mongodb入门到应用(三)--设计应用篇(golang类库+企业实例及优化)
MongoDB的设计和应用
本篇内容简介:
一、MongoDB简介
1. MongoDB和MySQL 的名词映射
2. MySQL的数据迁移到MongoDB (通过CSV文件)
二、MongoDB的Golang类库使用
(demo+常用功能封装,详见下载:https://download.csdn.net/download/duringnone/12245262)
三、使用注意事项
四、设计模式+索引优化+MongoDB架构迭代
1. MongoDB的构建模式+ 部分实例(数据库设计规则参考)
2. 企业实例(构建模式 + 架构设计到优化方案)
3. 索引优化 + 架构思考【简介】
一、简介 (MongoDB介绍+使用可见前两篇博客)
1、MongoDB和Mysql 的名词映射
| RDBMS(关键字/解释) | MongoDB(关键字/解释) |
|---|---|
| 数据库(database) | 数据库(database) |
| 表格(table) | 集合(collection) |
| 行(row) | 文档(document) |
| 列(column) | 字段(field) |
| 表联合(table joins) | 嵌入文档() |
| 索引(index) | 索引(index) |
| 主键 | 主键(MongoDB提供了key为 _id) |
| Mysqld(服务端入口文件) | mongod(服务端入口文件) |
2. MySQL的数据迁移到MongoDB (通过CSV文件)
1) 将数据导入mongodb
/usr/local/mongodb/bin/mongoimport --db 目标数据库 --collection 目标数据集合 --type csv --headerline --ignoreBlanks --file 数据源文件 # 将数据源文件(csv格式)导入到目标数据库的目标集合中
实例:
/usr/local/mongodb/bin/mongoimport --db db_isr --collection tb_isr_visitors --type csv --headerline --ignoreBlanks --file /root/csv/tb_isr_records_1.csv # 将csv文件导入mongodb的db_isr.db_isr_visitors集合中
二、MongoDB的Golang类库
1. 类库github地址:
https://github.com/mongodb/mongo-go-driver // mongodb官方提供的golang类库(截止20200311,暂不支持$lookup联表操作)
2. go get安装命令:
go get -u go.mongodb.org/mongo-driver # 使用go get 安装
3. go get gopkg.in/mgo.v2 // 安装mgo包,mgo是老版本的golang类库,官方已停止维护,但支持$lookup操作
4. 如若需要使用MongoDB-Golang类库的同学,可以去笔者的资源文件中下载,MongoDB-Golang,这个文件目录是笔者在Golang中使用MongoDB时,基于 mgo, mongo-go-dirver 这两个MongoDB常用golang类库的封装
1)MongoDB-Golang涉及的功能:
A) mgo,mongo-go-driver的连接池,增加,删除,修改,查看,多表关联查询,管道聚合操作,事务操作,原生mongo shells命令执行 等功能
B)上述所有功能均提供了详细的demo实例,并提供使用MongoDB从0-1的过程描述,并标注笔者的踩坑点和经验;下载后注意先看readme.txt
2)mgo和mongo-go-driver的区别:
A) 二者提供的功能上有交集,有互补:mongo-go-driver是MongoDB官方提供的Golang类库,持续更新中,但截止2020-02-29时,version=1.4+,仍不支持 $lookup操作(多表关联查询)和$graph操作(MongoDB提供的地理位置查询);而 mgo 官方已经停止更新,但提供 $lookup操作 【实测】
B) 二者性能不同:笔者使用体验下来,mongo-go-driver性能优于mgo性能,体现在维护golang和MongoDB的连接和连接设置上,具体的有兴趣可以看看二者源码
C) 二者使用习惯不用:mgo使用的连贯操作更多(类似PHP的ThinkPHP5,tp3等框架),而mongo-go-driver使用依赖注入更多一些(类似PHP的YII2,Laravel等框架)
3)使用本MongoDB-Golang 工具代码块 适应人群
A 首先本代码块是基于企业业务的封装,具有普遍使用性,涵盖了绝大部分应用场景
B) 适合MongoDB初学者:降低学习成本,底层实现对使用者透明,操作简单,提升开发效率
C) 适合从RDB(关系型数据库)刚转用MongoDB的使用者:此封装照顾了 MySQL等RDB使用者的用户习惯,返回的数据格式和ORM(关系映射数据格式)基本一致,
D) 照顾了 PHP 转 Golang的使用者,笔者以前也做过PHP,故使用过PHP的YII2,Laravel,ThinkPHP的开发者也能很清晰的看懂封装逻辑
E) 适合还未参加工作的同学,这些代码来自企业的基础功能包,是真实的工作代码
F) 本文件目录为功能代码块,可参考笔者的一篇MongoDB相关的博客使用,包含作者踩过的一些坑,可帮助初学使用者加深理解,内容涉及MongoDB相关(安装,常识,Mysql和MongoDB的基本对比,原生mongo shell命令...)
三、注意项
1. 聚合操作时$sum 操作作用同Mysql的count()和sum(),
db.tb_users.aggregate([{count:$sum:1}]) // select count(*) from tb_users
db.tb_users.aggregate([{count:$sum:"$age"}]) // select sum(age) from tb_users
***注意: mongodb的集合tb_users的字段age必须是数字类型,若是字符串类型,则无法使用sum()的功能
2. MongoDB对字段类型严格,若设置字段age为int,则db.tb_users.find({age:{$ge:"22"}); 无法获取查询结果,正确写法: db.tb_users.find({age:{$ge:22}})
3. 查询集合文档(对应Mysql数据表行记录)和聚合查询(类似Mysql的聚合函数操作)优化方案
1) 片键使用(查询是否命中片键,片键:mongo分片存储的规则,如hash)
2) 索引命中(match+project 都包含于 索引中,则从内存中读取,否则磁盘读取; 聚合操作中只有第一个match会用到索引; 通过project操作过滤掉不必要的字段,减少传输带宽过大造成的内存损耗)
4. MongoDB的集合(数据表)关系和设计原则参考
1->1: 内嵌
1->多:内嵌数组,或多 侧引用(引用另一个集合的_id等唯一键)
多->多: 跟实际情况而定
4. MongoDB的集合(数据表)中,单个文档(行记录)最大不超过16MB
5. 两个操作内存上限:
1) 单个文档存储最大不超过16MB,超过16MB会异常,可通过设置标记字段,标记当前文档为异常文档,详情参见(六-1-构建模式-异常模式)
2)MongoDB的内存操作最大不超过100MB,否则异常,但可通过设置allowDiskUse=true实现大于100MB的操作;缺点是allowDiskUse=true会将数据写入磁盘中,会降低响应速度; 例如:管道聚合操作时,使用allowDiskUse后比使用前,响应更慢
6. MongoDB的事务支持: MongoDB-4.0以前只支持单文档事务,Mongo-4.0开始支持副本集事务(跨文档事务),MongoDB-4.2开始支持副本集(跨文档事务),分片事务(跨分片事务)
7. remove() 方法 并不会真正释放空间。需要继续手动回收磁盘空间: 执行 db.repairDatabase(); 或 db.runCommand({ repairDatabase: 1 });
8. 删除集合文档时,错误写法:db.demo20191223.remove(); 正确写法:必须 db.demo20191223.remove({})
9. 多表关联查询:关键字$lookup,属于MongoDB的管道聚合操作,类似MySQL的聚合函数查询;
A)语法:
db.demoA.aggregate([$lookup:{
from:"tb_users", // 被关联的集合
localField:"a_uid", // demoA中的字段a_uid
foreignFeild:uid", // tb_users中的字段uid
as:"res" // 联表查询结果的别名
}]); // 类似SQL: SELECT * FROM demoA a LEFT JOIN tb_users tu ON tu.uid = a.a_uid;
B) 实例如: db.tb_flows.aggregate([
{$match:{app_id:"1008611",flow_add_date:20200115}},
{$lookup:{from:"tb_users", localField:"fb_uid", foreignField:"fb_uid", as: "res"}}, // 联表操作
{$unwind:"$res"}, // 将查询拆分
{$match:{res.add_date":20200114}}, // 类似SQL的having
{$group:{_id:"$fb_uid",counts:{$sum:1}}} // mongo根据group去重
]);
类似SQL: SELECT count(distinct fb_uid) as counts FROM tb_flows tf LEFT JOIN tb_users tu ON tu.fb_uid = tf.fb_uid WHERE tu.app_id = "1008611" AND tu.add_date = 20200114 AND tf.flow_add_date = 20200115;
分析:这是管道聚合查询
a) 首先,这里使用了2次$match,只有第一个$match会用到索引,其他的操作均在内存中完成计算,无法使用索引,分步匹配,尽可能得过滤掉无关的数据,减少内存操作数据量
b) 其次,MongoDB自身无法去重函数(MySQL中可disinct 关键字去重),但是可以根据group实现去重的效果;
10. 管道聚合操作中,尽量第一个管道使用$match过滤无关的数据,因为只有第一个$match会用到索引,其他的操作均在内存中完成计算,无法使用索引,$match可分步匹配,尽可能得过滤掉无关的数据,减少内存操作数据量;类似SQL的 WHERE和HAVING的使用
11. MongoDB自身无法去重函数(MySQL中可disinct 关键字去重),但是可以根据group实现去重的效果;****注意:Mongo Shell 工具用js封装了 distinct(),使用如: db.demo20191223.distinct("字段名"),返回会该字段去重后的字段值数组;但是处理数据量过大时,会出现异常,且性能比不上聚合操作,故建议使用聚合操作($group,$addToSet就可以实现字段去重数组)
12. mongo shell 命令行模式下,每个会话session,只允许登录一次(即需要切换账号密码时,需要先退出mongo,重新进入mongo命令行界面)
13. MongoDB副本集安装步骤【集群模式:一主一从一仲裁 , 建议采用1主2从(容灾效果更好)】
四、设计模式+索引优化+MongoDB架构迭代
1. MongoDB的构建模式
1. MongoDB的构建模式(10条:多态,属性,异常,分桶,计算,...)和部分举例(自行结合应用场景)
// ***注意: MongoDB的构建模式选择时,需权衡MongoDB的 易用性和性能
1) 多态模式,MongoDB的集合(数据表)各个文档(行记录)中的字段可以不一致(不存在的字段,其值默认为null,MongoDB中很多操作会自动过滤掉null值的文档);
应用场景:适用于业务逻辑改变时,随时增加/删除字段,无需操作字段(MySQL则需手动修改字段),也适用于文档数据的个性化存储,缺点:获取数据时需要注意查询条件的选定
例如:
{shop_name:"全家Famil",good_name:"怡宝",price:2,unit:"ml"},
{shop_name:"711",good_name:"百岁山",price:2,volume:"310",unit:"ml"},
{shop_name:"罗森",good_name:"农夫山泉",unit:"ml"}
...
2) 属性模式: 存储数据时,可以将多组数据存储集合中的同一个字段中(json格式);
应用场景:通过字段属性存储减少关联多个表,缺点:属性过多时,或属性频繁更新时会影响性能,即属性模式适用于存储不常更新的属性
例如:
{
shop_name:"全家Family",
water_detail:[
{name:"怡宝",price:2,volume:"310",unit:"ml"}
{name:"农夫山泉",price:2,volume:"350",unit:"ml"}
{name:"百岁山",price:3,volume:"500",unit:"ml"}
]
},{
shop_name:"好德",
water_detail:[
{name:"怡宝",price:2.5,volume:"310",unit:"ml"}
{name:"农夫山泉",price:2.5,volume:"350",unit:"ml"}
{name:"百岁山",price:3.5,volume:"500",unit:"ml"}
]
},
...
3) 分桶模式:
定义:将每个小时的数据存放在同一条文档中,该条文档中包含多条实时数据,每条数据实时更新/写入到此文档中,一般每条文档的时间跨度为1小时,如: 每条文档记录一小时内的温度测量情况,每分钟更新(插入)添加一条数据
应用场景: 物理网时序数据测量(每分钟测量一组数据,每小时的数据聚合在一条文档中),优点:减少文档条数,提高查询性能和数据聚合性能
实例:{
sensor_id: 12345,
start_date: ISODate("2019-01-31T10:00:00.000Z"),
end_date: ISODate("2019-01-31T10:59:59.000Z"),
measurements: [
{
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
},
{
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
},
…
{
timestamp: ISODate("2019-01-31T10:42:00.000Z"),
temperature: 42
}
],
transaction_count: 42,
sum_temperature: 2413
}
// 分桶: 每个小时的数据写入同一个文档中(存在则修改,否则创建),类似Mysql的根据唯一键更新同一条行记录(行记录以小时作为唯一键)
4) 异常值,超出存储上限时,添加标记字段,表示当前文档(行记录)和正常文档不一致,如异常文档多设置一个字段hashEx,且值为true
应用场景: 书籍在线销售,当书销量过高,记录的user数量过大,超出MongoDB字段值存储空间上限(每条文档的存储上限为16MB),当超出上限时,添加一个hasEx = true,表示该条文档异常,其他正常文档不做标记,查询时,根据hashEx=true的条件就可以获取所有异常的文档
5) 计算:
应用场景: 电影上映后,统计上映情况(各家影院的票房,观看时间,观看人数,并汇总),脚本定时计算上述指标,提高查询加载速度(区别于传统实时计算)
6) 预分配: 如影院/会议室的座位,A1~A100,A~F的5*100的二维数组,但是由于场馆是“凸”字形的,有效座位只有A1~A5,B1~~F100,也就是说 A6~A100座位是无效的,但是存储时仍需存储A6~A100,随之MMVP1存储在MongoDB-4.*后版本废弃后,此模式也被废弃
7)子集模式:将全量数据分成两部分,分别存放在两个集合中,主集合存储常用数据,当需要全量数据时再加载全量;但必须管理子集(更新子集数据)
应用场景: 评论,发帖/回帖
8) 扩展引用模式:将原本需要join联表的操作,在集合中新增一个引用字段,字段值存放被引用的字段(一般为被关联集合的文档标识符,如:唯一键_id)
应用场景:联表查询,如商品订单查询(商品订单表,商品表,商品属性表,....)
聚合关键词:$lookup
9)树形模式:用于记录树形结构,优点:省去多去join操作,但树形数据关联性很强,难维护,即适合读多写少的操作
应用场景:如:公司组织架构
聚合关键词:$graplookup
10) 近似值模式,指定规则,按照规则执行,优点:减少MongoDB负载,缺点:操作结果和实际结果存在一定误差,例如:
当记录uv数时,设置近似值规则:uv每增加10个,写一次集合,(实现:res=uv%10,res=0时,才可以写入集合,否则不写入);
2.企业实际案例+实际解决方案
1. 用户活动效果(活动数据统计:UV+PV+活跃用户数+用户留存率+每日新增用户数等指标)
背景: 为获取某个游戏活动的效果,统计活动数据的用户数据,以分析图表形式展示
机器配置:单台4核16G机器 * 3台,搭建副本集集群+分片的集群,架构如图:图1-当前架构,图2-为优化后的架构;
**注意:
1)最佳架构是3*3=9台机器(集群*3,单个集群(主节点*1,从节点*2,)),至少9台,
2) MongoDB架构--->多个分片--->单个分片(多个集群)--->集群(多个节点)--->一主多从,
3)从节点和仲裁节点区别:从节点会备份主节点的数据,并在集群选取时参与投票,可能被选为新一轮主节点; 仲裁节点只参与选举投票,没有被选资格,不做任何数据操作
4)图片1架构中,最优架构:三份分片,每个分片一个集群,每个集群一主两从,并将每个集群的各个节点分布在不同机器,避免同一个集群在同一台机器上备份导致单机负载过高,同时每台机器只有一个主节点,如图2所示
首次设计方案: 记录用户基本信息(集合tb_users),记录用户的每次流水记录(集合tb_flows),两个集合,客户端接口接入,管理端实时读取数据库数据,
实际问题:实时读取并计算分析数据,导致管理端分析接口响应很慢
解决方向:
1) 调整架构:(一主一从一仲裁,主从节点之间中会进行数据同步,若想集群i/o一次,单机会i/o两次,若换成一主二从,则单机i/o三次,故按照:步骤1-4)描述+图2优化架构进行调整架构)
2) 主从分离:主节点写入,从节点读取,缺点:主从节点数据不同步,存在延时,但读性能高,不适合强一致性的业务
3)实时计算指标 改为 定时计算并物化指标(类似MySQL的物化视图),几种常见的实现方式
A) 使用MongoDB的分桶,计算构建模式,业务层定时任务执行统计计算:(定时任务脚本,每天凌晨计算指标,并写入新集合tb_metric中,管理端读取tb_metric的数据),优点:响应快,查询性能更优,tb_metric的数据量比实时计算的数据量少的多;缺点:占用业务机器的CPU,内存资源,同时业务层和MongoDB集群的连接传输数据占用带宽资源; 注意:尽量返回较少的数据,较少传输占用带宽,如:只返回需要的字段,不返回全量字段;
B) 使用MongoDB的$merge操作,将计算结果通过$merge写入新的集合tb_metric中,管理端从新集合tb_metric中读取;优点:响应快,查询性能更优,tb_metric的数据量比实时计算的数据量少的多;缺点:$merge是MongoDB内置操作,占用MongoDB集群的CPU,内存等资源;注意:当操作涉及数据量过大时(超过100MB),可使用allowDiskUse=true,否则容易异常,但allowDiskUse涉及磁盘I/O,响应速度变慢,尽量减少单词操作的数据量过大,如:复杂的管道聚合操作,分多次$match条件过滤,减少涉及的数据量; 注: MongoDB的$merge等操作,类似MySQL的存储过程,执行效率高于业务层代码,但占用MongoDB自身的CPU和内存资源
4)建立合适的索引(详情参见:索引优化+ESR规则)
解决方案:因紧急程度和上线时间问题,且目前的数据量处理还在可接受范围内,故选择:解决方向中的 3-A)+ 4),架构暂时维持不变,
性能提升:
图1-优化前架构图:
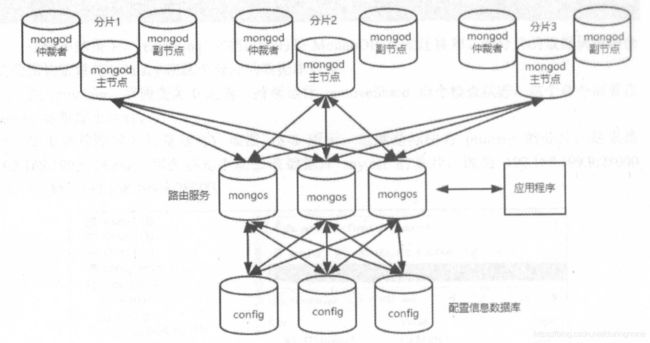
图2-优化后的架构:
3. MongoDB的索引和查询优化 【持续优化中】
1. 索引创建,删除命令
A) db.tb_users.getIndexes(); // 查看集合tb_users的所有索引详情,默认有一个_id主键索引;db.tb_users.getIndexSpecs(); // 功能同getIndexes()
B) db.tb_users.createIndex({"uid":1},{"name":"索引名","unique":bool,"sparse":bool); // 创建单个索引
a) 参数说明:
参数1:字段名:1-数据升序存储,-1-数据降序存储
参数2:
name:索引名,
unique:true-唯一索引、默认false,
sparse:对于不存在的字段不启用索引,即(是否过滤掉 null值/不存在的字段),true-不存在的字段不启用索引((过滤掉 null值/不存在的字段)),false-不存在的字段也启用索引(不过滤掉 null值/不存在的字段),默认false
expireAfterSeconds: 设置集合有效期(系统会自动删除过期索引),单位为秒
weight:设置索引被命中的权重
实例:
db.tb_users.createIndex({"uid":1},{name:"idx_uid","unique":true,sparse:true}); // tb_users表uid字段创建一个名为idx_uid的唯一索引,且升序存储uid数据,对 不存在uid字段的 文档记录不启用索引(即查询时自动过滤掉 不存在uid字段/uid字段值为null的文档记录);
C)db.tb_users.dropIndex("索引名"); //删除指定索引
D)db.tb_users.dropIndexes(); //删除当前集合所有索引(_id主键索引除外)
2. 索引优化和注意事项
1) 索引的ESR规则,eq+sort+range:
3. explain慢查询的使用
db.tb_users.explain("executionStats").find({"age":97}); //explain("executionStats")比explain操作更详细,多了一个executionStats对象信息
A) 例1(无索引):
>db.tb_users.explain("executionStats").find({"age":97});
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "db_isr_dev.tb_users",
"indexFilterSet" : false,
"parsedQuery" : {
"age" : {
"$eq" : 97
}
},
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"age" : {
"$eq" : 97
}
},
"direction" : "forward"
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 1,
"executionTimeMillis" : 0, // query的整体查询时间
"totalKeysExamined" : 0, // 索引扫描条目
"totalDocsExamined" : 12, // 集合(数据表)条目总数
"executionStages" : {
"stage" : "COLLSCAN", // 索引类型
"filter" : {
"age" : {
"$eq" : 97
}
},
"nReturned" : 1, // 查询返回的条目(文档数量)
"executionTimeMillisEstimate" : 0,
"works" : 14,
"advanced" : 1,
"needTime" : 12,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"direction" : "forward",
"docsExamined" : 12
}
},
"serverInfo" : {
"host" : "localhost.localdomain",
"port" : 27017,
"version" : "4.2.2",
"gitVersion" : "a0bbbff6ada159e19298d37946ac8dc4b497eadf"
},
"ok" : 1
}
B) 例2(唯一索引):
>db.tb_users.explain("executionStats").find({"fb_uid":1584164269896});
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "db_isr_dev.tb_users",
"indexFilterSet" : false,
"parsedQuery" : {
"fb_uid" : {
"$eq" : 1584164269896
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN", // 命中索引
"keyPattern" : { // 索引规则:正序存储字段数据
"fb_uid" : 1
},
"indexName" : "idx_fbUid",
"isMultiKey" : false,
"multiKeyPaths" : {
"fb_uid" : [ ]
},
"isUnique" : true,
"isSparse" : true,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward", // 正序查询,相对于
"indexBounds" : {
"fb_uid" : [
"[1584164269896.0, 1584164269896.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 1,
"executionTimeMillis" : 1,
"totalKeysExamined" : 1,
"totalDocsExamined" : 1,
"executionStages" : {
"stage" : "FETCH",
"nReturned" : 1,
"executionTimeMillisEstimate" : 0,
"works" : 2,
"advanced" : 1,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"docsExamined" : 1,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 1,
"executionTimeMillisEstimate" : 0,
"works" : 2,
"advanced" : 1,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"keyPattern" : {
"fb_uid" : 1
},
"indexName" : "idx_fbUid",
"isMultiKey" : false,
"multiKeyPaths" : {
"fb_uid" : [ ]
},
"isUnique" : true,
"isSparse" : true,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"fb_uid" : [
"[1584164269896.0, 1584164269896.0]"
]
},
"keysExamined" : 1,
"seeks" : 1,
"dupsTested" : 0,
"dupsDropped" : 0
}
}
},
"serverInfo" : {
"host" : "localhost.localdomain",
"port" : 27017,
"version" : "4.2.2",
"gitVersion" : "a0bbbff6ada159e19298d37946ac8dc4b497eadf"
},
"ok" : 1
}
2) db.tb_users.explain().find({"age":97});
indexOnly: 字段为 true ,表示我们使用了索引。
cursor:因为这个查询使用了索引,MongoDB 中索引存储在B树结构中,所以这是也使用了 BtreeCursor 类型的游标。如果没有使用索引,游标的类型是 BasicCursor。这个键还会给出你所使用的索引的名称,你通过这个名称可以查看当前数据库下的system.indexes集合(系统自动创建,由于存储索引信息,这个稍微会提到)来得到索引的详细信息。
n:当前查询返回的文档数量。
nscanned/nscannedObjects:表明当前这次查询一共扫描了集合中多少个文档,我们的目的是,让这个数值和返回文档的数量越接近越好。
millis:当前查询所需时间,毫秒数。
indexBounds:当前查询具体使用的索引。
A) 例1(无索引):
> db.tb_users.explain().find({"age":97});
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "db_isr_dev.tb_users",
"indexFilterSet" : false,
"parsedQuery" : {
"age" : {
"$eq" : 97
}
},
"queryHash" : "3838C5F3",
"planCacheKey" : "3838C5F3",
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"age" : {
"$eq" : 97
}
},
"direction" : "forward"
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "localhost.localdomain",
"port" : 27017,
"version" : "4.2.2",
"gitVersion" : "a0bbbff6ada159e19298d37946ac8dc4b497eadf"
},
"ok" : 1
}
B) 例2(唯一索引):
> db.tb_users.find({"fb_uid":1584164269896}).explain();
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "db_isr_dev.tb_users",
"indexFilterSet" : false,
"parsedQuery" : {
"fb_uid" : {
"$eq" : 1584164269896
}
},
"queryHash" : "3A6F3938",
"planCacheKey" : "E867E565",
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"fb_uid" : 1
},
"indexName" : "idx_fbUid",
"isMultiKey" : false,
"multiKeyPaths" : {
"fb_uid" : [ ]
},
"isUnique" : true,
"isSparse" : true,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"fb_uid" : [
"[1584164269896.0, 1584164269896.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "localhost.localdomain",
"port" : 27017,
"version" : "4.2.2",
"gitVersion" : "a0bbbff6ada159e19298d37946ac8dc4b497eadf"
},
"ok" : 1
}
3)
A)explain 希望看到的stage (查询的时候尽可能用上索引):
a) Fetch+IDHACK (索引查询,并通过_id查询)
b) Fetch+ixscan (索引查询,index查询)
c) Limit+(Fetch+ixscan)(limit限制返回条数,并使用索引查询)
d) PROJECTION+ixscan (project限制返回的字段)
e) SHARDING_FITER+ixscan (分片过滤,索引查询)
f) COUNT_SCAN (count不使用Index进行count时的stage返回)
B)explain 不希望看到的stage:
a) COLLSCAN (全表扫描),
b) SORT (使用sort但是无index)
c) 不合理的SKIP
d) SUBPLA(未用到index的$or)
e) COUNTSCAN(不使用index进行count)
C) 更多关于stag的值,见下2-1)stag表格
3.架构优化和思考
1) 每个副本集集群成员不能在同一个机器上,
2) 近似值模式,+ 分桶模式 构建模式,减少频繁操作MongoDB数据库,降低实时请求的压力;详情见构建模式专栏
3)match + project 能最好命中 索引名
a, b,c
idx_a_b_c
4) MongoDB的$merge等操作,类似MySQL的存储过程,执行效率高于业务层代码,但占用MongoDB自身的CPU和内存资源
5) 片键使用(查询命中片键)
6) 索引命中(match+project 都包含于 索引中,则从内存中读取,否则磁盘读取; 聚合操作中只有第一个match会用到索引; 通过project操作过滤掉不必要的字段,减少内存操作损耗)
7) whereTag默认缓存容量wt,物理机内存为n GB时,wt=(n-1)/2,当机器内存为16GB时,wt=(16-1)/2 = 7.5GB
3-1)explian中stag的索引 ( 如:explain.queryPlanner.winningPlan.stage和explain.queryPlanner.winningPlan.inputStage等)
| stag | 描述 | |
|---|---|---|
| COLLSCAN | 全表扫描 | |
| IXSCAN | 扫描索引 | |
| FETCH | 根据索引去检索指定document | |
| SHARD_MERGE | 将各个分片返回数据进行merge | |
| SORT | 表明在内存中进行了排序(与老版本的scanAndOrder:true一致) | |
| LIMIT | 使用limit限制返回数 | |
| SKIP | 使用skip进行跳过 | |
| IDHACK | 针对_id进行查询 | |
| SHARDING_FILTER | 通过mongos对分片数据进行查询 | |
| COUNT | 利用db.coll.explain().count()之类进行count运算 | |
| COUNTSCAN | count不使用Index进行count时的stage返回 | |
| COUNT_SCAN | count使用了Index进行count时的stage返回 | |
| SUBPLA | 未使用到索引的$or查询的stage返回 | |
| TEXT | 使用全文索引进行查询时候的stage返回 | |
| PROJECTION | 限定返回字段时候stage的返回 |