《共轭梯度法》读书笔记(一)——最速下降法
求解问题
二次型 (Quadratic form)是一个形如 f(x)=12xTAx−bTx+c f ( x ) = 1 2 x T A x − b T x + c 的标量二次方程,如果 A A 是一个 n∗n n ∗ n 对称正定阵,那么 f(x) f ( x ) 的最小值在 Ax=b A x = b 时取到。计算如下:
换一种方式,如果 x=A−1b x = A − 1 b ,对任意 e≠0 e ≠ 0 ,都有 f(x+e)>f(x) f ( x + e ) > f ( x ) ,证明如下:
因此,待求解的问题就是解 Ax=b A x = b ,或者等价的,求解二次型方程 f(x) f ( x ) 的最小值。
误差与残差
最速下降法迭代求解 Ax=b A x = b 。定义第 i i 次迭代得到的解为 x(i) x ( i ) ,随着迭代次数 i i 的增加,如果算法收敛,则 x(i) x ( i ) 将趋向于正解 x x 。
定义第 i i 次迭代的误差(error)为迭代解和正解的差,即
定义第 i i 次迭代的残差(residual)为迭代解在方程中的偏差,即
残差和误差之间的关系如下,
梯度下降法
梯度下降法(Gradient Descent)就是让下一次迭代沿着残差的方向进行,因为残差方向就是 f(x) f ( x ) 在 x(i) x ( i ) 处的梯度方向,即
其中 α α 表示迭代的步长。
最速梯度下降法
普通的梯度下降法将 α α 作为可调参数;而最速下降法(Steepest Descent)希望能一直沿着该梯度方向,走到该方向上的最低点,因此在二次型的背景下,它可以求解出 α α 。这里的变量是 α α ,函数是 f(x) f ( x ) ,求解最小值当然是导数等于0,即
代入 x=x(i+1) x = x ( i + 1 ) ,得到
将 r(i) r ( i ) 简写为 r r ,得到
由此我们也能计算出下一次迭代中的残差项 r(i+1) r ( i + 1 ) ,
由于计算 α α 时也需要计算 Ar(i) A r ( i ) ,因此迭代计算残差可以比直接计算要快。
收敛性证明
虽然直观上每一步都沿着梯度下降,而正定的二次型背景又决定了不会存在局部极值点或者鞍点,最速下降法似乎一定会收敛。但考虑严谨性,同时考虑收敛的效率,仍需证明它的收敛性。
由于 A A 对称正定,因此存在 n n 个互相正交的、单位长度的特征向量,记这些特征向量为 vj v j ,它们对应的特征值为 λj λ j (由正定性可知 λj>0 λ j > 0 )。
(以下出于简化考虑,第 i i 次迭代的下标将省略,非第 i i 次迭代的下标保留。)
将误差项 e e 表示为特征向量的线性组合,则
那么由 r=−Ae r = − A e 可得,
作为预备,解出
寻找下一轮迭代误差和当前误差之间的关系:
其中, ω ω 决定了收敛速度,
ω ω 的大小和矩阵 A A 自身性质相关,不加证明地给出
其中 κ κ 为 A A 的条件数 (Condition number),即 κ=λmax/λmin κ = λ m a x / λ m i n ,条件数越大,矩阵性质越差,收敛速度越慢;条件数越小,矩阵性质越好,收敛越快。但无论如何, ω<1 ω < 1 ,因此最速下降法在足够迭代次数下总是能收敛。
缺陷
如上所述,条件数过大时,最速下降法收敛速度很慢。比如,考虑一个很扁的椭圆(其长短轴分别为最大最小特征值,很扁说明条件数很大),如果起始点在长轴末端附近,则很容易走出“之”字形的路线,如下图所示。
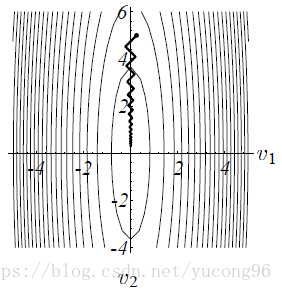
最速下降法收敛慢的例子
下一节的共轭方向法将考虑解决这一问题。
参考文献
- 《An Introduction to the Conjugate Gradient Method Without the Agonizing Pain》
这篇参考文献的摘要和introduction非常有趣,怼人的部分摘录如下:
… Unfortunately, many textbook treatments of the topic are written with neither illustrations nor intuition, and their victims can be found to this day babbling senselessly in the corners of dusty libraries. For this reason, a deep, geometric understanding of the method has been reserved for the elite brilliant few who have painstakingly decoded the mumblings of their forebears …
… When I decided to learn the Conjugate Gradient Method (henceforth, CG), I read four different descriptions, which I shall politely not identify. I understood none of them. Most of them simply wrote down the method, then proved its properties without any intuitive explanation or hint of how anybody might have invented CG in the first place. This article was born of my frustration …