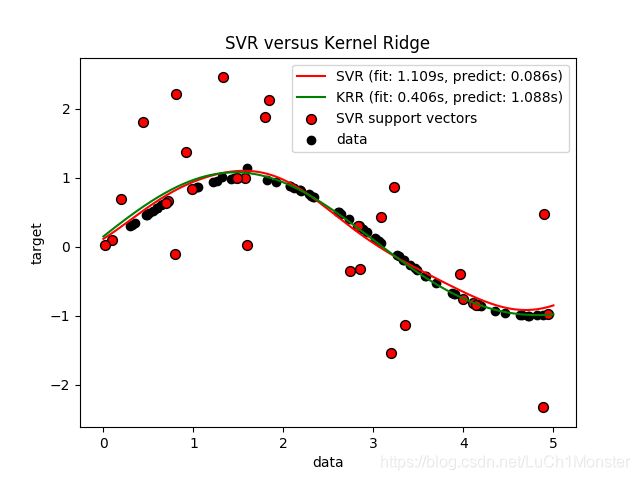
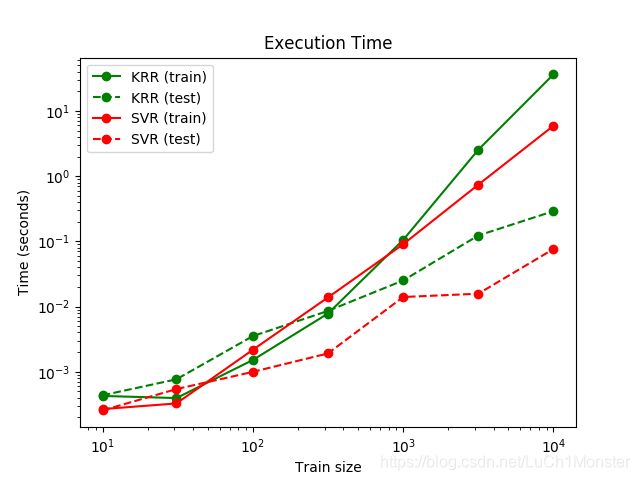
- Python开发常用的三方模块如下:
换个网名有点难
python开发语言
Python是一门功能强大的编程语言,拥有丰富的第三方库,这些库为开发者提供了极大的便利。以下是100个常用的Python库,涵盖了多个领域:1、NumPy,用于科学计算的基础库。2、Pandas,提供数据结构和数据分析工具。3、Matplotlib,一个绘图库。4、Scikit-learn,机器学习库。5、SciPy,用于数学、科学和工程的库。6、TensorFlow,由Google开发的开源机
- 【机器学习】广义线性模型(GLM)的基本概念以及广义线性模型在python中的实例(包含statsmodels和scikit-learn实现逻辑回归)
Lossya
机器学习pythonscikit-learn线性回归人工智能逻辑回归
引言GLM扩展了传统的线性回归模型,使其能够处理更复杂的数据类型和分布文章目录引言一、广义线性模型1.1定义1.2广义线性模型的组成1.2.1响应变量(ResponseVariable)1.2.2链接函数(LinkFunction)1.2.3线性预测器(LinearPredictor)1.3常见的广义线性模型1.3.1线性回归1.3.2逻辑回归1.3.3泊松回归1.4GLM的特性1.5广义线性模型
- Anaconda和Python的区别
王摇摆
ANACONDApython开发语言经验学习日常
0.专业英语Python巨蟒Anaconda大蟒蛇1.简单区别1.1安装包大小不同python自身缺少numpy、matplotlib、scipy、scikit-learn…等一系列包需要安装pip来导入这些包才能进行相应运算。Anaconda(开源的Python包管理器)是一个python发行版,包含了conda、Python等180多个科学包及其依赖项。包含了大量的包,使用Anaconda无需
- 机器学习框架巅峰对决:TensorFlow vs. PyTorch vs. Scikit-Learn实战分析
@sinner
技术选型机器学习tensorflowpytorchscikit-learn
1.引言1.1机器学习框架的重要性在机器学习的黄金时代,框架的选择对于开发高效、可扩展的模型至关重要。合适的框架可以极大地提高开发效率,简化模型的构建和训练过程,并支持大规模的模型部署。因此,了解和选择最合适的机器学习框架对于研究人员和工程师来说是一个关键的步骤。1.2三大框架概览:TensorFlow、PyTorch、Scikit-Learn目前,最流行的机器学习框架主要有TensorFlow、
- termux下pip包出现Package ‘xxx-dev‘ has no installation candidate处理
拐几个弯
其他termuxhasnoinstallationcandidatepip
---------------------------当时在平板termux上安装scikit-learn时,总会安装失败,因此在网上看一些教程,说是要安装一些xxx-dev的依赖,但是在pip这些依赖的时候总会Package‘xxx-dev’hasnoinstallationcandidate,后来找了半天终于在一个国外网站找到了原因:最新版的pip中,已将-dev依赖合并了原包,如Python
- PyTorch 基础学习(14)- 归一化
花千树-010
PyTorchpytorch学习人工智能
系列文章:《PyTorch基础学习》文章索引概述归一化是数据预处理中的重要步骤之一,它可以将数据调整到特定的范围或分布,有助于加速训练并提高模型的性能。在机器学习中,不同的归一化方法适用于不同的场景。本文将详细介绍scikit-learn中的常见归一化方法及其应用。1.Min-Max归一化MinMaxScalerMin-Max归一化将数据缩放到指定范围,通常是[0,1]。这种方法保留了数据的相对关
- sklearn 评估模型 常用函数
小Z资本
sklearn人工智能python
`sklearn.metrics`是scikit-learn库中的一个模块,它提供了许多用于评估预测模型性能的指标和工具。这些指标和工具可以帮助你了解模型在训练集和测试集上的表现,以及模型是否能够很好地泛化到未见过的数据。以下是一些`sklearn.metrics`中常用的函数和指标:1.**分类指标**:-`accuracy_score`:计算分类准确率。-`classification_rep
- 在sklearn中如何实现参数网格搜索(GridSearch)?
2401_85761762
sklearn人工智能python
深入理解Scikit-learn中的参数网格搜索(GridSearch)引言在机器学习模型的开发过程中,超参数的调整对于模型性能有着至关重要的影响。Scikit-learn(简称sklearn),作为Python中一个广泛使用的机器学习库,提供了强大的工具来帮助我们进行超参数的优化。其中,GridSearchCV是实现参数网格搜索的利器。本文将详细介绍GridSearchCV的使用方法,并探讨其在
- 人工智能开源库有哪些
openwin_top
人工智能人工智能开源python
TensorFlow:由Google开发的深度学习库,提供了丰富的工具和API,支持CPU和GPU计算。PyTorch:由Facebook开发的深度学习框架,提供动态图和静态图两种模式,并且易于使用。Keras:基于TensorFlow、Theano和CNTK等深度学习库的高级API,可帮助用户快速构建神经网络。Scikit-learn:用Python编写的机器学习库,提供了许多常见的机器学习算法
- Scikit-learn:用于数据挖掘和数据分析的简单而有效的工具,建立在 NumPy, SciPy 和 Matplotlib 上。
Jr_l
#数据科学数据挖掘scikit-learn数据分析
引言Scikit-learn是一个基于Python的机器学习库,旨在为数据挖掘和数据分析提供简单而有效的工具。它建立在强大的科学计算库之上,包括NumPy、SciPy和Matplotlib,提供了丰富的机器学习算法和工具,如分类、回归、聚类、降维、模型选择和数据预处理等。Scikit-learn的API设计简洁,使用方便,且拥有高效的实现,因此在学术研究和工业界中得到了广泛应用。无论是数据科学家还
- python库——sklearn的关键组件和参数设置
零 度°
pythonpythonsklearn
文章目录模型构建线性回归逻辑回归决策树分类器随机森林支持向量机K-近邻模型评估交叉验证性能指标特征工程主成分分析标准化和归一化scikit-learn,简称sklearn,是Python中一个广泛使用的机器学习库,它建立在NumPy、SciPy和Matplotlib这些科学计算库之上。sklearn提供了简单而有效的工具来进行数据挖掘和数据分析。我们将介绍sklearn中一些关键组件的参数设置。模
- Python中的自然语言处理和文本挖掘
api77
电商apiapipython自然语言处理easyui开发语言网络前端java
在Python中,自然语言处理(NLP)和文本挖掘通常涉及对文本数据进行清洗、转换、分析和提取有用信息的过程。Python有许多库和工具可以帮助我们完成这些任务,其中最常用的包括nltk(自然语言处理工具包)、spaCy、gensim、textblob和scikit-learn等。以下是一个简单的例子,展示了如何使用Python和nltk库进行基本的自然语言处理和文本挖掘。安装必要的库首先,确保你
- 吴恩达机器学习全课程笔记第二篇
亿维数组
MachineLearning机器学习笔记人工智能学习
目录前言P31-P33logistics(逻辑)回归决策边界P34-P36逻辑回归的代价函数梯度下降的实现P37-P41过拟合问题正则化代价函数正则化线性回归正则化logistics回归前言这是吴恩达机器学习笔记的第二篇,第一篇笔记请见:吴恩达机器学习全课程笔记第一篇完整的课程链接如下:吴恩达机器学习教程(bilibili)推荐网站:scikit-learn中文社区吴恩达机器学习学习资料(gith
- Python | Conda常用命令
-拟墨画扇-
Pythonpythonconda开发语言
一、介绍1、Anaconda工具Anaconda是一个用于数据科学和机器学习的开源软件包管理器和环境管理器。它包含了许多流行的数据科学工具和库,如Python、JupyterNotebook、numpy、pandas、scikit-learn等,可以帮助用户轻松地管理和安装这些工具和库。Anaconda还提供了一个名为Conda的包管理工具,可以帮助用户创建和管理不同的环境,以便在不同项目中使用不
- python机器学习库Scikit-learn
崔吉龙
python语言中用来处理机器学习的库最重要的就是Scikit-learn,简称sklearn。被大多数科学家所钟爱,包括了构建良好的学习算法、误差函数和测试例程。在sklearn的核心有四种类型的类覆盖了所有机器学习功能:分类回归聚类分组转换数据虽然sklearn提供的算法比较多,但是他们都符合基本的接口定义,为了是使用不同的算法时,所使用的接口时统一的。sklearn提供了四个基本对象接口。评
- 机器学习入门--循环神经网络原理与实践
Dr.Cup
机器学习入门机器学习rnn深度学习
循环神经网络循环神经网络(RNN)是一种在序列数据上表现出色的人工神经网络。相比于传统前馈神经网络,RNN更加适合处理时间序列数据,如音频信号、自然语言和股票价格等。本文将介绍RNN的基本数学原理、使用PyTorch和Scikit-Learn数据集实现的代码。数学原理RNN是一种带有循环结构的神经网络,其在处理序列数据时将前一次的输出作为当前输入的一部分。这使得RNN能够记住先前的状态和信息,并且
- 【机器学习笔记】 6 机器学习库Scikit-learn
RIKI_1
机器学习机器学习笔记scikit-learn
Scikit-learn概述Scikit-learn是基于NumPy、SciPy和Matplotlib的开源Python机器学习包,它封装了一系列数据预处理、机器学习算法、模型选择等工具,是数据分析师首选的机器学习工具包。自2007年发布以来,scikit-learn已经成为Python重要的机器学习库了,scikit-learn简称sklearn,支持包括分类,回归,降维和聚类四大机器学习算法。
- 聚类分析入门:使用Python和K-means算法进行数据聚类
Evaporator Core
python
文章标题:聚类分析入门:使用Python和K-means算法进行数据聚类简介聚类分析是机器学习中的一个重要任务,它涉及将数据集中的样本分成多个类别或簇,使得同一簇内的样本相似度较高,不同簇之间的样本相似度较低。K-means算法是一种常用的聚类算法,它通过迭代优化簇的中心点来实现聚类。本文将介绍如何使用Python编程语言和Scikit-learn库实现K-means算法,以及如何对数据进行聚类分
- Python机器学习:Scikit-learn库与应用
数据小爬虫
api电商api机器学习pythonscikit-learn开发语言运维服务器
当涉及到Python机器学习时,Scikit-learn是一个非常流行且功能强大的库。它提供了广泛的算法和工具,使得机器学习变得简单而高效。下面是一个简单的Scikit-learn库与应用示例,其中包括代码。首先,确保你已经安装了Scikit-learn库。你可以使用pip命令来安装它:bash复制代码pipinstallscikit-learn接下来,我们将使用Scikit-learn来执行一个
- 【机器学习算法】KNN鸢尾花种类预测案例和特征预处理。全md文档笔记(已分享,附代码)
机器学习python算法
本系列文章md笔记(已分享)主要讨论机器学习算法相关知识。机器学习算法文章笔记以算法、案例为驱动的学习,伴随浅显易懂的数学知识,让大家掌握机器学习常见算法原理,应用Scikit-learn实现机器学习算法的应用,结合场景解决实际问题。包括K-近邻算法,线性回归,逻辑回归,决策树算法,集成学习,聚类算法。K-近邻算法的距离公式,应用LinearRegression或SGDRegressor实现回归预
- 基于聚类的点云背景分离算法python代码
love6a6
算法聚类python
点云背景分离是一个常用的计算机视觉任务,它旨在从点云数据中分离出感兴趣的物体。聚类是一种常用的方法,可以通过将相似的点聚集在一起来完成背景分离。下面是一个简单的基于K-Means聚类的点云背景分离的Python代码示例,使用的是scikit-learn库:importnumpyasnpfromsklearn.clusterimportKMeansfromsklearn.preprocessingi
- 【机器学习】机器学习常见算法详解第4篇:KNN算法计算过程(已分享,附代码)
机器学习python算法
本系列文章md笔记(已分享)主要讨论机器学习算法相关知识。机器学习算法文章笔记以算法、案例为驱动的学习,伴随浅显易懂的数学知识,让大家掌握机器学习常见算法原理,应用Scikit-learn实现机器学习算法的应用,结合场景解决实际问题。包括K-近邻算法,线性回归,逻辑回归,决策树算法,集成学习,聚类算法。K-近邻算法的距离公式,应用LinearRegression或SGDRegressor实现回归预
- 21丨朴素贝叶斯分类(下):如何对文档进行分类?
张九日zx
朴素贝叶斯分类最适合的场景就是文本分类、情感分析和垃圾邮件识别。sklearn机器学习包sklearn的全称叫Scikit-learn,它给我们提供了3个朴素贝叶斯分类算法,分别是高斯朴素贝叶斯(GaussianNB)、多项式朴素贝叶斯(MultinomialNB)和伯努利朴素贝叶斯(BernoulliNB)。自然界的现象比较适合用高斯朴素贝叶斯来处理,而文本分类是使用多项式朴素贝叶斯或者伯努利朴
- Python的Sklearn库中的数据集
王荣胜z
一、Sklearn介绍scikit-learn是Python语言开发的机器学习库,一般简称为sklearn,目前算是通用机器学习算法库中实现得比较完善的库了。其完善之处不仅在于实现的算法多,还包括大量详尽的文档和示例。其文档写得通俗易懂,完全可以当成机器学习的教程来学习。二、Sklearn数据集种类sklearn的数据集有好多个种自带的小数据集(packageddataset):sklearn.d
- Python数据科学:Scikit-Learn机器学习
偶是不器
Pythonpython开发语言scikit-learn手写数字识别鸢尾花分类
4.1Scikit-Learn机器学习Scikit-Learn使用的数据表示:二维网格数据表实例1:通过Seaborn导入数据defskLearn():'''scikitLearn基本介绍:return:'''importseabornassns#导入Iris数据集#注:一般网络访问不了iris=sns.load_dataset('iris')iris.head()实例2:通过本地导入数据defs
- [韩顺平]python笔记
超级用户 root
Pythonpython笔记开发语言
AI工程师、运维工程师python排名逐年上升,为什么?python对大数据分析、人工智能中关键的机器学习、深度学习都提供有力的支持Python支持最庞大的代码库,功能超强数据分析:numpy/pandas/os机器学习:tensorflow/scikit-learn/theano爬虫:urllib/reques/bs4/scrapy网页开发:Django/falsk/web运维:saltstac
- 神经网络中的分位数回归和分位数损失
在使用机器学习构建预测模型时,我们不只是想知道“预测值(点预测)”,而是想知道“预测值落在某个范围内的可能性有多大(区间预测)”。例如当需要进行需求预测时,如果只储备最可能的需求预测量,那么缺货的概率非常的大。但是如果库存处于预测的第95个百分位数(需求有95%的可能性小于或等于该值),那么缺货数量会减少到大约20分之1。获得这些百分位数值的机器学习方法有:scikit-learn:Gradien
- Python三维体素化网格和点云计算
亚图跨际
Python计算python点云三维数据
要点Python三维点云自动生成3D网格和表面重建,创建多个细节层次Python使用4种工具体素化网格,创建点云数据可视化Python计算RGB-D图像的点云,点云地面检测算法,过滤点云以便下采样和去除异常值,scikit-learn聚类点云数据Python点云和网格计算更多示例:使用泊松盘采样在网格上生成蓝噪声样本,对体素网格上的点云进行下采样,从点云估计法线,计算每个顶点的网格法线三维点云点云
- Pycharm安装sklearn后,仍然报错No module named ‘sklearn‘
CRTao
pycharmsklearnide
Pycharm安装sklearn后,仍然报错Nomodulenamed‘sklearn’1.因为sklean是缩写,真正需要下载的包为scikit-learn2.下载scikit-learn不成功,可能是因为你之前安装过sklean,需要先把它卸载,然后再下载scikit-learn。3、下载scikit-learn还是不成功,需要检查一下你的pycharm的pip和电脑的pip版本是否相同,如果
- 机器学习--K近邻算法,以及python中通过Scikit-learn库实现K近邻算法API使用技巧
景天科技苑
机器学习机器学习python近邻算法
文章目录1.K-近邻算法思想2.K-近邻算法(KNN)概念3.电影类型分析4.KNN算法流程总结5.k近邻算法api初步使用机器学习库scikit-learn1Scikit-learn工具介绍2.安装3.Scikit-learn包含的内容4.K-近邻算法API5.案例5.1步骤分析5.2代码过程1.K-近邻算法思想假如你有一天来到北京,你有一些朋友也在北京居住,你来到北京之后,你也不知道你在北京的
- 如何用ruby来写hadoop的mapreduce并生成jar包
wudixiaotie
mapreduce
ruby来写hadoop的mapreduce,我用的方法是rubydoop。怎么配置环境呢:
1.安装rvm:
不说了 网上有
2.安装ruby:
由于我以前是做ruby的,所以习惯性的先安装了ruby,起码调试起来比jruby快多了。
3.安装jruby:
rvm install jruby然后等待安
- java编程思想 -- 访问控制权限
百合不是茶
java访问控制权限单例模式
访问权限是java中一个比较中要的知识点,它规定者什么方法可以访问,什么不可以访问
一:包访问权限;
自定义包:
package com.wj.control;
//包
public class Demo {
//定义一个无参的方法
public void DemoPackage(){
System.out.println("调用
- [生物与医学]请审慎食用小龙虾
comsci
生物
现在的餐馆里面出售的小龙虾,有一些是在野外捕捉的,这些小龙虾身体里面可能带有某些病毒和细菌,人食用以后可能会导致一些疾病,严重的甚至会死亡.....
所以,参加聚餐的时候,最好不要点小龙虾...就吃养殖的猪肉,牛肉,羊肉和鱼,等动物蛋白质
- org.apache.jasper.JasperException: Unable to compile class for JSP:
商人shang
maven2.2jdk1.8
环境: jdk1.8 maven tomcat7-maven-plugin 2.0
原因: tomcat7-maven-plugin 2.0 不知吃 jdk 1.8,换成 tomcat7-maven-plugin 2.2就行,即
<plugin>
- 你的垃圾你处理掉了吗?GC
oloz
GC
前序:本人菜鸟,此文研究学习来自网络,各位牛牛多指教
1.垃圾收集算法的核心思想
Java语言建立了垃圾收集机制,用以跟踪正在使用的对象和发现并回收不再使用(引用)的对象。该机制可以有效防范动态内存分配中可能发生的两个危险:因内存垃圾过多而引发的内存耗尽,以及不恰当的内存释放所造成的内存非法引用。
垃圾收集算法的核心思想是:对虚拟机可用内存空间,即堆空间中的对象进行识别
- shiro 和 SESSSION
杨白白
shiro
shiro 在web项目里默认使用的是web容器提供的session,也就是说shiro使用的session是web容器产生的,并不是自己产生的,在用于非web环境时可用其他来源代替。在web工程启动的时候它就和容器绑定在了一起,这是通过web.xml里面的shiroFilter实现的。通过session.getSession()方法会在浏览器cokkice产生JESSIONID,当关闭浏览器,此
- 移动互联网终端 淘宝客如何实现盈利
小桔子
移動客戶端淘客淘寶App
2012年淘宝联盟平台为站长和淘宝客带来的分成收入突破30亿元,同比增长100%。而来自移动端的分成达1亿元,其中美丽说、蘑菇街、果库、口袋购物等App运营商分成近5000万元。 可以看出,虽然目前阶段PC端对于淘客而言仍旧是盈利的大头,但移动端已经呈现出爆发之势。而且这个势头将随着智能终端(手机,平板)的加速普及而更加迅猛
- wordpress小工具制作
aichenglong
wordpress小工具
wordpress 使用侧边栏的小工具,很方便调整页面结构
小工具的制作过程
1 在自己的主题文件中新建一个文件夹(如widget),在文件夹中创建一个php(AWP_posts-category.php)
小工具是一个类,想侧边栏一样,还得使用代码注册,他才可以再后台使用,基本的代码一层不变
<?php
class AWP_Post_Category extends WP_Wi
- JS微信分享
AILIKES
js
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api) {
// 微信分享的数据
var wxData = {
&nb
- 封装探讨
百合不是茶
JAVA面向对象 封装
//封装 属性 方法 将某些东西包装在一起,通过创建对象或使用静态的方法来调用,称为封装;封装其实就是有选择性地公开或隐藏某些信息,它解决了数据的安全性问题,增加代码的可读性和可维护性
在 Aname类中申明三个属性,将其封装在一个类中:通过对象来调用
例如 1:
//属性 将其设为私有
姓名 name 可以公开
- jquery radio/checkbox change事件不能触发的问题
bijian1013
JavaScriptjquery
我想让radio来控制当前我选择的是机动车还是特种车,如下所示:
<html>
<head>
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.7.1/jquery.min.js" type="text/javascript"><
- AngularJS中安全性措施
bijian1013
JavaScriptAngularJS安全性XSRFJSON漏洞
在使用web应用中,安全性是应该首要考虑的一个问题。AngularJS提供了一些辅助机制,用来防护来自两个常见攻击方向的网络攻击。
一.JSON漏洞
当使用一个GET请求获取JSON数组信息的时候(尤其是当这一信息非常敏感,
- [Maven学习笔记九]Maven发布web项目
bit1129
maven
基于Maven的web项目的标准项目结构
user-project
user-core
user-service
user-web
src
- 【Hive七】Hive用户自定义聚合函数(UDAF)
bit1129
hive
用户自定义聚合函数,用户提供的多个入参通过聚合计算(求和、求最大值、求最小值)得到一个聚合计算结果的函数。
问题:UDF也可以提供输入多个参数然后输出一个结果的运算,比如加法运算add(3,5),add这个UDF需要实现UDF的evaluate方法,那么UDF和UDAF的实质分别究竟是什么?
Double evaluate(Double a, Double b)
- 通过 nginx-lua 给 Nginx 增加 OAuth 支持
ronin47
前言:我们使用Nginx的Lua中间件建立了OAuth2认证和授权层。如果你也有此打算,阅读下面的文档,实现自动化并获得收益。SeatGeek 在过去几年中取得了发展,我们已经积累了不少针对各种任务的不同管理接口。我们通常为新的展示需求创建新模块,比如我们自己的博客、图表等。我们还定期开发内部工具来处理诸如部署、可视化操作及事件处理等事务。在处理这些事务中,我们使用了几个不同的接口来认证:
&n
- 利用tomcat-redis-session-manager做session同步时自定义类对象属性保存不上的解决方法
bsr1983
session
在利用tomcat-redis-session-manager做session同步时,遇到了在session保存一个自定义对象时,修改该对象中的某个属性,session未进行序列化,属性没有被存储到redis中。 在 tomcat-redis-session-manager的github上有如下说明: Session Change Tracking
As noted in the &qu
- 《代码大全》表驱动法-Table Driven Approach-1
bylijinnan
java算法
关于Table Driven Approach的一篇非常好的文章:
http://www.codeproject.com/Articles/42732/Table-driven-Approach
package com.ljn.base;
import java.util.Random;
public class TableDriven {
public
- Sybase封锁原理
chicony
Sybase
昨天在操作Sybase IQ12.7时意外操作造成了数据库表锁定,不能删除被锁定表数据也不能往其中写入数据。由于着急往该表抽入数据,因此立马着手解决该表的解锁问题。 无奈此前没有接触过Sybase IQ12.7这套数据库产品,加之当时已属于下班时间无法求助于支持人员支持,因此只有借助搜索引擎强大的
- java异常处理机制
CrazyMizzz
java
java异常关键字有以下几个,分别为 try catch final throw throws
他们的定义分别为
try: Opening exception-handling statement.
catch: Captures the exception.
finally: Runs its code before terminating
- hive 数据插入DML语法汇总
daizj
hiveDML数据插入
Hive的数据插入DML语法汇总1、Loading files into tables语法:1) LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]解释:1)、上面命令执行环境为hive客户端环境下: hive>l
- 工厂设计模式
dcj3sjt126com
设计模式
使用设计模式是促进最佳实践和良好设计的好办法。设计模式可以提供针对常见的编程问题的灵活的解决方案。 工厂模式
工厂模式(Factory)允许你在代码执行时实例化对象。它之所以被称为工厂模式是因为它负责“生产”对象。工厂方法的参数是你要生成的对象对应的类名称。
Example #1 调用工厂方法(带参数)
<?phpclass Example{
- mysql字符串查找函数
dcj3sjt126com
mysql
FIND_IN_SET(str,strlist)
假如字符串str 在由N 子链组成的字符串列表strlist 中,则返回值的范围在1到 N 之间。一个字符串列表就是一个由一些被‘,’符号分开的自链组成的字符串。如果第一个参数是一个常数字符串,而第二个是type SET列,则 FIND_IN_SET() 函数被优化,使用比特计算。如果str不在strlist 或st
- jvm内存管理
easterfly
jvm
一、JVM堆内存的划分
分为年轻代和年老代。年轻代又分为三部分:一个eden,两个survivor。
工作过程是这样的:e区空间满了后,执行minor gc,存活下来的对象放入s0, 对s0仍会进行minor gc,存活下来的的对象放入s1中,对s1同样执行minor gc,依旧存活的对象就放入年老代中;
年老代满了之后会执行major gc,这个是stop the word模式,执行
- CentOS-6.3安装配置JDK-8
gengzg
centos
JAVA_HOME=/usr/java/jdk1.8.0_45
JRE_HOME=/usr/java/jdk1.8.0_45/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME
- 【转】关于web路径的获取方法
huangyc1210
Web路径
假定你的web application 名称为news,你在浏览器中输入请求路径: http://localhost:8080/news/main/list.jsp 则执行下面向行代码后打印出如下结果: 1、 System.out.println(request.getContextPath()); //可返回站点的根路径。也就是项
- php里获取第一个中文首字母并排序
远去的渡口
数据结构PHP
很久没来更新博客了,还是觉得工作需要多总结的好。今天来更新一个自己认为比较有成就的问题吧。 最近在做储值结算,需求里结算首页需要按门店的首字母A-Z排序。我的数据结构原本是这样的:
Array
(
[0] => Array
(
[sid] => 2885842
[recetcstoredpay] =&g
- java内部类
hm4123660
java内部类匿名内部类成员内部类方法内部类
在Java中,可以将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类。内部类仍然是一个独立的类,在编译之后内部类会被编译成独立的.class文件,但是前面冠以外部类的类名和$符号。内部类可以间接解决多继承问题,可以使用内部类继承一个类,外部类继承一个类,实现多继承。
&nb
- Caused by: java.lang.IncompatibleClassChangeError: class org.hibernate.cfg.Exten
zhb8015
maven pom.xml关于hibernate的配置和异常信息如下,查了好多资料,问题还是没有解决。只知道是包冲突,就是不知道是哪个包....遇到这个问题的分享下是怎么解决的。。
maven pom:
<dependency>
<groupId>org.hibernate</groupId>
<ar
- Spark 性能相关参数配置详解-任务调度篇
Stark_Summer
sparkcachecpu任务调度yarn
随着Spark的逐渐成熟完善, 越来越多的可配置参数被添加到Spark中来, 本文试图通过阐述这其中部分参数的工作原理和配置思路, 和大家一起探讨一下如何根据实际场合对Spark进行配置优化。
由于篇幅较长,所以在这里分篇组织,如果要看最新完整的网页版内容,可以戳这里:http://spark-config.readthedocs.org/,主要是便
- css3滤镜
wangkeheng
htmlcss
经常看到一些网站的底部有一些灰色的图标,鼠标移入的时候会变亮,开始以为是js操作src或者bg呢,搜索了一下,发现了一个更好的方法:通过css3的滤镜方法。
html代码:
<a href='' class='icon'><img src='utv.jpg' /></a>
css代码:
.icon{-webkit-filter: graysc