AMNet学习笔记
AMNet
图像检索是近些年来的热门,这次介绍记忆增强属性操作神经网络(AMNet),这种神经网络能够修改图像中的一些区域的属性,允许用户给出图片的同时加入一些关键词描述图片中没有的属性,从而能够更好的是检索出的图片符合用户的心理预期。
1. AMNet使用背景
网络时代,随着各种社交网络的兴起,网络中图片,视频数据每天都以惊人的速度增长,逐渐形成强大的图像检索数据库。针对这些具有丰富信息的海量图片,如何有效地从巨大的图像数据库中检索出用户需要的图片,成为信息检索领域研究者感兴趣的一个研究方向。
在一些使用场景中,用户也想要更换图像中的一些属性,使得图像更符合他们的心理预期。前人提出了多种方法,包括提供附加的相关属性描述,以及用预定义操作编辑图像,但是都存在着种种问题。
2. AMNet建模思路
1. 关键词描述
所谓的关键词描述,就是用户给出图片的同时,加上一些自己的想法。(如图)
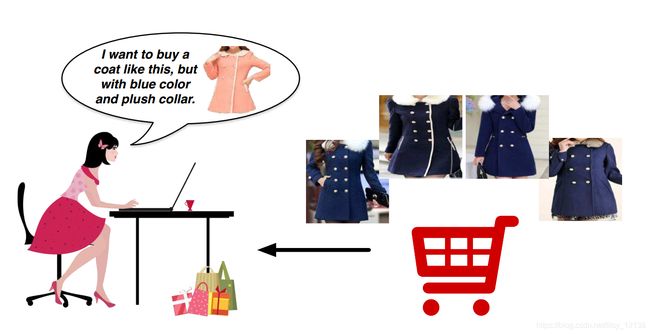
作者希望用户通过文字来给出关键词描述,先通过LSTM的方法,识别出用户描述中涉及的属性种类和属性数量。之后作者定义了一种内存块来描述用户给图片添加的关键词描述。
首先定义一个 C × Q C \times Q C×Q的矩阵M,用来描述所有的属性的values。其中 C = ∑ m = 1 M C m C=\sum_{m=1}^{M}C_{m} C=∑m=1MCm,这里的M是所有的属性数量, C m C_{m} Cm是第m种属性中拥有的values的数量,(如colors可以拥有蓝色,红色等等很多属性)。Q是每个属性表示的维度,(如一种颜色用多个数字来表示)。通过这种方式,M的每一行都表示了一种属性。
再定义一个C维one-hot向量 h h h,用来描述用户想要修改的属性。例如M的第i行表示红色,并且 h ( i ) = 1 h(i)=1 h(i)=1,则表示用户想把颜色换成红色。为了更好的表示,将h归一化,归一化的结果记作 h ′ h^{'} h′。
所以,用户想要修改的属性值就可以表示为一个 Q Q Q维向量 t t t
t = ∑ i = 1 C h ( i ) ′ ⊗ M ( i , : ) t=\sum_{i=1}^{C}h(i)^{'}\otimes M(i,:) t=i=1∑Ch(i)′⊗M(i,:)
2. 属性操作器
定义 r r r是最初的图像表示, r ′ r^{'} r′是对原有属性进行操作,即添加了用户属性要求后的Q维向量。 r ′ r^{'} r′是由 r r r和 t t t直接相连,再通过权重矩阵变化得到 :
r ′ = W ⋅ ( r , t ) + b r^{'}=W\cdot (r,t)+ b r′=W⋅(r,t)+b
我们训练好这个属性操作器后,就可以利用这个操作器,修改query图像中的属性。
3. 最终目标
将图库中的图片用 p p p来表示.我们最终的目标就是利用欧式距离,在图库中找到与我们的query 图片最接近的几张图片。公式如下:
m i n { ( r ′ − p ) 2 } min\{(r^{'}-p)^{2}\} min{ (r′−p)2}
3. AMNet 优化思路
1. 内存块优化
利用CNN,对M进行迭代,迭代公式如下:
▽ M = ∂ t ∂ M ▽ t = h ′ ⋅ ▽ t T \bigtriangledown M=\frac{\partial t}{\partial M}\bigtriangledown t=h^{'}\cdot \bigtriangledown t^{T} ▽M=∂M∂t▽t=h′⋅▽tT
因为t是由用户想修改的属性累和构成,所以在迭代的过程中只会对这些属性产生影响。这样能够更好的表示想要修改的属性。
初始化内存块时,训练一个图片集,将图片集中的数据取平均值放入M对应位置中。
2. 损失层
损失层是CNN中最重要的一环,在本文中,损失层很大程度上决定了t,r等向量的走向。本文用到了两种损失函数:用来预测属性类别的分类损失函数,用来检索图像的排序损失函数。首先来看分类损失函数:
L a = ∑ i = 1 N ∑ m = 1 M − l o g ( p ( a i m ∣ r e f i ) ) L_{a}=\sum_{i=1}^{N}\sum_{m=1}^{M}-log(p(a_{im}|ref_{i})) La=i=1∑Nm=1∑M−log(p(aim∣refi))
这里N是训练样本数量, a i m a_{im} aim 是第 i i i个图像的第 m m m个属性,很明显, p ( a i m ∣ r e f i ) p(a_{im}|ref_{i}) p(aim∣refi)就是反映的第 i i i个图像被分类到第 m m m个属性的概率
排序损失函数是一种三元组排序:
L t = ∑ t = 1 N m a x { 0 , d ( r i ′ , p i ) − d ( r i ′ , n i ) + m } L_{t}=\sum_{t=1}^{N}max\{0,d(r_{i}^{'},p_{i})-d(r_{i}^{'},n_{i})+m \} Lt=t=1∑Nmax{ 0,d(ri′,pi)−d(ri′,ni)+m}
r i ′ , p i , n i r_{i}^{'},p_{i},n_{i} ri′,pi,ni是ref,pos,neg图像的向量表示,这些向量是随机组合的。d就代表了不同图像的距离。我们期望 r e f ref ref与 n e g neg neg图像之间的距离大于 r e f + p o s + m ref+pos+m ref+pos+m之间的距离。如果满足条件,就说明这一项已经满足要求,所以排序损失为0,否则就有损失。
最终,定义总的损失函数为:
L = λ L a + ( 1 − λ ) L t L=\lambda L_{a}+(1-\lambda)L_{t} L=λLa+(1−λ)Lt
4. AMNet流程
最后总结一下AMNet的流程。
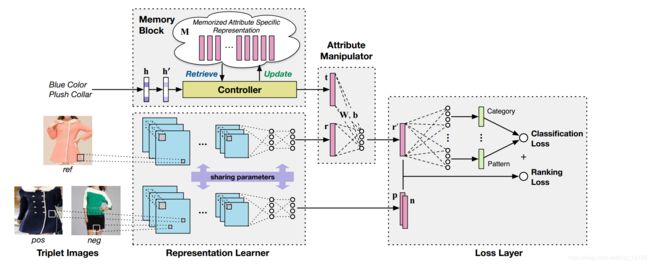
-
通过一个孪生CNN网络,训练 r e f , p o s , n e g ref,pos,neg ref,pos,neg图像。孪生网络具体理解参考这篇博客
-
通过LSTM将用户描述输入memory block,block中的controller负责找出图像中用户描述部分,输出 t t t。
-
属性操作器中将ref图像的向量 r r r和用户描述部分 t t t融合,形成最终的满足用户需求的图像向量 r ′ r{'} r′。
-
利用几个全连接层,使用 r ′ r{'} r′计算分类loss,并反向传播更新 r r r, t t t向量以及 M M M矩阵。
-
利用CNN,使用 r , p , n r,p,n r,p,n等向量,使用小规模动量法梯度下降的方式,计算rank loss。
-
最终我们得到训练好的权重矩阵。
-
输入一个query 图片时,利用已经训练好的权重矩阵,计算出 r ′ r{'} r′,与 p p p通过欧氏距离进行计算,找到最接近的x张图片。
备注:超参数 m m m设为0.5,超参数 λ \lambda λ设为0.2
5. 总结
疑问
-
虽然作者在之后的实验中,说明了使用memory block的方式要好于直接使用one-hot向量和原始图片直接组合的方法。但是我觉得图像属性毕竟是一种二维的方式,单纯的用一个向量表示图像中的属性,我觉得可解释行不强。
-
使用rank loss进行迭代的时候,我明白这是想更新 r ′ r^{'} r′.但是pos,neg向量应该也会被更新吧,更新之后是什么意思?
-
有些地方解释性真的不好。比如训练集中的pos其实是随机选的,这个我理解,但是这样训练效果真的好吗,画一个问号。
感受
我觉得我现在应该已经比较理解这篇论文了,在开始的时候有很多点不太理解,在掌握好整体框架,理清细节后,一个个问题逐渐破解。因为对于图像和属性的处理不够精细,所以AMNet比不上FSNet和EI Tree的效果。
文了,在开始的时候有很多点不太理解,在掌握好整体框架,理清细节后,一个个问题逐渐破解。因为对于图像和属性的处理不够精细,所以AMNet比不上FSNet和EI Tree的效果。