大数据--MapReduce学习笔记
一、MapReduce简介
- MapReduce:2004年 Google paper中提出。
- 一个用于分布式数据处理的编程模型和运行环境。适合处理各种结构化和非结构化的数据。
- HDFS(hadoop 分布式文件系统)是MapReduce的基础。
- 分布式系统的设计原则
moving computation is more cheaper than moving data。(现场办公)
-
Map
示例:我们要数图书馆中的所有的书,你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
-
Reduce
现在我们到一起,把各自统计的数报给管理员,管理员把所有人的统计数加在一起,这就是“Reduce”。
-
Hadoop生态系统架构

- MapReduce 部署视图
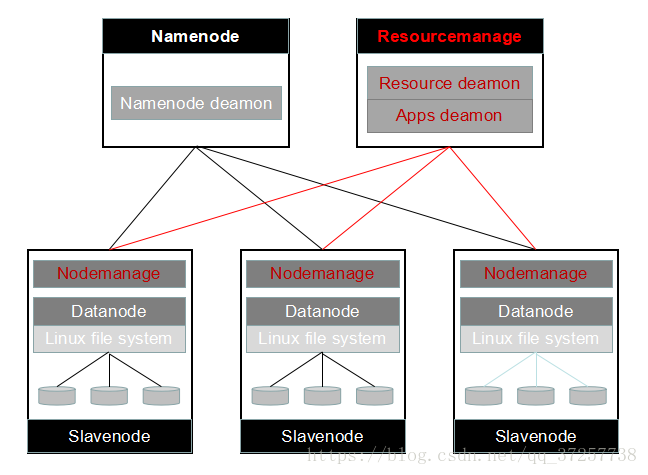
MR是和HDFS一样的master/slave模式的星型结构,MR的Nodemanage必须和HDFS的datanode部署在同一节点上。
- Map Reduce运行视图
MR的几个重要对象:

(1)、MR client:和用户交互,和MR集群交互。
(2)、Application:MR任务,Map算法、Reduce算法。
(3)、App config:MR任务相关配置参数。

(1)、Resourcemanage:
Resource deamon,整个MR集群的资源管理,主要是CPU、内存、网络。
Applications deamon,整个集群中MR任务(application)的调度监控,但只调度app master。
(1)、Nodemanage:对应HDFS的data node,负责本节点计算资源的监控,和Resourcemanage保持心跳。
(2)、Application master:一个map reduce任务内部的管理,task的启动,监控。
(3)、task:一个任务(app)被分解成若干task来执行具体的map reduce算法。分为map task和reduce task两类。通常,一个task运行在一个jvm内。
二、Map Reduce原理
Map、Shuffle和Reduce每一步都有key-value对作为输入和输出。
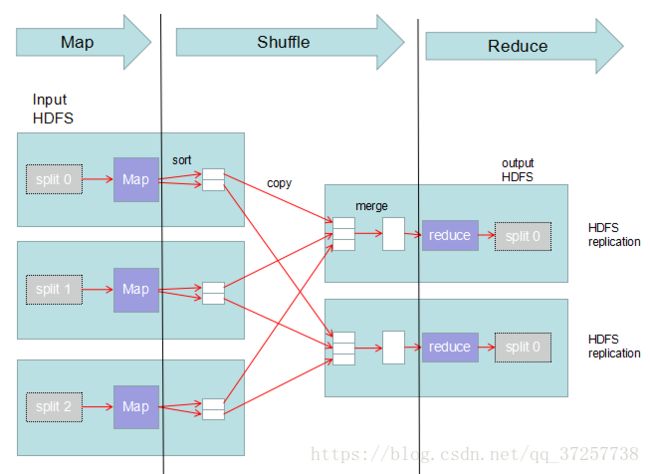
示例:处理一批有关天气的数据,计算每年的最高温度。
数据其格式如下:
1、按照ASCII码存储,每一行一条记录
2、每一行字符从0开始计数,第15个到第18个字符为年
3、第25个到第29个字符为温度,其中第25位是符号+/-

Map执行过程:
1、输入数据拆分(一般按block拆分)
2、map算法运行
3、map结果输出到本地硬盘
Map的输入(key,value)如下:
第一个map:
(0,0067011990999991950051507+0000+)
(1,0043011990999991950051518-0011+)
第二个map:
(2,0043012650999991949032412+0111+)
(3,0043012650999991949032418+0078+)
(4,0067011990999991937051507+0001+)
第三个map:
(5,0043011990999991937051512-0002+)
(6,0043011990999991945051518+0001+)
由map任务进行计算,map过程中:通过对每一行字符串的解析,得到年-温度的键值对(key-value)作为输出:
Map输出的(key,value)如下:
(1950,0)
(1950,-11)
(1949,111)
(1949,78)
(1937,1)
(1937,-2)
(1945,1)
Map的输出就是Shuffle阶段的输入,shuffle阶段分排序、合并两个过程
1、排序(按年份,年份相同的随机排)
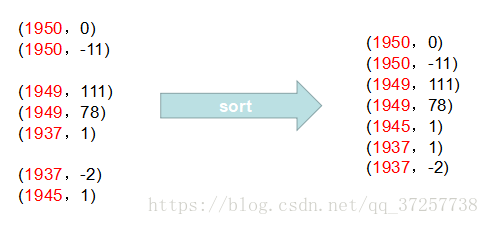
2、合并+分区(分区:与reduce对应)

Shuffle的输出就是reduce阶段的输入,reduce会根据shuffle输出的结果数据进行分区,reduce根据上述例子中的数据分为两个区,分别给两个reduce任务。
(1950,<0,-11>)
(1949,<111,78>)
(1945,1)
(1937,<1,-2>)
在reduce过程中,在列表中选择出最大的温度,将年-最大温度的(key,value)作为输出,输出至HDFS的两个文件中:
(1950,0)
(1949,111)
(1945,1)
(1937,1)
Map Reduce ,就是

Map task 运行分析
1、从输入的split中读取记录(K1,V1)
2、执行用户编写的map算法,生成(K2,V2)
3、(K2、V2)输出到本地磁盘
(1)、首先输出到内存
(2)、通过sort和merge生成(K2,list
(3)、输出到本地硬盘(多个spill文件)
4、spill文件继续sort和merge,生成map结果文件及索引文件
5、map结束
(1)、清理spill文件
(2)、告诉Application master,map结束。
注意:
(1)、Without reduce task?? Output format write to HDFS
(2)、Map result file clear?? Job finished
为什么搞这么复杂?
目的:在尽量减少磁盘IO情况下,对map task的输出进行partition 和sort ------这是Reduce的要求。
限制:内存buffer不能无限大。
优化:
1、map执行结果先输出为split文件,然后merge
2、用map输出数据的key进行排序
3、combiner(local reduce),减少reduce shu数据量
4、map输出结果文件压缩
reduce task 运行分析
很多阶段都可以并行进行
1、向Application master 查询结束的map task。
2、从结束的map task 节点上下载属于自己的数据(from map result file)下载到本地文件系统。(K2,list
3、(K2,list
4、用户reduce 算法执行,生成(K3,V3)格式数据。
5、reduce 执行结果写入HDFS,(K3,V3)格式。
6、通知Application master ,reduce task结束。
reduce task 任务和map task 任务一样复杂
目的:提高效率,在尽量减少磁盘IO情况下,对多个map task 的输出进行merge和sort ------这个是reduce 的要求。
限制:内存buffer不能无限大。
处理小文件问题:
1、小文件问题:
(1)、meta-data太多,占namenode内存。
(2)、map task任务太多。
2、处理方法:
(1)、task JVM reuse(资源重用)
(2)、存档文件(只能解决分布式文件系统存储小文件问题,不能解决MapReduce处理小文件问题)
HAR files: Hadoop Archives

(3)、分布式文件系统提供了一种MapReduce处理小文件的方法,MapReduce提供了一个名为CombineFileInputFormat的接口解决MapReduce处理小文件的方法。CombineFileInputFormat接口允许一个MapReduce任务处理多个小文件。
(4)、hadoop还提供了一种方法是 SequenceFile,SequenceFile可以存储多个小文件,像HAR文档一样。同时SequenceFile类型的文件在通过MapReduce处理的时候,一个SequenceFile文件可以启动一个MapReduce任务进行处理。可避免因小文件过多而启动多个MapReduce任务问题。
