Self-supervised and unsupervised learning for video
目录
ActBERT: Learning Global-Local Video-Text Representations(cvpr2020)
Self-supervised learning using consistency regularization of spatio-temporal data augmentation for action recognition(STCR)
Temporal Cycle-Consistency Learning(Google Brain)
Unsupervised leaning of visual representation using videos
Learning Video Object Segmentation from Unlabeled Videos
Self-Supervised Video Representation Learning with Space-Time Cubic Puzzles
Other methods
ActBERT: Learning Global-Local Video-Text Representations(cvpr2020)
背景:
- 在教做菜的视频中,视频创作者会描述,“开始切胡萝卜”,往往人物也是在正进行“切胡萝卜”的动作。这种天然的视觉对应关系,是进行视频文字自监督学习的重要要素。其中文字描述可以通过自动语音识别技术(ASR)从视频中或从创作者上传的字幕中提取文字。这样成对的视频文字数据就产生了。
- 为了解决视觉特征无法做分类预测的问题,VideoBERT 使用了 hierachical k-means 的方法将视觉特征进行离散化,这样每个数据特征都对应一个离散的视觉中心。
idea:在输入层同时加入全局动作特征与局部区域特征。
论文链接:https://openaccess.thecvf.com/content_CVPR_2020/papers/Zhu_ActBERT_Learning_Global-Local_Video-Text_Representations_CVPR_2020_paper.pdf
参考:https://www.jiqizhixin.com/articles/2020-07-20-8
Self-supervised learning using consistency regularization of spatio-temporal data augmentation for action recognition(STCR)
分为两个Branch, 一路Clean表示普通的Video,另一路表示引入Noise之后的, 2路不同的输入经过3D Backbone之后,我们希望feature 在 temporal-level和feature-level保持consistency。

Temporal Cycle-Consistency Learning(Google Brain)
TCC的关键在于通过循环一致性的原则,从多个视频中寻找出对应的相同动作。
研究人员首先将两个待配准的视频传入编码器中获取对应的嵌入信息,而后选择两个视频来进行TCC的训练,其中video1作为参考视频,从中取出一帧并利用最邻近方法在嵌入空间中找到video2中最为近似的一帧;而后以video2中找到的这一帧作为输入,从新到嵌入空间中寻找video中对应的帧(circle过程)。如果学习出的嵌入空间具有循环一致性的话,这一帧和先前输入video1的参考帧应该是同一帧。
参考:https://zhuanlan.zhihu.com/p/77771815
Unsupervised leaning of visual representation using videos
idea:用一个图片(patch)三元组(a, b, c)来训练网络,其中a和b是同一个视频中内容相近的patch, c是从其他视频中任意采样得到的patch,让网络能学习到a, b, c的特征并满足a,b之间的距离尽量小,a,c之间的距离尽量大。
参考:blog
Learning Video Object Segmentation from Unlabeled Videos(cvpr2020)
Author: Xiankai Lu...Steven C. H. Hoi
Key: 提出了一种无监督方法,从四个方面进行特征学习。类似于几个proxy task的组合。包括:frame, short-term, long-term and whole video granularities

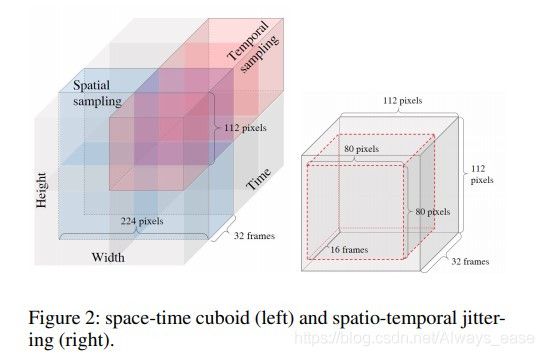
Self-Supervised Video Representation Learning with Space-Time Cubic Puzzles
论文:https://arxiv.org/pdf/1811.09795.pdf
Other methods
- Video Generation with GAN
与图像类生成方法类似。这种方法通常由两部分组成:generator(生成器:生成视频)+ discriminator(鉴别器:区分生成的与真实的视频)。Discriminator可以被迁移物其他的下游任务。
- Video Colorization
给一个灰色的图像,一些参考的彩色图像,让模型学习上色。
-
Video Future Prediction
给定一些序列,让模型学习预测后续的序列。如:Self-Supervised Video Representation Learning With Odd-One-Out Networks
参考:https://bbs.huaweicloud.com/blogs/181241