微软邓力:驱动大数据人工智能多种应用的三类深度学习模式(附PPT下载)
8月26日至27日,在中国科学技术协会、中国科学院的指导下,由中国人工智能学会发起主办、中科院自动化研究所与CSDN共同承办的2016中国人工智能大会(CCAI 2016)在北京辽宁大厦盛大召开,这也是本年度国内人工智能领域规模最大、规格最高的学术和技术盛会,对于我国人工智能领域的研究及应用发展有着极大的推进作用。大会由CSDN网站进行专题直播,并由百度开放云提供独家视频直播技术支持。
在26日的主题报告环节,微软人工智能首席科学家、IEEE Fellow邓力博士做了《驱动大数据人工智能多种应用的三类深度学习模式》的主题演讲,他首先介绍了深度学习的基本定义,以及深度学习的三种模式。邓力表示,AI=感知+认知,首先是感知,更深层次的是认知,而人工智能目前更需要解决的是认知的问题,而深度学习是提升认知,推进人工智能进一步发展的最有效的方法。然后,邓力介绍了深度学习在语音识别方面的进展,他表示,目前苹果、谷歌、亚马逊都在用深度学习研究语音识别,并取得了较好的效果。接着,邓力介绍了深度学习对于图像识别的影响。邓力接着介绍了深度学习在机器认知方面的进展,通过使用Long Short-Term Memory RNN等模型,目前已经可以实现效果比较好的效果。最后,邓力介绍了增强学习,他表示,深度学习加增强学习可以解决更复杂的人工智能难题,而深度非监督学习则是未来人工智能的又一个重要的研究课题和未来的发展方向。

以下为邓力演讲实录(未经演讲者本人确认):
谢谢大家,今天讲的题目是《驱动大数据人工智能多种应用的三类深度学习模式》,第一个模式是用有标注的大数据来做有监督深度学习,第二个是用无标注的(更)大数据来做非监督学习,第三部分就是深度增强学习。
深度学习与人工智能
首先,深度学习的基本概念大家要了解。如果不了解可以先看维基百科,维基百科有关深度学习的页面介绍得非常清楚,在一开头就把深度学习的三个基本要点讲出来了。深度学习有好多层的非线性变换,这跟大脑是有一定的关系,这也使端到端的优化很必要。在深度学习之前的一些很多模型,就比较“浅”,“端到端”的特点并不是特别明显。很大一部分深度学习的进展,就是怎样把这个深层优化解决。更重要的是,好多层非线性变化的结果,是在不同的层次上面把它抽象化进行层次的分类,这一点在所谓的图像上面显得特别清楚,在不同的层次上面看到有的时候是比较浅层的特征;接近于高层,认知方面的特征越来越明显。在语音识别上面,我们也发现有类似不同层次的抽象。这种多层次抽象对于深度学习在自然语言理解和推理的应用的意义是更大的。
机器进行有监督深度学习之前,一定要把输入输出匹配好,否则这个Y和X之间就做不了深度学习,然后这就所谓的supervision(有监督),在语音识别的情况下,你讲一个句子之后,有监督深度学习要求你把与这个句子语音相对应的文本准备好。这种学习方法有很大的局限。就是在训练样本越来越大之后,这样标注的价钱非常高,使得非常非常大规模的深度学习,并不可以那么如意的进行。所以,现在很多的公司内部做深度学习,只是把数据量局限到3000小时,至多3万小时。如果要再加到30万小时、300万小时,也要按照现有的学习方法来训练的话,那么这就已经到了一定程度使得经济上划不来了。
还有强化学习和非监督学习,这两个方向的学习是目前深度学习的更加活跃的领域,深度强化学习有很多成功的例子。

我这个题目还有一个字眼是“人工智能”?按Wikipedia,AI就是人为造成的智能。这并没告诉你新的信息。为了给你新的信息,从我现在这个演讲的角度来讲,我想把人工智能分成两部分,一部分是所谓的感知——感知是什么意思?就是说你所看到的这些现象、视觉的现象,还有语音的现象、音乐,手势,触觉,等等。感知指的是人怎样把原始的感官得来的信号转变到一些跟认知有关的过程,语音识别属于感知,图象识别也属于感知。

下面更重要的是叫做机器的认知。它包括自然语言,这是机器认知很大的部分。认知讲的是怎样把人类发明的符号进行转换,然后就可以形成知识。决策和控制也属于认知。刚才大疆的李泽湘教授讲的那些机器人的控制就在认知范畴之内。要控制好机器人的动作,必须要理解并模拟物理过程。然后认知还有很大的一部分是关于人机对话,这一方面最近很多公司在做非常大的投入,微软也有很多有关的消息。趁这个机会我向大家介绍一下我们微软的思路,让大家稍微了解一下这个新的领域。这个领域完全是属于机器认知部分的人工智能。
在讲之前,我先把人工智能的应用跟大家讲一下,刚才谭院长也有讲过很多人工智能的应用。首先让大家知道,深度学习在语音方面的应用最早是2009到2010年的时候。2年之后 深入学习在图像识别上的应用取得成功。研究者用的方法都是深度神经网络和有监督学习。还没有用到将来可能有的大数据量,只不过比他们之前用的数据更大。在图像识别成功之后的深入学习的成功例子包括机器翻译、包括自然语言理解和问答。
现在,深度学习第一步的成功我们已经看得很清楚。比如说用深度学习做的机器翻译的效果现在已经超过了发展了25年多的传统的统计方法。然后深度学习在游戏上面也有很大的成功,深度增强学习起了决定性的作用。那么下一步的波浪是什么呢?这张slide写的只是我的估计。比如说自动知识提取和整合应用并扩展。我现在有相当多的背景来做估计,也为此访问了不少专家。

深度学习下一步可能的成功,基于现在很多研究在往这方面,是所谓的人机对话,我们采用的基本技术是叫做增强深度学习,很大程度上直接用现有成功的深度学习和增强学习去达到成功的效果。增强深度学习有相当多这方面的应用,包括最近你们看到的新闻报道。在节能和环境保护上面已经有了相当大的意义。那些报道说已经在数据中心内能源节省了40%。
监督深度学习与语音识别
首先把这个监督深度学习在语音识别的应用给大家做一个回顾,基本思想就是用非常大量的有匹配的输入输出数据训练大型的深度神经网络。对于语音输入,你要知道他讲什么,把这个准备好以后就丢到深度学习的机器去训练它的大量参数。2009年差不多年底的时候,我们微软同多伦多大学当时做了一个非常好的合作。当时Hinton 教授到了我们微软来,把一个基于RBM/DBN pretraining 的深度神经网络方法给我们介绍了。在这之前几年之内,我们实际上用了非常强的深度贝叶斯网络方法来模拟语音生成的多层次的结构。从语音深层次的角度来讲,首先有个符号概念形成的层次。比如现在我要讲什么句子,几个毫秒之前我的脑袋就知道。生成这个符号概念之后要把这个概念转成下一层的所谓的motor control。然后motor controller在运动神经系统内激发出一些起控制作用的目标。不同的声音的元素(音素,phoneme)是跟不同的控制目标连在一起的。这个控制目标可以驱动发音肌肉高度协调的伸缩。这有点像刚才李教授讲手精细动作的控制。我这里讲的是在语音生成时嘴巴、舌头运动的控制。这一层次完了之后就到了下一层次,它可以描述整体的声道作为一个动态系统。那么在这一运动层之后的因果关系就是 articulatory-to-acoustis投射。用的是声学原理,把这个口腔运动层转化成声学的语音层。怎样把以上这种深层次的语音生成模型用于语音识别?你知道应该用Bayes Rule,这是一个很传统的方法。对这个非常深层的生成模型,我们在微软做了4到5年的研究。

当时在2006年Hinton教授和同事写了一篇DBN的文章,这被学术界认为是深度学习的开始。那篇文章讲的DBN实际上跟我以上讲的深层语音模型都是生成式模型。但DBN直接是用神经网络来参数化整体的生成式模型,这个是非常有用的。
我们当时在2009-2010年用DNN的方法,直接用很简单的神经网络,得到了同深层语音生成式模型差不了多少的识别率,但识别错误种类截然不同。所以我一做这种比较之后就觉得这个DNN肯定有学问,所以我们就继续把它的规模加大。原来的计划是把DNN加大到一定程度以后再回去把语音知识用物理模型的形态加回语音识别器。现在DNN/RNN做有监督学习太成功了,大家根本不想回去。但是我想下一步因为现有的DNN/RNN不能做无监督的深度学习,这些语音知识和物理模型在将来做无监督深度学习是必要的。
经过了大概2年多的艰苦奋斗,包括研究院北京的员工与我们合作,我们终于在2012年做出由DNN驱动的大型语音识别和翻译。这里想提到一个很重要的发现。差不多2010年夏天的时候,我们发现如果训练数据量变的越来越大之后,原先的用RBM/DBN来pretraining DNN的方法可以丢掉而用更简单的方法来retrain DNN。为了保证我们这么做是有比较好的理论根据,我们当时还做了非常强的分析,从理论上看出来大数据确实可以不需要那么复杂的pretraining。原理实际上很简单。现在所有的深度学习这一块基本上都不用当时所用的 RBM/DBN pretraining的方法。你们看文献的时候,你们要注意在2012年之前的文献常常把DBN和DNN混合在一起。我们微软同多伦多大学在2012年合写的文章中其实才把DBN和DNN正确地分开。
这么成功的语音识别方法,我们实际上并没有很多的知识权保护。Hinton和我在2012年秋同John Markoff分别采访时不约而同地讲到这一点。John也把这一点明确地写到他在纽约时报的著名文章。我想这跟深度学习2012-2013时在工业界迅速崛起有关。

深度学习2012年的时候就已经把语音识别的错误率降到这里(~13%)。今后两三年之后,2014、2015年继续降到了9%左右。
在深度学习成功之后的一年内,我们的进展非常快,跟以前我们用的很复杂的GMM-HMM方法来比较,DNN需要的工程优化要少多了。所以非常快地微软内部所有的语音产品包括 XBOX, Window Phone, Cortana, Skype都全部用深度学习来驱动. 苹果跟亚马逊一般很少在外面去讲他们做的东西,但他们确实也很快地用上了DNN。
监督深度学习与图像识别
下一步讲一下深度学习对物体图像识别的影响。对于图像识别深度学习让错误率下降比语音识别更快更多。你们看在2012年之前错误率差不多一直在26%左右。2012年那时候,大家不完全知道大数据可以把语音识别淘汰下来。当时ImageNet结果出来的时候,公布的时候是10月份,记得我当时把这个结果发给微软做视觉的同事,我的同事们不相信这么好的结果,说可能出了一些问题,也可能说这个dataset不够好,或是他们投机取巧。但我当时一看这ImageNet的结果,就马上知道他和语音识别结果一模一样,就是把模型做大,而且根本不需要preretraining。
这个结果是一个2013年成立的公司Clarifai得到的。2015年底,我们微软孙剑(编辑注:孙剑目前已经加盟旷视科技)的团队公布了这个结果,已经低于人类的错误率。哪怕所用的神经网络是更深,这个深度在近几年以来一直是低于20多. 到今天的2016年,大家真正认识到这个深层是这么的重要。

现在转到机器认知上面。我刚才讲的都是在感知上面的应用。在认知上面的应用,最近很大的一个突破是成功地用记忆模型跟用注意模型——这些都是人的认知技能——把这些模型用到深度学习上,让它们能够解决机器认知上面的问题包括机器翻译。大家对深度学习有一定了解的话,相信知道LSTM。

LSTM让很多的Short-Term记忆单元,变成长期的记忆。这跟人脑的记忆机制相差很远,所以LSTM只是一个数学的模型。你可以把以前的比较简单的神经网络给他理解成是一个“cell”,这个cell比较复杂.它是一个动态的模型。以前两千三千的节点可以被几百个LSTM cells替代。有了LSTM cells之后就可以记一些相当好的信息,如果需要的话,信息可以马上忘掉。 用什么方法使得这个模型把有用的信息记住,没用的忘掉呢。几个礼拜前,在1997年发明了这个模型的Schmidhuber教授在西雅图见到我。这么好的模型20年间没有人用,因为相当复杂。我们两个都同意说这个模型是一个现象模型,跟人类的记忆是差的非常远。那么有了这个模型之后,可以用到很多的学习方法,包括语音识别、语音理解,然后做人工对话。当然你们可以认识到当他本身的这种神经的机制跟真正人的认知有这么大区别的时候,一定有很大的空间让大家做更多的研究。

有了这个LSTM模型之后你就可以做非常有意思的东西,这个机器翻译的工作是一年多前发表的,这个东西为什么会翻译的这么好?他的精髓在什么地方?精髓就是当模型运行到这里之后,这一层已经把所有的信息给编码成一个thought vector,输入,然后用它做输入把这个解码器的网络进行驱动。

下面展示的是更深层的一些记忆模型,用于推理。细节就不讲太多了。
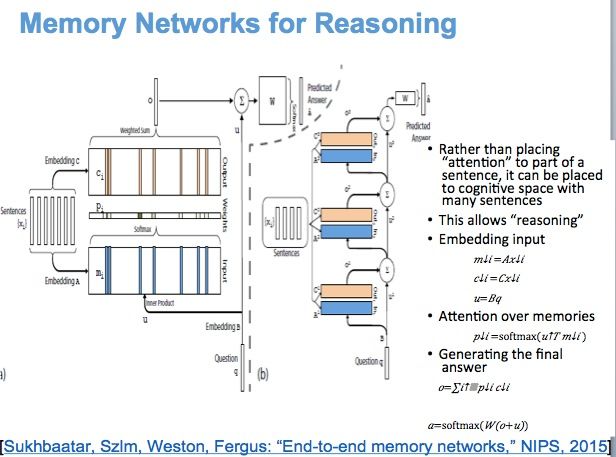
深度增强学习
深度增强学习可以理解成说是以前的增强学习加上深度学习,两者结合就可以解决以前的增强学习解决不了的问题。要是没有深度学习的话,旧的增强学习本身就解决不了现在可以解决的问题。增强学习的方法是看长期的收益。在整个学习的过程中可以把这个长期收益的给优化,这种方法用到阿尔法狗使得他战胜高手。
这里有两个深度学习的网络,AlphaGo是把不同机器学习方法组合在一起,主要的精华还是深度增强学习,第一个神经网络使得他的宽度减少,这样就可以使得搜索方法在比较局限的时间内把所有重要的那些东西搜索出来。

再讲一下深度增强学习在人机对话上的应用。最近我写了一篇文章(微软邓力:深度强化学习在聊天机器人领域的应用),从高层上面从机器学习角度来讲的。首先就说现在的Apps已经达到了一个局限,同时Bots成为了一个新模式。人机交界应用上深度学习已经用到这个领域来了。这个应用为什么需要用增强学习方法呢?是因为说我们交互过程中并不是说每一个对话每一个阶段就要得到什么,这个不可能的。你要是同机器对话,可能经过几轮。如果你想用这个机器干一些事情,让你买机票、订餐馆,你最后得到的收益信息是在完成任务之后得到的,所以这个长期收益的特点是非常符合增强学习的思想。
无监督深度学习
无监督深度学习是一个非常大的新兴领域,我们正在研究。要是没有这个labels你到底怎么做学习?它的精华在不同的研究部门有不同的想法。我们的想法是:一定要把整合人类的现有的知识巧妙地用上。应该把深层学习的方法和其他方法整合到一起。你们做有监督深度学习,都用到Back Propagation,我们现在很多人用的Back Propagation在无监督的条件下做不了。你首先就不知道优化什么和怎么优化。
我们做了一个比较简单的无监督深度学习实验。这个目标函数很奇怪,他旁边有一个很大的堡垒。这只是我们研究里的其中一个结果,让你看到无监督学习的困难在什么地方。


未来通用人工智能需要多种深度学习
最后从我们的角度来谈谈将来的AI会往什么方向发展。
AI将会是一个通用的AI(General AI)。今天早上谭院士讲的话跟我的观点是完全符合的,一个最有用的、最后成功的AI一定是通用的AI,否则这个AI不会被整个业界广泛采用。
怎样把一个领域的知识转化到另外一个领域的知识。这个要基于多种类的深度学习的结合,以及迁移学习的应用。
怎样在深度神经网络上面做symbolic processing,而且必须要能够自动的获取并且产生新的知识,能使得新的知识能够与所有的知识融合在一起。我希望整个业界能够把人工智能作为一种科学的研究来看待,而趋向就是能够广泛地开发使用通用的AI。

现在语音识别AI跟图像识别AI还不一样,目前用在图像识别的深度学习有与语音识别的深度学习不同的结构。阿尔法狗用的方法跟做下围棋和下象棋的方法也是不一样的。将来应该有一个统一的构架,他可以解决各种各样的问题。比如说AI用在医疗,比如说AI用在自动看书理解,比如说用AI代替小孩高考,将来用一个统一的AI就可以了。
我今天就讲到这里,谢谢大家。
演讲PPT下载:微软邓力:驱动大数据人工智能多种应用的三类深度学习模式
本文为现场速记实录,未经演讲者确认。