【译文】A Baseline for 3D Multi-Object Tracking
3D多目标跟踪的基线
作者:wengxinshuo
作者主页:http://www.xinshuoweng.com,主页有代码和视频
Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud 这篇文章也是她写的,强,学习!
摘要
三维多目标跟踪(MOT)是自主驾驶、辅助机器人等许多实时应用领域的关键技术,但近年来的研究工作更多地集中于开发精确的系统,较少考虑计算成本和系统复杂度。相反,本工作提出了一个简单而准确的实时基线三维MOT系统,我们使用一个现成的三维物体检测器(PointRCNN,基于PointNet++)从激光雷达点云获取带有方向角的三维边界盒(之后简称bbox)。然后,结合三维卡尔曼滤波和匈牙利匹配算法进行状态估计和数据关联。虽然我们的基线系统是标准方法的直接组合,但我们获得了最先进的结果。为了评估我们的基线系统,我们提出了一个新的3D MOT扩展到官方的KITTI 2D MOT评估,以及两个新的指标。我们提出的3D MOT基线方法为KITTI在3D MOT上建立了新的技术状态,将3D MOTA(多目标跟踪精度)从现有技术的72:23提高到76:47。令人惊讶的是。通过将我们的三维跟踪结果投影到二维mage平面上,并与已发表的二维MOT方法进行比较,我们的系统在KITTI官方排行榜上排名第二。此外,我们提出的3D MOT方法以214.7 FPS的速度运行。比最先进的2D MOT系统快65倍。
代码开源网址:https://github.com/xinshuoweng/AB3DMOT
// 虽然检测调的别人的算法,匹配和跟踪也是传统的匈牙利和卡尔曼滤波,但是升级到了3D,开了先河,而且241.7帧/秒简直快爆了牛逼!
1介绍
(参考文献用【】代替了)
多目标跟踪(MOT)是自主驾驶、机器人碰撞预测、视频人脸识别等众多视觉应用中必不可少的构件技术。由于在目标检测方面的重大进展,MOT取得了很大的进展。例如,对于KITTI的 MOT基准测试上的car类别,MOTA(多目标跟踪精度)在两年内从57.03提高到84.24。
尽管精度上有了很大的提高,但是代价是增加了系统的复杂性和计算量。复杂的系统使得模块化具有挑战,而且不清楚系统的哪个部分对性能贡献最大。例如,【】的主导工作有大量不同的系统管道,但在性能上只有很小的差异。而且,增加的计算成本产生的不利影响在【】中也很明显。虽然有很高的准确性,但是实时跟踪是遥不可及的。
相对于以前的工作更侧重于系统复杂性和计算成本,我们的目的在于提高准确性、简单实时的3D MOT系统。结果表示我们提出的系统结合了最小的3D MOT的部件,具有良好的运动性能。在KITTI数据集上,我们的系统在3D MOT上建立了最先进的性能。令人惊讶的是,如果我们投影3D跟踪结果到2D图像平面上,并且与所有已经发布的2D MOT方法对比,我们的系统在KITTI排行榜上占据第二,如图1所示。此外,由于我们的系统简单,它能以241.7FPS的速度在KITTI测试集上运行,是最先进MOT系统(BeyondPixels)的65倍。和其他实时MOT系统相比,例如 Complexer-YOLO,LP-SSVM,3D-CNN/PMBM,和MCMOT-CPD,我们的系统至少是两倍速且达到了更高的精度。我们希望我们的系统将作为一个简单而强大的基线,在此基础上,其他人能很容易的建立先进的3D MOT。

从技术上来讲,我们使用了一个现成的3D障碍物检测器,从激光雷达点云中获取有方向角的3D包围盒bbox。然后。结合3D卡尔曼滤波(恒速模型)和匈牙利算法进行状态估计和数据融合。虽然这些模块的组合很常规,但我们能够得到最先进的结果。而且,不想之前的3D MOT系统通常在在二维图像空间或者鸟瞰图中定义KF的状态空间。我们将KF扩展到了全三维领域,包括物体的三维位置,大小,速度和方向。
此外,我们发现了当前3D MOT评估两个缺点:
(1)KITTI数据集等标准MOT基准仅支持二维MOT评估,即,对图像平面的求值。在三维空间中直接评价三维MOT系统的工具目前还没有。当前的3D MOT评估方法是将三维轨迹输出投影到2D 图像平面,在KITTI 2D MOT基准上评估。然而我们认为这将阻碍三维MOT系统的未来发展,因为在图像平面上不能充分展示三维定位和跟踪的能力。为解决这个问题,我们提供了一个KITTI 2D MOT评估的3D 扩展,我们称之为KITTI-3DMOT评估工具。
(2)MOTA和MOTP等常见的MOT指标不考虑轨迹的置信度,因此需要选择一个置信度阈值来过滤误报。因此,它不能很好地反映不同阈值下的全谱精度和精度。为了解决这个问题,我们提出了两个新的度量标准——AMOTA和AMOTP (average)
总结所有阈值的性能。我们建议的KITTI-3DMOT评估工具和新的指标的代码一起发布,我们希望未来的3D MOT系统将使用它作为标准的评估工具。
我们的贡献总结如下:
(1)我们为在线实时应用提供了简单且准确的3D MOT基线系统;
(2)对官方KITTI 2D MOT评估器进行了三维扩展,实现了3D MOT评估;
(3)为鲁棒MOT提出了两种指标;
(4)我们的系统建立了最先进的性能在提出的KITTI 3DMOT评估工具上,并且排名第二,同时实现了最快速。
我们在此强调,尽管我们的3D MOT系统有更好的结果和更快的速度,但我们并不声称我们的3D MOT系统比之前的工作具有显著的算法新颖性。如前所述,我们希望我们的系统可以作为一个简单和坚实的基线,其他人可以很容易地建立在此基础上,以推进最先进的3D MOT。
2 相关工作(=文献综述)
2D 多目标跟踪
近年来,基于数据关联的二维MOT系统主要分为两类**:批处理方法和在线方法**。批处理方法试图从整个序列中找到全局最优解。它们通常创建一个网络流程图,可以用最小代价流算法求解。另一方面,在线方法只考虑当前帧的检测,对于实时应用通常是有效的。这些方法通常将数据关联问题表述为二分图匹配问题,并使用匈牙利算法解决【// 计算IOU,大于阈值即关联】。除了在后处理步骤中使用匈牙利算法外,现代在线方法还设计了能够使用神经网络构建关联的深度关联网络。我们的MOT系统也属于在线方法。为了简单和实时有效,我们采用了原始的匈牙利算法,没有使用神经网络。
独立于数据关联之外,设计合适的亲和度成本函数也是MOT系统的关键。早期的工作使用手工设定的特征,如空间距离和颜色直方图作为成本函数。相反,现代方法应用运动模型并且学习外观特征。与以往将外观模型与运动模型进行复杂组合的工作相比,我们选择使用最简单的运动模型,即,恒速,不使用外观模型。
3D 多目标跟踪
大多数3D MOT系统和2D共享相同的组件、唯一的区别在于检测的包围盒在三维空间而不是图像平面。因此,它有潜力去设计运动和外观模型在三维空间无角度失真。
【Mono-Camera3D Multi-Object Tracking Using Deep Learning Detections and PMBM Filtering. IV, 2018.】
提出了一种基于图像的方法,在三维空间中估计物体的位置和与摄像机的距离。然后利用泊松多伯努利混合滤波器估计物体的三维速度。
【The H3D Dataset for Full-Surround 3D Multi-Object Detection and Tracking in Crowded Urban Scenes. ICRA, 2019.】
在鸟瞰图中应用无迹卡尔曼滤波来估计三维速度和角速度。
【Combined Image- and World-Space Trackingin Traffic Scenes. ICRA, 2017.】
提出了一种2D-3D的卡尔曼滤波器,将图像观测和3D世界观测相结合,而不是使用手工制作的过滤器。
【3D Multi-Object Tracking with Feature Association Network. arXiv:1905.02843, 2019.】
【End-to-End Learning of Multi-Sensor 3D Tracking by Detection.ICRA, 2018.】设计暹罗网路从资料中学习过滤器。
与以往使用复杂滤波器的工作不同,为了简单,我们提出的系统仅使用原始的卡尔曼滤波器【A New Approach to Linear Filtering and Prediction Problems】,但将其状态空间扩展到整个三维域,不仅包括三维速度,还包括物体的三维尺寸、三维位置和航向角。
3D物体检测
作为三维MOT不可缺少的一部分,检测的3Dbbox的质量也很重要。先前的工作主要集中在处理激光雷达点云的输入,
【 Fast and Furious: Real Time End-to-End 3D Detection,Tracking and Motion Forecasting with a Single Convolutional Net. CVPR, 2018.】【VoxelNet: End-to-End Learning for Point Cloud Based 3D ObjectDetection. CVPR, 2018.】将点云划分为等间距的三维体素,应用3DCNNs来做3D bbox预测。
【HDNET: Exploiting HD Maps for 3D Object Detection.CoRL, 2018.】转换点云到鸟瞰图,并利用2D卷积。
【PointRCNN: 3D Object Proposal Generation and Detection fromPoint Cloud. CVPR, 2019.】直接处理点云输入,使用PointNet++进行3D检测。
此外,不使用点云,【Monocular 3D Object Detection Leveraging AccurateProposals and Shape Reconstruction. CVPR, 2019.】【Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud.arXiv:1903.09847, 2019. 】从单一图像实现了三维检测
3 方法
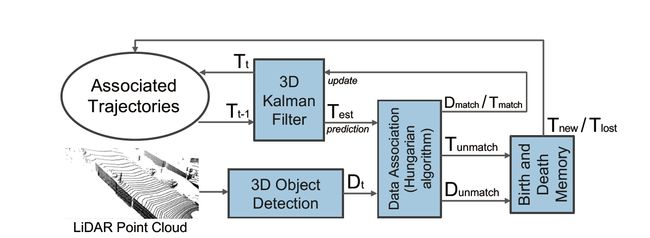
3D MOT的目标是将检测到的3D包围盒按顺序关联起来。由于我们的系统是一个在线的方法,在每一帧,我们只需要检测当前帧和与前一帧相关联的轨迹。我们的系统管道如图2所示,由以下几个部分组成:
(1)三维检测模块提供激光雷达点云的边界盒;
(2)三维卡尔曼滤波器预测当前帧的对象状态;
(3)数据关联模块将检测与预测轨迹匹配;
(4)三维卡尔曼滤波器根据测量结果更新目标状态;
(5)生死记忆控制着新出现和消失的轨迹
在【】之后,我们参数化了3D bbox化为8个参数的集合,包括三维坐标系下障碍物的中心点(x,y,z),障碍物(bboxs)大小(l,w,h),航向角θ,和它的置信度s。除了3D物体检测模块,我们的3D MOT系统不需要任何训练过程,可以直接进行推理。
3.1 3D物体检测
由于最近在三维物体检测方面的进展,我们可以利用许多成功的探测器的高质量检测。在这里,我们用两个在KITTI上最先进的3D探测器进行实验(PointRCNN和Mono3D_PLiDAR【作者自己写的】)。我们直接采用他们的模型在KITTI 3D对象检测基准的训练集上进行预训练。在第t帧,3D检测模块输出是一组检测 Dt = {Dt1,Dt2,…,Dtn}(n是不同帧之间变化的检测次数,就是一帧检测的bboxs数量),每个检测Dti用一个上面提到的组合(x,y,z,l,w,h,θ,s)来表示。在消融研究中,我们将展示不同的3D检测模块如何影响我们的3D MOT系统的性能。
PointRCNN【激光雷达,检测排行靠前,基于PointNet++】,Mono3D_PLiDAR【图像,作者自己写的】
3.2 3D卡尔曼滤波器——状态预测
为了预测下一帧的物体状态,我们使用恒定速度模型来近似物体的帧间位移,不依赖于相机的自运动。详细地,我们将物体轨迹的状态表示为一个10维向量T = (x,y,z,l,w,h,vx,vy,vz)。附加变量vx,vy,vz代表三维空间里物体的速度,没有包含角速度vθ是因为我们凭经验发现加入角速度会导致性能下降。
在每一帧,所有与前一帧T关联的轨迹Tt-1 = {Tt1,Tt2,…,Ttn}将被传到第t帧,命名为Test,基于恒速模型:
Xest = X + Vx;
Yest = Y + Vy;
Zest = Z + Vz;
因此对于每条轨迹在Tt-1中的,传播到t帧后的预测状态为预测状态为Test-j(同十维变量T),它将被输入数据关联模块。(公式就不写了,麻烦,markdown的公式编辑器不会用)
3.3 数据关联
为了使检测结果和预测轨迹相匹配,我们使用了匈牙利算法。亲和度矩阵计算每一对检测和预测轨迹之间的3D IOU。然后,可以利用匈牙利算法在多项式时间内解决二分图匹配问题。此外我们拒绝匹配IoU小于最小阈值的。数据关联模块的输出是一组检测:
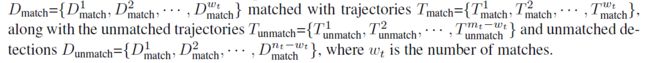
3.4 3D卡尔曼滤波器——状态更新
为了考虑Tmatch中的不确定性,我们根据Tmatch中每个轨迹对应的测量值来更新Tmatch中每个轨迹的整个状态空间,即, Dmatch中的匹配检测,并得到最终第t帧的关联轨迹Tt。根据贝叶斯规则,用上一步关联匹配的状态空间的加权平均值,更新每个轨迹的状态,加权平均值由上一步关联匹配的轨迹和检测的不确定性确定(详见卡尔曼滤波[42])。
此外,我们观察到朴素加权平均不能很好地用于定向。对于一个匹配了的对象i,它检测D的方向可以与和轨迹T的方向几乎相反,相差180°。然而,这是不可能的,因为我们假设物体应该平稳移动,并且在一帧内(0.1s)不能改变180°的方向。因此,匹配关联的D和T方向是错误的。因此,物体的平均轨迹T将会有一个在匹配关联的D和T方向之间的朝向,会导致相对有真值的低Iou值。为了防止这个问题,我们提出了一个方向校正技术。当Di匹配和Ti匹配的方向差异大于时90°时,给Timatch的方向角加180°,这样就和Dimatch方向大致一致了。我们将在消融研究中展示方位校正的作用。
3.5 生死记忆
由于现有的对象可能会消失,新的对象可能会进入,因此需要一个模块来管理轨迹的生成和去除。一方面,我们考虑所有不匹配的探测作为潜在的对象进入图像。为了避免误报跟踪,一个新的轨迹将不会为Diunmatch创建,直到它被连续检测到下一个Fmin帧。一旦新轨迹被成功创建,我们将轨迹的状态与其最近的测量相同,以vx,vy和vz的零速度进行初始化。
另一方面,我们认为所有不匹配的轨迹都是离开图像的潜在对象。为了避免删除某些帧上缺失检测的真正轨迹,我们对每一个Agemax帧的不匹配轨迹进行跟踪相关的轨迹。理想情况下,我们的三维MOT系统可以保持和插值真正的正轨迹与缺失检测,只有离开图像的轨迹被删除。
4 新MOT评估工具
4.1 KITTI-3DMOT 评估工具
KITTI数据集作为MOT测试中最重要的基准之一,对MOT测试的进展起着至关重要的作用。虽然KITTI数据集支持广泛的2D MOT评估,即,对图像平面的求值。在三维空间中直接评价三维MOT系统的工具目前还没有。因此,当前的三维运动轨迹评价方法是将三维轨迹输出投影到图像平面上,并使用二维IoU作为代价函数将投影的二维轨迹输出与二维地面真实轨迹进行匹配。然而,我们认为在二维图像平面上进行评价并不能充分体现三维定位和跟踪的能力。
为了更好地评估3DMOT系统,我们打破常规,实现了官方KITTI 2D MOT评估的3D扩展,我们称之为KITTI-3DMOT评估工具。具体地,我们将二维IoU的两两代价函数修改为三维IoU,并将三维轨迹输出直接与三维地面真实轨迹进行匹配。
4.2 新的MOT评估指标:平均MOTA/MOTP (AMOTA/AMOTP)
常规的MOT评估报告会根据如MOTA(详见第5.1节),MOTP,FP,FN,Precision,F1 score,IDS,FRAG等广泛指标来得出结果。但是,这些指标均未考虑轨迹的置信度。 因此,必须在评估之前选择单个置信度阈值,以滤除对误报的跟踪。 在这里,我们在图3中显示了使用不同阈值在六个MOT指标上的3D MOT系统的结果。我们可以看到,图3 (f)当召回数量超过0.8时,误报数量急剧增加,即,要使用一个非常低的阈值。此外,阈值也不能设置得太高,因为它会导致非常低的召回率和大量的假阴性,如图3 (e)所示。
因此,由于当前的度量没有考虑置信度,MOT系统必须选择一个适当的阈值,例如图3 (a)中的红点,以达到最高
MOTA2和排名。尽管使用单个阈值修复系统就足以进行部署,使用单一的阈值进行评价将会阻碍MOT系统未来的发展,因为在单一的阈值中无法反映所有的准确度和精密度。换句话说,一个MOT系统仅在一个阈值处获得较高的MOTA,而在其他阈值处获得极低的MOTA,仍然可以使用当前的度量标准。但在理想情况下,研究人员应该继续开发MOT系统,使MOTA在所有阈值上都尽可能高。
为了缓解上述问题,我们提出了两个新的度量标准,我们称之为AMOTA和AMOTP(平均MOTA和MOTP),总结所有阈值的MOTA和MOTP,而不是使用单一阈值。与目标检测的平均精度相似,AMOTA和通过MOTA和MOTP对召回曲线的积分计算AMOTP。根据KITTI对象检测基准,我们使用11点插值方法来近似积分。我们希望我们提出的AMOTA度量方法能够总结所有阈值的运动回忆曲线,因此更加鲁棒,可以作为将来对MOT系统进行排名的度量方法。

5实验
5.1设定
数据集
我们根据KITTI MOT基准进行评估,该基准由21个培训和29个测试视频序列组成。 对于每个序列,都提供了LiDAR点云,RGB图像以及校准文件。 用于培训和测试的帧数为8008和11095。对于测试拆分,KITTI不向用户提供任何注释,而是在服务器上保留注释以进行2D MOT评估。 对于训练分割,带注释的对象和轨迹的数量分别为30601和636,包括汽车,行人,骑自行车的人等。由于我们的跟踪系统不需要训练,因此我们使用所有21个训练序列进行验证。 另外,在这项工作中,我们仅评估汽车子集,该子集在所有对象类型中具有最多的实例数。
评估指标
除了建议的指标AMOTA和AMOTP,我们还评估了常规MOT指标,以便与包括MOTA在内的现有MOT系统进行比较MOTA(多目标跟踪精度,accuracy),MOTP(多目标跟踪精度,precision),MT(大多数跟踪的轨迹),ML(主要丢失的轨迹数),IDS(身份开关的数量),FRAG(被误报打断的轨迹碎片数),FPS(每秒帧),FP(假阳性数)和FN(假阴性数)。
基线
对于3D MOT,由于采用了诸如FANTrack [21],DSM [22]等最先进的方法,FaF [1]和Complexer-YOLO [26]尚未发布代码,我们选择重现两个代表性3D MOT系统的结果:FANTrack [21](KITTI上最精确的3D MOT系统)和Complexer-YOLO [ 26](KITTI上最快的3D MOT系统)进行比较。
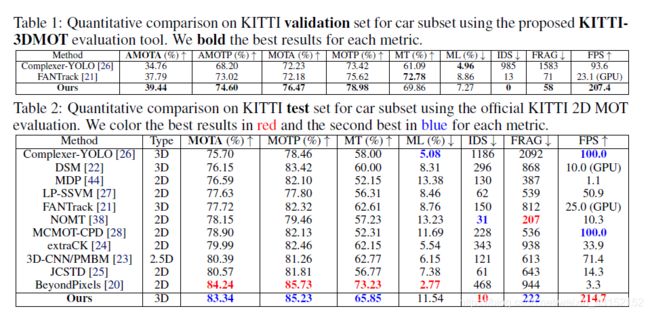
对于2D MOT,我们将与KITTI数据集上的八个最佳执行方法进行比较,包括BeyondPixels [20], JCSTD [25], 3D-CNN/PMBM [23], extraCK [24], MCMOT-CPD [28],NOMT [38], LP-SSVM[27]和MDP[44]。
实现细节
对于表1、2和3中所示的最终系统,我们使用(PointRCNN)在KITTI 3D对象检测基准的训练集上进行预训练的作为我们的3D对象检测模块,(x,y,z,l, w,h,vx,vy,vz)作为状态空间,不包括角速度v,数据关联模块中的IoUmin = 0.1,出生和死亡记忆模块中的Fmin = 3,Agemin = 2。
5.2 实验结果
KITTI-3DMOT基准测试的定量比较
我们在表1中总结了最先进的3D MOT系统和我们提出的系统的结果。使用提出的KITTI-3DMOT评估工具对结果进行了评估。 由于KITTI数据集没给出测试集的注释,因此,在使用建议的KITTI-3DMOT评估工具时,我们只能在验证集上进行评估。 我们的3D MOT系统始终优于其他系统(MT和ML指标仅次于我们),在KITTI 3D MOT上建立了最新的性能,并将3D MOTA从现有技术的72:23提高到76:47。 此外,我们实现了令人印象深刻的零身份切换(?)。 此外,我们的系统比其他3D MOT系统更快,并且不需要任何GPU。 我们注意到,尽管[21]的3D MOTA略差于[26],[21]具有比[26]高得多的3D AMOTA,这表明[21]在所有阈值上的整体性能要比[26]高得多。
KITTI-2DMOT基准测试的定量比较
除了使用建议的KITTI-3DMOT评估工具评估我们的3D MOT系统外,我们还可以将3D MOT系统的3D轨迹输出投影到2D图像平面上,并在测试集上报告2D MOT结果。
由于KITTI数据集不会释放测试集的注释,因此我们无法在测试集上计算建议的AMOTA和AMOTP度量的结果。 因此,只有常规MOT指标如表2所示。令人惊讶的是,在KITTI数据集上所有现有的MOT系统中,我们排在第2位,仅落后于最新的2D MOT系统BeyondPixels [20],距离MOTA为0:9。 同样,我们的3D MOT系统以214:7 FPS的速度运行,比BeyondPixels [65]快65倍。 与其他实时MOT系统进行比较时,例如MCMOTCPD[28],LP-SSVM [27],Complexer-YOLO [26]和3D-CNN/PMBM [23],我们的系统速度至少快一倍,并且精度更高。
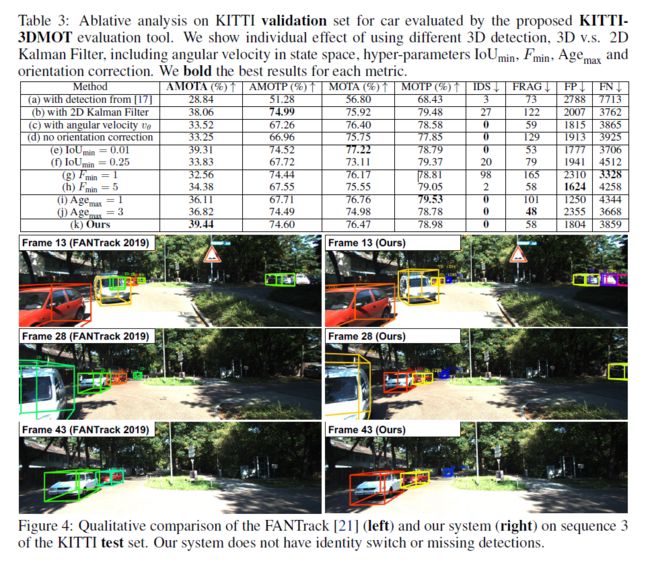
定性比较
我们可视化我们的系统和以前最先进的3D结果MOT系统FANTrack [21]以图4中的KITTI测试集的一个示例序列为例。我们可以看到,FANTrack的结果(左)包含一些标识切换(即颜色变化),而在我们的系统中缺少对远处物体的检测 (正确)没有这些问题。 在补充材料的视频演示中,我们在更多序列上进行了详细的定性比较,并表明(1)我们的系统不需要训练,而不会出现过度拟合的问题,而基于深度学习的方法FANTrack [21 ]显然在多个测试序列上过拟合,并且
(2)与FANTrack [21]相比,我们的系统具有更少的身份切换,盒子抖动和闪烁。
视频演示
5.3 切除实验(=对比实验,选取最优方法)
三维检测质量的效果
在表3 (a)中,我们将3D检测模块切换为Mono3D_PLiDAR,而不是在(k)中使用PointRCNN。区别在于PointRCNN需要激光雷达点云,Mono3D_PLiDAR只需要单一的图像。因此,PointRCNN提供了更高的三维检测质量。我们可以看到,(k)中的跟踪性能在所有指标上都明显优于(a),这意味着3D MOT系统的检测质量至关重要。
3D VS 2D 卡尔曼滤波器
在表3中,我们用2D卡尔曼滤波器(b)替换了建议系统(k)中的3D卡尔曼滤波器,即通过在2D空间中关联3D检测盒来产生3D轨迹输出。 具体来说,我们定义轨迹的状态空间T =(x; y; s; r; vx; vy; vs),其中(x,y)是对象的2D位置,s是2D框区域,r是长宽比和(vx,vy,vs)是2D图像平面中的速度。 在表3(b)(k)中,我们观察到在(k)将IDS从27减少到0,将FRAG从122减少到58,这是因为3D空间中与深度信息的关联可以帮助解决2D空间中存在的深度歧义。 总体而言,AMOTA从(b)中的38.06改进为(k)中的39.44。
在状态空间中包括角速度Vθ的效果
我们在状态空间中再加上一个变量v,以使轨迹c的状态空间T =(x; y; z;; l; w; h; vx; vy; vz; v)。 在表3中,我们观察到,与(k)相比,在(c)中添加v导致AMOTP和AMOTP显着下降。 我们了解这可能违反直觉。 但是我们发现,大多数汽车实例在KITTI数据集中都没有角速度,即它们是静态的或直线运动的。 结果,增加角速度实际上会引入不必要的噪声。
方向校正的效果
如第3.4节所述,我们在最终模型中使用了方向校正,如表3(k)所示。在这里,我们在不使用表3(d)中的方向校正的情况下进行了实验。 我们观察到方向校正有助于改善 在所有指标上的性能,表明此技巧应应用于将来的所有3DMOT系统。
阈值IoUmin对数据关联的影响
在表3中,我们改变IoUmin = 0.1 (k) ,IoUmin = 0.01 (e)和IoUmin = 25 (f),我们观察到减少IoUmin 0.01稍微增加了MOTA,(k)从76.47到77.22 (e)。然而,(e)和(f)在AMOTA和AMOTP方面的表现都比(k)差。
最小帧Fmin对新轨迹的影响
我们将Fmin=3 (k)调整为Fmin=1 (g), Fmin=5 (h),结果如表3所示。我们可以看到Fmin=1(即,为未匹配的检测立即创建一个新的轨迹)或Fmin=5(即,在接下来的五帧中,不断检测到未匹配的检测后,产生新的轨迹),导致AMOTA和AMOTP的性能较差,说明Fmin=3是合适的。
Agemax对丢失轨迹的影响
我们验证的效果hyper-parameter Agemax通过减少Agemax = 1 (i)和增加Agemax = 3 (j)。我们证明(i)和(j)下降导致AMOTA AMOTP。Agemax = 2(即保持跟踪无与伦比的轨迹Tunmatch后两帧)在我们最后的模型(k)是最好的选择。
6 结论
在本文中,我们为在线3D MOT提出了一种准确,简单且实时的基线系统。此外,还提出了一种新的评估工具以及新的度量标准AMOTA和AMOTP 3D MOT评估。 通过在KITTI数据集上进行的广泛实验,我们的系统在3D MOT上建立了最新的性能。 同样,我们以最快的速度将KITTI 2D MOT官方排行榜列在所有已发表作品的官方排行榜上,这表明简单准确的3D MOT可以在2D中产生非常好的效果。 我们希望我们的系统将作为一个简单而坚实的基准,其他人可以轻松地以此为基础来推进3D MOT的最新发展。