Kubernetes 中,我们一般不直接创建 Pod,而是通过控制器,如Deployment,StatefulSet,DaemonSet, 因为控制器能为我们提供水平伸缩,rollout(版本更新),self-healing(故障恢复)等能力。我们将在接下来的文章了解控制器。
[转载请注明出处]
作者:雨歌
欢迎关注作者公众号:半路雨歌,查看更多技术干货文章
