R语言学习笔记(六)——apply函数系列与相关函数(by,aggregate,cut,factor)
R语言学习笔记六
-
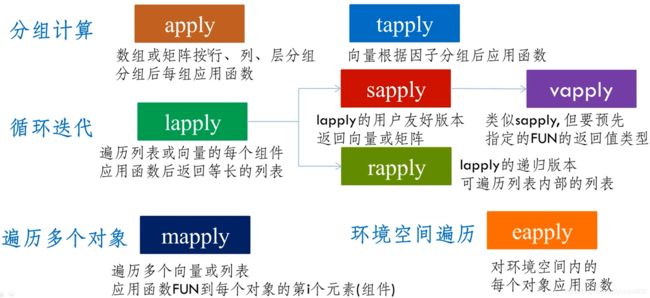
- apply函数族
-
- 分组计算--apply函数
-
- 二维
- 三维
- 分组计算--tapply函数
-
- 单因子分组
- 多因子分组
- 循环迭代--lapply函数
- 循环迭代--sapply 和 vapply
- 循环迭代--rapply函数
- 遍历多个对象--mapply函数
- eapply函数
- split函数
- by函数
- aggregate函数
-
-
- 函数形式
- 公式形式
-
- Cut函数
- factor函数和因子相关操作
-
-
- 因子相关的操作
-
apply函数族
分组计算–apply函数
apply(x, margin, fun, ...)
x:矩阵或者数组margin:一个向量,给出在哪几个维度上应用函数【1表示行,2表示列,3表示层】fun:要应用的函数…:传递给fun的额外参数
二维
> m<-matrix(1:12,nrow=3)
> m
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> apply(m,1,sum)
[1] 22 26 30
> apply(m,2,sum)
[1] 6 15 24 33
传递没有函数名的函数
> apply(m,1,function(x){
x=x+1
sum(x^2)
})
[1] 214 270 334
三维
> sales
, , A
Q1 Q2 Q3 Q4
apple 24 27 39 38
orange 29 32 23 35
banana 25 24 32 27
, , B
Q1 Q2 Q3 Q4
apple 32 20 26 39
orange 38 27 26 36
banana 32 32 30 20
apply(sales,3,function(x){
cat('x=\n')
print(x)
cat('------------------\n')
sum(x)
})
=======结果=======
x=
Q1 Q2 Q3 Q4
apple 24 27 39 38
orange 29 32 23 35
banana 25 24 32 27
------------------
x=
Q1 Q2 Q3 Q4
apple 32 20 26 39
orange 38 27 26 36
banana 32 32 30 20
------------------
A B
355 358
如果希望查看多个维度,比如在层的基础上对行或者列进行细分,需要引入维度向量,代码中1和3的顺序导致矩阵转置
apply(sales,c(3,1),function(x){
cat('x=\n')
print(x)
cat('------------------\n')
sum(x)
})
ps:也可以用rowSums就传入3即可
分组计算–tapply函数
tapply(x,index,fun,...)
- 将向量分组以后每组应用函数
x:被分组的向量index:一个因子或者多个因子的列表,每个因子都和向量x一样长fun:应用的函数...:传递给fun的额外参数
单因子分组
> height
[1] 181 169 163 175 160 183 169 181 181 175
> sex
[1] Female Female Female Male Male Male
[7] Female Female Male Female
Levels: Female Male
''' sex是因子,height是向量'''
> tapply(height,sex,function(x) c(min(x),mean(x),max(x)))
$Female
[1] 163 173 181
$Male
[1] 160.00 174.75 183.00
统计每组个数用table(x)就行
多因子分组
> score<-pmin(round(rnorm(50,mean=80,sd=9)),100)
> sex<-factor(sample(c('男','女'),50,replace=T,prob=c(0.3,0.7)))
> major<-factor(sample(c('经济','管理','统计','信息'),50,replace=T))
> tapply(score,list(sex,major),function(x) round(mean(x),digits = 2))
管理 经济 统计 信息
男 88.00 87.75 81.50 81.50
女 79.87 81.50 92.25 80.21
循环迭代–lapply函数
lapply(x,fun,...)
- 在列表或者向量的每个元素上应用函数
- 返回值是一个和x等长的列表
> lapply(c(1,2,3,4),function(x) x+1)
[[1]]
[1] 2
[[2]]
[1] 3
[[3]]
[1] 4
[[4]]
[1] 5
> data<-list(tag1=1:10,tag2=11:20,tag3=21:30)
> lapply(data,function(x) mean(x))
$tag1
[1] 5.5
$tag2
[1] 15.5
$tag3
[1] 25.5
循环迭代–sapply 和 vapply
sapply(x,fun,...)
返回向量或者矩阵,比lapply更加用户友好
> sapply(data,summary)
tag1 tag2 tag3
Min. 1.00 11.00 21.00
1st Qu. 3.25 13.25 23.25
Median 5.50 15.50 25.50
Mean 5.50 15.50 25.50
3rd Qu. 7.75 17.75 27.75
Max. 10.00 20.00 30.00
vapply(x,fun,fun.value,...)
vapply和sapply相似,但要预先预定fun函数的返回值类型,用起来更安全
注意必须传递FUN.VALUE=,在指定时只能将integer指定为double不能反过来。
> r1<-vapply(data,sum,FUN.VALUE=as.integer(0))
> r2<-vapply(data,sum,FUN.VALUE=0.0)
> r3<-vapply(data,sum,FUN.VALUE=3+4i)
> r1
tag1 tag2 tag3
55 155 255
> r2
tag1 tag2 tag3
55 155 255
> r3
tag1 tag2 tag3
55+0i 155+0i 255+0i
> typeof(r1)
[1] "integer"
> typeof(r2)
[1] "double"
循环迭代–rapply函数
rapply(object,f)
- lapply的递归版本,可以遍历列表内部的列表
- object:要遍历递归的列表
x <- list(tag1=1:5,
tag2=list(lab1=11:17,lab2=21:28),
tag3=31:36)
> rapply(x,sum)
tag1 tag2.lab1 tag2.lab2 tag3
15 98 196 201
遍历多个对象–mapply函数
mapply(FUN, ... , MoreArgs= NULL)
- 同时遍历多个向量和列表,应用函数FUN到每个向量或列表的第i个元素
- 第一个参数是FUN
- …:多个向量或列表
- MoreArgs:一个列表list用于传递给FUN的额外参数
实例【注意执行顺序】:
x <- 1:5
y <- c(16,20,8,14,30)
z <- c(100,200,300,400,500)
myfunc <- function(x,y,z,a,b){
cat("x=",x," y=",y," z=",z," a=",a," b=",b,"\n",sep="")
3*x + y/2 + z + a - b
}
> mapply(myfunc,x,y,z,MoreArgs=list(a=77,b=88))
x=1 y=16 z=100 a=77 b=88
x=2 y=20 z=200 a=77 b=88
x=3 y=8 z=300 a=77 b=88
x=4 y=14 z=400 a=77 b=88
x=5 y=30 z=500 a=77 b=88
[1] 100 205 302 408 519
根据执行顺序我们可以进行列表的横向拼接:
''' 实现tag1和tag2拼接'''
x<-list(tag1=1:5,tag2=11:16)
y<-list(tag1=6:10,tag2=17:22)
mapply(function(a,b){
cat("a=",a,"b=",b,"\n")
c(a,b) #连接
},x,y)
------------
a= 1 2 3 4 5 b= 6 7 8 9 10
a= 11 12 13 14 15 16 b= 17 18 19 20 21 22
$tag1
[1] 1 2 3 4 5 6 7 8 9 10
$tag2
[1] 11 12 13 14 15 16 17 18 19 20 21 22
eapply函数
eapply(env,FUN,...)
- 对环境空间env中的每个对象使用FUN函数
- env:遍历的环境空间。默认环境是
.GlobalEnv - FUN:使用的函数
eapply(.GlobalEnv,function(d){
cat("d=",d,"\n")
if(mode(d)=="numeric"){
sum(d)
}else{
NA
}
})
创建环境的方法:
myenv <- new.env() '''创建一个新的环境,名为myenv'''
myenv$x <- 101:110 '''在环境内创建对象x'''
myenv$y <- c(8,5,6,2,9)
myenv$z <- 21:27
split函数
- spllit(x, f)
– x:要分组的向量或者数据框
– f:因子或者因子列表
> height <- c(180,166,175,162,160,158,182,173)
> sex <- factor(c("M","F","M","F","F","F","M","F"))
> res <- split(height,sex)
> res
$F
[1] 166 162 160 158 173
$M
[1] 180 175 182
多因子分组
> ret <- split(score,list(major,sex))
- unsplit(value, f)
– value:向量或数据框作为组件的列表
> unsplit(res,sex)
[1] 180 166 175 162 160 158 182 173
对数据框分组
> s <- data.frame(major,sex,height,weight,score)
> head(s)
major sex height weight score
1 统计 男 180 76 88
2 经济 男 181 67 72
3 统计 女 166 54 68
4 统计 男 178 70 54
5 经济 女 157 45 79
6 经济 男 176 75 91
============
> split(s,s$major)
$管理
major sex height weight score
7 管理 女 170 60 69
8 管理 女 173 60 86
9 管理 女 167 58 66
......
多因子:
split(s,list(s$major,s$sex))
by函数
by(data,indices, fun, ...)
- 将函数应用到使用因子分组的子数据框上
data:通常是数据框dataframe,也可以是矩阵indices:因子或者因子的列表,长度nrow(data)fun:应用的函数,函数内的参数是子数据框...:额外参数- 函数返回值是by类对象
''' 数据准备'''
> head(s)
id major sex height weight score
1 ID01 管理 男 172 59 82
2 ID02 经济 女 162 58 85
3 ID03 统计 男 172 73 69
4 ID04 经济 女 159 51 82
5 ID05 经济 女 171 41 81
6 ID06 管理 女 168 49 76
''' sex major都是factor'''
---------------------------
ret <- by(s,s$sex,function(d){
''' d是分隔后的子数据框 '''
c(mean(d$height),mean(d$weight),mean(d$score))
})
---------------------------
> ret
s$sex: 男
[1] 174.42857 65.95238 78.80952
------------------------------------------------------------------------
s$sex: 女
[1] 162.94737 50.42105 77.31579
> class(ret) #by类的对象
[1] "by"
如果进行多因子分组,使用 list( s$sex, s$major)
aggregate函数
函数形式
aggregate(x, by, FUN, ...)
- 将数据框分组以后,每一列应用函数
- x:要分组的数据框【只能传递应用函数的列】
- by:因子的列表【必须是列表】,每个因子的长度和数据框的行数相同
- FUN:每列应用的函数
哪怕只有一个因子,也必须是list()
> aggregate(s[4:6],list(sex=s$sex),mean) #列表中给出组件名
sex height weight score
1 男 173.8750 69.68750 74.68750
2 女 164.4583 49.95833 81.54167
公式形式
aggregate(formula, data, FUN, ...)
- 使用公式给出数据框中要被分组的列和用于创建分组的列
formula:公式,例如cbind(y1,y2)~x1+x2,左边是要被分组的一个或者多个数值型列;右边是创建分组的一个或者多个因子列【用+连接】data:数据框subset:可选向量,给出要使用的观测的子集
> aggregate(height~sex,data=s,
function(x) round(mean(x),1),subset = s$score>=85)
sex height
1 男 171.7
2 女 164.9
> #基于专业和性别分组统计身高、体重、成绩的均值
> aggregate(cbind(height,weight,score)~major+sex,data=s,
+ function(x) round(mean(x),1))
major sex height weight score
1 管理 男 175.3 69.6 76.1
2 经济 男 173.8 72.7 70.7
3 统计 男 170.7 64.0 79.3
4 管理 女 163.8 46.9 77.0
5 经济 女 163.8 52.1 83.4
6 统计 女 166.1 51.4 85.3
Cut函数
cut(x,breaks,labels,include.lowest = FALSE, right = TRUE,
ordered_result = FALSE)
- 作用:将数值型向量分成多段并转化成因子,每个分段对应一个因子
x:被分段的数值型向量breaks:分段点向量,要同时给出中间和两端的向量labels:产生的因子各个水平的名称include.lowest:默认是左开右闭的区间,因此最小值不包含,传递TRUE参数表示包含最小值right:指明各个区间是否为右闭,默认TRUE,传递FALSE为左闭右开ordered_result:传递TRUE则产生有序因子
> table(score)
score
0 50 56 58 59 60 61 62 64 66 67 68 69 70 71 72 73 74 75
3 1 1 1 2 2 1 1 1 5 1 4 8 5 5 4 4 2 2
76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 95 96 100
5 7 5 6 4 6 4 3 5 3 2 4 3 3 2 2 1 1 1
rf <- cut(score,breaks=c(0,60,70,85,100),
labels=c("差","中","良","优"),
include.lowest=T,right=F,ordered_result=T)
'''
ordered_result=T
表示因子里面按照给出的顺序排列,即变量是顺序分类变量
'''
> class(rf)
[1] "ordered" "factor"
> rc<-table(rf)
> rc
rf
差 中 良 优
8 23 67 22
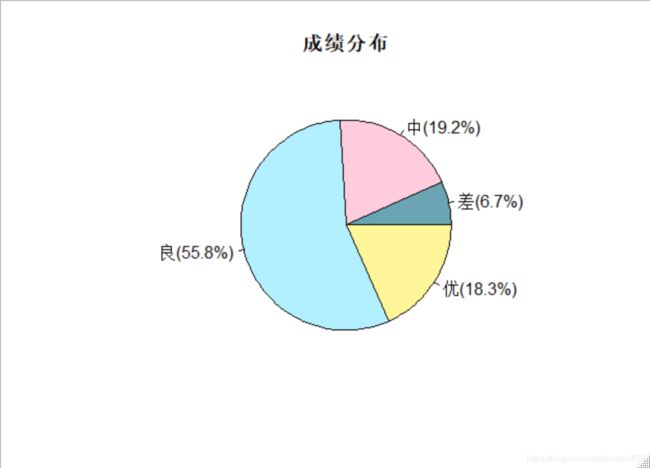
> lbs <- paste0(names(rc),"(",round(100*rc/sum(rc),1),"%)")
> lbs
[1] "差(6.7%)" "中(19.2%)" "良(55.8%)" "优(18.3%)"
> pie(rc,col=c('#6BA4B3','#FFCCDE','#B3F0FF','#FFF699'),labels=lbs,main="成绩分布")
factor函数和因子相关操作
factor(x, levels, labels, ordered)
- 创建因子,即分类变量
x:向量levels:可选,因子的水平,可以设置x中元素之外的值,可用于指定有序因子中水平的顺序labels:可选,各个水平的标签ordered:是否产生有序因子,默认FALSE
> data <- sample(c("F","M"),20,replace=T,prob=c(0.6,0.4))
> table(data)
data
F M
12 8
最简单的操作方法:
> sex <- factor(data)
> sex
[1] M F F M M M F F F F F M M F F F M M F F
Levels: F M
如果需要加入新的类别,但目前没有该类别,需要在levels里面指明:
sex<-factor(data,levels=c("F","M","U"))
sex
sex[3] <- "U" # 这样才不会报错
最复杂的情况:
> sex<-factor(data,levels=c("F","M","U"),
labels=c("女","男","未知"), ordered=TRUE)
> sex
[1] 男 女 女 男 男 男 女 女 女 女 女 男 男 女 女 女 男 男 女 女
Levels: 女 < 男 < 未知
因子相关的操作
| 操作 | 含义 |
|---|---|
| levels(f) | 获得因子的各个水平 |
| levels(f) <- value | 给因子增加水平 |
| nlevels(f) | 获得因子中水平的个数 |
| droplevels(f) | 删除因子中未使用的水平 |
| as.character(f) | 将因子转换为字符串向量 |
| as.integer(f) | 将因子转换为整数向量 |
> levels(sex)
[1] "F" "M"
> nlevels(sex)
[1] 2
> as.character(sex)
[1] "男" "女" "女" "男" "男" "男" "女" "女" "女" "女" "女" "男" "男" "女"
[15] "女" "女" "男" "男" "女" "女"
> as.integer(sex)
[1] 2 1 1 2 2 2 1 1 1 1 1 2 2 1 1 1 2 2 1 1
droplevels实例:
> levels(sex) <- c("F","M","U")
> sex
[1] M F F M M M F F F F F M M F F F M M F F
Levels: F M U
'''数据中没有U,因此drop掉 '''
> droplevels(sex)
[1] M F F M M M F F F F F M M F F F M M F F
Levels: F M