在上篇学习笔记中http://www.cnblogs.com/huligong1234/p/3464371.html 主要记录Nutch安装及简单运行的过程。
笔记中 通过配置抓取地址http://blog.tianya.cn 并执行抓取命令 nohup ./bin/nutch crawl urls -dir data -threads 100 -depth 3 &
进行了抓取。本次笔记主要对抓取的过程进行说明。
首先这里简要列下抓取命令常用参数:
参数:
- -dir dir 指定用于存放抓取文件的目录名称。
- -threads threads 决定将会在获取是并行的线程数。
- -depth depth 表明从根网页开始那应该被抓取的链接深度。
- -topN N 决定在每一深度将会被取回的网页的最大数目。
我们之前的抓取命令中:nohup ./bin/nutch crawl urls -dir data -threads 100 -depth 3 &
depth配置为3,也就是限定了抓取深度为3,即告诉Crawler需要执行3次“产生/抓取/更新”就可以抓取完毕了。那么现在要解释下两个问题,一是何谓一次“产生/抓取/更新”,二是每一次过程都做了哪些事情。
下面慢慢来解释,先查看日志
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ pwd
/home/hu/data/nutch/release-1.6/runtime/local
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ less nohup.out
| ……… Injector: starting at 2013-12-08 21:36:58
…………… Fetcher: finished at 2013-12-08 21:37:37, elapsed: 00:00:07 |
从上面日志可以看到,抓取过程先从Injector(注入初始Url,即将文本文件中的url 存入到crawldb中)开始
抓取过程为:
Injector->
Generator->Fetcher->ParseSegment->CrawlDb update depth=1
Generator->Fetcher->ParseSegment->CrawlDb update depth=2
Generator->Fetcher->ParseSegment->CrawlDb update->LinkDb depth=3
即循环Generator->Fetcher->ParseSegment->CrawlDb update 这个过程;
第一次注入url初值,Generator urls,Fetcher网页,ParseSegment解析数据,update CrawlDb 。之后每次更新crawldb,即url库。
下图提供网上找来的相关流程图片,以便于理解:
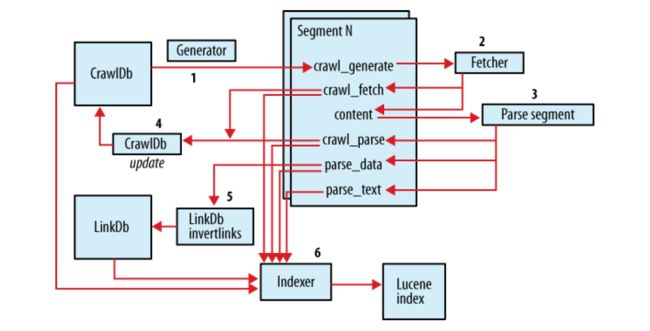
总结如下:
1) 建立初始 URL 集
2) 将 URL 集注入 crawldb 数据库---inject
3) 根据 crawldb 数据库创建抓取列表---generate
4) 执行抓取,获取网页信息---fetch
5) 解析抓取的内容---parse segment
6) 更新数据库,把获取到的页面信息存入数据库中---updatedb
7) 重复进行 3~5 的步骤,直到预先设定的抓取深度。---这个循环过程被称为“产生/抓取/更新”循环
8) 根据 sengments 的内容更新 linkdb 数据库---invertlinks
9) 建立索引---index
抓取完成之后生成3个目录(crawldb linkdb segments):
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ls ./data/
crawldb linkdb segments
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ls ./data/crawldb/
current old
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ls ./data/crawldb/current/
part-00000
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ls ./data/crawldb/current/part-00000/
data index
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ls ./data/crawldb/current/part-00000/data
./data/crawldb/current/part-00000/data
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ls ./data/crawldb/current/part-00000/index
./data/crawldb/current/part-00000/index
Nutch的数据文件:
crawldb: 爬行数据库,用来存储所要爬行的网址。
linkdb: 链接数据库,用来存储每个网址的链接地址,包括源地址和链接地址。
segments: 抓取的网址被作为一个单元,而一个segment就是一个单元。
crawldb
crawldb中存放的是url地址,第一次根据所给url :http://blog.tianya.cn进行注入,然后update crawldb 保存第一次抓取的url地址,下一次即depth=2的时候就会从crawldb中获取新的url地址集,进行新一轮的抓取。
crawldb中有两个文件夹:current 和old. current就是当前url地址集,old是上一次的一个备份。每一次生成新的,都会把原来的改为old。
current和old结构相同 里面都有part-00000这样的一个文件夹(local方式下只有1个) 在part-00000里面分别有data和index两个文件。一个存放数据,一个存放索引。
另外Nutch也提供了对crawldb文件夹状态查看命令(readdb):
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ./bin/nutch readdb
Usage: CrawlDbReader
-stats [-sort] print overall statistics to System.out
[-sort] list status sorted by host
-dump
[-format csv] dump in Csv format
[-format normal] dump in standard format (default option)
[-format crawldb] dump as CrawlDB
[-regex
[-status
-url
-topN
[
This can significantly improve performance.
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ./bin/nutch readdb ./data/crawldb -stats
CrawlDb statistics start: ./data/crawldb
Statistics for CrawlDb: ./data/crawldb
TOTAL urls: 2520
retry 0: 2520
min score: 0.0
avg score: 8.8253967E-4
max score: 1.014
status 1 (db_unfetched): 2346
status 2 (db_fetched): 102
status 3 (db_gone): 1
status 4 (db_redir_temp): 67
status 5 (db_redir_perm): 4
CrawlDb statistics: done
说明:
-stats命令是一个快速查看爬取信息的很有用的命令:
TOTAL urls:表示当前在crawldb中的url数量。
db_unfetched:链接到已爬取页面但还没有被爬取的页面数(原因是它们没有通过url过滤器的过滤,或者包括在了TopN之外被Nutch丢弃)
db_gone:表示发生了404错误或者其他一些臆测的错误,这种状态阻止了对其以后的爬取工作。
db_fetched:表示已爬取和索引的页面,如果其值为0,那肯定出错了。
db_redir_temp和db_redir_perm分别表示临时重定向和永久重定向的页面。
min score、avg score、max score是分值算法的统计值,是网页重要性的依据,这里暂且不谈。
此外,还可以通过readdb的dump命令将crawldb中内容输出到文件中进行查看:
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ./bin/nutch readdb ./data/crawldb -dump crawl_tianya_out
CrawlDb dump: starting
CrawlDb db: ./data/crawldb
CrawlDb dump: done
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ls ./crawl_tianya_out/
part-00000
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ less ./crawl_tianya_out/part-00000
| http://100w.tianya.cn/ Version: 7 http://aimin_001.blog.tianya.cn/ Version: 7 http://alice.tianya.cn/ Version: 7 http://anger.blog.tianya.cn/ Version: 7 ……………… |
从上面内容可以看到,里面保存了状态,抓取的时间,修改时间,有效期,分值,指纹,头数据等详细关于抓取的内容。
也可以使用url命令查看某个具体url的信息:
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ./bin/nutch readdb ./data/crawldb -url http://zzbj.tianya.cn/
URL: http://zzbj.tianya.cn/
Version: 7
Status: 1 (db_unfetched)
Fetch time: Sun Dec 08 21:42:34 CST 2013
Modified time: Thu Jan 01 08:00:00 CST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 7.6175966E-6
Signature: null
Metadata:
segments
每一个segments都是一组被作为一个单元来获取的URL。segments是它本身这个目录以及它下面的子目录:
- 一个crawl_generate确定了将要被获取的一组URL;
- 一个crawl_fetch包含了获取的每个URL的状态;
- 一个content包含了从每个URL获取回来的原始的内容;
- 一个parse_text包含了每个URL解析以后的文本;
- 一个parse_data包含来自每个URL被解析后内容中的外链和元数据;
- 一个crawl_parse包含了外链的URL,用来更新crawldb。
这里要穿插一下,通过查看nohup.out最后内容时,发现出现异常问题:
| hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ tail -n 50 nohup.out |
如上日志信息,出现此问题的原因和上一篇笔记中出现的http.agent.name问题有关,因http.agent.name问题出现异常,但仍然生成了相应的空文件目录。 解决方式也很简单,删除报错的文件夹即可。
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ls ./data/segments/
20131208211101 20131208213723 20131208213806 20131208213957
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ rm -rf data/segments/20131208211101
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ls ./data/segments/
20131208213723 20131208213806 20131208213957
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$
因为我们执行时的depth是3,一次爬行中每次循环都会产生一个segment,所以当前看到的是三个文件目录,Segment是有时限的,当这些网页被Crawler重新抓取后,先前抓取产生的segment就作废了。在存储中,Segment文件夹是以产生时间命名的,方便我们删除作废的segments以节省存储空间。我们可以看下每个文件目录下有哪些内容:
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ls data/segments/20131208213723/
content crawl_fetch crawl_generate crawl_parse parse_data parse_text
可以看到,一个segment包括以下子目录(多是二进制格式):
content:包含每个抓取页面的内容
crawl_fetch:包含每个抓取页面的状态
crawl_generate:包含所抓取的网址列表
crawl_parse:包含网址的外部链接地址,用于更新crawldb数据库
parse_data:包含每个页面的外部链接和元数据
parse_text:包含每个抓取页面的解析文本
每个文件的生成时间
1.crawl_generate在Generator的时候生成;
2.content,crawl_fetch在Fetcher的时候生成;
3.crawl_parse,parse_data,parse_text在Parse segment的时候生成。
如何查看每个文件的内容呢,如想查看content中抓取的网页源码内容,这个在本文后面会有介绍。
linkdb
linkdb: 链接数据库,用来存储每个网址的链接地址,包括源地址和链接地址。
由于http.agent.name原因,linkdb中内容插入失败,我重新执行了下爬虫命令,下面是执行完成后nohup.out中末尾日志信息:
| 。。。。。。 ParseSegment: finished at 2014-01-11 16:30:22, elapsed: 00:00:07 |
现在可以查看linkdb中内容信息了
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ bin/nutch readlinkdb ./data/linkdb -dump crawl_tianya_out_linkdb
LinkDb dump: starting at 2014-01-11 16:39:42
LinkDb dump: db: ./data/linkdb
LinkDb dump: finished at 2014-01-11 16:39:49, elapsed: 00:00:07
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ls ./crawl_tianya_out_linkdb/
part-00000
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ head -n 10 ./crawl_tianya_out_linkdb/part-00000
http://100w.tianya.cn/ Inlinks:
fromUrl: http://star.tianya.cn/ anchor: [2012第一美差]
fromUrl: http://star.tianya.cn/ anchor: 2013第一美差
http://aimin_001.blog.tianya.cn/ Inlinks:
fromUrl: http://blog.tianya.cn/blog/mingbo anchor: 长沙艾敏
fromUrl: http://blog.tianya.cn/ anchor: 长沙艾敏
http://alice.tianya.cn/ Inlinks:
fromUrl: http://bj.tianya.cn/ anchor:
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$
可以看到有的网页有多个Inlinks,这说明网页的重要性越大。和分值的确定有直接关系。比如一个网站的首页就会有很多的Inlinks。
其他信息查看:
1.根据需要可以通过命令查看抓取运行的相关讯息
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ cat nohup.out | grep elapsed
Injector: finished at 2013-12-08 21:10:53, elapsed: 00:00:14
Generator: finished at 2013-12-08 21:11:08, elapsed: 00:00:15
Injector: finished at 2013-12-08 21:37:15, elapsed: 00:00:17
Generator: finished at 2013-12-08 21:37:30, elapsed: 00:00:15
Fetcher: finished at 2013-12-08 21:37:37, elapsed: 00:00:07
ParseSegment: finished at 2013-12-08 21:37:45, elapsed: 00:00:07
CrawlDb update: finished at 2013-12-08 21:37:58, elapsed: 00:00:13
Generator: finished at 2013-12-08 21:38:13, elapsed: 00:00:15
Fetcher: finished at 2013-12-08 21:39:29, elapsed: 00:01:16
ParseSegment: finished at 2013-12-08 21:39:36, elapsed: 00:00:07
CrawlDb update: finished at 2013-12-08 21:39:49, elapsed: 00:00:13
Generator: finished at 2013-12-08 21:40:04, elapsed: 00:00:15
Fetcher: finished at 2013-12-08 21:42:17, elapsed: 00:02:13
ParseSegment: finished at 2013-12-08 21:42:24, elapsed: 00:00:07
CrawlDb update: finished at 2013-12-08 21:42:37, elapsed: 00:00:13
Injector: finished at 2014-01-11 16:22:29, elapsed: 00:00:14
Generator: finished at 2014-01-11 16:22:45, elapsed: 00:00:15
Fetcher: finished at 2014-01-11 16:22:52, elapsed: 00:00:07
ParseSegment: finished at 2014-01-11 16:22:59, elapsed: 00:00:07
CrawlDb update: finished at 2014-01-11 16:23:12, elapsed: 00:00:13
Generator: finished at 2014-01-11 16:23:27, elapsed: 00:00:15
Fetcher: finished at 2014-01-11 16:24:48, elapsed: 00:01:21
ParseSegment: finished at 2014-01-11 16:24:55, elapsed: 00:00:07
CrawlDb update: finished at 2014-01-11 16:25:05, elapsed: 00:00:10
Generator: finished at 2014-01-11 16:25:20, elapsed: 00:00:15
Fetcher: finished at 2014-01-11 16:30:15, elapsed: 00:04:54
ParseSegment: finished at 2014-01-11 16:30:22, elapsed: 00:00:07
CrawlDb update: finished at 2014-01-11 16:30:35, elapsed: 00:00:13
LinkDb: finished at 2014-01-11 16:30:48, elapsed: 00:00:13
2.查看segments目录下content内容,上面我们提到content内容是抓取时网页的源码内容,但因为是二进制的无法直接查看,不过nutch提供了相应的查看方式:
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ bin/nutch readseg
Usage: SegmentReader (-dump ... | -list ... | -get ...) [general options]
* General options:
-nocontent ignore content directory
-nofetch ignore crawl_fetch directory
-nogenerate ignore crawl_generate directory
-noparse ignore crawl_parse directory
-noparsedata ignore parse_data directory
-noparsetext ignore parse_text directory
* SegmentReader -dump
* SegmentReader -list (
List a synopsis of segments in specified directories, or all segments in
a directory
-dir
* SegmentReader -get
Get a specified record from a segment, and print it on System.out.
Note: put double-quotes around strings with spaces.
查看 content:
content包含了从每个URL获取回来的原始的内容。
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ bin/nutch readseg -dump ./data/segments/20140111162237 ./data/crawl_tianya_seg_content -nofetch -nogenerate -noparse -noparsedata -noparsetext
SegmentReader: dump segment: data/segments/20140111162237
SegmentReader: done
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ls ./data/crawl_tianya_seg_content/
dump .dump.crc
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ head -n 50 ./data/crawl_tianya_seg_content/dump
Recno:: 0
URL:: http://blog.tianya.cn/
Content::
Version: -1
url: http://blog.tianya.cn/
base: http://blog.tianya.cn/
contentType: text/html
metadata: Date=Sat, 11 Jan 2014 08:22:46 GMT Vary=Accept-Encoding Expires=Thu, 01 Nov 2012 10:00:00 GMT Content-Encoding=gzip nutch.crawl.score=1.0 _fst_=33 nutch.segment.name=20140111162237 Content-Type=text/html; charset=UTF-8 Connection=close Server=nginx Cache-Control=no-cache Pragma=no-cache
Content:
- 博客首页
- 社会民生
- 国际观察
- 娱乐
- 体育
- 文化
- 历史
- 生活
- 情感
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$
我们也可以采取同样的方式查看其他文件内容,如crawl_fetch,parse_data等。
查看crawl_fetch:
crawl_fetch包含了获取的每个URL的状态。
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ bin/nutch readseg -dump ./data/segments/20140111162237 ./data/crawl_tianya_seg_fetch -nocontent -nogenerate -noparse -noparsedata -noparsetext
SegmentReader: dump segment: data/segments/20140111162237
SegmentReader: done
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ head -n 50 ./data/crawl_tianya_seg_fetch/dump
Recno:: 0
URL:: http://blog.tianya.cn/
CrawlDatum::
Version: 7
Status: 33 (fetch_success)
Fetch time: Sat Jan 11 16:22:46 CST 2014
Modified time: Thu Jan 01 08:00:00 CST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.0
Signature: null
Metadata: _ngt_: 1389428549880Content-Type: text/html_pst_: success(1), lastModified=0
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$
查看crawl_generate:
crawl_generate确定了将要被获取的一组URL。
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ bin/nutch readseg -dump ./data/segments/20140111162237 ./data/crawl_tianya_seg_generate -nocontent -nofetch -noparse -noparsedata -noparsetext
SegmentReader: dump segment: data/segments/20140111162237
SegmentReader: done
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ head -n 50 ./data/crawl_tianya_seg_generate/dump
Recno:: 0
URL:: http://blog.tianya.cn/
CrawlDatum::
Version: 7
Status: 1 (db_unfetched)
Fetch time: Sat Jan 11 16:22:15 CST 2014
Modified time: Thu Jan 01 08:00:00 CST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.0
Signature: null
Metadata: _ngt_: 1389428549880
查看crawl_parse:
crawl_parse包含了外链的URL,用来更新crawldb。
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ bin/nutch readseg -dump ./data/segments/20140111162237 ./data/crawl_tianya_seg_parse -nofetch -nogenerate -nocontent –noparsedata –noparsetext
SegmentReader: dump segment: data/segments/20140111162237
SegmentReader: done
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ head -n 50 ./data/crawl_tianya_seg_parse/dump
Recno:: 0
URL:: http://aimin_001.blog.tianya.cn/
CrawlDatum::
Version: 7
Status: 67 (linked)
Fetch time: Sat Jan 11 16:22:55 CST 2014
Modified time: Thu Jan 01 08:00:00 CST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 0.016949153
Signature: null
Metadata:
Recno:: 1
URL:: http://anger.blog.tianya.cn/
CrawlDatum::
Version: 7
Status: 67 (linked)
Fetch time: Sat Jan 11 16:22:55 CST 2014
Modified time: Thu Jan 01 08:00:00 CST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 0.016949153
Signature: null
Metadata:
。。。。
查看parse_data:
parse_data包含来自每个URL被解析后内容中的外链和元数据。
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ bin/nutch readseg –dump ./data/segments/20140111162237 ./data/crawl_tianya_seg_data -nofetch -nogenerate -nocontent -noparse –noparsetext
SegmentReader: dump segment: data/segments/20140111162237
SegmentReader: done
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ head -n 50 ./data/crawl_tianya_seg_data/dump
Recno:: 0
URL:: http://blog.tianya.cn/
ParseData::
Version: 5
Status: success(1,0)
Title: 天涯博客_有见识的人都在此
Outlinks: 59
outlink: toUrl: http://blog.tianya.cn/blog/society anchor: 社会民生
outlink: toUrl: http://blog.tianya.cn/blog/international anchor: 国际观察
outlink: toUrl: http://blog.tianya.cn/blog/ent anchor: 娱乐
outlink: toUrl: http://blog.tianya.cn/blog/sports anchor: 体育
outlink: toUrl: http://blog.tianya.cn/blog/culture anchor: 文化
outlink: toUrl: http://blog.tianya.cn/blog/history anchor: 历史
outlink: toUrl: http://blog.tianya.cn/blog/life anchor: 生活
outlink: toUrl: http://blog.tianya.cn/blog/emotion anchor: 情感
outlink: toUrl: http://blog.tianya.cn/blog/finance anchor: 财经
outlink: toUrl: http://blog.tianya.cn/blog/stock anchor: 股市
outlink: toUrl: http://blog.tianya.cn/blog/food anchor: 美食
outlink: toUrl: http://blog.tianya.cn/blog/travel anchor: 旅游
outlink: toUrl: http://blog.tianya.cn/blog/newPush anchor: 最新博文
outlink: toUrl: http://blog.tianya.cn/blog/mingbo anchor: 天涯名博
outlink: toUrl: http://blog.tianya.cn/blog/daren anchor: 博客达人
outlink: toUrl: http://www.tianya.cn/mobile anchor:
outlink: toUrl: http://bbs.tianya.cn/post-1018-1157-1.shtml anchor: 天涯“2013年度十大深度影响力博客”名单
outlink: toUrl: http://jingyibaobei.blog.tianya.cn/ anchor: 烟花少爷
outlink: toUrl: http://lljjasmine.blog.tianya.cn/ anchor: 寻梦的冰蝶
。。。。
查看parse_text:
parse_text包含了每个URL解析以后的文本。
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ bin/nutch readseg -dump ./data/segments/20140111162237 ./data/crawl_tianya_seg_text -nofetch -nogenerate -nocontent -noparse -noparsedata
SegmentReader: dump segment: data/segments/20140111162237
SegmentReader: done
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ head -n 50 ./data/crawl_tianya_seg_text/dump
Recno:: 0
URL:: http://blog.tianya.cn/
ParseText::
天涯博客_有见识的人都在此 博客首页 社会民生 国际观察 娱乐 体育 文化 历史 生活 情感 财经 股市 美食 旅游 最新博文 天涯名博 博客达人 博客总排行 01 等待温暖的小狐狸 44887595 02 潘文伟 34654676 03 travelisliving 30676532 04 股市掘金 28472831 05 crystalkitty 26283927 06 yuwenyufen 24880887 07 水莫然 24681174 08 李泽辉 22691445 09 钟巍巍 19226129 10 别境 17752691 11 微笑的说我很幸 15912882 12 尤宇 15530802 13 sundaes 14961321 14 郑渝川 14219498 15 黑花黄 13174656 博文排行 01 任志强戳穿“央视十宗罪”都 02 野云先生:钱眼里的文化(5 03 是美女博士征男友还是媒体博 04 黄牛永远走在时代的最前沿 05 “与女优度春宵”怎成员工年 06 如何看待对张艺谋罚款748万 07 女保姆酒后色诱我上床被妻撞 08 年过不惑的男人为何对婚姻也 09 明代变态官员囚多名尼姑做性 10 女人不肯承认的20个秘密 社会排行 国际排行 01 风青杨:章子怡“七亿陪睡案 02 潘金云和她的脑瘫孩子们。 03 人民大学前校长纪宝成腐败之 04 小学语文课本配图错误不是小 05 闲聊“北京地铁要涨价” 06 “高压”整治火患之后,还该 07 警惕父母误导孩子的十种不良 08 一代名伶红线女为什么如此红 09 黎明:应明令禁止官员技侦发 10 官二代富二代的好运气不能独 01 【环球热点】如此奢华—看了 02 阿基诺的民,阿基诺的心,阿 03 “中国向菲律宾捐款10万美元 04 美国法律界:对青少年犯罪的 05 一语中的:诺贝尔奖得主锐评 06 300万元保证金骗到武汉公司1 07 乱而取之的智慧 08 中国连宣泄愤怒都有人“代表 09 世界啊,请醒醒吧,都被美元 10 反腐利器呼之欲出,贪腐官员 娱乐排行 体育排行 01 2013网络票选新宅男女神榜单 02 从《千金归来》看中国电视剧 03 汪峰自称是好爸爸时大家都笑 04 黄圣依称杨子是靠山打了谁的 05 汪峰连锁型劣迹被爆遭六六嘲 06 舒淇深V礼服到肚脐令人窒息 07 张柏芝交老外新欢照曝光(图 08 吴奇隆公开恋情众网友送祝福 09 独家:赵本山爱女妞妞练功美 10 “帮汪峰上头条”背后的注意 01 道歉信和危机公关 02 【环球热点】鸟人(视频) 03 曼联宣布维迪奇已出院 04 哈登,别让假摔毁了形象。。。。。。
也可以统一放到一个文件中去查看:
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ bin/nutch readseg -dump ./data/segments/20140111162237 ./data/segments/20140111162237_dump
SegmentReader: dump segment: data/segments/20140111162237
SegmentReader: done
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ less ./data/segments/20140111162237_dump/dump
3.通过list,get列出segments一些统计信息
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ bin/nutch readseg -list -dir data/segments
NAME GENERATED FETCHER START FETCHER END FETCHED PARSED
20140111162237 1 2014-01-11T16:22:46 2014-01-11T16:22:46 1 1
20140111162320 57 2014-01-11T16:23:27 2014-01-11T16:24:43 58 19
20140111162513 135 2014-01-11T16:25:21 2014-01-11T16:30:09 140 102
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ bin/nutch readseg -list data/segments/20140111162320/
NAME GENERATED FETCHER START FETCHER END FETCHED PARSED
20140111162320 57 2014-01-11T16:23:27 2014-01-11T16:24:43 58 19
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ bin/nutch readseg -get data/segments/20140111162513 http://100w.tianya.cn/
SegmentReader: get 'http://100w.tianya.cn/'
Crawl Parse::
Version: 7
Status: 67 (linked)
Fetch time: Sat Jan 11 16:30:18 CST 2014
Modified time: Thu Jan 01 08:00:00 CST 1970
Retries since fetch: 0
Retry interval: 2592000 seconds (30 days)
Score: 1.8224896E-6
Signature: null
Metadata:
4.通过readdb及topN参数命令查看按分值排序的url
(1).这里我设定的条件为:前10条,分值大于1
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ./bin/nutch readdb ./data/crawldb -topN 10 ./data/crawldb_topN 1
CrawlDb topN: starting (topN=10, min=1.0)
CrawlDb db: ./data/crawldb
CrawlDb topN: collecting topN scores.
CrawlDb topN: done
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ cat ./data/crawldb_topN/part-00000
1.0140933 http://blog.tianya.cn/
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$
(2).不设分值条件,查询前10条
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ ./bin/nutch readdb ./data/crawldb -topN 10 ./data/crawldb_topN_all_score
CrawlDb topN: starting (topN=10, min=0.0)
CrawlDb db: ./data/crawldb
CrawlDb topN: collecting topN scores.
CrawlDb topN: done
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$ cat ./data/crawldb_topN_all_score/part-00000
1.0140933 http://blog.tianya.cn/
0.046008706 http://blog.tianya.cn/blog/society
0.046008706 http://blog.tianya.cn/blog/international
0.030586869 http://blog.tianya.cn/blog/mingbo
0.030586869 http://blog.tianya.cn/blog/daren
0.030330064 http://www.tianya.cn/mobile
0.029951613 http://blog.tianya.cn/blog/culture
0.029951613 http://blog.tianya.cn/blog/history
0.029951613 http://blog.tianya.cn/blog/life
0.029951613 http://blog.tianya.cn/blog/stock
hu@hu-VirtualBox:~/data/nutch/release-1.6/runtime/local$
---------------------------
nutch抓取过程简析今天就记录到这。
参考:
http://yangshangchuan.iteye.com/category/275433
http://www.oschina.net/translate/nutch-tutorial Nutch 教程
http://wenku.baidu.com/view/866583e90975f46527d3e1f3.html Nutch入门教程.pdf
转载于:https://www.cnblogs.com/huligong1234/p/3515214.html