MySQL的Replace into 与Insert into ..... on duplicate key update ...真正的不同之处
今天听同事介绍oracle到mysql的数据migration,他用了Insert into ..... on duplicate key update ...,我当时就想怎么不用Replace呢,于是回来就仔细查了下,它们果然还是有区别的,看下面的例子吧:
1 Replace into ...
1.1 录入原始数据
mysql> use test;
Database changed
mysql> 
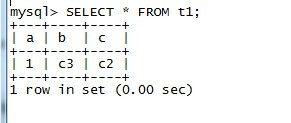
mysql> CREATE TABLE t1 SELECT 1 AS a, 'c3' AS b, 'c2' AS c;
ALTER TABLE t1 CHANGE a a INT PRIMARY KEY AUTO_INCREMENT ;
Query OK, 1 row affected (0.03 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> INSERT INTO t1 SELECT 2,'2', '3';
Query OK, 1 row affected (0.01 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> insert into t1(b,c) select 'r2','r3';
Query OK, 1 row affected (0.08 sec)
Records: 1 Duplicates: 0 Warnings: 0

1.2 开始replace操作
mysql> REPLACE INTO t1(a,b) VALUES(2,'a') ;
Query OK, 2 rows affected (0.06 sec)

【】看到这里,replace,看到这里,a=2的记录中c字段是空串了,
所以当与key冲突时,replace覆盖相关字段,其它字段填充默认值,可以理解为删除重复key的记录,新插入一条记录,一个delete原有记录再insert的操作。
1.3 但是不知道对主键的auto_increment有无影响,接下来测试一下:
mysql> insert into t1(b,c) select 'r4','r5';
Query OK, 1 row affected (0.05 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> select * from t1;
+---+----+----+
| a | b | c |
+---+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | r2 | r3 |
| 5 | r4 | r5 |
+---+----+----+
4 rows in set (0.00 sec)【】从这里可以看出,新的自增不是从4开始,而是从5开始,就表示一个repalce操作,主键中的auto_increment会累加1.
所以总结如下:
Replace:
当没有key时,replace相当于普通的insert.
当有key时,可以理解为删除重复key的记录,在保持key不变的情况下,delete原有记录,再insert新的记录,新纪录的值只会录入replace语句中字段的值,其余没有在replace语句中的字段,会自动填充默认值。
2.1 ok,再来看Insert into ..... on duplicate key update,
mysql> insert into t1(a,b) select '3','r5' on duplicate key update b='r5';
Query OK, 2 rows affected, 1 warning (0.19 sec)
Records: 1 Duplicates: 1 Warnings: 1
mysql> select * from t1;
+---+----+----+
| a | b | c |
+---+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | r5 | r3 |
| 5 | r4 | r5 |
+---+----+----+
4 rows in set (0.00 sec)【】a=5时候,原来的c值还在,这表示当key有时,只执行后面的udate操作语句.
2.2 再检查auto_increment情况。
mysql> insert into t1(a,b) select '3','r5' on duplicate key update b='r5';
Query OK, 2 rows affected, 1 warning (0.19 sec)
Records: 1 Duplicates: 1 Warnings: 1
mysql> select * from t1;
+---+----+----+
| a | b | c |
+---+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | r5 | r3 |
| 5 | r4 | r5 |
+---+----+----+
4 rows in set (0.00 sec)
mysql> insert into t1(b,c) select 'r6','r7';
Query OK, 1 row affected (0.19 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> select * from t1;
+---+----+----+
| a | b | c |
+---+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | r5 | r3 |
| 5 | r4 | r5 |
| 7 | r6 | r7 |
+---+----+----+
5 rows in set (0.00 sec)
【】从这里可以看出,新的自增不是从6开始,而是从7开始,就表示一个Insert .. on deplicate udate操作,主键中的auto_increment也跟replace一样累加1.
2.3 再看下当没有key的时候,insert .. on deplicate update的情况
mysql> insert into t1(a,b,c) select '33','r5','c3' on duplicate key update b='r5';
Query OK, 1 row affected, 1 warning (0.23 sec)
Records: 1 Duplicates: 0 Warnings: 1
mysql> select * from t1;
+----+----+----+
| a | b | c |
+----+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | b5 | r3 |
| 5 | r4 | r5 |
| 7 | r6 | r7 |
| 9 | s6 | s7 |
| 33 | r5 | c3 |
+----+----+----+
7 rows in set (0.00 sec)
看a=33的记录,ok,全部录入了。
3 总结从上面的测试结果看出,相同之处:
(1),没有key的时候,replace与insert .. on deplicate udpate相同。
(2),有key的时候,都保留主键值,并且auto_increment自动+1
不同之处:有key的时候,replace是delete老记录,而录入新的记录,所以原有的所有记录会被清除,这个时候,如果replace语句的字段不全的话,有些原有的比如例子中c字段的值会被自动填充为默认值。
而insert .. deplicate update则只执行update标记之后的sql,从表象上来看相当于一个简单的update语句。
但是实际上,根据我推测,如果是简单的update语句,auto_increment不会+1,应该也是先delete,再insert的操作,只是在insert的过程中保留除update后面字段以外的所有字段的值。
所以两者的区别只有一个,insert .. on deplicate udpate保留了所有字段的旧值,再覆盖然后一起insert进去,而replace没有保留旧值,直接删除再insert新值。
从底层执行效率上来讲,replace要比insert .. on deplicate update效率要高,但是在写replace的时候,字段要写全,防止老的字段数据被删除。
个人倾向与用Replace。