Elasticsearch 的使用Demo
**
Elasticsearch 的使用Demo
**
Elasticsearch项目地址:
https://github.com/looly/elasticsearch-definitive-guide-cn
http://git.oschina.net/loolly/elasticsearch-definitive-guide-cn
1. 安装Elasticsearch
唯一的要求是安装官方新版的Java,地址:www.java.com
你可以从 elasticsearch.org/download 下载Elasticsearch。
进入elasticsearch/bin目录,执行文件elasticsearch.bat

或者cmd输入
elasticsearch
启动后
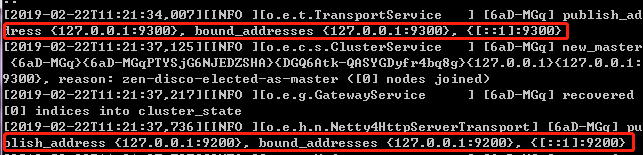
可以看到绑定了两个端口:
9300:Java程序访问的端口
9200:浏览器、postman访问的端口
我们在浏览器中访问:http://127.0.0.1:9200
{
"name" : "6aD-MGq",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "Z2LQKB3UQl2Ka0bNHmIz0w",
"version" : {
"number" : "5.6.13",
"build_hash" : "4d5320b",
"build_date" : "2018-10-30T19:05:08.237Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}
浏览器显示如上,说明Elasticsearch已经安装成功了
2. 安装Head插件
使用直观方便的Head 插件图形化界面来实现 Elasticsearch 的日常管理
下载 head 插件:https://github.com/mobz/elasticsearch-head
解压到任意目录,但是要和 elasticsearch 的安装目录区别开。
注意:es5以上版本安装head需要安装node和grunt,所以我们先安装node和grunt
第一步:从地址:https://nodejs.org/en/download/ 下载
这里选择的是Windows Installer(.msi) 64-bit的版本,一直next完成安装。

第二步:安装完成用cmd进入安装目录执行 node -v可查看版本号

能看到版本号说明node安装成功
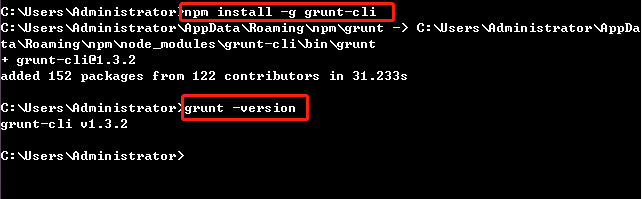
第三步:将 grunt 安装为全局命令 。Grunt 是基于 Node.js 的项目构建工具,它可以自动运行你所设定的任务。
执行 npm install -g grunt-cli 安装grunt ,安装完成后执行grunt -version查看是否安装成功,会显示安装的版本号
2.1. 配置运行
第一步:进入Elasticsearch安装目录下的config目录,修改elasticsearch.yml文件.在文件的末尾加入以下代码:

然后去掉network.host: 192.168.0.1的注释符号(#)并改为network.host: 0.0.0.0
去掉http.port的注释符号(#)
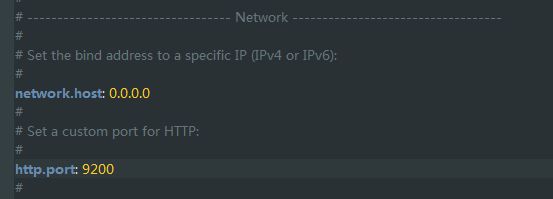
去掉cluster.name,node.name的注释符号(#)

第二步:双击elasticsearch.bat重启Elasticsearch
第三步:修改elasticsearch-head-master\Gruntfile.js
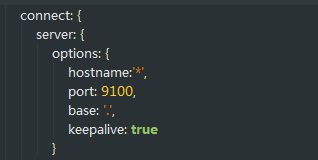
在对应的位置加上hostname:’*’
第四步:在 /elasticsearch-head-master打开cmd命令行窗口执行
npm install
然后执行
grunt server
或者
npm run start
运行head插件,如果运行不成功建议重新安装grunt。
然后打开浏览器访问:http://127.0.0.1:9100 成功结果如下:

3. 安装Ik分词器
ElasticSearch 默认采用的分词器, 是单个字分词 ,效果很差 ,所以我们需要安装一个更实用的分词器,这里采用IK分词器
注意!IK分词器的版本必须和Elasticsearch的版本一致!此处使用的是5.6.13版本
源码地址:https://github.com/medcl/elasticsearch-analysis-ik/tree/6.2.x
架包地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
第一步:先将其解压,将解压后的 elasticsearch 文件夹重命名文件夹为 ik
第二步:将 ik 文件夹拷贝到 elasticsearch/plugins 目录下。
第三步:重新启动,显示如下即说明成功加载 IK 分词器。
3.1. IK 分词器扩展词典
进入 elasticsearch/plugins/ik/config 目录
新建扩展词典文件,拓展名为 .dic,输入自定义扩展词
然后在ik/config目录下修改IKAnalyzer.cfg.xml
标签内填入自定义扩展词典文件名

4. SpringBoot整合Elasticsearch
首先我们要新建一个SpringBoot项目,再进行Elasticsearch的整合。
pom依赖:
4.0.0
elasticsearchProject
elasticsearchProject
1.0-SNAPSHOT
org.springframework.boot
spring-boot-starter-parent
2.0.4.RELEASE
UTF-8
UTF-8
1.8
org.springframework.boot
spring-boot-starter
org.springframework.boot
spring-boot-starter-data-elasticsearch
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-maven-plugin
application.properties文件配置:
Elasticsearch配置文件(必须)
该配置和Elasticsearch的elasticsearch.yml中的配置信息有关
spring.data.elasticsearch.cluster-name=my-application
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
Elasticsearch的elasticsearch.yml中的配置:
======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: my-application
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-1
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0
#
# Set a custom port for HTTP:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
#discovery.zen.ping.unicast.hosts: ["host1", "host2"]
#
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1):
#
#discovery.zen.minimum_master_nodes: 3
#
# For more information, consult the zen discovery module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
4.1 索引操作
4.1.1. 创建索引和映射
SpringBoot-data-elasticsearch提供了面向对象的方式操作elasticsearch
业务:创建一个商品对象,有这些属性:
id,title,category,brand,price,图片地址
在SpringDataElasticSearch中,只需要操作对象,就可以操作elasticsearch中的数据
【实体类】
public class Item {
private Long id;
private String title; //标题
private String category;// 分类
private String brand; // 品牌
private Double price; // 价格
private String images; // 图片地址
}
【映射—注解】
Spring Data通过注解来声明字段的映射属性,有下面的三个注解:
@Document 作用在类,标记实体类为文档对象,一般有两个属性
indexName:对应索引库名称
type:对应在索引库中的类型
shards:分片数量,默认5
replicas:副本数量,默认1
@Id 作用在成员变量,标记一个字段作为id主键
@Field 作用在成员变量,标记为文档的字段,并指定字段映射属性:
type:字段类型,是枚举:FieldType,可以是text、long、short、date、integer、object等
text:存储数据时候,会自动分词,并生成索引
keyword:存储数据时候,不会分词建立索引
Numerical:数值类型,分两类
基本数据类型:long、interger、short、byte、double、float、half_float
浮点数的高精度类型:scaled_float
需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时还原。
Date:日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
index:是否索引,布尔类型,默认是true
store:是否存储,布尔类型,默认是false
analyzer:分词器名称,这里的ik_max_word即使用ik分词器
例如:
@Document(indexName = "item",type = "docs", shards = 5, replicas = 1)
public class Item {
/**
* @Id注解必须是springframework包下的org.springframework.data.annotation.Id
*/
@Id
private Long id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String title; //标题
@Field(type = FieldType.Keyword)
private String category;// 分类
@Field(type = FieldType.Keyword)
private String brand; // 品牌
@Field(type = FieldType.Double)
private Double price; // 价格
@Field(index = false, type = FieldType.Keyword)
private String images; // 图片地址
}
【创建索引】
ElasticsearchTemplate中提供了创建索引的API:

根据类的信息自动生成(也可以手动指定indexName和Settingsa)
【映射】
映射相关的API:

根据类的字节码信息(注解配置)来生成映射(或者手动编写映射)
【启动类】
@SpringBootApplication
public class EsDemoApplication {
public static void main(String[] args) {
SpringApplication.run(EsDemoApplication.class,args);
}
}
【测试类】
@RunWith(SpringRunner.class)
@SpringBootTest(classes = EsDemoApplication.class)
public class EsDemoApplicationTests {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Test
public void testCreateIndex() {
elasticsearchTemplate.createIndex(Item.class);
}
}
运行testCreateIndex(),索引创建成功后打开elasticsearch-head-master即可看到创建的新索引:

同样可以根据类名或索引名删除。

4.2. 数据处理
4.2.1. Repository接口
Spring Data 允许自动根据方法名或类的信息进行CRUD操作。只要定义接口,继承Repository提供的接口,就能具备各种基本的CRUD功能。
public interface ItemRepository extends ElasticsearchRepository{
}
4.2.2. 新增对象(批量)
测试类注入ItemRepository,写一个方法:
@Autowired
private ItemRepository itemRepository;
@Test
public void testSave(){
Item item = new Item(1L, "小米9", " 手机",
"小米", 2999.00, "http://image.baidu.com/13123.jpg");
itemRepository.save(item);
}
运行后 在127.0.0.1:9100 中可以看到数据:

【批量新增】
@Test
public void testSaveList(){
List- list = new ArrayList<>();
list.add(new Item(2L, "华为Mate20", " 手机", "华为", 3699.00, "http://image.baidu.com/13123.jpg"));
list.add(new Item(3L, "苹果X", " 手机", "苹果", 8999.00, "http://image.baidu.com/13123.jpg"));
itemRepository.saveAll(list);
}
运行后

4.2.3. 修改
elasticsearch中本没有修改,它的修改原理是该是先删除在新增修改和新增是同一个接口,区分的依据就是标注了@Id 的字段——id。
修改id为1 的数据:
@Test
public void update(){
Item item = new Item(1L, "小米笔记本", " 电脑",
"小米", 5499.00, "http://image.baidu.com/13123.jpg");
itemRepository.save(item);
}
结果变化:

4.3. 查询
4.3.1. 基本查询
ElasticsearchRepository提供了一些基本的查询方法:

例:查询所有
@Test
public void query(){
Iterable- list = this.itemRepository.findAll(Sort.by("price").ascending());
for (Item item : items) {
System.out.println(item);
}
}
对某字段排序查找所有 Sort.by(“price”).descending() 降序
Sort.by(“price”).ascending():升序

4.3.2. 自定义方法
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。
比如:你的方法名叫做:findByTitle,那么它就知道你是根据title查询,然后自动帮你完成,无需写实现类。
当然,方法名称要符合一定的约定:

例如,我们可以按照价格区间查询,定义这样的一个方法

不需要写实现类,然后我们直接去运行:
@Test
public void queryByPriceBetween(){
List- list = this.itemRepository.findByPriceBetween(4000.00, 6000.00);
for (Item item : list) {
System.out.println("item = " + item);
}
}
只查到一条符合的数据,证明有效:
![]()
4.3.3. 自定义查询
matchQuery:
@Test
public void testQuery(){
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withQuery(QueryBuilders.matchQuery("title", "小米"));
Page- page = itemRepository.search(queryBuilder.build());
long totalElements = page.getTotalElements();
System.out.println("获取的总条数:"+totalElements);
for (Item item : page) {
System.out.println(item);
}
}
NativeSearchQueryBuilder:Spring提供的一个查询条件构建器,帮助构建json格式的请求体
QueryBuilders.matchQuery(“title”, “小米”):利用QueryBuilders来生成一个查询。
QueryBuilders提供了大量的静态方法,用于生成各种不同类型的查询:

Page:默认是分页查询,因此返回的是一个分页的结果对象,包含属性:
totalElements:总条数
totalPages:总页数
Iterator:迭代器,本身实现了Iterator接口,因此可直接迭代得到当前页的数据
其它属性:

查询的结果如下:

还有更多的查询方式:
termQuery:功能更强大,除了匹配字符串以外,还可以匹配int/long/double/float/…
@Test
public void testTermQuery(){
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
builder.withQuery(QueryBuilders.termQuery("price",3699.0));
// 查找
Page- page = this.itemRepository.search(builder.build());
for(Item item:page){
System.out.println(item);
}
}
Boolean查询:
@Test
public void testBooleanQuery(){
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
builder.withQuery(
QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("title","华为"))
.must(QueryBuilders.matchQuery("brand","华为")));
// 查找
Page- page = this.itemRepository.search(builder.build());
for(Item item:page){
System.out.println(item);
}
}
模糊查询:
@Test
public void testFuzzyQuery(){
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
builder.withQuery(QueryBuilders.fuzzyQuery("title","Mate",));
Page- page = this.itemRepository.search(builder.build());
for(Item item:page){
System.out.println(item);
}
}
4.3.4. 分页查询
利用NativeSearchQueryBuilder 可以方便的实现分页:
@Test
public void queryByPage(){
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 添加基本分词查询
queryBuilder.withQuery(QueryBuilders.matchQuery("category","手机"));
// 分页:
int pageNum = 0;
int pageSize = 5;
queryBuilder.withPageable(PageRequest.of(pageNum, pageSize));
// 搜索,获取结果
Page- page = itemRepository.search(queryBuilder.build());
// 总条数
long total = page.getTotalElements();
System.out.println("总条数 = " + total);
// 总页数
System.out.println("总页数 = " + page.getTotalPages());
// 当前页
System.out.println("当前页:" + page.getNumber());
// 每页大小
System.out.println("每页大小:" + page.getSize());
for (Item item : page) {
System.out.println(item);
}
}
结果:

可以发现Elasticsearch的分页页码是从0开始的。
4.3.5. 排序
排序也通用通过NativeSearchQueryBuilder完成:
@Test
public void queryWithSort(){
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//添加基本查询条件
queryBuilder.withQuery(QueryBuilders.matchQuery("category","手机"));
// 排序
queryBuilder.withSort(SortBuilders.fieldSort("price").order(SortOrder.DESC));
// 搜索,获取结果
Page- items = this.itemRepository.search(queryBuilder.build());
// 总条数
long total = items.getTotalElements();
System.out.println("总条数 = " + total);
for (Item item : items) {
System.out.println(item);
}
}
结果如下:

4.4. 聚合
聚合可以让我们极其方便的实现对数据的统计、分析。例如:
什么品牌的手机最受欢迎?
这些手机的平均价格、最高价格、最低价格?
这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
Elasticsearch中的聚合,包含多种类型,最常用的两种,一个叫桶,一个叫度量:
桶(bucket)
桶的作用,是按照某种方式对数据进行分组,每一组数据在ES中称为一个桶,例如我们根据国籍对人划分,可以得到中国桶、英国桶,日本桶……或者我们按照年龄段对人进行划分:0-10,10-20,20-30,30-40等。
Elasticsearch中提供的划分桶的方式有很多:
Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组
Histogram Aggregation:根据数值阶梯分组,与日期类似
Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组
Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按段分组
……
综上所述,我们发现bucket aggregations 只负责对数据进行分组,并不进行计算,因此往往bucket中往往会嵌套另一种聚合:metrics aggregations即度量
度量(metrics)
分组完成以后,我们一般会对组中的数据进行聚合运算,例如求平均值、最大、最小、求和等,这些在ES中称为度量
比较常用的一些度量聚合方式:
Avg Aggregation:求平均值
Max Aggregation:求最大值
Min Aggregation:求最小值
Percentiles Aggregation:求百分比
Stats Aggregation:同时返回avg、max、min、sum、count等
Sum Aggregation:求和
Top hits Aggregation:求前几
Value Count Aggregation:求总数
……
注意:在ES中,需要进行聚合、排序、过滤的字段其处理方式比较特殊,因此不能被分词。这里我们将color和make这两个文字类型的字段设置为keyword类型,这个类型不会被分词,将来就可以参与聚合。
4.4.1. 聚合为桶
@Test
public void testAgg(){
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 无查询关键词
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null));
// 1、添加一个新的聚合,聚合类型为terms,聚合名称为brands,聚合字段为brand
queryBuilder.addAggregation(AggregationBuilders.terms("brands").field("brand"));
// 2、查询,需要把结果强转为AggregatedPage类型
AggregatedPage- aggPage = (AggregatedPage
- ) this.itemRepository.search(queryBuilder.build());
// 3、解析
// 3.1、从结果中取出名为brands的那个聚合,
// 因为是利用String类型字段来进行的term聚合,所以结果要强转为StringTerm类型
StringTerms agg = (StringTerms) aggPage.getAggregation("brands");
// 3.2、获取桶
List
buckets = agg.getBuckets();
// 3.3、遍历
for (StringTerms.Bucket bucket : buckets) {
// 3.4、获取桶中的key(品牌名称)
System.out.println(bucket.getKeyAsString());
// 3.5、获取桶中的文档数量
System.out.println(bucket.getDocCount());
}
}
获得的结果为:

其中关键的API:
AggregationBuilders:聚合的构建工厂类。
所有聚合都由这个类来构建,我们可以看到他的方法:

主要包括:
ValueCountBuilder vcb= AggregationBuilders.count("count_uid").field("uid");
(2)去重统计某个字段的数量(有少量误差)
CardinalityBuilder cb= AggregationBuilders.cardinality("distinct_count_uid").field("uid");
(3)聚合过滤
FilterAggregationBuilder fab= AggregationBuilders.filter("uid_filter").filter(QueryBuilders.queryStringQuery("uid:001"));
(4)按某个字段分组
TermsBuilder tb= AggregationBuilders.terms("group_name").field("name");
(5)求和
SumBuilder sumBuilder= AggregationBuilders.sum("sum_price").field("price");
(6)求平均
AvgBuilder ab= AggregationBuilders.avg("avg_price").field("price");
(7)求最大值
MaxBuilder mb= AggregationBuilders.max("max_price").field("price");
(8)求最小值
MinBuilder min= AggregationBuilders.min("min_price").field("price");
(9)按日期间隔分组
DateHistogramBuilder dhb= AggregationBuilders.dateHistogram("dh").field("date");
(10)获取聚合里面的结果
TopHitsBuilder thb= AggregationBuilders.topHits("top_result");
(11)嵌套的聚合
NestedBuilder nb= AggregationBuilders.nested("negsted_path").path("quests");
(12)反转嵌套
AggregationBuilders.reverseNested("res_negsted").path("kps ");
AggregatedPage:聚合查询的结果类。它是Page的子接口:
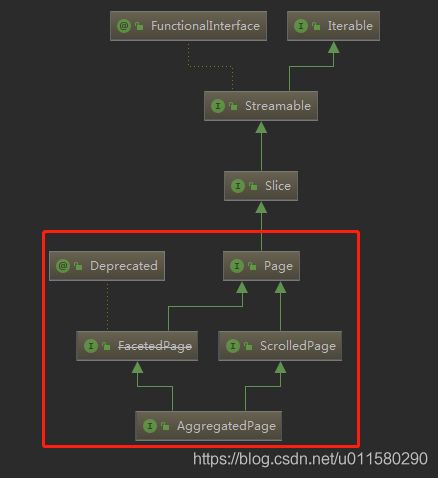
AggregatedPage在Page功能的基础上,拓展了与聚合相关的功能,它其实就是对聚合结果的一种封装。

而返回的结果都是Aggregation类型对象,不过根据字段类型不同,又有不同的子类表示

4.4.2. 嵌套聚合,求平均值
@Test
public void testSubAgg(){
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 无查询关键词
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null));
// 1 添加一个新的聚合,聚合类型为terms,聚合名称为brands,聚合字段为brand
// 在品牌聚合桶内进行嵌套聚合,求平均值
queryBuilder.addAggregation(AggregationBuilders.terms("brands").field("brand")
.subAggregation(AggregationBuilders.avg("priceAvg").field("price")));
// 2 查询,需要把结果强转为AggregatedPage类型
AggregatedPage- aggPage = (AggregatedPage
- ) this.itemRepository.search(queryBuilder.build());
// 3 解析
// 3.1 从结果中取出名为brands的那个聚合,
// 因为是利用String类型字段来进行的term聚合,所以结果要强转为StringTerm类型
StringTerms agg = (StringTerms) aggPage.getAggregation("brands");
// 3.2 获取桶
List
buckets = agg.getBuckets();
// 3.3 遍历
for (StringTerms.Bucket bucket : buckets) {
// 3.4 获取桶中的key,即品牌名称 和桶中的文档数量
System.out.println(bucket.getKeyAsString() + ",共" + bucket.getDocCount() + "台");
// 3.5 获取子聚合结果:
InternalAvg avg = (InternalAvg) bucket.getAggregations().asMap().get("priceAvg");
System.out.println("平均售价:" + avg.getValue());
}
}
结果为:

5. ElasticSearch 与 MySQL数据同步
5.1. logstash
Logstash 是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,
并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件。
下载地址(5.6.13版本):https://artifacts.elastic.co/downloads/logstash/logstash-5.6.13.zip
解压,进入 bin 目录,控制台输入字符
logstash -e 'input { stdin { } } output { stdout {} } '
随后有类似日志

stdin,表示输入流,指从键盘输入
stdout,表示输出流,指从显示器输出
命令行参数:
-e 执行
–config 或 -f 配置文件,后跟参数类型可以是一个字符串的配置或全路径文件名或全路径
路径(如:/etc/logstash.d/,logstash 会自动读取/etc/logstash.d/目录下所有*.conf 的文
本文件,然后在自己内存里拼接成一个完整的大配置文件再去执行)
5.2. MySQ数据导入ElasticSearch
(1)在 logstash-5.6.8 安装目录下创建文件夹 mysqletc (名称随意)
(2)文件夹下创建 mysql.conf (名称随意) ,内容如下:
input {
jdbc {
# mysql 数据库链接,shop为数据库名
jdbc_connection_string =>"jdbc:mysql://localhost:3306/pdm?characterEncoding=UTF8"
# db账号密码
jdbc_user => "root"
jdbc_password => "root"
# mysql的驱动包(这里已经拷贝至logstash-5.6.13安装目录的mysqletc下)
jdbc_driver_library => "E:/logstash-5.6.13/mysqletc/mysql-connector-java-5.1.44.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
# 执行的sql 文件路径+名称
statement_filepath => "E:/logstash-5.6.13/mysqletc/dataType.sql"
#定时字段 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新(测试结果,不同的话请留言指出)
schedule => "* * * * *"
}
}
output {
elasticsearch {
#ESIP 地址与端口
hosts => "localhost:9200"
#ES 索引名称(自己定义的)
index => "pdmdatatype"
#自增 ID 编号
document_id => "%{id}"
document_type => "DataType"
}
#以 JSON 格式输出
stdout {
codec => json_lines
}
}
注意!保证文件采用UTF-8编码,最好删除中文注释,否则有可能导致无法读取
(3)将 mysql 驱动包 mysql-connector-java-5.1.46.jar 拷贝至 e:/logstash-
5.6.13/mysqletc/ 下 。e:/logstash-5.6.13 是你的安装目录
然后进入bin目录 命令符控制台输入:
logstash -f ../mysqletc/mysql.conf
显示

(每分钟会进行一次查询 更新到Elasticsearch)
然后打开浏览器,进入127.0.0.1:9100 “数据浏览”标签可以看到从数据导入的数据:

6. 实例
依赖
4.0.0
com.example
testelasticaearch
0.0.1-SNAPSHOT
jar
org.springframework.boot
spring-boot-starter-parent
2.1.1.RELEASE
UTF-8
UTF-8
1.8
org.springframework.boot
spring-boot-starter-data-elasticsearch
org.springframework.boot
spring-boot-starter-web
net.java.dev.jna
jna
3.0.9
org.springframework.boot
spring-boot-starter-test
test
org.projectlombok
lombok
1.18.4
org.springframework.boot
spring-boot-maven-plugin
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
true
spring-milestones
Spring Milestones
https://repo.spring.io/milestone
false
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
true
spring-milestones
Spring Milestones
https://repo.spring.io/milestone
false
结构

代码
Commom
ArticleSearchRepository
package com.demo.common;
import com.demo.pojo.Article;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface ArticleSearchRepository extends ElasticsearchRepository {
public Article queryArticleById(Long id);
}
Controller
ArticleController
package com.demo.controller;
import com.demo.pojo.Article;
import com.demo.service.ArticleService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 文章Controller
*/
@RestController
@RequestMapping("/article")
public class ArticleController {
@Autowired
private ArticleService articleService;
@RequestMapping("/add")
public String add(Article article) throws Exception {
try{
articleService.add(article);
return "success";
}catch(Exception e){
return "fail";
}
}
@RequestMapping("/delete")
public String delete(Article article) throws Exception {
try{
articleService.delete(article);
return "success";
}catch(Exception e){
return "fail";
}
}
@RequestMapping("/update")
public String update(Article article) throws Exception {
try{
articleService.update(article);
return "success";
}catch(Exception e){
return "fail";
}
}
@RequestMapping("/queryArticleById")
public Article queryArticleById(Long id) throws Exception {
try{
return articleService.queryArticleById(id);
}catch(Exception e){
return null;
}
}
}
Pojo
Article
package com.demo.pojo;
import lombok.Getter;
import lombok.Setter;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import java.io.Serializable;
import java.util.Date;
@Getter
@Setter
@Document(indexName="article",type="docs")
public class Article implements Serializable {
@Id
private Long id;
/**
* 标题
*/
private String title;
/**
* 内容
*/
private String content;
/**
* 发布时间
*/
private Date postTime;
/**
* 作者
*/
private String author;
public Article() {
}
public Article(Long id, String title, String content, Date postTime, String author) {
this.id = id;
this.title = title;
this.content = content;
this.postTime = postTime;
this.author = author;
}
@Override
public String toString() {
return "Article{" +
"id=" + id +
", title='" + title + '\'' +
", content='" + content + '\'' +
", postTime=" + postTime +
", author='" + author + '\'' +
'}';
}
}
Service
ArticleService
package com.demo.service;
import com.demo.pojo.Article;
/**
* 文章service
*/
public interface ArticleService {
//增加
public String add(Article article);
//删除
public String delete(Article article);
//局部更新
public String update(Article article);
//查询
public Article queryArticleById(Long id);
}
impl.ArticleServiceImpl
package com.demo.service.impl;
import com.demo.common.ArticleSearchRepository;
import com.demo.pojo.Article;
import com.demo.service.ArticleService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
/**
* 文章serviceImpl
*/
@Service
public class ArticleServiceImpl implements ArticleService {
private final ArticleSearchRepository articleSearchRepository;
@Autowired
public ArticleServiceImpl(ArticleSearchRepository articleSearchRepository) {
this.articleSearchRepository = articleSearchRepository;
}
@Override
public String add(Article article){
try {
articleSearchRepository.save(article);
return "success";
} catch (Exception e) {
e.printStackTrace();
return "defeated";
}
}
@Override
public String delete(Article article){
try {
articleSearchRepository.delete(article);
return "success";
} catch (Exception e) {
e.printStackTrace();
return "defeated";
}
}
@Override
public String update(Article article){
try {
articleSearchRepository.save(article);
return "success";
} catch (Exception e) {
e.printStackTrace();
return "defeated";
}
}
@Override
public Article queryArticleById(Long id){
return articleSearchRepository.queryArticleById(id);
}
}
Application
SearchApplication
package com.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SearchApplication {
public static void main(String[] args) {
SpringApplication.run(SearchApplication.class,args);
}
}
Resources
application.properties
spring.data.elasticsearch.cluster-name=my-application
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
测试(postman)
使用的是本地默认端口:8080
启动SearchApplication后
使用add方法,添加一个Article数据
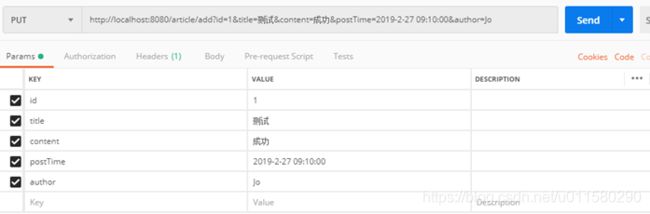
在head中我们可以看到已经存入ES

然后调用queryArticleById方法,参数传 id 值为 1,获取到结果

然后调用update方法对id为1的数据进行修改:

再看head 显示已经修改成功:

最后调用delete方法删除这条数据:

Head显示 这条数据已经不在了:

本文主要参考https://blog.csdn.net/chen_2890/article/details/83895646 这篇博客,在此对原作者表示谢意。