二分图匹配——匈牙利算法
匈牙利算法是由匈牙利数学家Edmonds于1965年提出,因而得名。匈牙利算法是基于Hall定理中充分性证明的思想,它是部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。
基本原则就是在原有匹配(最开始的按优先顺序匹配)基础上重新分配,看是否可以添加一个新的匹配。
预备知识
我们需要了解一下图论的一些知识。
1 无向图
边没有方向的图称为无向图。
定义
无向图G=
1.V是非空集合,称为顶点集。
2.E是V中元素构成的无序二元组的集合,称为边集。
解释
直观来说,若一个图中每条边都是无方向的,则称为无向图。
(1)无向边的表示
无向图中的边均是顶点的无序对,无序对通常用圆括号表示。
【例】无序对(vi,vj)和(vj,vi)表示同一条边。
(2)无向图的表示
【例】下面(b)图中的G2和(c)图中的G3均是无向图,它们的顶点集和边集分别为:
V(G2)={v1,v2,v3,v4}
E(G2)={(vl,v2),(v1,v3),(v1,v4),(v2,v3),(v2,v4),(v3,v4)}
V(G3)={v1,v2,v3,v4,v5,v6,v7}
E(G3)={(v1,v2),(vl,v3),(v2,v4),(v2,v5),(v3,v6),(v3,v7)}
(3)若G是无向图,则0≤e≤n(n-1)/2
恰有n(n-1)/2条边的无向图称无向完全图(Undirected Complete Graph)
注意:完全图具有最多的边数。任意一对顶点间均有边相连。
图1
与之对应的则被称为“有向图”。两者唯一的区别在于,有向图中的边是有方向性的。下图即是一个有向图,边的方向分别是:(1->2), (1-> 3), (3-> 1), (1->5), (2->3), (3->4), (3->5), (4->5), (1->6), (4->6)。要注意,图中的边(1->3)和(3->1)是不同的。有向图和无向图的许多原理和算法是相通的。
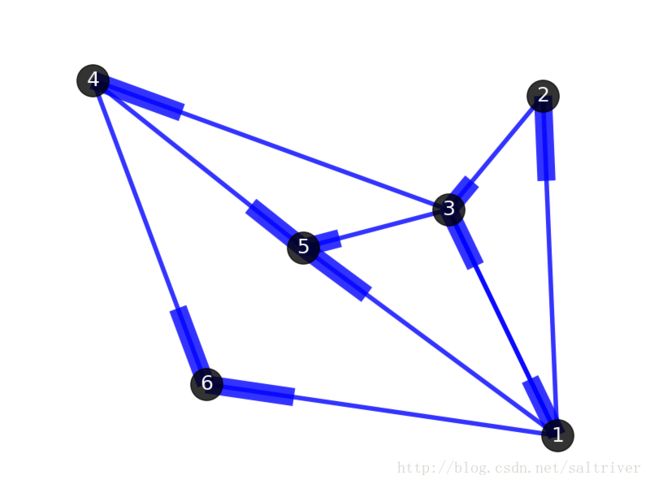
图2
2 二分图
二分图又称作二部图,是图论中的一种特殊模型。 设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。
图3
简而言之,就是顶点集V可分割为两个互不相交的子集,并且图中每条边依附的两个顶点都分属于这两个互不相交的子集,两个子集内的顶点不相邻。
二分图的性质及判定
无向图G为二分图的充分必要条件是,G至少有两个顶点,且其所有回路的长度均为偶数。如果无回路(如图3就没有回路),相当于任一回路的次数为0,0也是偶数,故也视为二分图。

图4
见图4所示,其存在回路。如:1-4-2-5-1,长度为4,偶数。任意一种都为偶数(循环的周期回路也是偶数)。如果在1和2之前添一条边,那就不是二分图了,如下图。

图5
添了1--2的边后,回路就存在了1--4--2--1,长度为3,奇数,所以图3就不是二分图。这也违背了二分图的定义 ,定义中指出图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),但是很明显图5中1-2的边的两个顶点来自同一个点集。
3 二分图匹配
给定一个二分图G,在G的一个子图M中,M的边集{E}中的任意两条边都不依附于同一个顶点,则称M是一个匹配。
图中加粗的边是数量为2的匹配。
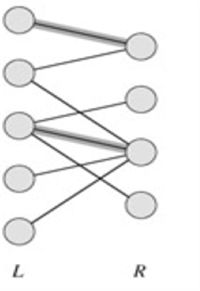
图6
最大匹配
选择边数最大的子图称为图的最大匹配问题(maximal matching problem)
如果一个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备匹配。
图7所示为一个最大匹配,但不是完全匹配。图8是个完全匹配。
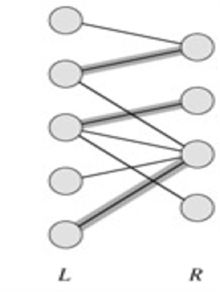
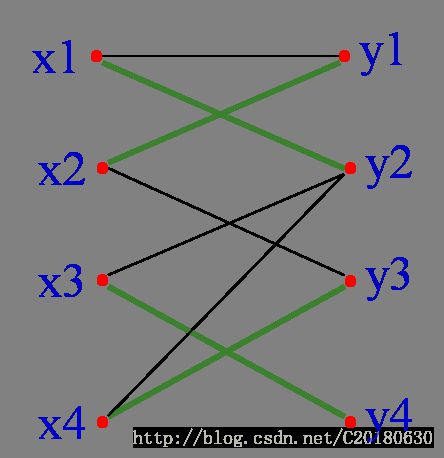
图7 图8
增广路径
也称增广轨或交错轨。设M为二分图G已匹配边的集合,若P是图G中一条联通两个未匹配顶点的路径,且属于M的边和不属于M的边在P上交替出现,则称P为相对于M的一条增广路径。P的起点在X部,终点在Y部,反之亦可,路径P的起点终点都是未匹配的点。
增广路径是一条“交错轨”。也就是说, 它的第一条边是目前还没有参与匹配的,第二条边参与了匹配,第三条边没有..最后一条边没有参与匹配,并且起点和终点还没有被选择过,这样交错进行,显然P有奇数条边,因为不属于匹配的边比匹配的边要多一条!。
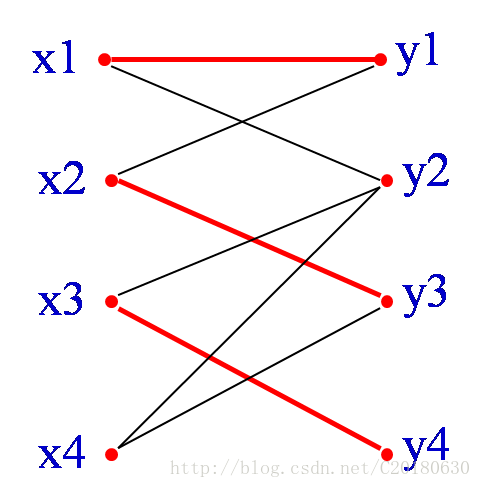
图9
如图9,红边为三条已经匹配的边。从X部一个未匹配的顶点x4开始,找一条路径P:
x4y3-y3x2-x2y1-y1x1-x1y2
因为y2是Y部中未匹配的顶点,x4是X部中未匹配的顶点,且匹配的边和未匹配的边交替出现,故所找路径是增广路径P。
其中有属于匹配M的边为{x2,y3},{x1,y1} ,不属于匹配的边为{x4,y3},{x2, y1}, {x1,y2}
可以看出:P有奇数条边,不属于匹配的边要多一条!
图10
如果从M中抽走{x2,y3},{x1,y1},并加入{x4,y3},{x2, y1}, {x1,y2},也就是将增广路所有的边进行”反色”,则可以得到四条边的匹配M’={{x3,y4}, {x4,y3},{x2, y1}, {x1,y2}} 。如图10所示,可知四条边的匹配是最大匹配,也是完全匹配。
容易发现这样修改以后,匹配仍然是合法的,但是匹配数增加了一对。
另外,单独的一条连接两个未匹配点的边显然也是交错轨。可以证明,当不能再找到增广轨时,就得到了一个最大匹配.这也就是匈牙利算法的思路.
下面介绍单独的一条连接两个未匹配点的边显然也是交错轨的情况。如在图11中,刚开始的时候,没有一个匹配的,此时进行匹配1-1,1和1相连就是一条增广路径(交错轨)。

图11
增广路径性质
由增广路的定义可以推出下述三个结论:
- P的路径长度必定为奇数,第一条边和最后一条边都不属于M,因为两个端点分属两个集合,且未匹配(单独的一条连接两个未匹配点的边显然也增广路径)。
- P经过取反操作可以得到一个更大的匹配M’。
- M为G的最大匹配当且仅当不存在相对于M的增广路径。
下面请出主角上场
匈牙利算法
用增广路求最大匹配(称作匈牙利算法,匈牙利数学家Edmonds于1965年提出)
算法轮廓:
- 置M为空
- 找出一条增广路径P(先找出单个边的增广路径),碰到多个边的增广路径通过取反操作获得更大的匹配M’代替M
- 重复2操作直到找不出增广路径为止
找增广路径的算法
我们采用DFS(深度优先搜索)的办法找一条增广路径:
从X部一个未匹配的顶点Xi开始,找一个未访问的邻接点Yi(Yi一定是Y部顶点)。对于Yi,分两种情况:
如果Yi未匹配,这俩相连,则就算已经找到一条增广路(是单个边的增广路径)
如果Yi已经匹配,则取出yi的匹配顶点Xm(Xm一定是X部顶点),边(Xm,Yi)目前是匹配的,根据“取反”的想法,要将(Xm,Yi)改为未匹配,(Xi,Yi)设为匹配,能实现这一点的条件是看从Xm为起点能否新找到一条增广路径P’。如果行,则Xi-Yi-P’就是一条以Xi为起点的增广路径。
然后取反,则(Xi,Yi)就匹配上了,总的匹配的边要多一条了。
X Y

图12
请先看图11,图11中红线表示的是未匹配的边(这就是置M为空),再看如图12所示,蓝线表示的是已匹配的边,这两个匹配的都是单个边的增广路径(在Y部分从上往下找)。因此X1,X2,都找到了单边的增广路径。接着该X3了,X3先从Y1下手,Y1已经和X1匹配了,这时看X1(这时把X1看为未匹配的点,因为增广路径的定义是,从起点为未匹配的点到终点为未匹配的点)能不能找到一条增广路径,显然从X1出发可以找到一条增广路径:X1Y2-Y2X2-X2Y3。这时就形成了新的增广路径:X3Y1-Y1X1-X1Y2-Y2X2-X2Y3。此时根据取反操作,则X3Y1、X1Y2、X2Y3,成为匹配边(3条)。比之前的两条匹配边多了一条。
匹配结果如图13所示,黄色是之前的匹配,蓝色是新的匹配。
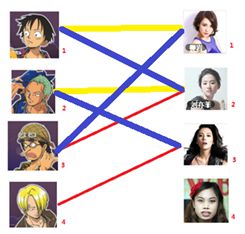
图13
接下来是X4,X4因为找不增广路径(增广路径从未匹配起点出发,到未匹配点的终点),所以无法进行匹配。故最大匹配结果为:
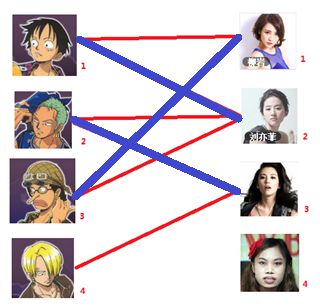
图14
代码实现
下面的代码求的是最大匹配数量。
/**
*Copyright (c) 2019 Young Fan.All Right Reserved.
*Author: Young Fan
*Date: 2019.05.31
*IDE: Visual Studio 2017
*Description:
*/
#define _CRT_SECURE_NO_WARNINGS
#include
#include
using namespace std;
const int N = 505; //设置数组的大小
bool line[N][N]; //记录连接x和y的边,如果i和j之间有边则为1,否则为0
int result[N]; //记录当前与y节点相连的x的节点:i未加入匹配时为link[i]==0
bool used[N]; //记录y中节点是否使用
int k, m, n;
bool found(int x)
{
for (int i = 1; i <= n; i++)
{
if (line[x][i] && !used[i])
{
used[i] = true;
if (result[i] == 0 || found(result[i]))
{
result[i] = x;
return true;
}
}
}
return false;
}
int main()
{
int x, y;
printf("请输入相连边的数量k:\n");
while (scanf("%d", &k) && k) //当输入的k值大于0才可以往下执行。且可以循环输入k;输入时,用空格作为分隔符
{
printf("请输入二分图中x和y中点的数目:\n");
scanf("%d %d", &m, &n);
memset(line, 0, sizeof(line));
memset(result, 0, sizeof(result));
for (int i = 0; i < k; i++)
{
printf("请输入相连边的两个点:\n");
scanf("%d %d", &x, &y);
line[x][y] = 1;
}
int sum = 0;
for (int i = 1; i <= m; i++)
{
memset(used, 0, sizeof(used)); //置空操作
if (found(i)) sum++;
}
printf("%d\n", sum);
}
return 0;
} 匈牙利算法中的增广路径取反操作在代码实现的时候使用的是递归,递归一直往下找。在递归过程中,进行取反操作。
第29行代码:result[i] = x; 实际上就是取反操作。
我们以图11为例,进行代码测试。测试结果如下:

参考博客:
趣写算法系列之--匈牙利算法:
https://blog.csdn.net/dark_scope/article/details/8880547
二分图匹配——匈牙利算法和KM算法:
https://blog.csdn.net/c20180630/article/details/70175814
匈牙利算法——最大匹配问题详解:
https://blog.csdn.net/dengheCSDN/article/details/77619308
算法讲解:二分图匹配:
https://blog.csdn.net/thunderMrbird/article/details/52231639
匈牙利算法与增广路径:
https://blog.csdn.net/reid_zhang1993/article/details/44080167
二分图的定义和判定:
https://blog.csdn.net/li13168690086/article/details/81506044
图论(一)图:顶点,边,同构,有向/无向图,权重,路径(最短路径),环,连通图/连通分量:
https://blog.csdn.net/qq_30796379/article/details/80152270
应用:
[AI开发]基于深度学习的视频多目标跟踪实现:
https://www.cnblogs.com/xiaozhi_5638/p/9376784.html
匈牙利算法-指派问题
人数与工作数不等的指派问题
工作<人数,增加虚拟工作;人数<工作,增加虚拟工人。参考:https://blog.csdn.net/Wonz5130/article/details/80678410
指派问题(匈牙利算法):https://www.cnblogs.com/ylHe/p/9287384.html
基于匈牙利算法的任务分配问题的python实现:https://blog.csdn.net/jingshushu1995/article/details/80411325
Hungarian algorithm:http://www.hungarianalgorithm.com/examplehungarianalgorithm.php