自己用C++实现BaseLine Jpeg解码(要点总结)
忙活这几天,终于自己用C++完整实现了BaseLine的Jpeg解码算法,中间阅读了一些论文和网上的帖子,发现其中有很多没有说清楚的地方,自己在实现的过程中也受到网上资料的很多误导,现在自己完整地把Jpeg解码算法实现了一遍,把有疑惑的地方都解决了,遂将自己对于Jpeg解码算法的理解要点记录在这篇帖子中,本人初学图形图像的相关内容,本帖内容有谬误的地方敬请各位大贤不吝指教。
解码步骤和要点:
1.获取图像信息
首先在程序中以二进制方式读入Jpeg图像文件,根据Jpeg文件的标准格式来分析文件中的各个字段,得出图像的一些重要信息,例如图像的宽度和高度,图像的色彩分量个数,每个分量的采样因子,每个色彩分量使用的huffman表和反量化表的编号,量化表精度等等,这些参数决定了后期怎么对图像进行解码,同时还要在分析文件字段的同时将huffman表字段和量化表字段的数据记录下来,并且根据还原huffman表的方法将huffman表恢复出来,将反量化表也记录下来,为后期解码做准备,至于Jpeg文件中各个字段的定义以及还原huffman表的方法,网上有很多帖子都有讲解(这个帖子讲得不错:http://www.cnblogs.com/leaven/archive/2010/04/06/1705846.html),这里就不赘述重复内容了。
这里简单说一下各个参数的作用,图像的宽度和高度就不用说了,它描述了解压后图像矩阵的宽度和高度,色彩分量个数描述了图像是黑白的还是彩色的,这个参数可以是1,3,或4,1表示只有一个亮度的分量,当然图像就是黑白灰度图像,3表示图像使用的是YCbCr的色彩空间,当然就是彩色图像,4表示另外的CMYK的图像格式,这个没有深入研究过是什么东东,先放一边,一般的Jpeg图像都是使用YCbCr色彩空间的彩色图像,下文就以这样的最具代表性的图像为例进行论述。颜色分量的采样因子决定了亮度信号和两个色差信号的采样频率,一般情况下普通的Jpegz真彩图像使用的是4:1:1的采样因子,意思就是一个图像中的MCU由4个8*8的数据块构成,每4个数据块合成一个mcu, 就像下面的图表示的一样假设图像是37pix * 45pix的(懒得再网上找示意图了,自己手画一个):
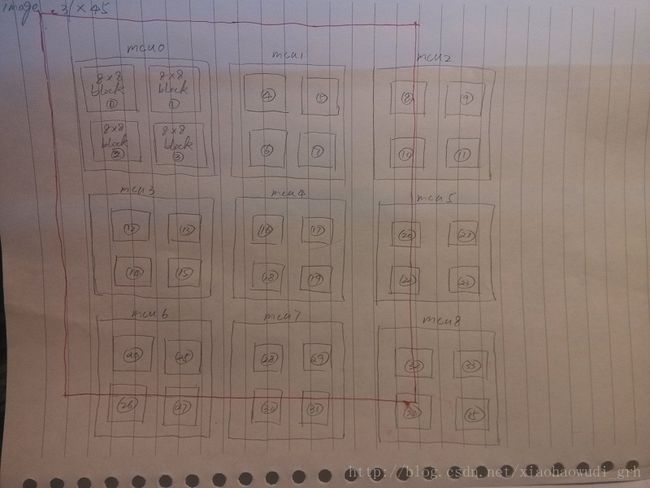
图里面的红色框起来的部分就是真实的图像涵盖的数据范围,红色方框以外的数据是重复最后一行或者是最后一列数据的出来的,实际上是冗余的数据,但是Jpeg图像的压缩数据是以mcu为最小单位的,所以冗余信息也保存在了图像的压缩数据里面,上面的图是4:1:1的图像格式的,还有其他不同的采样比例的就不多说了,情况是类似的,只不过每个mcu里面包含的数据块的个数不同而已,下面针对4:1:1的这种经常出现的格式进行说明:
可以看到这种图像的格式中,每个mcu都包含4个8*8的数据块,每个数据块是Jpeg压缩的最小数据单元,对应了相应位置某一个颜色分量的一个解压后的8*8的位图数据块,对于4:1:1的格式而言,简单的说,就是图里面的0,1,2,3这4个数据块的亮度分量Y的数值单独进行采样,数据相互独立,而Cr和Cb两个颜色分量的采样数据共享,也就是说这四个数据块的Cr和Cb两个分量共用一个8*8的数值采样矩阵,这四个数据块组成了16*16的一个mcu,就把8*8的色度采样矩阵的一个数值拓展到四个像素点上就行了,也就是说每4个像素点(左上,右上,左下,右下组成一个正方形的四个像素)的色度数值是一样的,这样一个8*8的色度值采样矩阵刚好把一个mcu的色度矩阵填满。
2.恢复huffman表
经过第一步的准备之后,下一步将huffman表恢复出来,恢复的方法参照前面提到的帖子,对于彩色图像而言,一般是有4个huffman表(亮度的直流分量huffman表,亮度的交流分量huffman表,色度的直流分量huffman表,色度的交流分量huffman表),这四个huffman表的类型(直流还是交流)以及编号(0号或者1号)是上一步骤可以得到的,恢复出来的huffman表是一个01字符串和权重值的键值对集合,用c++ STL类库里面的map
3.恢复反量化表
根据反量化表的精度(一般是8位或者16位精度),在文件的字节流的对应位置读取64个字节或者是64个双字节数据,从左到右,从上到下存入8*8的矩阵中,一般有两个反量化表(一个亮度的反量化表,一个色度的反量化表,Cb和Cr两个色差信号使用一个色度反量化表)。
4.转换压缩数据
正确定位到文件的字节流中真实的压缩图像数据的位置之后,将这部分真实的图像压缩数据保存到缓存里面,然后将其一个字节一个字节地换成二进制的形式例如0换成“00000000”,3换成“00000011”等等,然后组成一个新的字符流,这个字符流里面只有0和1两种字符。
5.huffman译码:
利用已经重构的huffman表和上一步构造的01字符流进行huffman译码的工作,其实过程很简单,就是在当前的字符流位置开始寻找出现在huffman码表中的字符串,然后把该字符串对应的权值数值读取出来,具体的进行译码的方法参照前面提到的帖子就行了,下面对压缩图像的码流进行一些说明,码流是以mcu为一个单位的,其顺序是[Y0,Y1,Y2,Y3,Cb1234,Cr1234], [Y4,Y5,Y6,Y7,Cb4567,Cr4567]..........这样的,所以读的时候是四个亮度信号Y,两个色度信号Cb,Cr,然后循环往复,每个信号译码完成之后都是64个数据,这64个数据要从上到下,从左到右放到图像的对应的色彩分量的缓存矩阵的对应位置上去,在进行译码的时候,注意亮度信号和色度信号要使用不同的huffman表,注意在这个过程中就要同时进行反差分变换了,我一开始做的时候反差分变换是在解码完所有的mcu后再进行的,事实证明这样是错的,反差分变换应该在huffman译码的同时就进行,也就是说差分反变换的顺序其实因该是下面图里面的箭头对应的顺序,而我一开始认为的顺序是0,1,4,5,8,9,2,3,6,7,10,11.....这样的,这也是受到网上的一些资料的误导,这个问题要格外小心,我也是调试了很长时间才找到问题所在。下面图画的是亮度信号的反差分编码顺序,色度信号中,每一个mcu里面只有一个8*8的色度采样矩阵,就直接按照mcu0,mcu1,mcu2,mcu3.....的顺序进行反差分变换就行了。

还有一点要说明一下,每一次huffman译码的出来的权值并不是真实的采样数据,还要再进行一次译码,huffman译码完成后还要在01字符流中往后读特定的位数,然后根据这些位组成的01字符串再译码一次,这次使用的译码表就不是huffman码表了,这个码表在上面提到的帖子里面有,读者请自行参照,其实没有必要使用译码表,这个编码是很容易看出规律的,开头是1的字符串就代表正数,这个编码也就是这个正数的二进制编码,负数的编码就是其相反数编码的反码,这样译码就简单了,完全没有必要参照译码表。还有要注意的一点,一个mcu里面只有1个Cb和1个Cr色度采样的8*8矩阵,而不是4个。
6.反量化
前面的步骤里面重构了反量化表(一个亮度反量化表和一个色度反量化表),反量化过程非常简单,把每一个亮度8*8矩阵的数值乘以亮度反量化表的对应位置的数值,把每一个色度8*8矩阵的数值乘以色度反量化表的对应位置的数值。再提醒一次,一个mcu里面色度的8*8矩阵只有两个(Cb的和Cr的),所以一个mcu中的反量化操作次数是6次。
7.反z形扫描和反余弦变换
下面一步对每一个8*8的数据块(亮度和色度都包括在内)进行反z形扫描,其实就是重新确定矩阵里面元素的位置,方法很简单,十几行代码就搞定了,就不赘述了,上文提到的帖子里面也有相关的内容,读者请自行参照,然后在对每一个8*8矩阵进行反余弦变换,这个就是套公式了,反余弦变换的公式我就懒得敲的网上到处都是,这两步变换都是把一个8*8的矩阵通过运算转换成一个新的8*8矩阵,值得注意的是这时候一个mcu里面只变换出两个色度的8*8矩阵,这时候,要把这两个矩阵的数据拓展到整个mcu对应的颜色分量中,也就是把反z形扫描和反余弦变换这两步变换之后的8*8矩阵的数据拓展成一个16*16的矩阵,然后把这个16*16的矩阵存回图像的色度信号对应的缓存的对应位置中去。
8.YCbCr转RGB
经过上面稀里哗啦的步骤之后,其实整个图像已经解码完成了,现在的数据是3个矩阵,分别对应亮度信号Y,和两个色度信号Cb,Cr,Jpeg为了压缩人眼对于色度变化不敏感的视觉冗余数据,所以采用的是YCbCr的色彩空间,但是要在软件界面上显示图像,还要进行色彩空间的转换,把YCbCr的三个分量矩阵转换为RGB色彩空间的三个矩阵,转换的方法又是套公式了,公式懒得敲了,直接粘出来对应的代码吧:
//色彩空间的转换
void YCbCr2RGB()
{
int i, j;
for(i=0; i 255)
rgb_image.R[i][j] = 255;
if(rgb_image.G[i][j] < 0)
rgb_image.G[i][j] = 0;
if(rgb_image.G[i][j] > 255)
rgb_image.G[i][j] = 255;
if(rgb_image.B[i][j] < 0)
rgb_image.B[i][j] = 0;
if(rgb_image.B[i][j] > 255)
rgb_image.B[i][j] = 255;
}
}
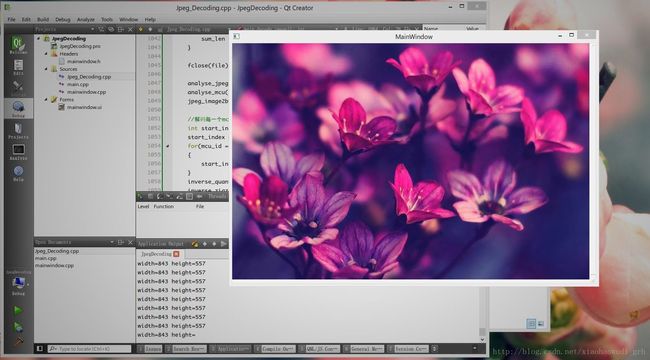
} 注意越界的数据要回归到区间[0,255]里面,最后形成的rgb矩阵就是完全解压后的位图矩阵了,在软件界面中一个点一个点地涂色,整个图像就显示出来了,下面是我用Qt做的一个简单的显示界面,显示的图像没有问题,截两张张桌面的图片来显示,整个解码过程应该是没有什么问题了(还有一点忘了说了,有些资料里面还有相反数校正的步骤,我通过学习Jpeg压缩算法,从来没有发现有这个步骤,我在实现Jpeg解压算法的时候也没有这个步骤,具体原因还待进一步学习,这又是一大误导,害我调试半天,汗。。。。):

简单总结一下,经过自己实现一遍基本的Jpeg解码算法,我对于图形图像的一些基本知识有了比较深刻的了解,通过自己实践,发现网上的一些技术贴和一些论文都有一些细枝末节的错误,看来还是实践出真知,虽然算法的调试比较痛苦,但是能学习到一些东西还是值得的。