组原4_指令偏移寻址
目录
1. 基址寻址 EA = (BR) + A
2. 变址寻址 EA = (IX) + A
3. 相对寻址 EA = (PC) + A
4. 例题
5. 小结
6. 附加 堆栈寻址
1. 基址寻址 EA = (BR) + A
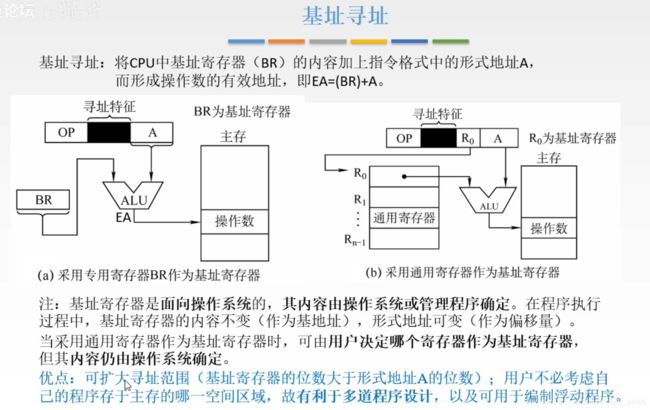
基址寄存器可以是 专用寄存器 和 通用寄存器
区别:
使用专用寄存器的时候,不需要在指令中指出寄存器编号,而是将编号隐含的放在操作码中;只要进行基址寻址这个操作,就自动去寻找相应的专用寄存器;
使用通用寄存器的时候,因为通用寄存器除了要进行基址寻址任务外,还有很多其它任务。所以当某条指令用到它的时候需要给出它的一个编号,编号就填写到指令字的一个字段中。
基址寄存器是面向操作系统的,意思是 其内容只能由操作系统来修改,或者专门设置一个管理程序来修改。
在程序执行过程中,这个内容是不改的(基地址)。通过调整形式地址(偏移量)定位到程序中的不同指令。
使用通用寄存器作为基址寄存器时,用户可以决定由哪个寄存器作为基址寄存器,但是寄存器的内容仍由操作系统确定
这样做的优势是:有利于多道程序设计。(独特优点)
扩大寻址范围的原理是:基址寄存器的位数大于 形式地址A 的位数。(这个是偏移寻址的一个公共优点,后面不赘述。)
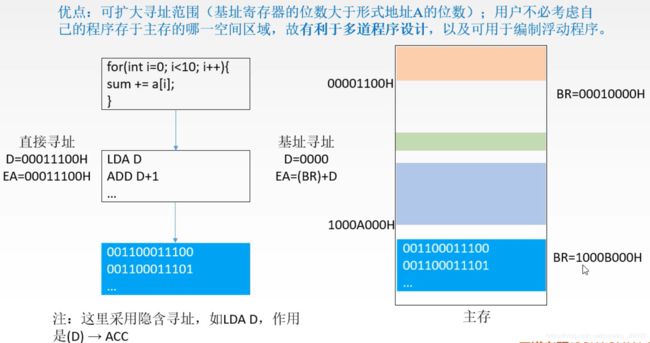
LDA 是数据传送类指令 (从一个地方到另一个地方)
LDA D 这条机器指令只有一个地址,说明隐含了一个地址,隐含的地址就是ACC (LDA中的 A含义)
该指令作用:(D) —> ACC
ADD D+1 同样是隐含寻址,只给了其中一个操作数地址,另一个隐含在 ACC 中,即 ACC 中的内容和 D+1 当中的内容做加法最后再存回 ACC 中。
==> 实际上,就是完成了 a[0] + a[1] 运算。
蓝色的块放到右侧主存中,要存放的一部分是指令的机器码,一部分是数组对应的每一个元素要放到一串连续的位置中。
如果采用的是直接寻址, D 填的应该是主存中的一个实际位置。
在设计的时候,写的是一个伪代码,暂时不知道 D 应该填多少,代码放入主存后,可以通过查主存代码位置 确认 D 的内容。对应的,后面有 D 的地方也填入该地址,这就是直接寻址需要去做的一件事。
如果要将程序换个位置执行,则需要将 D 的内容改为新的位置,如果程序较多,则意味着要不断查主存状态再去填 D 的内容。
这就是为什么要基址寻址,把我们从繁杂的工作中解放出来。基址寻址的 有利于多道程序设计,表达的是 将程序放在不同的位置后,只需要修改一下基址寄存器即可(该过程由操作系统完成),就能把数据之间的那些地址自动映射过去。
2. 变址寻址 EA = (IX) + A
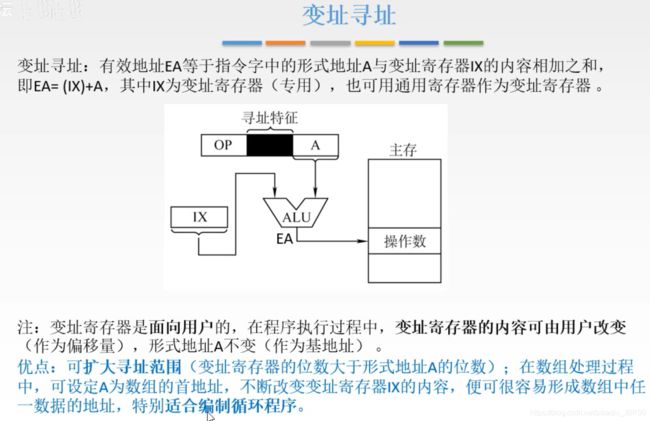
变址寄存器的内容可变,并不只是赋值,而是还提供一些自增或者自减的功能,这一功能在循环程序中用的很多。
基址寻址的特点更多的是,整个程序在内存中的浮动,变址寄存器就开始涉及到程序实现的细节。

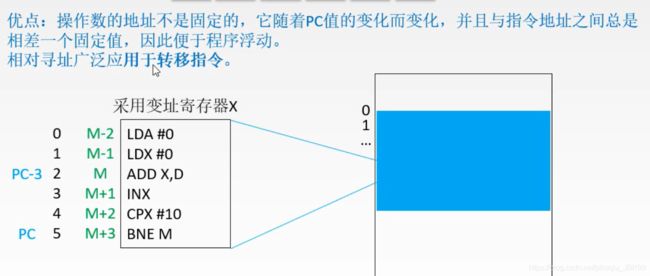
LDA #0 // 把0 存放到 ACC 中 #代表立即寻址 (形式地址就是操作数)
LDX #0 // 把0 存放到变址寄存器中
//上面两个都是隐含了一个操作数的指令
ADD X,D
// 看起来是两个操作数,实际还是隐含寻址。
这个 ADD 使用的是变址寻址,所以需要先计算操作数的地址,变址寄存器当中的内容即(X),再加上形式地址 D,得到操作数的地址,这个地址中的内容 即((X) + D) ,才是操作数。
这个操作数和 ACC 中的操作数做一个加法 ((ACC) + ((X) + D))得到结果存回 ACC 中 。
D 是这个数组的首地址 (a[0]地址),变址寄存器存放的是 0 ,所以 ((X) + D) ==> a[0] ,
又 ACC 起始存放 0 所以((ACC) + ((X) + D))= a[0] ; 也就是将 a[0] 放到 ACC 中。
INX ==> IN 表示增加,执行这条机器指令就是将 X+1;
// 这两句主要实现循环的作用。
CPX #10
BNE M // 条件跳转指令
在需要处理的元素数量增加时,需要修改的只是 CPX #10 机器语言中的10,整个指令语句数量是没有变的。
这也是为什么变址寻址适合编制循环程序,并且还特别适合处理数组,因为数组元素是连续存放的。如果不连续,没办法通过加一减一操作来定位到新的元素。

3. 相对寻址 EA = (PC) + A
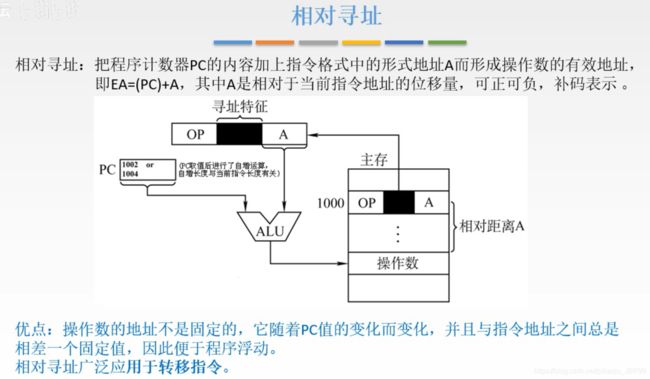
基址寻址更关注的是某一个程序应该放到主存中的哪一块,并且放到不同块的时候,程序可以正常运行的,
而相对寻址的浮动强调的是能够 用于转移指令。
(可以理解为 一个是全局的浮动,一个是内部的浮动)
4. 例题
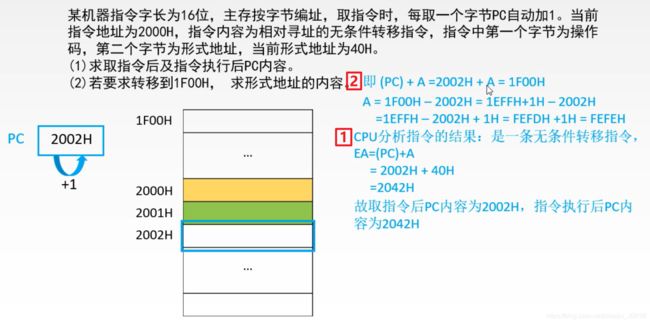
指令长度是存储字长的两倍,所以需要访存两次才取完指令。
每次取完 PC 都会加1,所以取完指令 PC 会定位到下一个内存地址。
5. 小结
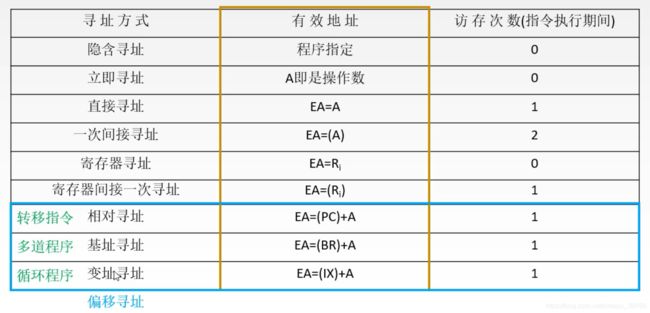
要清楚每一种寻址方式如何生存有效地址,如何定位到这条指令的操作数。
这里的访存次数是指指令执行期间的访存次数。
后面三种是偏移寻址,其基本形式是一样的。特点在于使用不同的寄存器的一些设定,不同的设定有各自的优势。
6. 附加 堆栈寻址
堆栈寻址并不是特别重要,更多是为了知识结构的完整性。
堆栈寻址可以将所有操作数都隐含表示。
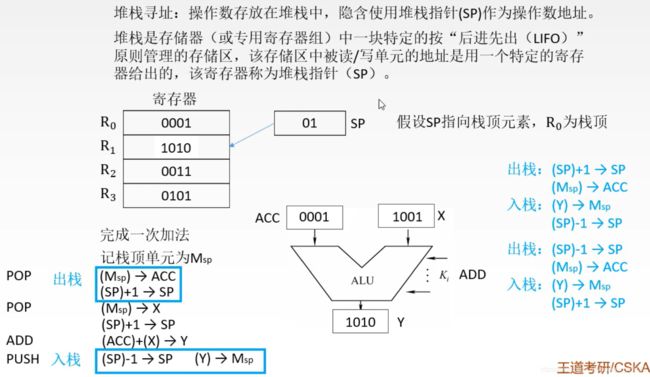
入栈和出栈操作要会写. ( X是操作数寄存器 )
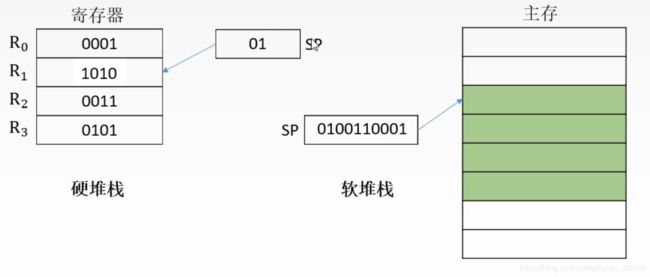
实际上这个堆栈只要用一堆具有存储功能的单元就能完成,所以也可以用存储器划分出一段专门的区域来做堆栈。一般来说,由于寄存器比较贵,更多的时候使用存储器来实现堆栈。
寄存器实现的堆栈叫做硬堆栈,从主存划分一块区域实现的堆栈叫做软堆栈。两者都需要有一个寄存器来存放堆栈指针。