Pytorch 图像分类(AlexNet,VGGNet,Inception,ResNet,DenseNet,MobileNet)
文章目录
-
-
- 前言
- 1. AlexNet
- 2. VGGNet
- 3. Inception
- 4. ResNet
- 5. DenseNet
- 6. MobileNet
-
前言
其实现阶段图像分类网络已经发展的很好了,本文只是简单的罗列一下经典的分类网络的基本思想,不涉及代码。其实在使用pytorch的基础上,里面的TORCHVISION.MODELS已经帮我们封装好了,直接使用就可以。
1. AlexNet
AlexNet是2012年ILSVRC 2012(ImageNet Large Scale Visual Recognition Challenge)竞赛的冠军网络,分类准确率由传统方法的 70%+提升到 80%+(当时传统方法已经进入瓶颈期,所以这么大的提升是非常厉害的)。它是由Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,深度学习开始迅速发展。

AlexNet 一些性质:
- 首次利用 GPU 进行网络加速训练。
- 使用了 ReLU 激活函数,而不是传统的 Sigmoid 激活函数以及 Tanh 激活函数。
- 使用了 LRN 局部响应归一化。
- 在全连接层的前两层中使用了 Dropout方法按一定比例随机失活神经元,以减少过拟合。
AlexNet GitHub
2. VGGNet
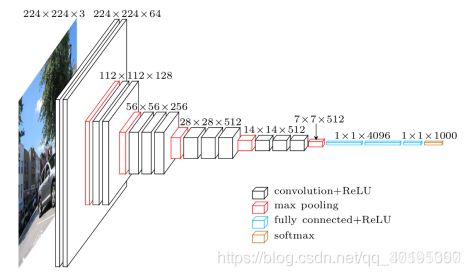
VGGNet由牛津大学计算机视觉组合和Google DeepMind公司研究员一起研发的深度卷积神经网络。它探索了卷积神经网络的深度和其性能之间的关系,通过反复的堆叠33的小型卷积核和22的最大池化层,成功的构建了16~19层深的卷积神经网络。VGGNet获得了ILSVRC 2014年比赛的亚军和定位项目的冠军,在top5上的错误率为7.5%。目前为止,VGGNet依然被用来提取图像的特征。在原论文中给出了一系列VGG模型的配置,下面这幅图是VGG16模型的结构简图。
VGGNet 一些性质:
- 通过堆叠多个3x3的卷积核来替代大尺度卷积核(在拥有相同感受野的前提下能够减少所需参数)。
- VGGNet作者总结出LRN层作用不大,越深的网络效果越好。
- 11的卷积也是很有效的,但是没有33的卷积效果好,因为3*3的网络可以学习到更大的空间特征。
VGGNet的网络结构如下图所示。VGGNet包含很多级别的网络,深度从11层到19层不等,比较常用的是VGGNet-16和VGGNet-19。VGGNet把网络分成了5段,每段都把多个3*3的卷积网络串联在一起,每段卷积后面接一个最大池化层,最后面是3个全连接层和一个softmax层。

VGGNet GitHub
3. Inception
Google InceptionNet出现在ILSVRC2014年的比赛中(和VGGNet同年),并以较大优势夺得了第一名的成绩,它的top5错误率为6.67%,VGGNet的错误率为7.3%。InceptionNet的最大特点是控制了计算量和参数量的同时提高了网络的性能,它的层数为22,比VGGNet19还深,但是只有15亿次浮点计算和500万的参数量。InceptionNet精心设计的Inception Module也很大程度上提高了参数的利用率。
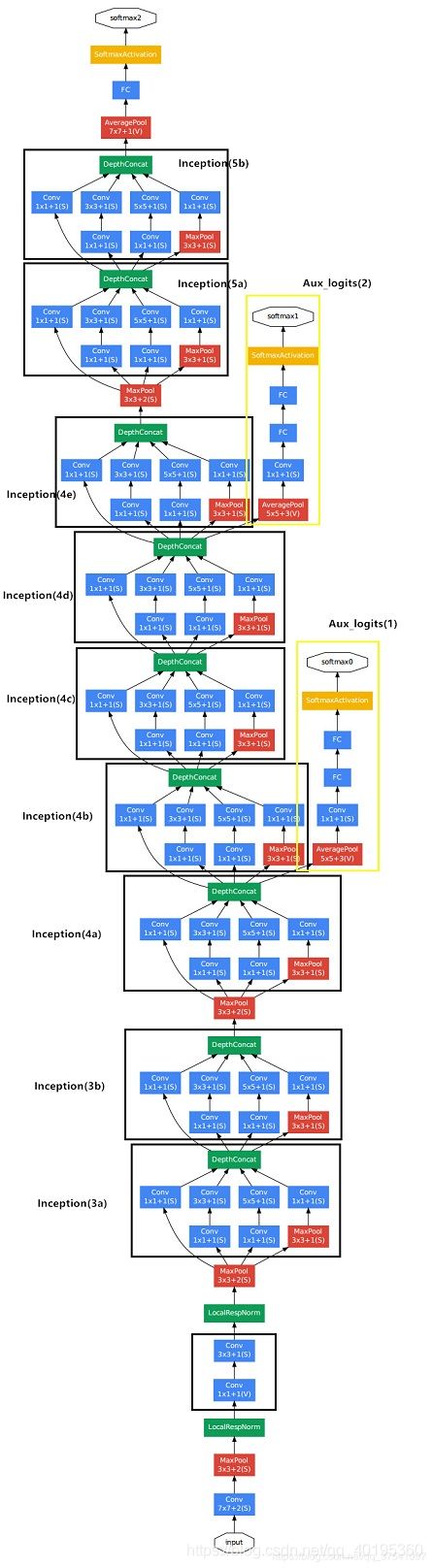
Inception V1:

Inception v1网络是一个精心设计的22层卷积网络,并提出了具有良好局部特征结构的Inception模块,即对特征并行地执行多个大小不同的卷积运算与池化,最后再拼接到一起。由于1×1、3×3和5×5的卷积运算对应不同的特征图区域,因此这样做的好处是可以得到更好的图像表征信息。
左图呢,是论文中提出的inception原始结构,右图是inception加上降维功能的结构,这种1×1的模块可以先将特征图降维,再送给3×3和5×5大小的卷积核,由于通道数的降低,参数量也有了较大的减少(用1×1卷积核实现降维的思想)。
GoogleNet GitHub
Inception V2:
Inception v2进一步通过卷积分解与正则化实现更高效的计算,增加了BN层,同时利用两个级联的3×3卷积取代了Inception v1版本中的5×5卷积,如图3.15所示,这种方式既减少了卷积参数量,也增加了网络的非线性能力。
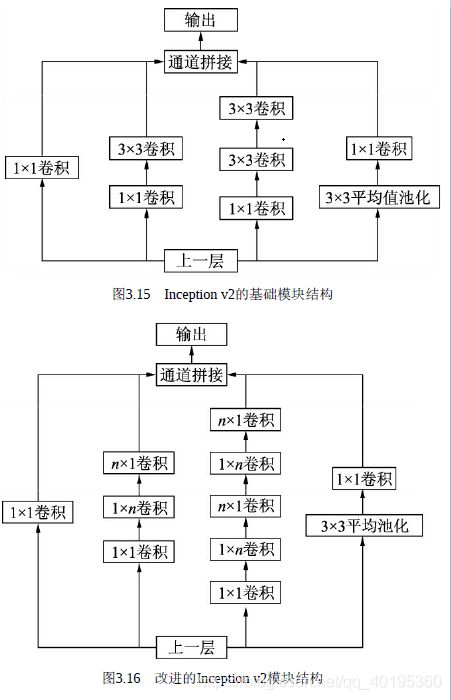
更进一步,Inception v2将n×n的卷积运算分解为1×n与n×1两个卷积,如图3.16所示,这种分解的方式可以使计算成本降低33%。
Inception V3:
Inception v3在Inception v2的基础上,使用了RMSProp优化器,在辅助的分类器部分增加了7×7的卷积,并且使用了标签平滑技术。
Inception V4:
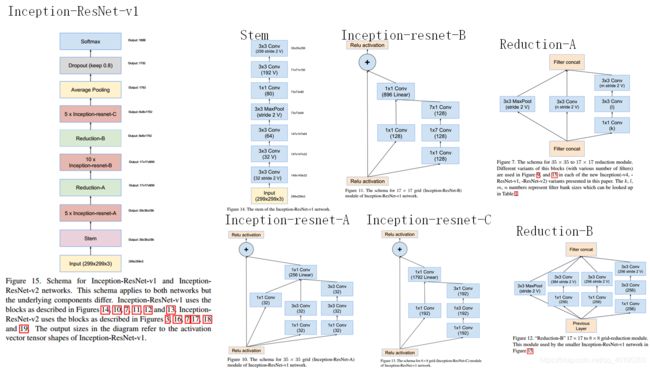
Inception v4则是将Inception的思想与残差网络进行了结合,显著提升了训练速度与模型准确率,这里对于模块细节不再展开讲述。至于残差网络这一里程碑式的结构,正是由下一节的网络ResNet引出的。
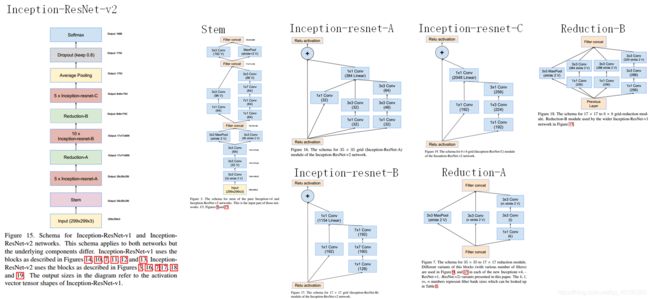
4. ResNet
ResNet(Residual Neural Network)由微软研究院的Kaiming He等四名华人提出,通过使用ResNet Unit成功训练出了152层的神经网络,并在ILSVRC2015比赛中取得冠军,在top5上的错误率为3.57%,同时参数量比VGGNet低,效果非常突出。ResNet的结构可以极快的加速神经网络的训练,模型的准确率也有比较大的提升。同时ResNet的推广性非常好,甚至可以直接用到InceptionNet网络中。
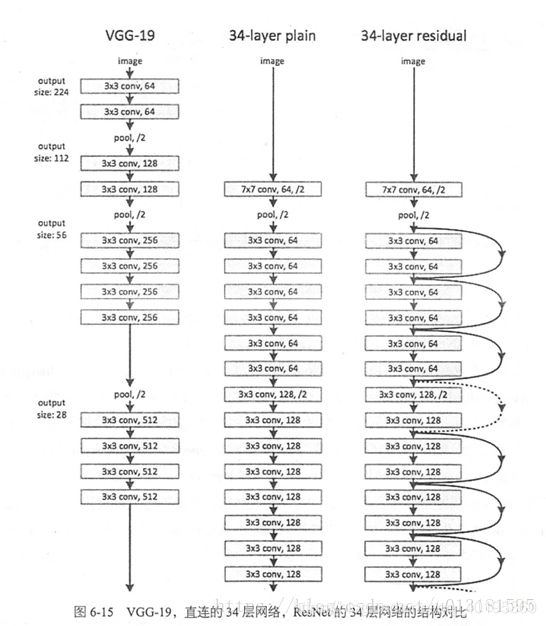
在ResNet网络结构中会用到两种残差模块,下图是论文中给出的两种残差结构。左边的残差结构是针对层数较少网络,例如ResNet18层和ResNet34层网络。右边是针对网络层数较多的网络,例如ResNet101,ResNet152等。为什么深层网络要使用右侧的残差结构呢。因为,右侧的残差结构能够减少网络参数与运算量。同样输入一个channel为256的特征矩阵,如果使用左侧的残差结构需要大约1170648个参数,但如果使用右侧的残差结构只需要69632个参数。明显搭建深层网络时,使用右侧的残差结构更合适。

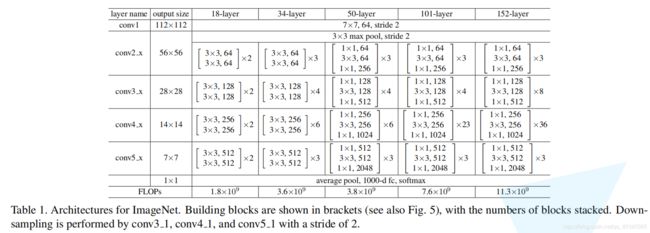
下面这幅图是原论文给出的不同深度的ResNet网络结构配置,注意表中的残差结构给出了主分支上卷积核的大小与卷积核个数,表中的xN表示将该残差结构重复N次。那到底哪些残差结构是虚线残差结构呢。
ResNet GitHub
5. DenseNet
前面ResNet通过前层与后层的“短路连接”(Shortcuts),加强了前后层之间的信息流通,在一定程度上缓解了梯度消失现象,从而可以将神经网络搭建得很深。更进一步,DenseNet最大化了这种前后层信息交流,通过建立前面所有层与后面层的密集连接,实现了特征在通道维度上的复用,使其可以在参数与计算量更少的情况下实现比ResNet更优的性能。
DenseNet的网络架构如下图所示,网络由多个Dense Block与中间的卷积池化组成,核心就在Dense Block中。Dense Block中的黑点代表一个卷积层,其中的多条黑线代表数据的流动,每一层的输入由前面的所有卷积层的输出组成。注意这里使用了通道拼接(Concatnate)操作,而非ResNet的逐元素相加操作。

具体的Block实现细节如下图所示,每一个Block由若干个Bottleneck的卷积层组成,对应上面图中的黑点。Bottleneck由BN、ReLU、1×1卷积、BN、ReLU、3×3卷积的顺序构成,也被称为DenseNet-B结构。其中1x1 Conv得到 4k 个特征图它起到的作用是降低特征数量,从而提升计算效率。

关于Block,有以下4个细节需要注意:
1.每一个Bottleneck输出的特征通道数是相同的,例如这里的32。同时可以看到,经过Concatnate操作后的通道数是按32的增长量增加的,因此这个32也被称为GrowthRate。
2.这里1×1卷积的作用是固定输出通道数,达到降维的作用。当几十个Bottleneck相连接时,Concatnate后的通道数会增加到上千,如果不增加1×1的卷积来降维,后续3×3卷积所需的参数量会急剧增加。1×1卷积的通道数通常是GrowthRate的4倍。
3.上图中的特征传递方式是直接将前面所有层的特征Concatnate后传到下一层,这种方式与具体代码实现的方式是一致的。
- Block采用了激活函数在前、卷积层在后的顺序,这与一般的网络上是不同的。
DenseNet的结构有如下两个特性:
- 神经网络一般需要使用池化等操作缩小特征图尺寸来提取语义特征,而Dense Block需要保持每一个Block内的特征图尺寸一致来直接进行Concatnate操作,因此DenseNet被分成了多个Block。Block的数量一般为4。
- 两个相邻的Dense Block之间的部分被称为Transition层,对于Transition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。具体包括BN、ReLU、1×1卷积(Conv)、2×2平均池化操作。1×1卷积的作用是降维,起到压缩模型的作用,而平均池化则是降低特征图的尺寸。
- Transition层可以起到压缩模型的作用。假定Transition的上接DenseBlock得到的特征图channels数为m ,Transition层可以产生θm个特征(通过卷积层),其中0 <θ≤1是压缩系数(compression rate)。当 θ=1时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,原论文中使用θ≤0.5 。对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。
对于ImageNet数据集,图片输入大小为224x224,网络结构采用包含4个DenseBlock的DenseNet-BC,其首先是一个stride=2的7x7卷积层,然后是一个stride=2的3x3 MaxPooling层,后面才进入DenseBlock。

6. MobileNet
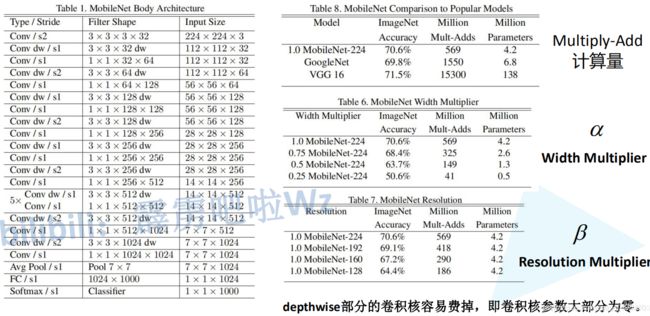
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)。要说MobileNet网络的优点,无疑是其中的Depthwise Convolution结构(大大减少运算量和参数数量)。
MobileNet v1
-
对标准卷积层进行改进Depth-Wise Conv 和 Point-Wise Conv
Depth-Wise Conv(简称dw),也称深度可分离卷积,它将卷积核的每个通道分别应用于输入特征图的每个通道(这样,输入和输出的通道数维持一致),而非如标准卷积般将输入特征图的所有通道加权组合在一起。
Point-Wise Conv(简称pw), 也称逐点卷积,它使用1x1大小的卷积核,用于组合深度可分离卷积的输出结果(将深度可分离卷积的输出通道数映射到目标通道数)。
标准卷积将提取空间特征和通道之间的相关性组合在一起,而MobileNet将其分解为Depth-Wise + Point-Wise,这样的效果是先基于各个通道提取空间特征(空间相关性),之后再组合通道之间的相关性,这种因式分解操作具有大幅度减少计算和模型大小的效果。 -
使用2个超参数(宽度乘数α,分辨率乘数β)构建更小的模型
宽度乘子α和分辨率乘子β,通过这两个超参,可以进一步缩减模型,文章中也给出了具体的试验结果。此时,我们反过来看,扩大宽度和分辨率,都能提高网络的准确率,但如果单一提升一个的话,准确率很快就会达到饱和,这就是2019年谷歌提出efficientnet的原因之一,动态提高深度、宽度、分辨率来提高网络的准确率。 -
网络结构
MobileNet v2
-
倒残差结构:Inverted Residual
在MobileNet v2中,由于使用了深度可分离卷积来逐通道计算,本身计算量就比较少,因此在此可以使用1×1卷积来升维,在计算量增加不大的基础上获取更好的效果,最后再用1×1卷积降维。这种结构中间宽两边窄,类似于柳叶,该结构也因此被称为Inverted Residual Block。

根据上图,对比下可以发现,两者都采用了 1×1 -> 3 ×3 -> 1 × 1 的卷积模式以及shortcut,不同点在于ResNet先使用pw降维,后使用pw升维,而MobileNetV2“反其道而行之”——先使用pw升维,后使用pw降维。 -
去掉ReLU6
深度可分离卷积得到的特征对应于低维空间,特征较少,如果后续接线性映射则能够保留大部分特征,而如果接非线性映射如ReLU,则会破坏特征,造成特征的损耗,从而使得模型效果变差。针对此问题,MobileNet v2直接去掉了每一个Block中最后的ReLU6层,减少了特征的损耗,获得了更好的检测效果。

-
网络结构

MobileNet v3
v1将标准卷积分解为dw+pw,同时使用2个超参进一步构建小模型和降低计算量;v2在v1基础上,在dw前加入 Expansion Layer 进行通道数的扩展,将dw后的pw接的ReLU6替换为线性激活层,并且引入了shortcut,最终形成 inverted-residual(倒残差) 这样的结构。MobileNet V3 发表于2019年,该v3版本结合了v1的深度可分离卷积、v2的Inverted Residuals和Linear Bottleneck、SE模块,利用NAS(神经结构搜索)来搜索网络的配置和参数。这种方式已经远远超过了人工调参了,太恐怖了。
-
新的非线性激活函数:h-swish
由于嵌入式设备计算sigmoid是会耗费相当大的计算资源的,因此作者提出了h-switch作为激活函数。且随着网络的加深,非线性激活函数的成本也会随之减少。所以,只有在较深的层使用h-switch才能获得更大的优势。
-
基于Squeeze & Excitation(SE)的轻量级注意力结构
在v2的block上引入SE模块,SE模块是一种轻量级的通道注意力模块。在depthwise之后,经过池化层,然后第一个fc层,通道数缩小4倍,再经过第二个fc层,通道数变换回去(扩大4倍),然后与depthwise进行按位相乘。通过实验证明,这样在减少时耗的同时也提高了精度,这是属于MobileNet的轻量级SE结构。

-
修改了部分v2的结构:头部卷积核的通道数及最后的尾部结构
作者发现,计算资源耗费最多的层是网络的输入和输出层,因此作者对这两部分进行了改进。如下图所示,上面是v2的最后输出几层,下面是v3的最后输出的几层。可以看出,v3版本将平均池化层提前了。在使用1×1卷积进行扩张后,就紧接池化层-激活函数,最后使用1×1的卷积进行输出。通过这一改变,能减少10ms的延迟,提高了15%的运算速度,且几乎没有任何精度损失。
其次,对于v2的输入层,通过3×3卷积将输入扩张成32维。作者发现使用ReLU或者switch激活函数,能将通道数缩减到16维,且准确率保持不变。这又能节省3ms的延时。 -
网络结构搜索:资源受限的NAS(Platform-Aware NAS)与 NetAdapt
资源受限的NAS,用于在计算和参数量受限的前提下搜索网络来优化各个块(block),所以称之为模块级搜索(Block-wise Search) 。NetAdapt,用于对各个模块确定之后网络层的微调每一层的卷积核数量,所以称之为层级搜索(Layer-wise Search)。一旦通过体系结构搜索找到模型,我们就会发现最后一些层以及一些早期层计算代价比较高昂。于是作者决定对这些架构进行一些修改,以减少这些慢层(slow layers)的延迟,同时保持准确性。这些修改显然超出了当前搜索的范围。 -
网络结构
最后,v3的结构如下图所示。作者提供了两个版本的v3,分别是large和small,对应于高资源和低资源的情况。两者都是使用NAS进行搜索出来的。
MobileNet v3 GitHub