机器学习算法02—— K近邻算法实战
摘要:本文主要介绍kNN算法的原理和实列。包括算法描述、算法缺点、算法概述。
1.kNN定义
若一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本的大多数是属于类别A,则该样本也是属于A类。
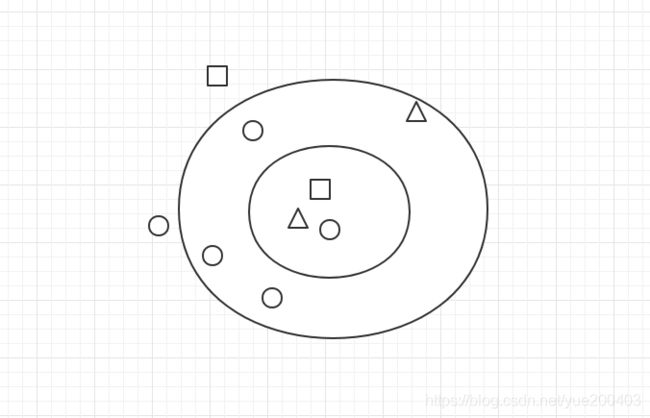
2.kNN详细描述:
已存在一个带标签的数据库,对输入没有标签的新数据后。将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似(最邻近)的分类标签。只选择前k个最相似的数据,然后从k个里选中出现次数最多的分类。
3.kNN算法描述
1.计算已知类别数据集中的点与当前点之间的距离。
2.按照距离递增次序排序。
3.取与当前距离最小的前k个点
4.确定前k个点所在类别的出现频率。
5.返回前k个点中出现频率最高类别作为当前点的预测分类
4.kNN分类----------鸢尾花
(我使用的是Jupyter,它比较好用,且不需要自己导包,使用了import就可以用该包)
1.导入数据集,从sklearn.datasets自带的数据集中导入
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
2.封装kNN算法类
import numpy as np
from math import sqrt
from collections import Counter
class KNNClassifier:
def __init__(self,k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None
self._y_train = None
def fit(self,X_train,y_train):
"""根据训练集X_train,y_train训练KNN分类器"""
assert X_train.shape[0] == y_train.shape[0], "the size of X_train must equal to the size of y_train"
assert self.k <= X_train.shape[0], "the size of X_train must be at least k"
self._X_train = X_train
self._y_train = y_train
return self
def predict(self,X_predict):
"给定待预测的数据集X_predict,返回表示X_predict的结果向量"
assert self._X_train is not None and self._y_train is not None, "must fit before predict"
assert X_predict.shape[1] == self._X_train.shape[1], "the feature number of X_predict must equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self,x):
"""给定单个待预测数据x,返回x的预测结果"""
assert x.shape[0] == self._X_train.shape[1], "the feature number of x must equal to X_train"
distances = [sqrt(np.sum(i-x)**2) for i in self._X_train]
nearset = np.argsort(distances)
topk_y = [self._y_train[i] for i in nearset[:self.k]]
votes = Counter(topk_y)
return votes.most_common(1)[0][0]
def _repr_(self):
return "KNN(K=%d)" % self.k
3.分割数据以及训练和预测 这里k取20的测试准确率比较高
knn = KNNClassifier(k=20)
from sklearn.model_selection import train_test_split
train_X,test_X,train_y,test_y = train_test_split(X,y,test_size=0.2,random_state=0)
knn.fit(train_X,train_y)
result = knn.predict(test_X)
display(np.sum(result==test_y))
4.对上面的数据可视化展示
#数据可视化
import matplotlib as mpl
import matplotlib.pyplot as plt
#设置画布大小
plt.figure(figsize=(10,10))
#绘制训练集结果 只取第0列和第1列的数据显示
plt.scatter(train_X[train_y==0,2],train_X[train_y==0,3],color='y',label='Iris-virginica')
plt.scatter(train_X[train_y==1,2],train_X[train_y==1,3],color='orange',label='Iris-setosa')
plt.scatter(train_X[train_y==2,2],train_X[train_y==2,3],color='pink',label='Iris-versicolor')
right = test_X[result==test_y]
wrong = test_X[result!=test_y]
#绘制测试集正确结果
plt.scatter(test_X[test_y==0,2],test_X[test_y==0,3],color='b',label='l-Iris-virginica')
plt.scatter(test_X[test_y==1,2],test_X[test_y==1,3],color='r',label='l-Iris-setosa')
plt.scatter(test_X[test_y==2,2],test_X[test_y==2,3],color='cyan',label='l-Iris-versicolor')
#绘制knn模型预测结果
plt.scatter(test_X[result==0,2],test_X[result==0,3],color='g',label='p-Iris-virginica',marker='>')
plt.scatter(test_X[result==1,2],test_X[result==1,3],color='g',label='p-Iris-setosa',marker='+')
plt.scatter(test_X[result==2,2],test_X[result==2,3],color='g',label='p-Iris-versicolor',marker='*')
plt.title('knn model result')
plt.xlabel('length')
plt.ylabel('width')
plt.legend(loc='best')
5.效果图(可能需放大看的更清楚)
1.这个是取前两个维度展示的结果;结合上面代码,其中Iris开头的是训练集结果;l-Iris开头的是测试集正确结果;p-Iris开头的是knn模型预测结果;从下图可知,30个测试样本有三个是分类错误的,其准确率是27/30,达到90%以上。

2.这个是取后两个维度展示的结果。(与上面代码相符)
