LLVM学习笔记(48)
4. 指令选择
4.1. 总述
4.1.1. LLVM IR语法
这部分内容翻译自《Getting Started with LLVM Core Libraries》一书的第5章第3小节,部分删节。
观察Clang编译sum.c文件
int sum(int a, int b) {
return a+b;
}
得到的LLVM IR汇编文件,sum.ll:
target datalayout = "e-p:64:64:64-i1:8:8-i8:8:8-i16:16:16- i32:32:32-i64:64:64-f32:32:32-f64:64:64-v64:64:64-v128:128:128- a0:0:64-s0:64:64-f80:128:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx10.7.0"
define i32 @sum(i32 %a, i32 %b) #0 {
entry:
%a.addr = alloca i32, align 4
%b.addr = alloca i32, align 4
store i32 %a, i32* %a.addr, align 4
store i32 %b, i32* %b.addr, align 4
%0 = load i32* %a.addr, align 4
%1 = load i32* %b.addr, align 4
%add = add nsw i32 %0, %1
ret i32 %add
}
attributes #0 = { nounwind ssp uwtable ... }
整个LLVM文件的内容,不管是汇编还是字节码,都称为定义了一个LLVM模块。模块是LLVM IR的顶层数据结构。每个模块包含一组函数,函数含有一组包含一组指令的基本块。模块还包含支持这个模块的外围实体,比如全局变量,目标机器数据布局,外部函数原型以及数据结构声明。
LLVM局部变量类似于汇编语言中的寄存器,可以有任何以%符号开头的名字。因此,%add = add nsw i32 %0, %1将局部值%0加到%1上,将结果放入新的局部值,%add。你可以给值给任何名字,但如果你没什么创造力,你可以只是使用数字。在这个简短的例子里,我们可以看到LLVM如何表示其基本属性:
- 它使用静态单赋值(Static Single Assignment, SSA)形式。注意没有值被重新赋值;每个值仅有一次赋值。一个值的每次使用可以追踪到负责定义它的唯一指令。归功于SSA形式创建的、微不足道的use-def链,即,一组到一个使用者的定义,这对简化优化具有巨大的价值。如果LLVM没有使用SSA形式,我们将需要运行一个经典优化,比如常量传播及公共子表达式消除,必须的、单独的数据流分析来计算use-def链。
- 代码被组织为3地址指令。数据处理指令有两个源操作数,结果放在单独的目标操作数中。
- 有数目无限的寄存器。注意LLVM局部值如何可以是任意以%符号开头的名字,包括从0开始的数字,比如%0,%1,以此类推,没有最大数目的限制。
Target datalayout结构包含由target host描述的target triple的大小端及类型大小信息。某些优化依赖于知道目标机器的数据布局来正确地转换代码。观如何完成察布局声明:
target datalayout = "e-p:64:64:64-i1:8:8-i8:8:8-i16:16:16- i32:32:32-i64:64:64-f32:32:32-f64:64:64-v64:64:64-v128:128:128- a0:0:64-s0:64:64-f80:128:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx10.7.0"
从这个字符串我们可以获取以下事实:
- 目标机器是一个使用macOX 10.7.0的x86_64处理器。它是一个小端目标机器,这由布局的第一个字母表示(小写e)。大端目标机器需要使用一个大写E。
- 关于类型的信息由格式type:
: : 提供。在前面的例子里,p:64:64:64表示指针是64比特大小,abi及preferred对齐设置为到64位边界。ABI对齐指定了一个类型的最小对齐要求,而preferred对齐指出一个可能更大的值,如果这是有好处的。32位整数类型i32:32:32大小是32比特,32位abi与preferred对齐,等等。
函数声明很像C语法:
define i32 @sum(i32 %a, i32 %b) #0 {
这个函数返回一个类型i32的值,有两个i32实参%a与%b。局部标识符总是需要前缀%,而全局标识符使用@。LLVM支持大量的类型,但最重要是以下这些:
- iN形式的任意大小整数;常见的例子有i32,i64及i128。
- 浮点类型,比如32位单精度float及64位双精度double。
- 格式为<<#elements>> x <
>的向量类型。一个带有四个i32元素的向量被写作<4 x i32>。
在函数声明中的#0标记映射到一组函数属性,也非常类似于C/C++函数及方法中使用的。属性集定义在文件的末尾:
attributes #0 = { nounwind ssp uwtable "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf"="true" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "unsafe-fp-math"="false" "use-soft-float"="false" }
例如,nounwind标记一个函数或方法不会抛出异常,而ssp告诉代码生成器使用一个栈毁坏保护器(stack smash protector),以增强这段代码抵御攻击的安全性。
函数被显式分为基本块(BB),并使用一个标记来开始一个新BB。与值标识符与一条指令关联的方式相同,标记与基本块关联。如果一个标记声明被忽略,LLVM汇编器自动地生成使用自己命名方案的标记。基本块是在第一条指令有单个入口点,在最后一条指令有单个出口的指令序列。这样,当指令跳转到对应一个基本块的标记时,我们知道它将执行这个基本块中的所有指令,直到最后一条将跳转到另一个基本块的指令。基本块与它们关联的标记需要符合以下条件:
- 每个BB需要以一条终结者指令结尾,它跳转到其他BB或从函数返回
- 第一个BB,称为入口BB,在一个LLVM函数里是特殊的,不能是任何分支指令的目标
我们的LLVM文件,sum.ll,只有一个BB,因为它没有跳转,循环或调用。函数以entry标记开始,以返回指令ret终止:
entry:
%a.addr = alloca i32, align 4
%b.addr = alloca i32, align 4
store i32 %a, i32* %a.addr, align 4
store i32 %b, i32* %b.addr, align 4
%0 = load i32* %a.addr, align 4
%1 = load i32* %b.addr, align 4
%add = add nsw i32 %0, %1
ret i32 %add
alloca指令在当前函数的栈帧上保留空间。空间大小由元素类型大小确定,它遵循指定的对齐。第一条指令,%a.addr = alloca i32, align 4,分配一个4字节栈元素,它遵守一个4字节对齐。指向这个栈元素的一个指针被保存在局部标识符%a.addr中。Alloca指令常用于表示局部(自动)变量。
实参%a与%b通过store指令保存在栈位置%a.addr与%b.addr。通过load指令值从相同的内存位置读回来,它们用在加法%add = add nsw i32 %0, %1里。最后,加法的结果,%add,由函数返回。标记nsw指出这个加法操作没有有符号回绕(no signed wrap),这表示指令已知没有溢出,允许某些优化。如果你对nsw标记背后的历史感兴趣,Dan Gohman在http://lists.cs.uiuc.edu/pepermail/llvmdev/2011-December/045924.html的文章值得一读。
事实上,load与store指令是重复的,函数实参可以直接用在add指令中。默认的,Clang使用-O0(没有优化),没有删除不必要的读与写。如果我们以-O1编译,输出的是简单得多的代码:
define i32 @sum(i32 %a, i32 %b) ... {
entry:
%add = add nsw i32 %b, %a
ret i32 %add
}
...
4.1.1.1. LLVM IR内存中模型
内存中表示与我们刚展示的LLVM语法十分相似。代表IR的C++类的头文件位于include/llvm/IR。以下是最重要类的列表:
- 类Module聚集了整个编译单元中使用的所有数据,它是LLVM术语里module的同义词。它将Module::iterator typedef为遍历这个模块中函数的一个便利的方法。你可以通过begin()与end()方法获取这些迭代器。在http://llvm.org/docs/doxygen/html/classllvm_1_1Module.html可看到完整接口。
- 类Function包含与一个函数定义或声明相关的所有对象。在声明(使用isDeclaration方法检查是否为一个声明)的情形里,它仅包含函数原型。在这两个情形中,它包含一组可通过getArgumentList()或一组arg_begin()及arg_end()访问的函数参数列表。可以使用Function:: arg_iterator typedef来遍历之。如果Function对象代表一个函数定义,并且通过习惯语法for (Function::iterator i = function.begin(), e = function.end(); i != e; ++i)遍历其内容,遍历将跨过基本块。在http://llvm.org/docs/doxygen/html/classllvm_1_1Function.html可看到完整接口。
- 类BasicBlock封装了一组LLVM指令,通过begin()/end()习惯语法访问。可以使用方法getTerminator()直接访问最后的指令,还有几个辅助方法用于穿越CFG,比如当基本块有一个前驱时,通过getSinglePredecessor()访问基本块的前驱。不过,如果它没有一个前驱时,需要你自己找出前驱列表,通过遍历基本块,检查它们终结指令的目标,这不难办到。在http://llvm.org/docs/doxygen/html/classllvm_1_1BasicBlock.html可看到完整接口。
- 类Instruction代表LLVM IR里的一个原子计算、一条指令。它有一些访问高级谓词的方法,比如isAssociative(),isCommutative(),isIdempotent()或isTerminator(),但其实际功能可以getOpCode()获取,该方法返回llvm::Instruction枚举的一个成员,代表这个LLVM IR的操作码。可以通过op_begin()及op_end()方法组访问其操作数。在http://llvm.org/docs/doxygen/html/classllvm_1_1Instruction.html可看到完整接口。
我们还没展示LLVM IR最强有力的方面(由SSA形式激活):Value与User接口;它们使得你很容易行进在use-def及def-use链中。在LLVM内存里IR中,一个从Value派生的类表示它定义了一个其他对象可以使用的结果,而User派生类表示这个实体使用一个或多个Value接口。Function与Instruction都是Value与User的派生类,而BasicBlock只是Value的派生类。为了理解这,让我们深入分析这两个类:
- 类Value定义了方法use_begin()与use_end()使你能够遍历User,提供了一个容易的方法来访问其def-use链。对每个Value类,你还可以通过getName()方法访问其名字。这模拟了任何LLVM值都可以有一个单独的相关标识符这个事实。例如,%add1可以标识一个add指令的结果,BB1可以标识一个基本块,而myfunc可以标识一个函数。Value也有一个强大的,称为replaceAllUsesWith (Value*)的方法,它遍历这个值所有的使用者,以其他某个值替换它。这是一个SSA形式如何使你容易地替换指令并编写快速优化的良好例子。在http://llvm.org/docs/doxygen/html/classllvm_1_1Value.html可看到完整接口。
- 类User有让你快速访问所有它使用的Value接口的op_begin()与op_end()方法。注意这代表use-def链。你还可以使用称为replaceUsesofWith (Value *From, Value *To)的辅助方法来替换它使用的值。在http://llvm.org/docs/doxygen/html/classllvm_1_1User.html可看到完整的接口。
4.1.2. 理解指令选择阶段
这部分内容翻译自《Getting Started with LLVM Core Libraries》的第6章,第3小节,部分删节。
指令选择是将LLVM IR转换为表示目标指令的SelectionDAG节点(SDNode)的过程。首先是从LLVM IR指令构建出节点带有IR操作的SelectionDAG对象。其次,这些节点经过降级、DAG合并,以及合法化阶段,使其更容易与目标指令进行匹配。然后指令选择使用节点模式匹配执行一个DAG到DAG的转换,把SelectionDAG节点转换为表示目标机器指令的节点。
【注:指令选择遍是后端所采用遍中开销最高者。SPEC CPU2006基准测试函数的一个编译研究发现,平均来说,在LLVM 3.0里,以llc –O2生成x86代码,指令选择遍单独使用了将近一半的时间。如果你对-O2目标机器相关及目标机器无关遍的平均耗费时间感兴趣,在http://www.ic.unicamp.br/~reltech/2013/13-13.pdf,你可以在LLVM JIT编译代价分析报告的附录中查找。】
4.1.2.1. 类SelectionDAG
类SelectionDAG采用DAG来表示每个基本块的运算,其中每个SDNode对应一条指令或操作数。下图由LLVM生成,展示了sum.bc的DAG,它仅有一个函数,即一个基本块:
这个DAG的边以使用-定义关系在多个操作中维护次序。如果节点B(比如add)有一条外出边到节点A(比如Constant<-10>),表示节点A定义了一个节点B使用的(作为加法的一个操作数)值(32位整数-10)。这样,A的操作必须在B之前执行。黑色箭头代表一个展示了数据流依赖的规范边,就像我们的add例子。蓝色虚线箭头代表非数据流链,它们用于维护不相关指令间的次序,例如,如果load与store指令访问相同的内存地址,它们必须遵循原来在程序中的顺序。在上面的图中,我们知道由于一条蓝色虚线边,CopyToReg操作一定在X86ISD::RET_FLAG之前执行。红色的边则保证其相邻的节点一定粘在一起,这意味着它们一定被连续发布,中间没有其他指令。例如,我们知道因为一条红色边,节点CopyToReg与X86ISD::RET_FLAG一定一起调度。
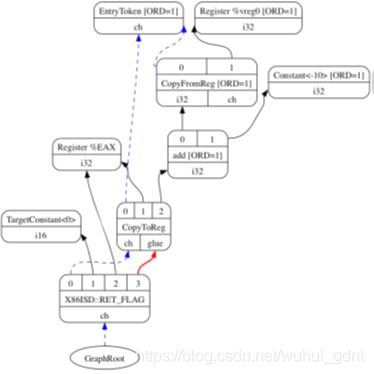
依赖于与其使用者的关系,每个节点可以支持不同类型的值。一个值不一定是具体的,可以是一个抽象符号。它可以具有下述的任意类型:
- 节点提供的值可以是一个表示整数,浮点,向量或指针的具体值类型。一个从其操作数计算出新值的数据处理节点的结果就是这个类别的一个例子。类型可以是i32,i64,f32,v2f32(带有两个元素的向量),以及iPTR等等。在其他节点使用这个值时,这个生产者-消费者关系在LLVM图里显示为正常的黑色边。
- 类型Other是一个用于表示chain值(图中的ch)的抽象节点。在另一个节点使用一个Other类型值时,连接两者的边在LLVM图中显示为蓝色虚线。
- 类型Glue表示黏结。在另一个节点使用一个Glue类型值时,连接两者的边在LLVM图中显示为红色。
SelectionDAG对象有一个特殊的EntryToken来标识基本块的入口,它提供了一个Other类型值以允许被串接的节点得以通过使用这个节点来开始。SelectionDAG对象还有对紧跟着最后一条指令的图形根节点的一个引用,这个关系也被编造为类型Other值的一个链。
在这个阶段,作为初始步骤尝试的一个结果,比如降级与合法化——它们负责为指令选择准备DAG,目标机器无关与目标机器相关的节点共存。在指令选择的最后,所有被目标机器指令匹配的节点将是目标机器相关的。在上图中,我们具有如下目标机器无关节点:CopyToReg,CopyFromReg,Register(%verg0),add及Constant。另外,我们有如下已经被预处理且目标机器相关的节点(虽然在指令选择后它们仍然可以改变):TargetConstant,Register(%EAX)及X68ISD:: RET_FLAG。
从图中的例子我们还可以观察到以下语义:
- Register:这个节点可以援引虚拟或物理(目标机器特定)寄存器。
- CopyFromReg:这个节点拷贝一个定义在当前基本块作用域外的寄存器,允许我们在当前上下文使用它——在我们的例子里,它拷贝一个函数实参。
- CopyToReg:这个节点将一个值拷贝到一个特定的寄存器,但不提供其他节点使用的任何具体值。不过,这个节点产生一个chain值(类型Other)与其他不会生成一个具体值的节点串接起来。例如,要使用一个写入EAX的值,X86ISD::RET_FLAG节点使用Register(%EAX)节点的i32类型,通过由CopyToReg产生的chain,保证%EAX被CopyToReg更新,因为chain强制CopyToReg在X86ISD::RET_FLAG之前调度。