目标检测综述(一)
目标检测综述
论文链接:https://arxiv.org/pdf/1905.05055v1.pdf
目标检测是计算机视觉中最重要也是最具挑战性的分支之一,它在人们的生活中得到了广泛的应用,如监控安全、自主驾驶等,目的是定位某一类语义对象的实例。随着用于检测任务的深度学习网络的快速发展,目标检测器的性能得到了极大的提高。为了深入了解目标检测管道的主要发展现状,本调查首先分析了现有典型检测模型的方法,并对基准数据集进行了描述。之后,我们主要系统地介绍了各种目标检测方法,包括一级和二级探测器。此外,我们列出了传统的和新的应用。分析了目标检测的一些代表性分支。最后,我们讨论了利用这些目标检测方法来建立一个有效和高效的系统的体系结构,并指出了一套发展趋势,以便更好地遵循最新的算法和进一步的研究。
introduction
近年来,目标检测因其广泛的应用和近年来的技术突破而受到越来越多的关注。这项任务正在学术界和现实世界的应用中进行广泛的研究,如监控安全、自动驾驶、交通监控、无人机场景分析和机器人视觉。在导致目标检测技术快速发展的诸多因素和努力中,值得注意的贡献应该归因于深度卷积神经网络和gpu计算能力的发展。目前,深度学习模型已广泛应用于计算机视觉的整个领域,包括通用目标检测和特定领域目标检测。大多数最先进的物体探测器利用深度学习网络作为骨干和检测网络分别从输入图像(或视频)、分类和定位提取特征。目标检测是一种与计算机视觉和图像处理相关的计算机技术,用于检测数字图像和视频中某一类语义对象(如人、建筑物或汽车)的实例。目标检测的研究领域包括多类检测、边缘检测、突出目标检测、姿态检测、场景文本检测、人脸检测、行人检测等。作为场景理解的重要组成部分,目标检测广泛应用于现代生活的各个领域,如安全领域、军事领域、交通领域、医疗领域和生活领域。此外,到目前为止,许多基准在目标检测领域发挥了重要作用,如Caltech [1], KITTI [2], ImageNet [3], PASCAL VOC [4], MS COCO [5], Open Images V5[6]。在2018年ECCV VisDrone竞赛中,主办方发布了一个基于无人机平台的新数据集[7],其中包含大量图像和视频。
• Two kinds of object detectors
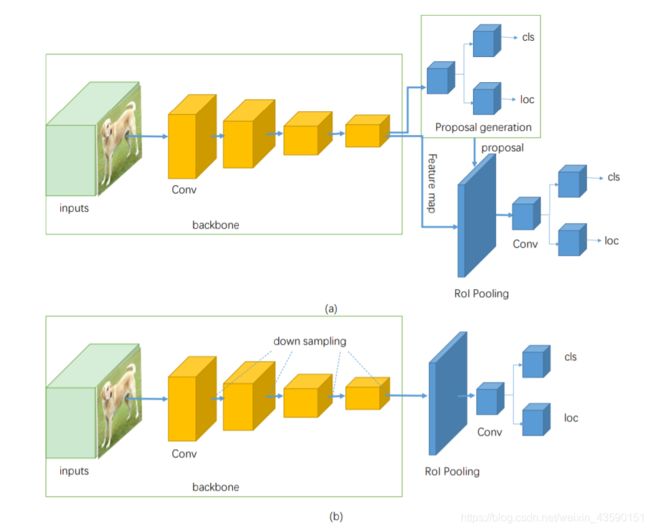
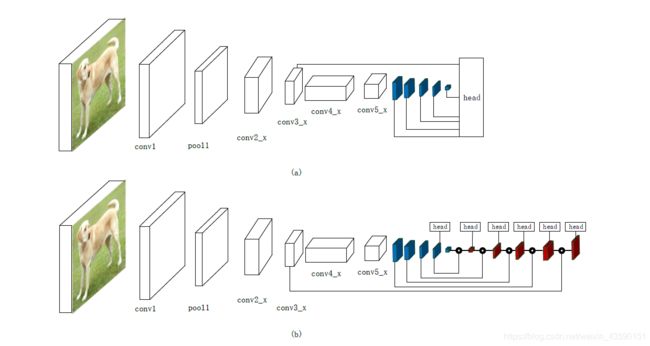
现有的特定领域图像对象检测器通常可以分为两类,一类是两级检测器,最具代表性的一种,Faster R-CNN[8]。另一种是单级检测器,如YOLO [9], SSD[10]。两级检测器具有较高的定位和目标识别精度,而单级检测器具有较高的推理速度。采用ROI pooling层将两级检测器分为两级。例如,在fater R-CNN中,第一阶段称为RPN,一种区域建议网络,提出候选对象边界盒。第二阶段,通过RoIPool (RoI Pooling)操作从每个候选框中提取特征,用于以下分类和边界盒回归任务[11]。图1 (a)为两级探测器的基本结构。此外,单级检测器直接从输入图像中提出预测框,不需要区域建议步长,因此具有时间效率,可用于实时设备。图1 (b)为单级探测器的基本结构。
• Contributions
本文的其余部分组织如下。对象检测器需要一个强大的骨干网络来提取丰富的特性。本文将在下面的第2节讨论骨干网。众所周知,特定于领域的图像检测器的典型管道是任务的基础和里程碑。在第3部分,本文阐述了在2019年6月之前提出的最具代表性和开创性的基于深度学习的方法。第4节描述了常用的数据集和度量。第5节系统地阐述了一般目标检测方法的分析。第6节详细介绍了目标检测的五个典型领域和几个流行的分支。第7节总结了发展趋势。
BACKBONE NETWORKS
骨干网作为目标检测任务的基本特征提取器,以图像作为输入,输出相应输入图像的特征映射。用于检测的骨干网大多是去除最后的全连接层进行分类的网络。改进后的基本分类网络也可用。例如Lin等[15]增加或减少图层,或者用特殊设计的图层替换一些图层。为了更好的满足具体的需求,部分模型[9][16]利用新设计的主干进行特征提取。
针对精度和效率的不同要求,人们可以选择连接更紧密的椎骨,如ResNet[11]、ResNeXt[17]、AmoebaNet[18]或轻量化骨干网络,如MobileNet[19]、ShuffleNet[20]、SqueezeNet[21]、Xception[22]、MobileNetV2[23]。当应用于移动设备时,轻量级的骨干网络可以满足要求。Wang等人[24]提出了一种新的实时目标检测系统,将PeleeNet与SSD[10]相结合,并对体系结构进行了优化,以提高处理速度。为了满足高精度和更精确应用的需要,需要复杂的骨架。另一方面,视频、摄像头等实时获取不仅需要高速的处理速度,还需要高精度的[9],这就需要精心设计的主干来适应检测体系结构,在速度和精度之间进行权衡。
为了提高检测精度,采用更深、密集连接的骨干代替较浅、稀疏连接的骨干。He et al.[11]利用ResNet[25]而不是VGG[26]来捕捉丰富的特征,这种特征在Faster R-CNN[8]中由于高性能,进一步提高了精度。
新型高性能分类网络可以提高目标检测的精度,降低目标检测任务的复杂性。这是进一步提高网络性能的有效方法,因为骨干网作为一个特征提取器。众所周知,特征的质量决定了网络性能的上界,这是一个需要进一步探索的重要步骤。
TYPICAL BASELINES
随着深度学习的发展和计算能力的不断提高,一般目标检测领域取得了很大的进步。当基于cnn的第一个目标检测器R-CNN被提出时,做出了一系列重要的贡献,极大地促进了一般目标检测的发展。我们介绍了一些有代表性的对象检测体系结构,供初学者入门。
A. Two-stage Detectors
- R-CNN: R-CNN是一种基于区域的CNN检测器。Girshick等[28]提出了可用于目标检测任务的R-CNN,他们的工作首次表明在PASCAL VOC数据集[4]上使用CNN可以比基于更简单的HOG-like特征的系统显著提高目标检测性能。深度学习方法在目标检测领域的有效性和有效性得到了验证。
R-CNN检测器由四个模块组成。第一个模块生成与类别无关的区域建议。第二模块从每个区域方案中提取定长特征向量。第三个模块是一组特定类的线性支持向量机,用于对图像中的对象进行分类。最后一个模块是精确预测边界盒的边界盒回归器。首先,在生成区域建议时,采用了selective search的方法。然后使用CNN从每个区域方案中提取一个4096维的特征向量。由于全连通层需要固定长度的输入向量,因此区域建议特征应该具有相同的大小。本文采用固定的227×227像素作为CNN的输入大小。我们知道,在不同的图像中,目标的大小和高宽比不同,这使得第一个模块提取的区域建议在大小上不同。无论候选区域的大小或长宽比如何,作者将其周围的紧密边框中的所有像素扭曲为所需大小227×227。特征提取网络由五个卷积层和两个全连接层组成。所有CNN参数在所有类别中共享。每个类训练独立的支持向量机,不同支持向量机之间不共享参数。
对较大的数据集进行预训练,然后对指定的数据集进行微调,是深度卷积神经网络快速收敛的一种很好的训练方法。首先,Girshick等人[28]在一个大规模数据集(ImageNet分类数据集[3])上对CNN进行预训练。最后的全连接层被CNNs ImageNet专用的1000路分类层所替代。下一步是使用SGD(随机梯度下降)来微调候选窗口上的CNN参数。最后一个全连接层是一个(N+1)方式的分类层(N:对象类,1:背景),它是随机初始化的。
在设置正样本和负样本时,作者将其分为两种情况。首先是在微调过程中将IoU(交集比并)重叠阈值定义为0.5。在阈值以下,region proposals被定义为负样本,而在阈值之上,region proposals被定义为正样本。此外,region proposals中与groundtruth的重叠最大IoU被分配给ground-truth box.另一种情况是在训练SVM时设置参数。相比之下,对于它们各自的类,只有ground-truth box被作为正样本,并且proposal与一个类的所有ground-truth实例的重叠都小于0.3 IoU,作为该类的消极proposal。这些ground-truth的重叠部分在0.5和1之间,它们不是ground truth,这使得正样本的数量增加了大约30个。因此,这样大的集合可以有效地避免微调过程中的过拟合。
- Fast R-CNN:一年后,Ross Girshick[29]提出了一个更快的版本,叫做Fast R-CNN[29]。由于R-CNN在不共享计算的情况下对每个区域方案进行卷积前向传递,使得R-CNN在支持向量机分类上花费了很长时间。Fast RCNN从整个输入图像中提取特征,然后通过感兴趣区域(RoI)池化层得到固定大小的特征作为下面分类和bounding box回归全连接层的输入。从整个图像中提取一次特征,一次发送给CNN进行分类和定位。
与向CNN输入每个区域建议的R-CNN相比,快速的R-CNN可以节省大量的时间用于CNN的处理,也可以节省大量的磁盘存储来存储大量的特征。如前所述,RCNN的训练是一个多阶段的过程,包括预训练阶段、微调阶段、支持向量机分类阶段和边界盒回归阶段。Fast R-CNN是一个单阶段的端到端训练过程,使用每个标记RoI的多任务损失来联合训练网络。
另一个改进是Fast R-CNN使用RoI池化层从不同大小的region proposals中提取固定大小的feature map。该操作不需要对区域进行扭曲,保留了region proposals特征的空间信息。为了快速检测,采用截断奇异值分解,加速了全连通层的前传计算。
实验结果表明,在PASCAL VOC 2007数据集[4]上,Fast R-CNN具有66.9%的mAP,而R-CNN为66.0%。训练时间下降到9.5小时,而RCNN只有84h,快9倍。在测试速率(s/image)方面,SVD截断的Fast R-CNN (0.32s)比RCNN (47s)快213。这些实验在Nvidia K40 GPU上进行,证明了快速R-CNN确实加速了目标检测过程。
- Faster R-CNN:在提出Fast R-CNN 3个月后,Faster R-CNN[8]进一步改善了基于区域的CNN基线。Fast R-CNN使用 selective search 来提出RoI,速度较慢,运行时间与检测网络相同。faster R-CNN用一种新的RPN(区域建议网络)代替了它,这是一种完全卷积的网络,可以有效地预测具有大范围尺度和宽高比的region proposals。RPN与检测网络共享全图像卷积特征和一套通用的卷积层,从而加快了region proposals的生成速度。图3 (b)简化了该过程。此外,一种针对不同尺寸目标的新方法是使用多尺度锚点作为参考。该锚点可以大大简化生成各种大小区域建议的过程,而不需要输入图像或特征的多个尺度。在最后一个共享卷积层的输出(feature map)中,滑动一个固定大小的窗口(3×3),每个特征窗口的中心点相对于原始输入图像中k(3×3)锚盒的中心点。作者定义锚框具有3种不同的比例和3种高宽比。区域建议是相对于参考锚框参数化的。然后测量预测盒与其对应的ground truth box之间的距离,优化预测box的位置。
实验表明,Faster R-CNN大大提高了检测精度和效率。在PASCAL VOC 2007测试集中,使用共享卷积计算,Faster R-CNN获得了69.9%的mAP而Fast R-CNN为66.9%。另外,更快的R-CNN的总运行时间(198ms)比相同VGG[26]骨干的Fast R-CNN (1830ms)低近10倍,处理速率为5帧/秒和0.5帧/秒。
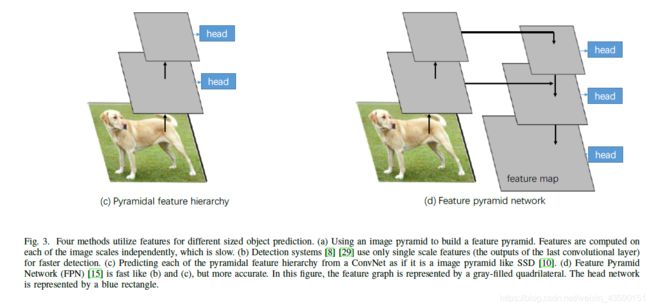
- Mask R-CNN: Mask R-CNN[11]是一个扩展faster R-CNN的工作,主要用于实例分割任务。无论添加并行掩模分支,Mask R-CNN都可以看作一个更准确的目标检测器。He et al.使用Faster RCNN和ResNet [25]-FPN [15] (feature pyramid network,一个骨干网络,根据其规模从feature pyramid的不同层次提取感兴趣区域的特征)骨干进行特征提取,具有良好的准确率和处理速度。FPN包括一个自下而上的通路和一个有横向连接的自上而下的通路。自底向上路径是一个主干卷积网络,它计算由多个尺度的特征图组成的特征层次,其缩放比例步骤为2。自顶向下的途径通过从更高的金字塔层次上向上采样,空间上更粗糙,但语义上更强,从而产生更高分辨率的特征。一开始,顶层金字塔特征图被自底向上路径最后一个卷积层的输出捕获。每一个横向连接都将自底向上路径和自顶向下路径的相同空间大小的特征图合并在一起。feature map的维数是不同的,但是convolutional layer可以改变维数。一旦进行横向连接操作,就会形成新的金字塔层,每一层的预测都是独立进行的。由于高分辨率的feature map对于检测小物体非常重要,而低分辨率的feature map具有丰富的语义信息,因此feature pyramid network可以提取出显著的feature。
另一种提高准确率的方法是用RoIAlign代替RoI pooling,从每个RoI中提取小的feature map,如图2所示。传统的RoI pooling将floating number量化为两步,得到每个bin中的近似特征值。首先,根据输入图像中RoI的坐标和下采样步幅,量化计算每个RoI在特征图上的坐标。然后将感兴趣区域特征图划分为多个boxes,生成大小相同的特征图,并在此过程中量化。这两种量化操作会导致RoI与提取的特征之间的不一致。为了解决这个问题,在这两个步骤中,RoIAlign避免了对RoI边界或区域的量化。首先计算每个感兴趣区域特征图坐标的浮点数,然后进行双线性插值运算,计算每个感兴趣区域中四个有规律采样位置的特征的精确值。然后使用最大池或平均池聚合结果以获得每个box的值。图2是RoIAlign操作的示例。
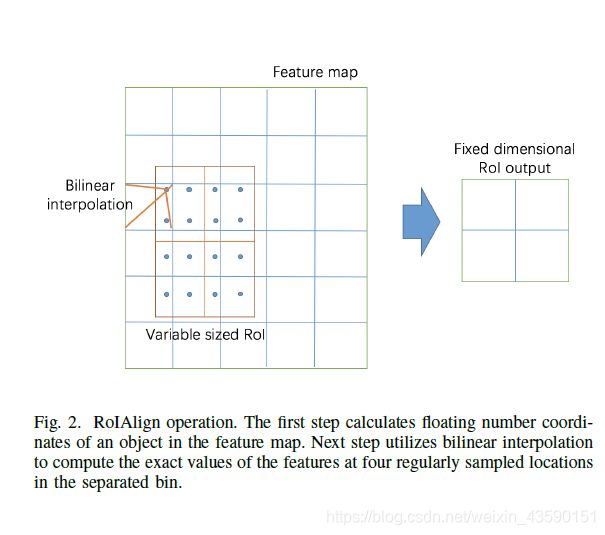
实验表明,通过上述两种改进,提高了系统的精度。采用ResNet-FPN骨干算法改进1.7点box AP, RoIAlign算法改进1.1点box AP。
B. One-stage Detectors
- YOLO:YOLO是Redmon等人在Faster RCNN[8]之后提出的一种一级目标检测器。其主要贡献是实时检测完整的图像和网络摄像头。首先,这是由于这个管道预测每幅图像的边界盒少于100,而Fast R-CNN使用selective search预测2000个region proposals每张图片。其次,YOLO帧检测作为一个回归问题,统一的架构可以直接从输入图像中提取特征来预测边界盒和类概率。YOLO网络运行速度为每秒45帧,在泰坦X GPU上没有批处理,相比之下fast R-CNN速度0.5fps, faster R-CNN速度7fps。
YOLO管道首先将输入图像划分为S×S网格,网格单元格负责检测中心所在的对象。置信值由两部分相乘得到,其中P(object)表示包含对象的box的概率,IOU(交集大于并集)表示包含该对象的盒子的精确度。每个网格单元预测B个边界框(x;y; w;h)和置信分数,C类的C维条件类概率。特征提取网络包含24个卷积层和2个全连接层。在ImageNet dataset的预训练中,作者使用了前20个卷积层和一个平均池化层,以及一个完全连接层。为了更好的检测性能,使用了整个网络。为了得到更细粒度的视觉信息以提高检测精度,在检测阶段将预训练阶段的输入分辨率提高一倍。
实验表明,YOLO的定位精度不高,定位误差是造成预测误差的主要因素。Fast R-CNN有很多背景误报,而YOLO是它的3倍。YOLO在PASCAL VOC dataset上进行训练和测试,与fast R-CNN (70.0% mAP, 0.5fps)和faster R-CNN (73.2% mAP, 7fps)相比,YOLO在45 fps下实现了63.4% mAP。
- YOLOv2:YOLOv2[30]是YOLO的第二个版本[9],采用了一系列来自以往作品的设计决策和新颖的概念,以提高YOLOs的速度和精度。
Batch Normalization.
对卷积层输入的固定分布将对层产生积极的影响。因为优化步骤使用的是随机梯度下降,所以将整个训练集标准化是不切实际的。因为SGD在培训中使用小批量,每个小批量产生相应batch激活的平均值和方差的估计。计算大小为m的小批量的均值和方差值,然后对激活函数后的m进行归一化,使其均值为零,方差为1。最后,从相同的分布中采样每个小批的元素。这个操作可以看作是一个BN层[31],它输出具有相同分布的激活。YOLOv2在每个卷积层之前增加了一个BN层,加速了网络的收敛速度,有助于模型的正则化。批处理归一化在mAP上得到超过2%的改进。
High Resolution Classifier.
在YOLO骨干中,分类器采用输入分辨率为224×224,然后将分辨率提高到448进行检测。这个过程需要网络调整到一个新的分辨率输入时,切换到目标检测任务。为了解决这个问题,YOLOv2在ImageNet数据集上的分类网络448×448添加了一个微调过程,10个epoch, mAP增加了4%。
Convolutional with Anchor Boxes.
在原有的YOLO网络中,预测盒的坐标是由完全连接的层直接生成的。faster R-CNN使用锚盒作为参考来生成与预测盒的偏移量。YOLOv2采用这种预测机制,首先去除完全连接的层。然后它为每个锚框预测类和对象。此操作增加了7%的召回率,而mAP减少了0.3%。
Predicting the size and aspect ratio of anchor boxes using dimension clusters.
在faster R-CNN中,经验地识别锚框的大小和长宽比。为了便于学习预测好的检测结果,YOLOv2对训练集边界盒使用K-means聚类自动得到好的先验。使用维度集群以及直接预测边界框中心位置,比使用锚框的版本提高了YOLO近5%。
Fine-Grained Features.
对于小物体的定位,高分辨率的地形图可以提供有用的信息。与ResNet中的残差网络类似,YOLOv2通过将相邻的特征叠加到不同的通道,将高分辨率特征与低分辨率特征连接起来,性能略微提高1%。
Multi-Scale Training
为了使网络能够健壮地运行不同大小的图像,网络每10批就从{320,352,…,608}中随机选择一个新的图像尺寸大小。这意味着同一个网络可以预测不同分辨率的探测结果。在高分辨率检测中,在VOC 2007上,YOLOv2的mAP达到78.6%,fps达到40fps,而YOLO的mAP为63.4%及45fps。
YOLOv2提出了一种新的分类骨干,即具有19个卷积层和5个maxpooling层的Darknet-19,处理一幅图像所需的操作较少,但准确率较高。更有竞争力的YOLOv2版本有78.6%的mAP和40fps,而faster R-CNN与ResNet主干有76.4% mAP和5fps, SSD500有76.8% mAP和19fps。如前所述,YOLOv2可以实现较高的检测精度和较高的处理速度,这得益于7项主要改进和一个新的骨干。
- YOLOv3:YOLOv3[32]是YOLOv2的改进版本。首先,YOLOv3使用多标签分类(独立的logistic分类器)来适应包含许多重叠标签的更复杂数据集。其次,YOLOv3利用三种不同比例的feature map来预测边界盒。最后的卷积层预测三维张量:编码类的预测、对象性和边界框。第三,YOLOv3提出了一个更深入、更健壮的特征提取器,称为Darknet-53,灵感来自ResNet。
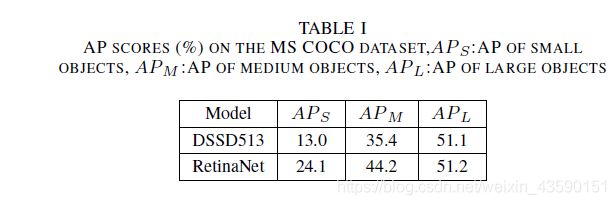
在MS COCO数据集上的实验结果表明,YOLOv3 (AP:33%)在MS COCO指标下的性能与SSD变体(DSSD513:AP:33.2%)相当,但比DSSD快3倍,略低于RetinaNet [33] (AP:40.8%)。但在IOU= 0.5(或AP50)时,使用旧的mAP检测度量,YOLOv3可以实现57.9%的mAP, DSSD513为53.3%,RetinaNet为61.1%。由于多尺度预测的优势,YOLOv3可以更多地检测小尺度的物体,但对大中型物体的检测性能相对较差。
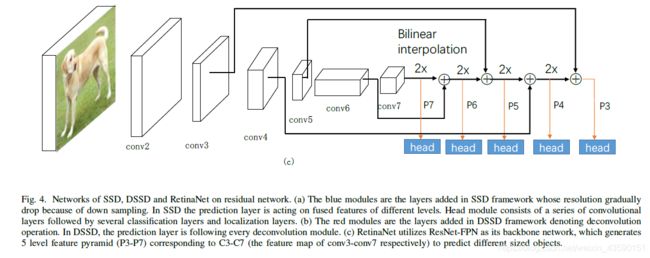
- SSD:SSD[10],单发探测器内多个类别单程直接预测类别分数和盒补偿违约边界框的一组固定在每个位置在几个不同尺度和不同尺度的特征图,如图4所示(一个)。默认的边界框有不同的纵横比和尺度地图在每个特性。在不同的feature maps中,默认边界框的比例被计算,在最高层和最低层之间有规则的空间,每个特定的feature map学习对对象的特定比例做出反应。对于每个默认框,它预测所有对象类别的偏移量和机密。方法如图3 ©所示。在训练时,将这些默认边界盒与ground truth盒进行匹配,其中所匹配的默认盒为正例子,其余为负例子。对于大量默认框为负数的情况,采用难负样本挖掘方法,将每个默认框的置信度损失最大,选取最优的默认框,使其正负之比最多为3:1。同时,采用数据增强的方法,可以大幅度提高数据的精度。
实验表明,SSD512与vgg16[26]主干网相比,在贴图和速度上都具有较好的竞争力。在PASCAL VOC 2007和PASCAL VOC的测试集上,SSD512(输入图像大小:512×512)实现mAP分别为81.6%和 80.0%。在PASCAL VOC2012测试集中,faster R-CNN(78.8%, 75.9%)和YOLO (VOC2012: 57.9%)。在MS COCO的数据集上SSD512在所有评价标准下都优于Faster R-CNN。
- DSSD:DSSD(反卷积单阶段探测器)是SSD(单阶段探测器)的改进版本。其中增加了预测模块和反卷积模块,并采用ResNet-101作为骨干。DSSD的体系结构如图4 (b)所示,对于预测模块,Fu等人在每个预测层中添加一个残差块,然后将预测层的输出与残差块按元素进行相加。反卷积模块增加特征图的分辨率,增强特征。每个反卷积层之后是一个预测模块,用于预测各种大小不同的目标。在训练过程中,首先在ILSVRC CLSLOC数据集上对基于ResNet-101的骨网进行预训练,然后使用321×321或513×513检测数据集输入对原始SSD模型进行训练。最后,训练反卷积模块冻结SSD模块的所有权重。
在PASCAL VOC数据集和MS COCO数据集上的实验表明了DSSD513模型的有效性,同时增加了预测模块和反卷积模块对PASCAL VOC 2007测试数据集增强2.2%。
- RetinaNet:RetinaNet[33]是Lin等人在2018年2月提出的一种以Focalloss为分类损失函数的一级目标探测器。RetinaNet的架构如图4 ©所示,R-CNN是一种典型的两级目标检测器。第一阶段生成稀疏的区域建议集,第二阶段对每个候选位置进行分类。由于第一阶段滤除了大部分的负位置,两阶段探测器比一阶段探测器能获得更高的精度,一阶段探测器提出了密集的候选位置集。其主要原因是单级检测器在训练网络收敛时前类别极不平衡。因此,作者提出了一个损失函数,称为Focalloss,它可以降低分配给分类良好或简单的例子的损失。焦点损失集中在困难的训练例子上,避免了训练过程中大量的容易的负样本作用于检测器。RetinaNet继承了以往单级检测器速度快的特点,同时极大地克服了单级检测器难以训练不平衡正负例的缺点。
实验表明,在MS COCO test-dev数据集上,基于ResNet-101-FPN主干的RetinaNet的AP为39.1%,而DSSD513为33.2%。有了ResNeXt-101-FPN,它取得了40.8%的AP远远超过DSSD513。RetinaNet大大提高了对中小型目标的检测精度。
-
M2Det:为了满足对象实例间尺度变化大的问题,Zhao等[35]提出了构建更有效特征金字塔的多级特征金字塔网络(multilevel feature pyramid network, MLFPN)。采用三步来获得最终的增强特征金字塔。首先,像FPN一样,将主干中多层提取的多层特征融合为基础特征。其次,将基特征送入块中,由交替关节稀疏的Ushape模块和特征融合模块组成,得到TUM的解码器层作为下一步的特征。最后,通过等效尺度的译码层积分,构造出包含多层次特征的特征金字塔。到目前为止,已经准备了多尺度、多层次的特征。剩下的部分是按照SSD体系结构获取边界框的定位和分类以端到端方式进行。由于M2Det是单级检测器,在COCO test-dev set上使用VGG-16,以11.8 FPS的速度实现AP 41.0,在多尺度推断策略下实现AP 44.2,在单尺度下比RetinaNet800 (Res101- FPN为主干)高出0.9%。
-
RefineDet:RefineDet[36]的整个网络包含两个相互连接的模块,锚点细化模块和目标检测模块。通过传输连接块将两个模块连接起来,传输和增强前一个模块的特征,以便更好地预测后一个模块中的对象。训练过程是端到端的,分为预处理、检测(两个相互连接的模块)和NMS三个阶段。
经典的单级检测器SSD、YOLO、RetinaNet均采用一步回归方法得到最终结果。结果表明,两步级联回归方法能较好地预测难检测目标,特别是小目标,并能提供更准确的目标位置。
未完待续
REFERENCE
[1] P. Dollar, C. Wojek, B. Schiele, and P. Perona, Pedestrian detection: An evaluation of the state of the art, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 34, pp. 743 761, April 2012.
[2] A. Geiger, P. Lenz, and R. Urtasun, Are we ready for autonomous driving? the kitti vision benchmark suite, in 2012 IEEE Conference on Computer Vision and Pattern Recognition, pp. 3354 3361, June 2012.
[3] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei, Imagenet large scale visual recognition challenge, International Journal of Computer Vision, vol. 115, pp. 211 252, Dec 2015.
[4] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman, The pascal visual object classes (voc) challenge, International Journal of Computer Vision, vol. 88, pp. 303 338, Jun 2010.
[5] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ar, and C. L. Zitnick, Microsoft coco: Common objects in context, in Computer Vision ECCV 2014 (D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, eds.), (Cham), pp. 740 755, Springer International Publishing, 2014.
[6] A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin, J. Pont-Tuset, S. Kamali, S. Popov, M. Malloci, T. Duerig, and V. Ferrari, The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale, arXiv:1811.00982, 2018.
[7] P. Zhu, L. Wen, X. Bian, H. Ling, and Q. Hu, Vision meets drones: A challenge, arXiv preprint arXiv:1804.07437, 2018.
[8] S. Ren, K. He, R. Girshick, and J. Sun, Faster r-cnn: Towards real-time object detection with region proposal networks, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, pp. 1137 1149, June 2017.
[9] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, You only look once: Unified, real-time object detection, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 779 788, June 2016.
[10] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, Ssd: Single shot multibox detector, in Computer Vision ECCV 2016 (B. Leibe, J. Matas, N. Sebe, and M. Welling, eds.), (Cham), pp. 21 37, Springer International Publishing, 2016.
[11] K. He, G. Gkioxari, P. Dollr, and R. Girshick, Mask r-cnn, in 2017 IEEE International Conference on Computer Vision (ICCV), pp. 2980 2988, Oct 2017.
[12] A. Khan, A. Sohail, U. Zahoora, and A. S. Qureshi, A survey of the recent architectures of deep convolutional neural networks, arXiv preprint arXiv:1901.06032, 2019.
[13] Z. Zou, Z. Shi, Y. Guo, and J. Ye, Object detection in 20 years: A survey, CoRR, vol. abs/1905.05055, 2019. [14] L. Liu, W. Ouyang, X. Wang, P. Fieguth, J. Chen, X. Liu, and M. Pietik ainen, Deep learning for generic object detection: A survey, arXiv preprint arXiv:1809.02165, 2018.
[15] T. Lin, P. Dollr, R. Girshick, K. He, B. Hariharan, and S. Belongie, Feature pyramid networks for object detection, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 936 944, July 2017.
[16] Z. Li, C. Peng, G. Yu, X. Zhang, Y. Deng, and J. Sun, Detnet: A backbone network for object detection, arXiv preprint arXiv:1804.06215, 2018.
[17] S. Xie, R. Girshick, P. Doll ar, Z. Tu, and K. He, Aggregated residual transformations for deep neural networks, in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1492 1500, 2017.
[18] G. Ghiasi, T.-Y. Lin, R. Pang, and Q. V. Le, Nas-fpn: Learning scalable feature pyramid architecture for object detection, arXiv preprint arXiv:1904.07392, 2019.
[19] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, Mobilenets: Efficient convolutional neural networks for mobile vision applications, arXiv preprint arXiv:1704.04861, 2017.
[20] X. Zhang, X. Zhou, M. Lin, and J. Sun, Shufflenet: An extremely efficient convolutional neural network for mobile devices, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6848 6856, 2018.
[21] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, Squeezenet: Alexnet-level accuracy with 50x fewer parameters and 0.5 mb model size, arXiv preprint arXiv:1602.07360, 2016.
[22] F. Chollet, Xception: Deep learning with depthwise separable convolutions, in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1251 1258, 2017.
[23] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, Mobilenetv2: Inverted residuals and linear bottlenecks, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4510 4520, 2018.
[24] R. J. Wang, X. Li, and C. X. Ling, Pelee: A real-time object detection system on mobile devices, in Advances in Neural Information Processing Systems, pp. 1963 1972, 2018.
[25] K. He, X. Zhang, S. Ren, and J. Sun, Deep residual learning for image recognition, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770 778, June 2016.
[26] K. Simonyan and A. Zisserman, Very deep convolutional networks for large-scale image recognition, arXiv preprint arXiv:1409.1556, 2014. [27] W. Rawat and Z. Wang, Deep convolutional neural networks for image classification: A comprehensive review, Neural computation, vol. 29, no. 9, pp. 2352 2449, 2017.
[28] R. Girshick, J. Donahue, T. Darrell, and J. Malik, Rich feature hierarchies for accurate object detection and semantic segmentation, in 2014 IEEE Conference on Computer Vision and Pattern Recognition, pp. 580 587, June 2014.
[29] R. Girshick, Fast r-cnn, in 2015 IEEE International Conference on Computer Vision (ICCV), pp. 1440 1448, Dec 2015.
[30] J. Redmon and A. Farhadi, Yolo9000: Better, faster, stronger, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6517 6525, July 2017.
[31] S. Ioffe and C. Szegedy, Batch normalization: Accelerating deep network training by reducing internal covariate shift, arXiv preprint arXiv:1502.03167, 2015.
[32] J. Redmon and A. Farhadi, Yolov3: An incremental improvement, CoRR, vol. abs/1804.02767, 2018. [33] T. Lin, P. Goyal, R. Girshick, K. He, and P. Dollr, Focal loss for dense object detection, in 2017 IEEE International Conference on Computer Vision (ICCV), pp. 2999 3007, Oct 2017.
[34] C.-Y. Fu, W. Liu, A. Ranga, A. Tyagi, and A. C. Berg, Dssd: Deconvolutional single shot detector, arXiv preprint arXiv:1701.06659, 2017.
[35] Q. Zhao, T. Sheng, Y. Wang, Z. Tang, Y. Chen, L. Cai, and H. Ling, M2det: A single-shot object detector based on multi-level feature pyramid network, arXiv preprint arXiv:1811.04533, 2018.
[36] S. Zhang, L. Wen, X. Bian, Z. Lei, and S. Z. Li, Single-shot refinement neural network for object detection, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4203 4212, 2018. [37] H. Hu, J. Gu, Z. Zhang, J. Dai, and Y. Wei, Relation networks for object detection, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3588 3597, 2018.
[38] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei, Deformable convolutional networks, in Proceedings of the IEEE international conference on computer vision, pp. 764 773, 2017.